首先感谢丘祐玮老师在网易云课堂的Python网络爬虫实战课程,接下来也都是根据课程内容而写.一来算是自己的学习笔记,二来分享给大家参考之用。
课程视频大概是在16年11月录制的,现在是18年2月.其中有几处因网站更新升级产生的不同,小小修改后仍是爬虫学习的高价值资料.
本教程十分适合爬虫初学者(像我这样),涉及知识内容很基础.下面正式开始:
一 首先布置开发语言和环境
1.1 python
对于Windows用户来说,推荐下载Anaconda(开源的Python发行版本,包含了多个科学包及其依赖项).,因为它的c编译器跟Linux,Mac是一样的,这样可以避免很多的各种各样安装配件问题.由于官网入口进可能有些问题,可以从清华大学镜像网站下载它。至于版本选择对应的最新版本(当前版本如下)噻.
就这样的,安装.
如果按默认进行安装,在c盘你的用户文件夹下看到这个
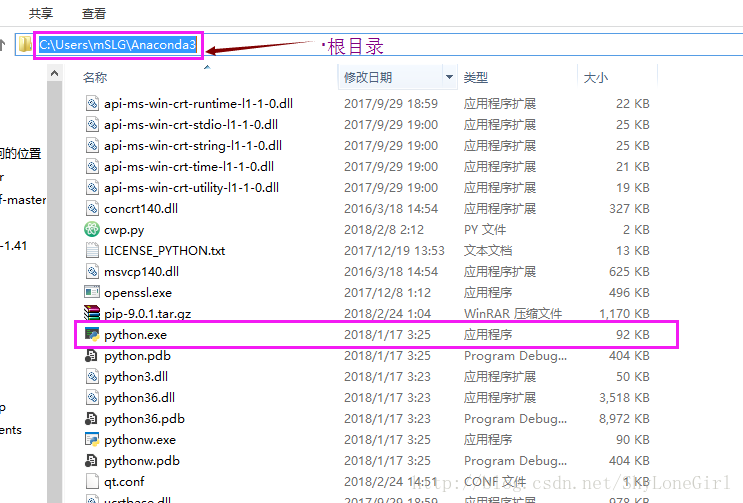
为了方便使用python,把上面的这个包含python.exe的根目录添加到系统的环境变量中,参见 1.3
1.2 pip
pip是一个提供对包的查找下载安装卸载功能的Python包管理工具。官网下载最新版本(当前9.0.1).
解压后到看到是这样(因为我把它解压在了Anaconda目录下才会这样,这个解压文件夹到哪里无所谓啦):
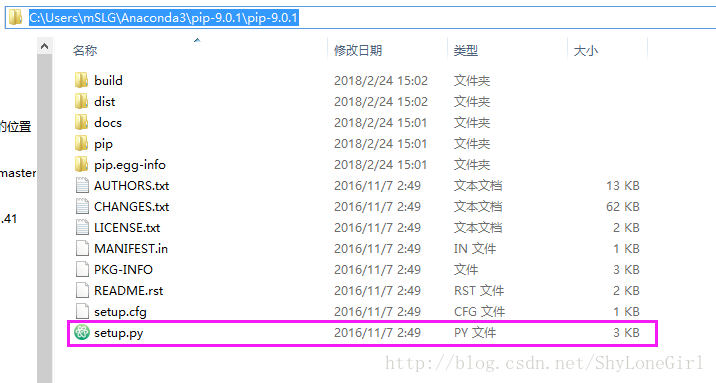
在这个包含setup.py的目录下,按住shif同时右键打开命令行输入:
python setup.py install
(这样的前提是刚刚 1.1 你把python添加到环境变量了噻,不然识别不出python噻)
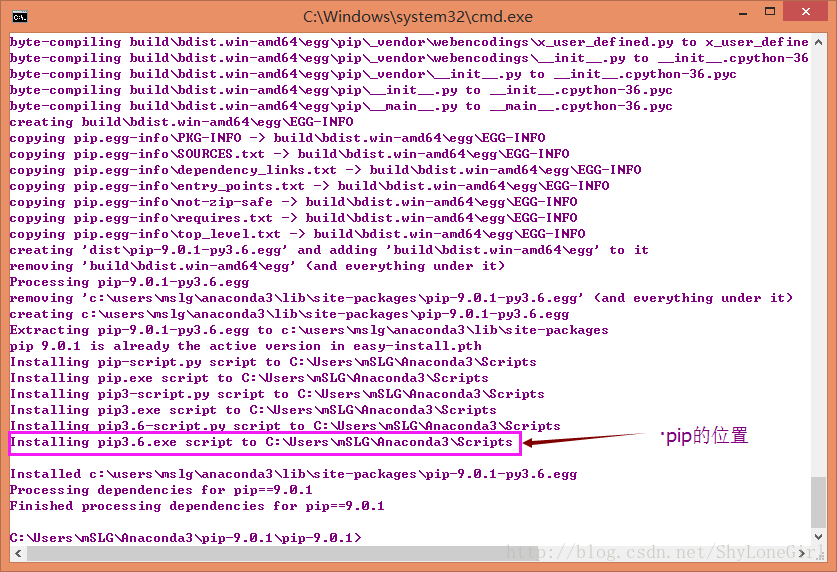
像这样,安装完成。按照上面这个目录我们找到这里
同样按着shift同时右键打开命令行:
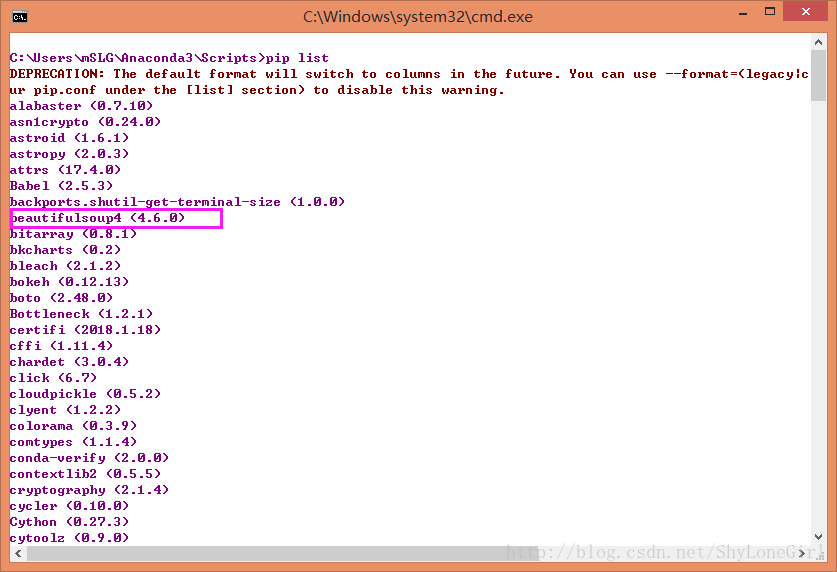
pip list
就能看到好多的包儿,比如接下来我们将会用到的这个Beautifulsoup4.
