文章目录
- 前言
- 一、基本目标
- 二、使用步骤
- 整体代码
- 结果
- 总结
前言
🙉随机找了个网站爬爬,我们的目标是
1.利用爬虫的re、xpath等知识,爬取到这个官网上的新闻,内容有:新闻标题, 发布时间, 新闻链接, 阅读次数, 新闻来源五个属性。
2.把我们爬到的数据放到一个csv的文件中!
那么我们下面开始!🌝
提示:爬虫不可用作违法活动,爬取时要设定休眠时间,不可过度爬取,造成服务器宕机,需付法律责任!!!
一、基本目标
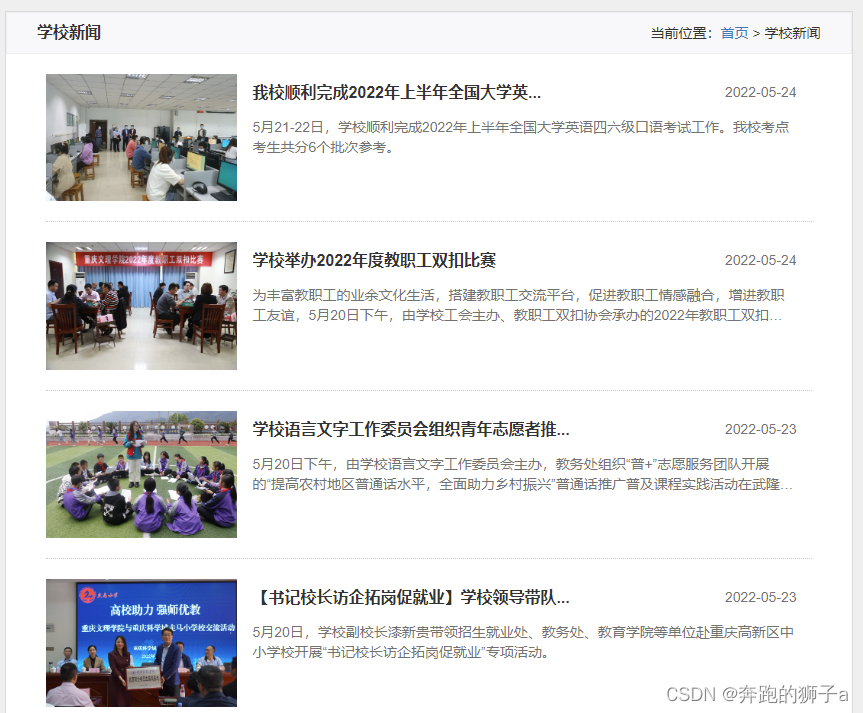
🌎我们的目标是爬取这个https://www.cqwu.edu.cn/channel_23133_0310.html网址的新闻数据
二、使用步骤
整体代码
import re
import time
import requests
from lxml import etree
import csv# 带爬网址
base_url = "https://www.cqwu.edu.cn/channel_23133_0310.html"
# 反反爬
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36","Accept-Encoding": "gzip, deflate, br","Accept-Language": "zh-CN,zh;q=0.9"
}# 爬取信息
resp = requests.get(url=base_url,headers=headers)
# 把信息通过etree进行赋值
html = etree.HTML(resp.text)
# xpath定位新闻列表信息
news_list = html.xpath("/html/body/div/div[3]/div/div/div[2]/div/ul/li")
data_list = []
# 对新闻列表循环遍历
for news in news_list:# 获取新闻链接news_url = news.xpath("./a/@href")[0]# 继续爬取新闻的详情页news_resp = requests.get(url=news_url)# 把详情页html信息赋值news_html = etree.HTML(news_resp.text)# xpath定位新闻详情页的标题news_title = news_html.xpath("/html/body/div/div[3]/div[1]/div/div[2]/div/div/h4/text()")[0]# re正则获取日期和引用来源time_refer_obj = re.compile(r'<div class="news-date">.*?发布时间:(?P<time>.*?)浏览:.*?次 来源:(?P<refer>.*?)