追风赶月莫停留,平芜尽处是春山。
文章目录
- 追风赶月莫停留,平芜尽处是春山。
- 一、网页分析
- 二、接口分析
- url分析
- 返回数据分析
- 三、编写代码
- 完整代码
2021.7.14更新:浏览器标识使用
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0也就是火狐浏览器内核的,我发现用chrome已经加载不出新的一页了。文中的代码已经更新了。
一、网页分析
打开网址 较真查证平台

打开开发者模式,刷新网页,往下翻看的时候注意到刷新出来了一个请求 URL

请求到的数据是

正好能够和网页中的内容对应起来。


其中还包含标题、言论的真实性、时间、查证的要点以及查证者。
二、接口分析
url分析
https://vp.fact.qq.com/loadmore?artnum=0&token=U2FsdGVkX19IPDkKITF2xCZa%252FxETYaJM%252BPz7pppjc5ZVBjEbahmQ%252F33hOL42W%252BAN&page=1&stopic=&_=1619407484449&callback=jsonp1
我们可以很容易的发现page=1是表示页数,去验证一下发现当page=0的时候其实返回的是第一页的数据。
token=U2FsdGVkX19IPDkKITF2xCZa%252FxETYaJM%252BPz7pppjc5ZVBjEbahmQ%252F33hOL42W%252BAN,这个就是网站设置的Session。其实这个让他保持不变就行,失效了再换
stopic=&_=1619407484449,看到后面的13位数字第一反应是时间戳,而且还是毫秒级别的时间戳,事实便是如此。

返回数据分析

虽然显示的返回数据类型是text类型,但是看这浏览的格式总感觉像是JSON格式的

发现返回的数据是jsonp1(json_data)这种格式的,所以咱们只要把jsonp1()去掉然后提取中间的内容就可以格式化为json数据了
三、编写代码
知道了url规则,以及返回数据的格式,那现在咱们的任务就是构造url然后请求数据
我们可以设置两个变量page, timestamp代表页数和时间戳
page改变很简单,用for循环直接循环就OK
for page in range(0, 100):
timestamp的话就要借助time库来生成
timestamp = int(time.time()*1000)
现在来构造url:
url = "https://vp.fact.qq.com/loadmore?artnum=0&token=U2FsdGVkX19IPDkKITF2xCZa%252FxETYaJM%252BPz7pppjc5ZVBjEbahmQ%252F33hOL42W%252BAN&page={}&stopic=&_={}&callback=jsonp1".format(page, timestamp)
接下来生成前100页的url:
for page in range(0, 100):timestamp = int(time.time()*1000)url = "https://vp.fact.qq.com/loadmore?artnum=0&token=U2FsdGVkX19IPDkKITF2xCZa%252FxETYaJM%252BPz7pppjc5ZVBjEbahmQ%252F33hOL42W%252BAN&page={}&stopic=&_={}&callback=jsonp1".format(page, timestamp)
对于每个url我们都要去用requests库中的get方法去请求数据:
所以我们为了方便就把请求网页的代码写成了函数get_html(url),传入的参数是url返回的是请求到的内容。
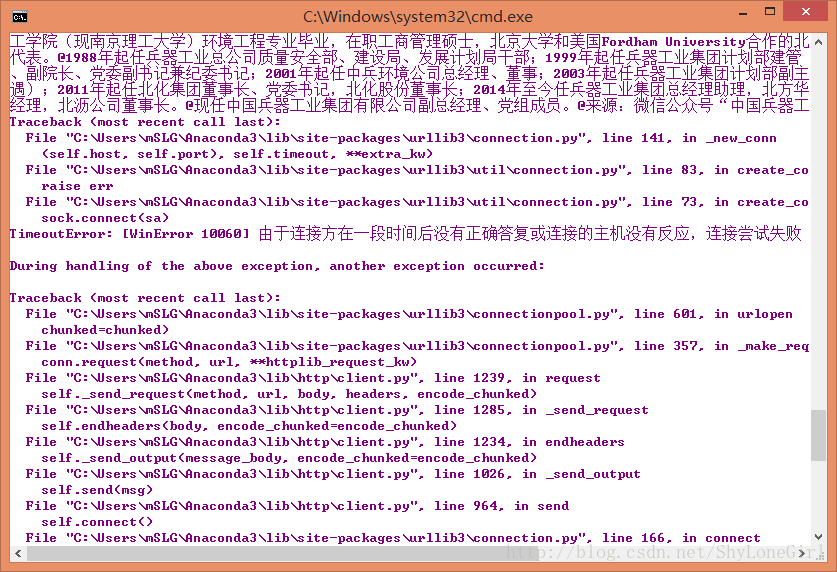
def get_html(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0"}response = requests.get(url, headers=headers)response.encoding = response.apparent_encodingtime.sleep(3) # 加上3s 的延时防止被反爬return response.text
现在我们用到的requests.get()只传入了两个参数url, headers,其实还有更多参数,请读者自行百度。
这个网站只需要这两个参数就足够了。
传入headers目的是为了模拟浏览器进行访问,防止被反爬。