1.3 添加环境变量
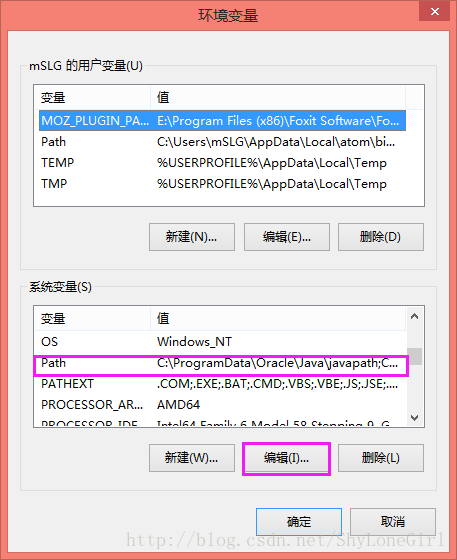
需要添加的两个,一个是python.exe根目录,一个是pip.exe的根目录(位置参考上面截图上指示的)。
右击计算机,属性,然后
选中Path,编辑。(特别注意每两个路径之间英文分号隔开,最后一个路径后无分号)
好了这下我们可以在计算机的任何位置 使用python 和pip了。
二 jupyter notebook编辑器套件安装
(这步非必须,你也可以使用任意一款编辑器,甚至记事本写代码,因此这里做简单介绍)
2.1 安装 jupyter,打开命令行输入:
pip install jupyter
2.2 命令行开启 jupyter notebook(每次使用时都这样开启):
jupyter notebook
之后弹出如下如下
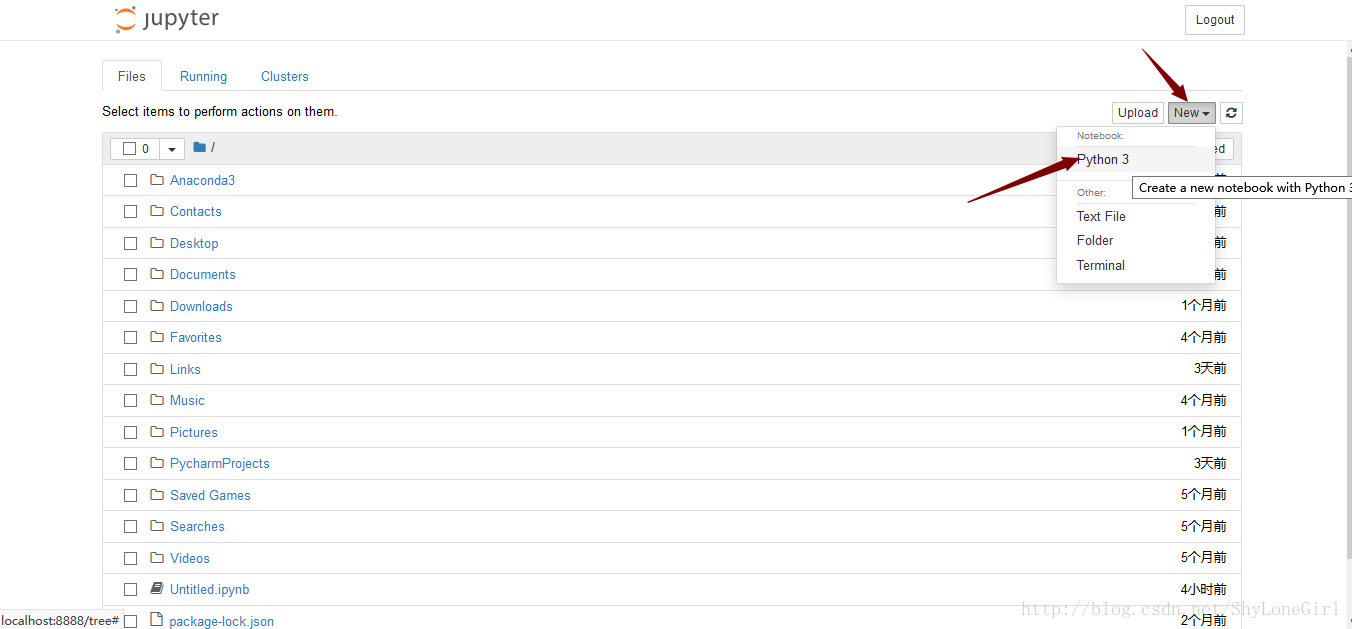
这个编辑器是网页形式,使用很方便,如图新建一个python文件。
三 开始爬虫程序编写
3.1 为了抓取和操作网页内容,需要安装两个套件。打开命令行安装
pip install requests
然后,
pip install BeautifulSoup4
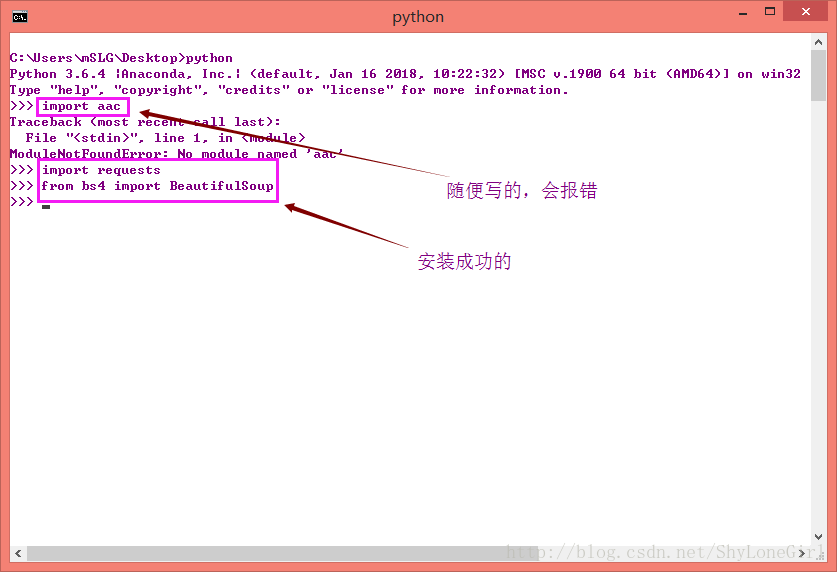
(事实上Anaconda已经为我们准备好了这些套件)测试一下是否成功
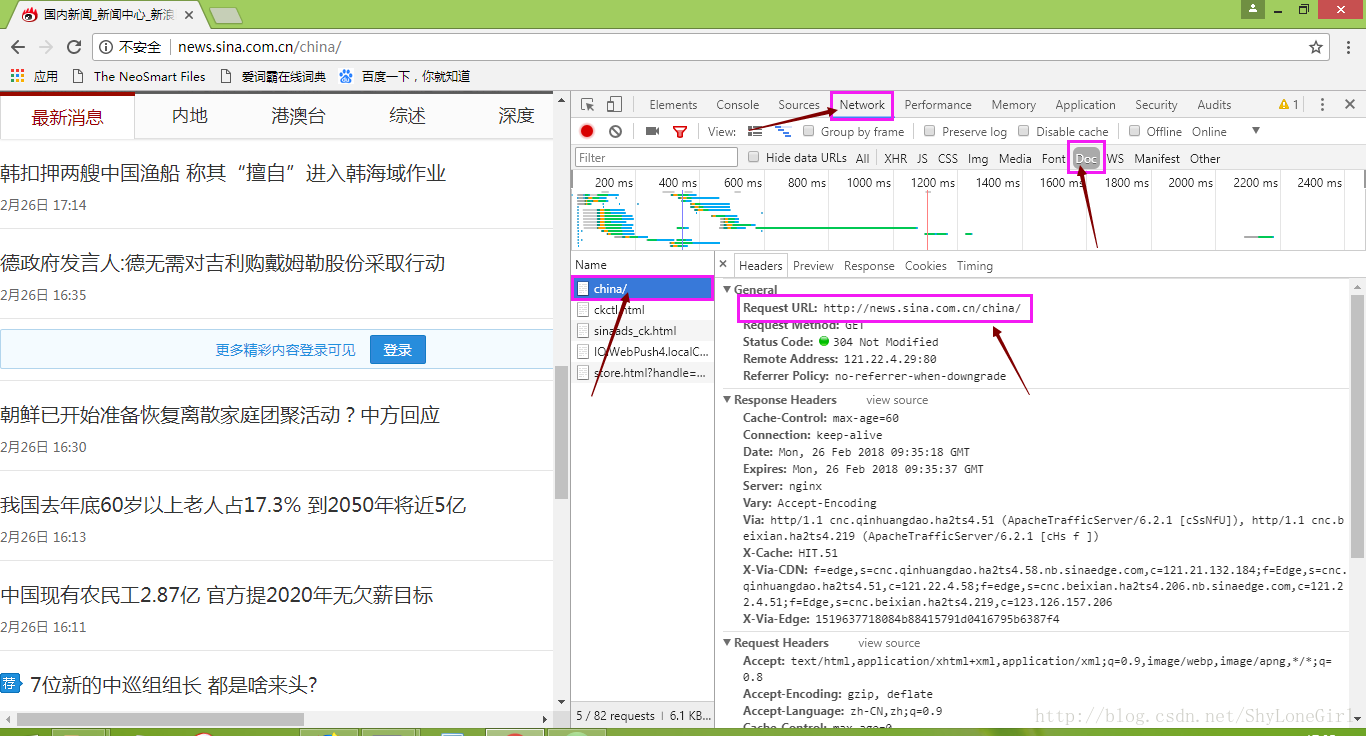
3.2 推荐使用Chrome浏览器,打开新浪新闻国内专栏首页http://news.sina.com.cn/china/
右击检查,观察这些内容:
3.3 使用开发者工具找到新闻标题所在的html标签
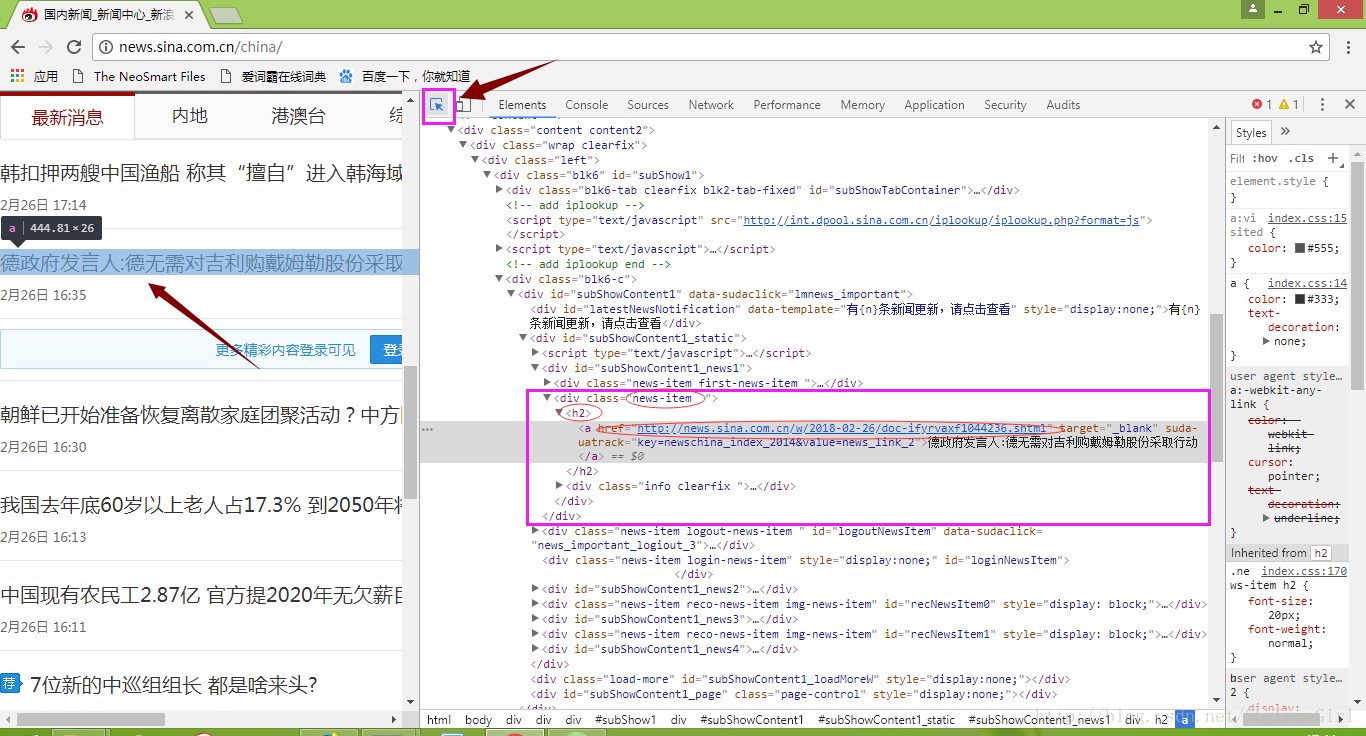