</div>', re.S)result = time_refer_obj.finditer(news_resp.text)for it in result:# 对日期和引用进行赋值news_time = it.group("time")news_refer = it.group("refer").strip()# re正则获取浏览量数据count_obj = re.compile(r"浏览:<Script Language='Javascript' src='(?P<count_url>.*?)'>", re.S)result = count_obj.finditer(news_resp.text)for it in result:count_url = "https://www.cqwu.edu.cn" + it.group("count_url")count_resp = requests.get(url=count_url)news_read = count_resp.text.split("'")[1].split("'")[0]# 创建一个字典,把各项爬取的信息赋值到字典当中data = {}data['新闻标题'] = news_titledata['发布时间'] = news_timedata['新闻链接'] = news_urldata['阅读次数'] = news_readdata['新闻来源'] = news_refer# 字典添加到列表中,后续变成xml使用data_list.append(data)# 休眠一秒time.sleep(1)print(data)# 1.创建文件对象,encoding='utf-8'是设置编码格式,newline=''为了防止空行
f = open('news.csv', 'w', encoding='utf-8',newline='')
# 2.基于文件对象构建csv写入对象
csv_write = csv.writer(f)
# 3.构建列表头
csv_write.writerow(['新闻标题', '发布时间', '新闻链接', '阅读次数', '新闻来源'])
for data in data_list:# 4.写入csv文件csv_write.writerow([data['新闻标题'], data['发布时间'], data['新闻链接'], data['阅读次数'], data['新闻来源']])
print("爬取结束!")结果
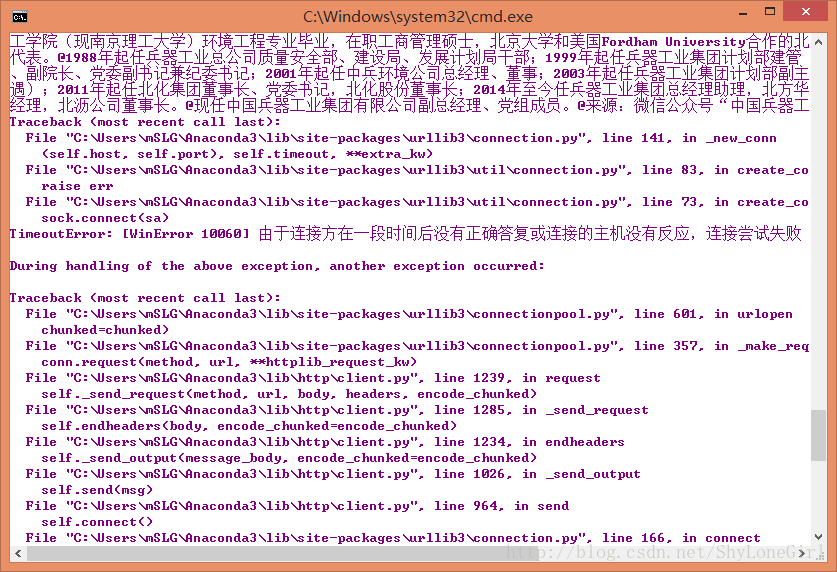
🌗下面是我们程序运行的输出过程
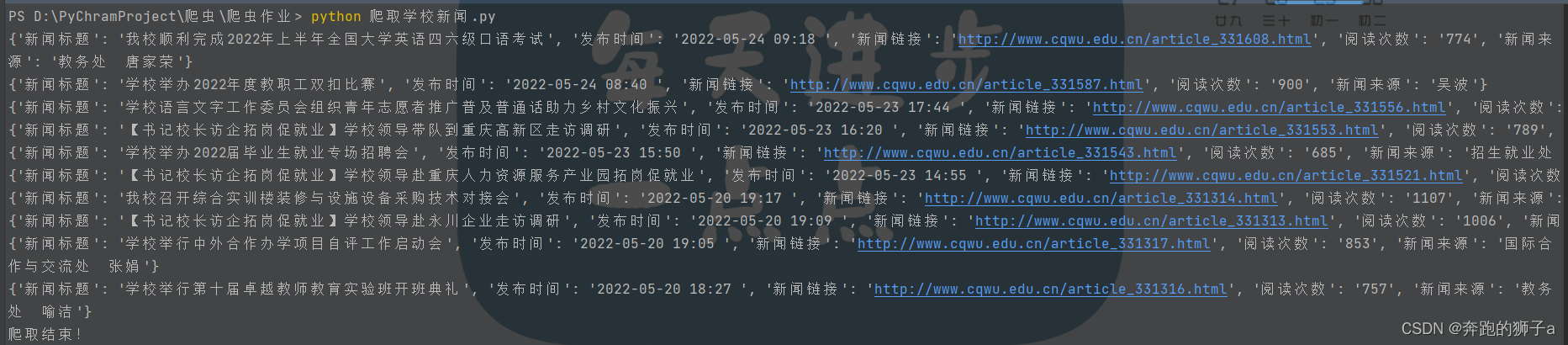
🌖这个是程序把数据存储到csv文件的文档

总结
爬虫的基本步骤:
1.检查有没有反爬,设置常规反反爬,User-Agent和referer都是最常见的反爬手段
2.利用xpath和re技术进行定位,定位后获取想到的数据即可
3.利用csv库把数据写入到csv文件中