可以在这里找到headers 的相关信息,我们现在只需要其中的user-agent就足够了。
上文说到返回的数据其实是个伪json格式的数据,我们做一下处理就能变成json格式的数据
for page in range(0, 100):timestamp = int(time.time()*1000)url = "https://vp.fact.qq.com/loadmore?artnum=0&token=U2FsdGVkX19IPDkKITF2xCZa%252FxETYaJM%252BPz7pppjc5ZVBjEbahmQ%252F33hOL42W%252BAN&page={}&stopic=&_={}&callback=jsonp1".format(page, timestamp)html = get_html(url) # 此时html里面存的是伪json格式的数据html = html[7:-1] # 用字符串提取提取出来中间的json格式的内容
我们使用json库来格式化数据使其更方便我们后续的提取
response = json.loads(html)
到此,数据处理部分就完成了,下一步就是数据提取了。

我们发现数据都在content标签下,所以我们用
response = response['content']
来提取列表里数据,此时response是一个列表类型的数据
那我们就来遍历这个列表提取所需要的数据并存到一个字典中
for i in response:data = {}data['explain'] = i['explain']data['title'] = i['title']data['date'] = i['date']data['result'] = i['result']data['author'] = i['author']data['abstract'] = i['abstract']
那接下来就是保存了,我也写了个函数save_data(data)传入的是字典类型的数据
def save_data(data):title = ["title", "date", "explain", "result", "author", "abstract"]with open("疫情谣言数据.csv", "a", encoding="utf-8", newline="")as fi:fi = csv.writer(fi) # 引入csv库fi.writerow([data[i] for i in title]) # 写入文件
提取完数据然后调用保存函数就OK了
for i in response:data = {}data['explain'] = i['explain']data['title'] = i['title']data['date'] = i['date']data['result'] = i['result']data['author'] = i['author']data['abstract'] = i['abstract']save_data(data)
完整代码
# -*- coding:utf-8 -*-
# @time: 2021/4/26 11:05
# @Author: pioneer
# @Environment: Python 3.7
import json
import requests
import csv
import timedef get_html(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0"}response = requests.get(url, headers=headers)response.encoding = response.apparent_encoding # 自动识别并设置编码time.sleep(3) # 加入3s延时,防止被反爬return response.textdef save_data(data):title = ["title", "date", "explain", "result", "author", "abstract"]with open("疫情谣言数据.csv", "a", encoding="utf-8", newline="")as fi:fi = csv.writer(fi) # 导入csv库fi.writerow([data[i] for i in title]) # 写入文件def get_data():for page in range(0, 100):print(page)timestamp = int(time.time()*1000)url = "https://vp.fact.qq.com/loadmore?artnum=0&token=U2FsdGVkX19IPDkKITF2xCZa%252FxETYaJM%252BPz7pppjc5ZVBjEbahmQ%252F33hOL42W%252BAN&page={}&stopic=&_={}&callback=jsonp1".format(page, timestamp)html = get_html(url) # 此时html里面存的是伪json格式的数据html = html[7:-1] # 用字符串提取提取出来中间的json格式的内容response = json.loads(html)response = response['content'] # 提取数据列表for i in response:data = {}data['explain'] = i['explain']data['title'] = i['title']data['date'] = i['date']data['result'] = i['result']data['author'] = i['author']data['abstract'] = i['abstract']save_data(data)if __name__ == '__main__':get_data()
得到的部分数据截图

欢迎一键三连哦!
还想看哪个网站的爬虫?欢迎留言,说不定下次要分析的就是你想要看的!