3.4 获取国内新闻首页的新闻标题,时间,和链接
在jupyter notebook中写代码如下:
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
for news in soup.select('.news-item'):
if len(news.select('h2')) > 0:
h2 = news.select('h2')[0].text
time = news.select('.time')[0].text
a = news.select('a')[0]['href']
print(h2,time,a)
结果图
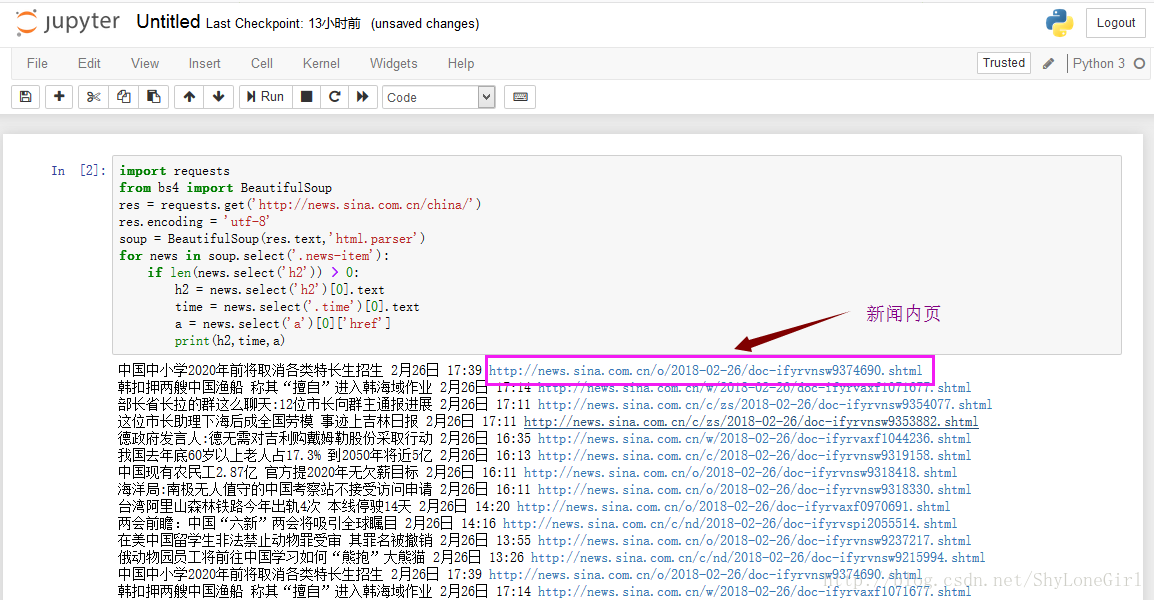
3.5 获取新闻内页的新闻标题,时间,新闻来源
打开上图中的内页链接(因为新闻实时在更新,根据自己情况选择合适新闻页做实验即可),同样上面方法找到我们感兴趣的内容,如图
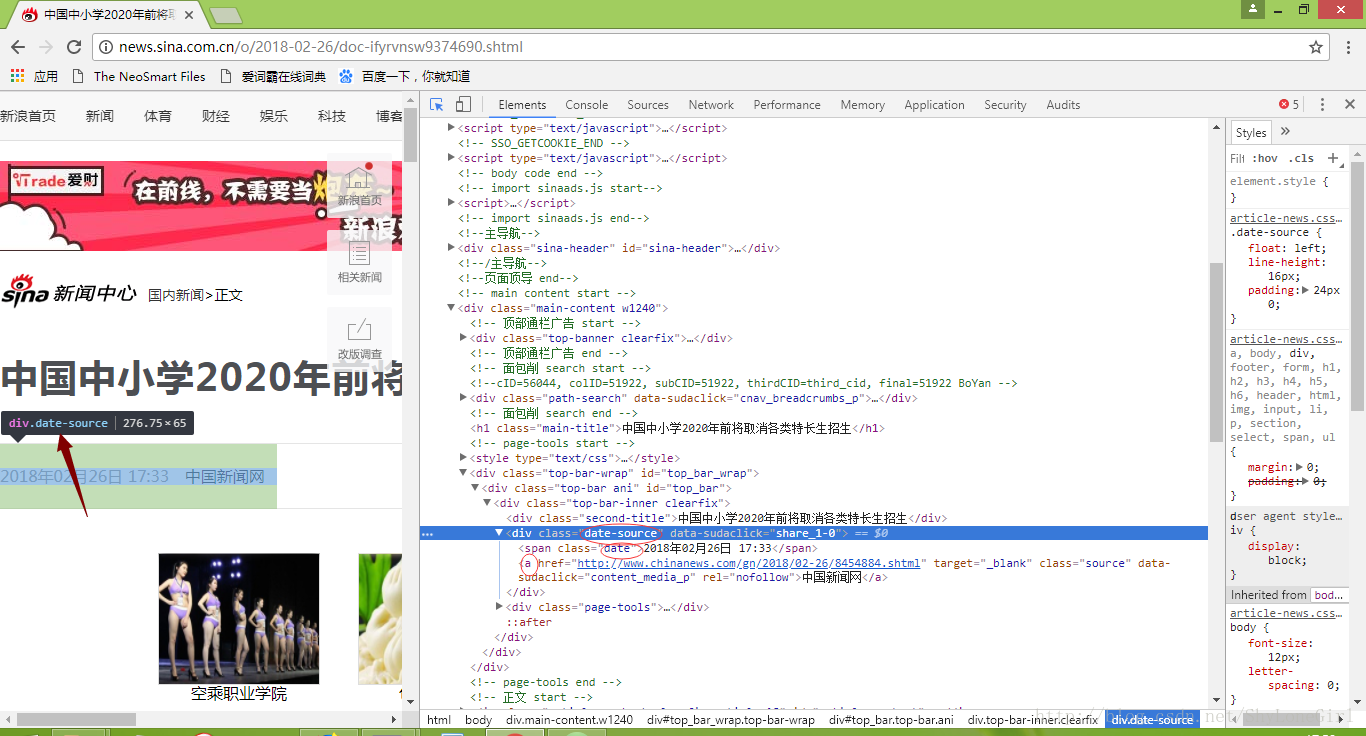
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/o/2018-02-26/doc-ifyrvnsw9374690.shtml')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
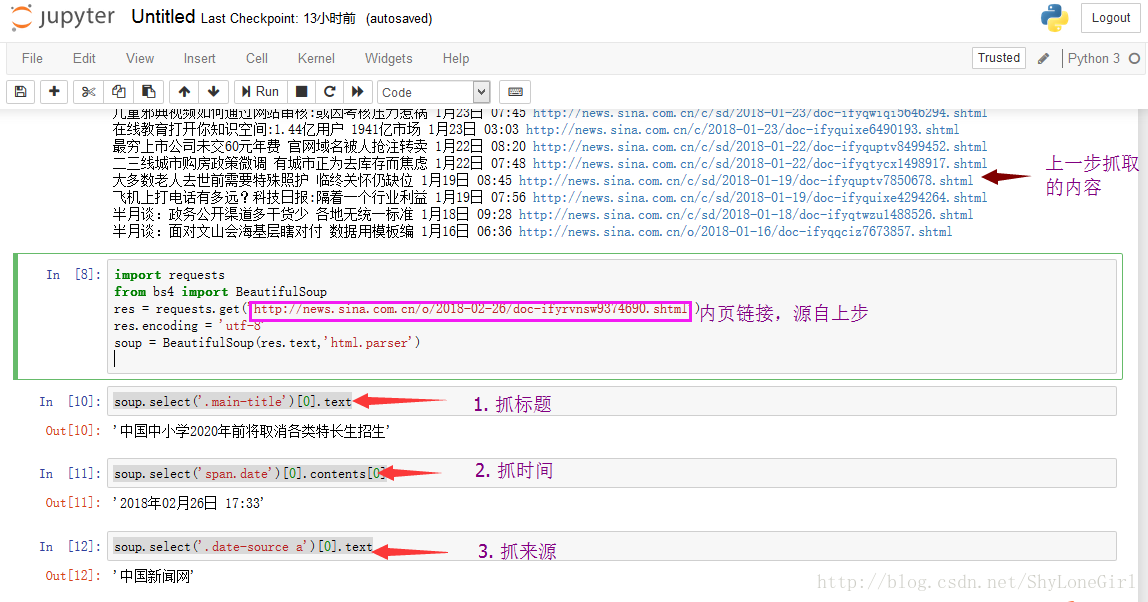
#抓标题
soup.select('.main-title')[0].text
#日期
soup.select('span.date')[0].contents[0]
#来源
soup.select('.date-source a')[0].text
结果如图所示
