关于大数据时代的数据挖掘
(1)为什么要进行数据挖掘:有价值的数据并不在本地存储,而是分布在广大的网路世界,我们需要将网络世界中的有价值数据挖掘出来供自己使用
(2)非结构化数据:网络中的数据大多是非结构化数据,如网页中的数据都没有固定的格式
(3)非结构化数据的挖掘--ETL:即三个步骤,分别是抽取(extract)、转换(transformation)、存储(loading),经过这三个步骤后的数据才可以取用
关于网络爬虫
(1)可以从各大网站爬取大量数据,并进行结构化,最后存储在本地数据库,供我们自己索引使用
(2)网络爬虫构架:
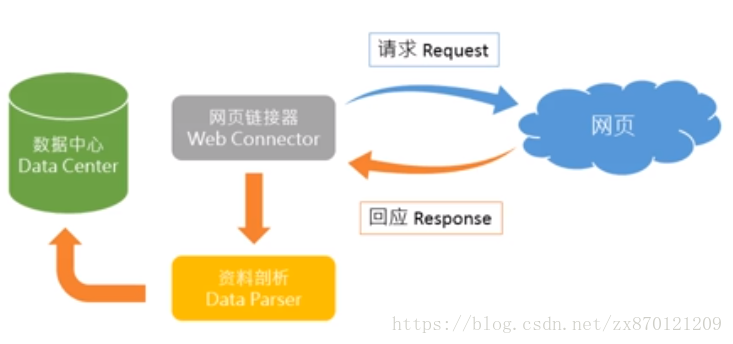
比如自己电脑上的浏览器就是网页连接器,一个网站的网页就是网页适服器,在浏览器中输入该网站的网址,就是向网页适服器发送请求,网页适服器将页面在浏览器中显示就是给的回应,网络爬虫通过网页适服器给出的回应,找到相关数据进行爬取,并对这些数据进行剖析,得到结构化数据资料,最后存储在数据中心以备使用
关于网络爬虫的一个实战(新闻资讯爬取)
项目描述:通过python网络爬虫爬取新浪网上国内新闻栏中的所有新闻资讯,内容包括各大新闻的标题、新闻来源、时间、文章内容、编辑以及评论数,最后做成表格的形式存于excel表格中
项目工具:python,谷歌浏览器
所需模块:request、re、BeautifulSoup4、datetime、json
具体步骤:
(1)观察网页:打开新浪网国内新闻页面http://news.sina.com.cn/china/。在页面空白处点击右键,点选最下方的“检查”选项,出现当前网页的开发人员工具查看界面,其中的“network”栏可以当作我们的“监听器”,可以查看当前页面中网页适服器返回的回应内容,回应内容分为很多类,如JS是Javascripts做成的内容,CSS是网页装饰器,doc是网页文件内容等等,这里我们要抓取的新闻资讯一般是放在doc中的,找到doc类型中的名为china的文件就是我们要找的国内新闻所在,其内容在“response”回应中可以找到。
(2)获取网页整体资源--request:request模块是用于获取网络资源的模块,可以使用REST操作,即post、put、get、delete等操作对网络资源进行存取。读取一个网页的网络资源的简单代码如下:
import requests
newsurl = 'http://news.sina.com.cn/china/'
res = requests.get(newsurl)
res.encoding = 'utf-8'
print(res.text)
其中res.encoding = 'utf-8'是将编码格式转变成中文格式,res.text是显示所获取的资源的内容
(3)获取细节资源--BeautifulSoup4:BeautifulSoup4模块可以按照Document Object Model Tree对获取的网络资源进行分层,然后通过select方法对各个层次中的细节资源进行获取。Document Object Model Tree图形如下:

使用BeautifulSoup4取出网络资源,以便于从中再取出细节内容:
import requests
from bs4 import BeautifulSoup
newsurl = 'http://news.sina.com.cn/c/2018-08-14/doc-ihhtfwqq9509421.shtml'
res = requests.get(newsurl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text)
print(soup.text)
这里说明一下res.text和soup.text的区别,前者中res是网页回应内容,text是取出这个网页回应的所用内容,而后者中soup是BeautifulSoup对象,这里的text是去掉回应内容中的标签,如<html></html>
(4)BeautifulSoup的select方法:可以针对不同的标签来取出标签中的内容
1.找出含有h1标签的元素:
soup = BeautifulSoup(html_sample)
header = soup.select('h1')
print(header)
2.找出含有a标签的元素:
soup = BeautifulSoup(html_sample)
alink = soup.select('a')
print(alink)
3.找出id为title的元素:
soup = BeautifulSoup(html_sample)
title = soup.select('#title')
print(title)
4.找出class为link的元素:
soup = BeautifulSoup(html_sample)
link = soup.select('.link')
print(link)
5.获取一个元素中的属性--获取一个超链接中的herf属性的内容
soup = BeautifulSoup(html_sample)
alink = soup.select('a')
for link in alink:
print(link['herf'])
BeautifulSoup的select方法获取的内容是列表形式,如果要对其内容进行操作,必须要将列表元素拿出来,如要获取class为link的元素中文字内容,则可以使用print(link[0].text)
(5)制作一个简单的爬虫
首先,进入新浪新闻网国内新闻页面,进入该页的开发人员界面,随意查看一条新闻的元素,可以发现这些新闻都是位于一个class为news-item的<div>内,所以选择这个class,对其中的内容进行遍历即可得到所有的新闻的内容
然后,查看每一条新闻的具体内容,其中题目位于h2标签中,时间有class='time'标记,网址在第一个a标签中
最后,通过这些标签对所有具体内容进行筛选。代码如下:
import requests
from bs4 import BeautifulSoup
url = 'http://news.sina.com.cn/china/'
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text)
# print(soup)
for new in soup.select('.news-item'):
if len(new.select('h2')) > 0:
h2 = new.select('h2')[0].text
time = new.select('.time')[0].text
a = new.select('a')[0]['href']
print(h2, time, a)
得到的结果如下:
一图读懂:多方整治“天价片酬” 演员最高拿多少? 8月15日 09:12 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3527505.shtml 上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml 上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml 上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml 中国核潜艇极限长航背后:艇员出航前写遗书拍遗像 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3450991.shtml 天津村庄遭龙卷风侵袭 砖房被吹塌大树拦腰折断 8月15日 08:54 http://slide.news.sina.com.cn/c/slide_1_86058_311891.html 珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml 珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml 众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml 众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml 今天是日本战败投降纪念日:当年日本曾想靠它翻盘 8月15日 08:21 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3417423.shtml 港媒:若美台不理“不得”警告 大陆将以行动说话 8月15日 08:19 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3399386.shtml 进口博览会期间上海将对网约车实行临时价格干预 8月15日 08:15 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3178883.shtml 台“皮带大王”厦门公司倒闭拍卖 员工拿千万欠薪 8月15日 08:11 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193973.shtml 张广宁任广东肇庆市委副书记(图/简历) 8月15日 07:59 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193541.shtml