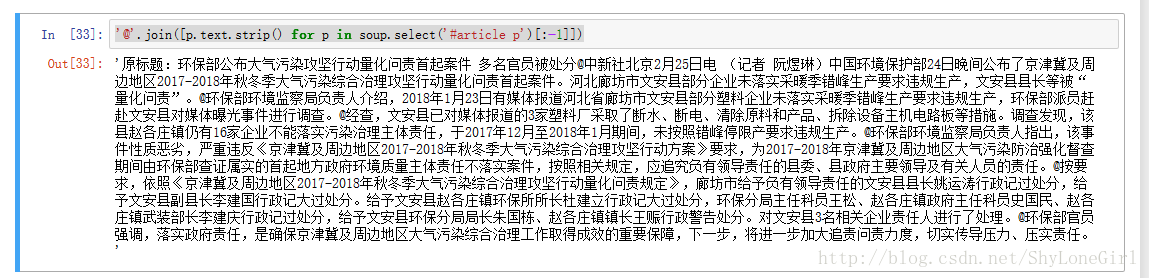
3.6 整理全文内容
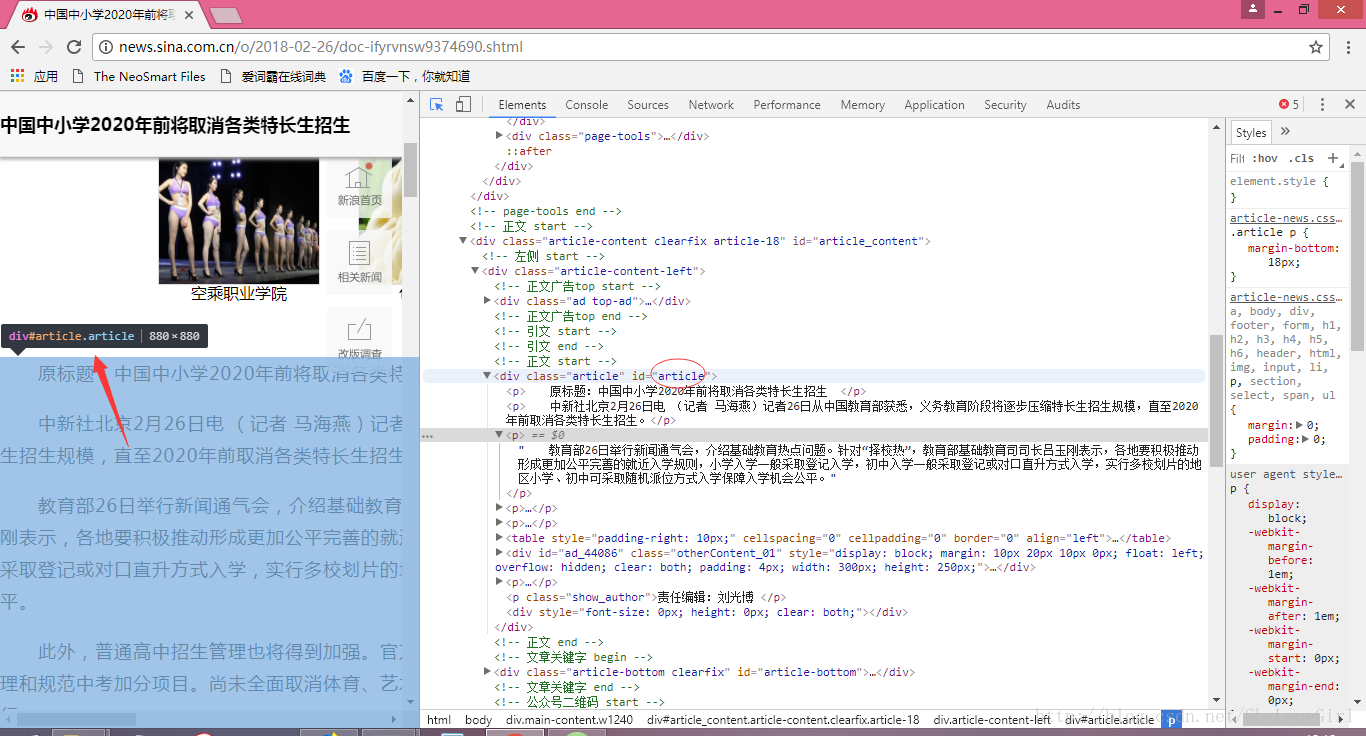
article = []
for p in soup.select('#article p')[:-1]:
article.append(p.text.strip())
print(article)
'@'.join(article)
另一种写法
'@'.join([p.text.strip() for p in soup.select('#article p')[:-1]])
结果
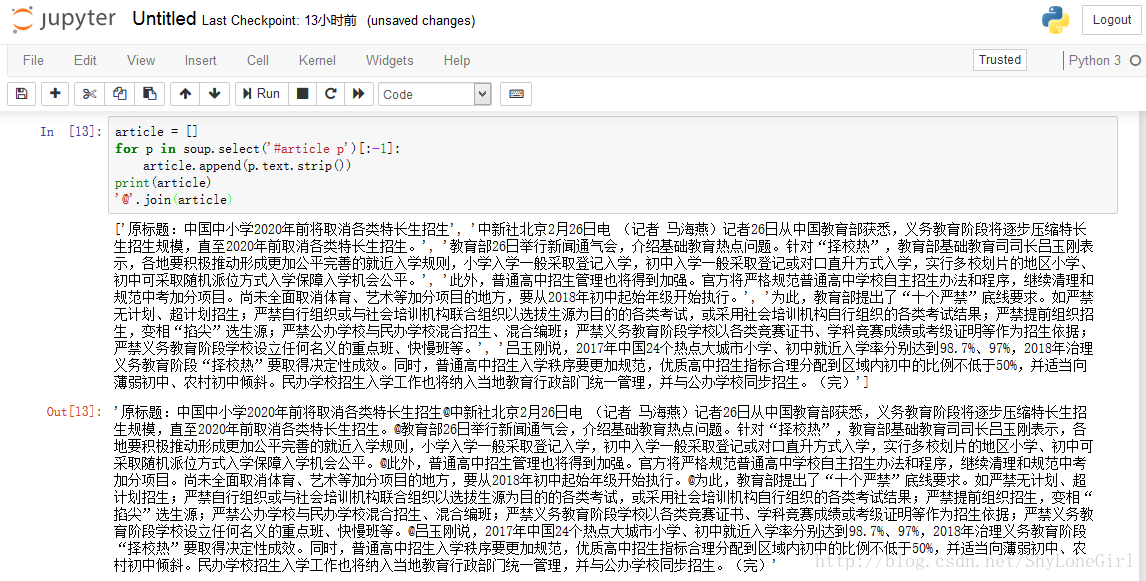
3.7 找作者/编辑
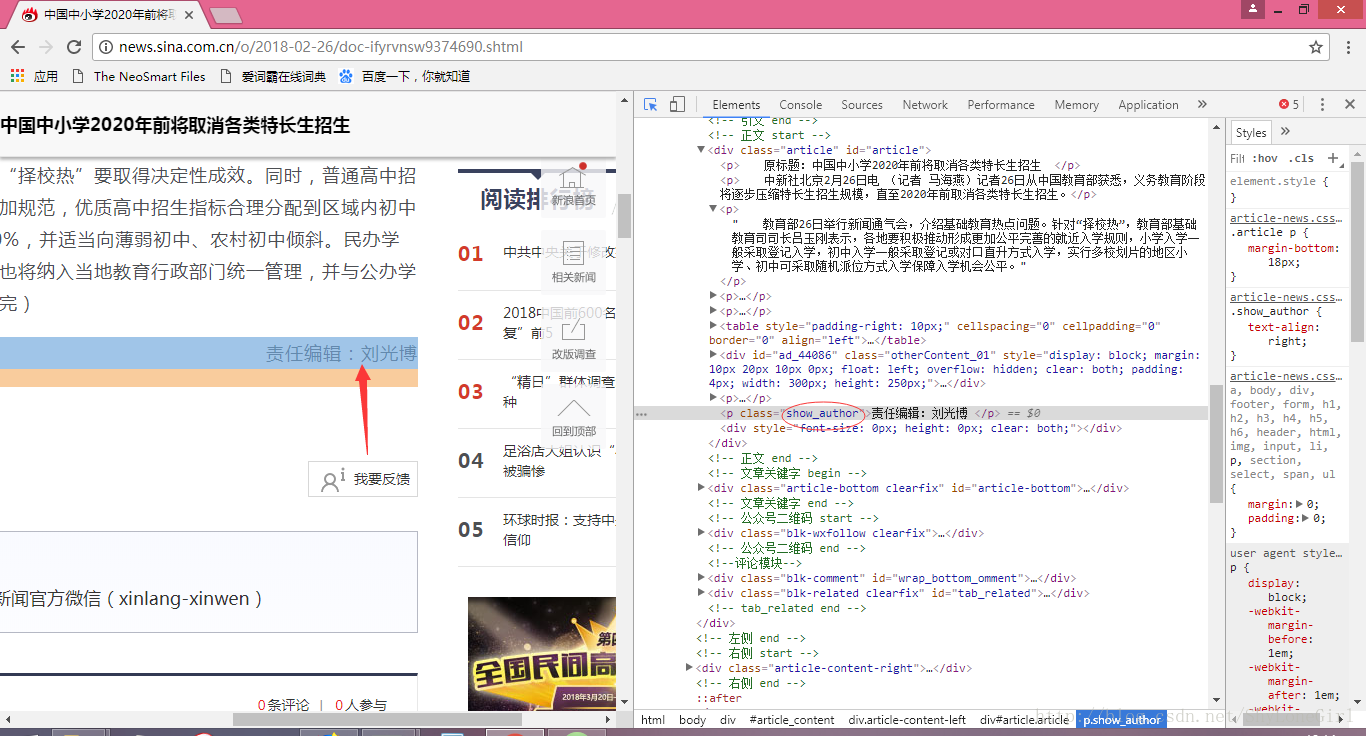
soup.select('.show_author')[0].text.lstrip('责任编辑:')

3.8 评论数儿
评论总数在这里(不好意思,实验网页选的不太好,应该找一个评论数非0的网页)

找到这个链接

import requests
coments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&\
format=json&channel=gn&newsid=comos-fyrvnsw9374690&group=undefined&compress=0&\
ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&callback=jsonp_1519640265968&_=1519640265968')
print(coments.text)
import json
jd = json.loads(coments.text.strip('jsonp_1519640265968(').rstrip(')'))
jd['result']['count']['total']
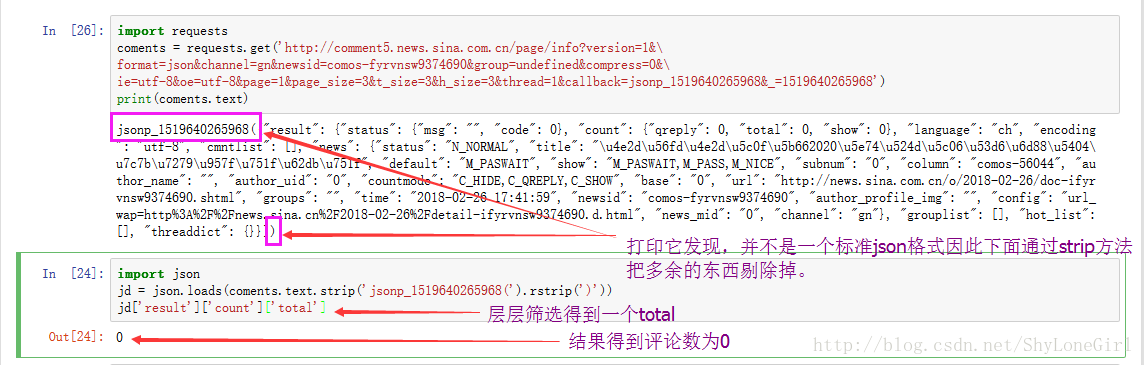
3.9 提取新闻标识符
我们从新闻内页的开发者监视窗口发现,这两个地址有相似之处。
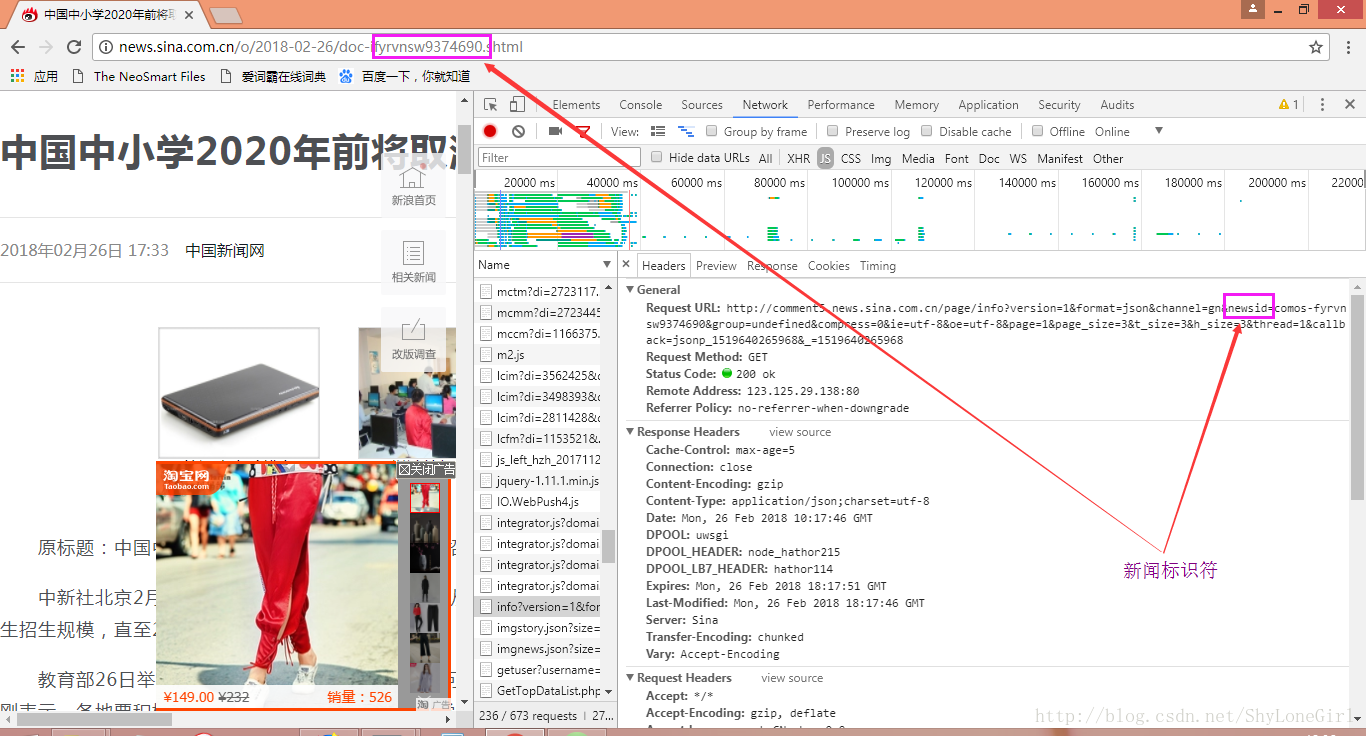
这部分内容就是每条新闻的标识。
newsurl = 'http://news.sina.com.cn/c/nd/2018-02-24/doc-ifyrvnsw9374690.shtml'
newsurl.split('/')[-1].strip('doc-i').rstrip('.shtml')
# coments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&\
# format=json&channel=gn&newsid=comos-fyrvnsw9374690&group=undefined&compress=0&\
# ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&callback=jsonp_1519640265968&_=1519640265968')
comentURL = 'http://comment5.news.sina.com.cn/page/info?version=1&\
format=json&channel=gn&newsid=comos-{}&group=undefined&compress=0&\
ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&\
callback=jsonp_1519551354078&_=1519551354078'
comentURL.format(newsid)
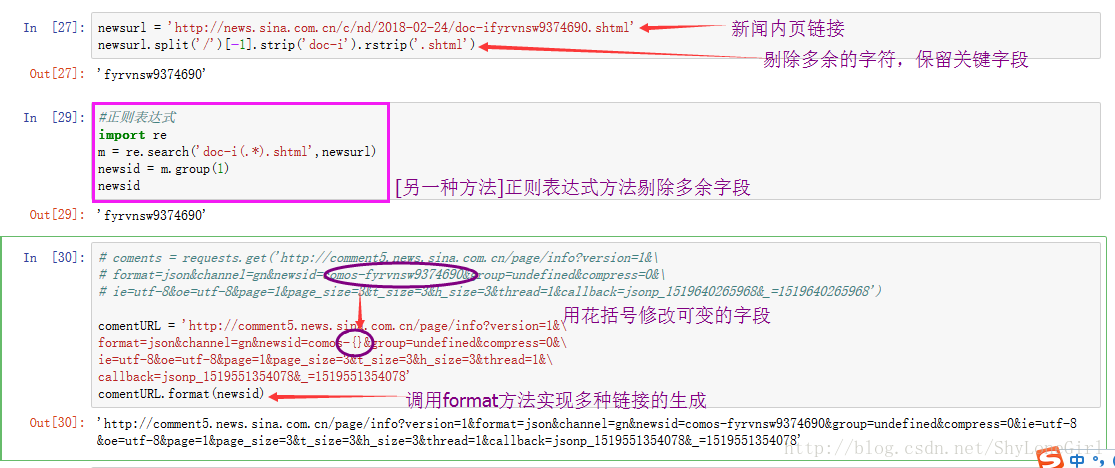
四 完整程序和解释
由于一些不知名原因(猜测可能是对请求频率的限制或者网络通畅)导致抓取新闻内页信息并不是很理想,可能耗时较长或者程序报错。对此还会继续改进代码。因此在程序后部分程序块1部分是我们想要的结果(但存在问题,不过每次执行到print(newsdetails)会看到已经爬到内页数据了),测试使用程序块2中,get到所有的链接。
最后使用pandas套件整理数据,在同级目录下生成Excel文件。
import requests
import re
import json
import pandas
from bs4 import BeautifulSoup
from datetime import datetimedef getNewsDetail(newsurl):result = {}res = requests.get(newsurl)res.encoding = 'utf-8'soup = BeautifulSoup(res.text,'html.parser')result['title'] = soup.select('.main-title')[0].textresult['newssource'] = soup.select('.date-source a')[0].contents[0]timesource = soup.select('span.date')[0].textresult['dt'] = datetime.strptime(timesource,'%Y年%m月%d日 %H:%M')result['article'] = '@'.join([p.text.strip() for p in soup.select('#article p')[:-1]])result['editor'] = soup.select('.show_author')[0].text.lstrip('责任编辑:')result['comments'] = getCommentCounts(newsurl)return resultcomentURL = 'http://comment5.news.sina.com.cn/page/info?version=1&\
format=json&channel=gn&newsid=comos-{}&group=undefined&compress=0&\
ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&\
callback=jsonp_1519551354078&_=1519551354078'def getCommentCounts(newsurl):m = re.search('doc-i(.*).shtml',newsurl)newsid = m.group(1)coments = requests.get(comentURL.format(newsid))jd = json.loads(coments.text.strip('jsonp_1519551354078(').rstrip(')'))return jd['result']['count']['total']res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')newsdetails = []
news_total = []#-----------------1-----------------
# for news1 in soup.select('.news-item'):
# if len(news1.select('h2')) > 0 :
# a = news1.select('a')[0]['href']
# newsdetails.append(getNewsDetail(a))
# newsary = getNewsDetail(a)
# news_total.extend(newsdetails)
# print(newsdetails)
#-----------------1-----------------#-----------------2-----------------
for news1 in soup.select('.news-item'):if len(news1.select('h2')) > 0 :a = news1.select('a')[0]['href']ah2 = {}ah2['title'] = news1.select('h2')[0].textah2['url'] = news1.select('a')[0]['href']newsdetails.append([a])newsary = ah2news_total.extend([ah2])
#-----------------2-----------------df = pandas.DataFrame(news_total)
df.to_excel('news.xlsx')
print(df)
说明
· 同时作为初学者水平有限疏漏之处在所难免,欢迎大家批评指正和交流。
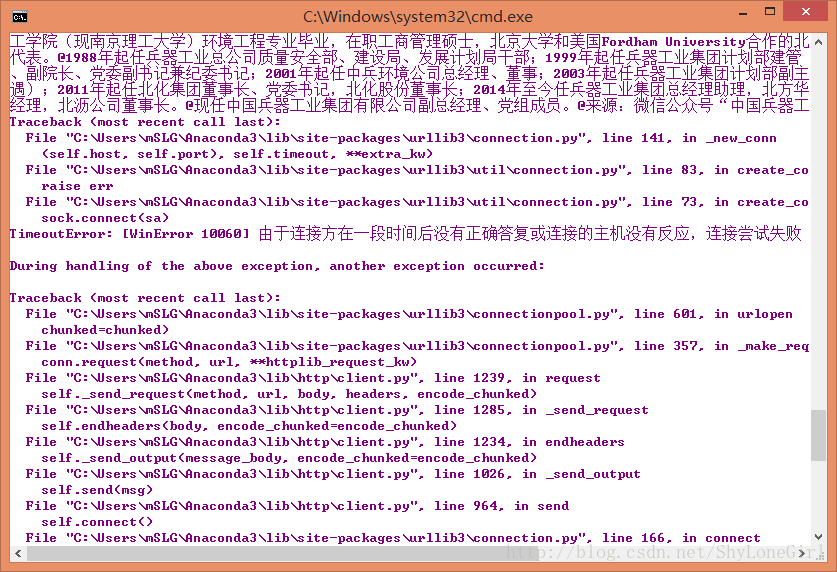
· 四中存在的问题正在积极排查原因和探索解决方法,希望解决过此类问题的高手不吝赐教。如图
---希望对你有帮助





