原文链接:http://www.nicemxp.com/articles/11
本文目的抓取腾讯新闻首页中要闻页签下的所有新闻标题和链接。
如图:

地址:http://news.qq.com/top_index.shtml
要闻页签中一般会有几个分页:

所以要爬取要闻下的所有新闻标题和链接就需要一个一个分页的爬取。下面开始写代码。
首先获取腾讯新闻页面内容,写一个获取页面的接口。
先导入本次抓取所必备的库
# -*- coding:utf-8 -*-#Python抓取网页必备的库
import urllib
import urllib2
#正则表达式
import re
#随机数生成
import random
#gzip
import gzip
from StringIO import StringIO构建请求头部,请求页面
#构建页面请求的头部
headers = {'User-Agent':user_agent, "Referer":referer}
#构建页面请求
request = urllib2.Request(url, headers=headers)
#请求目的页面,设置超时时间为45秒
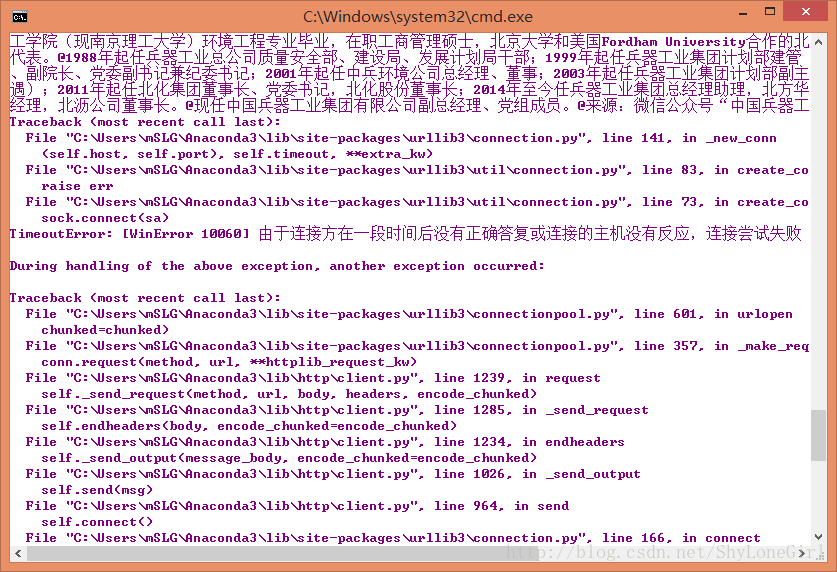
response = urllib2.urlopen(request, timeout = 45)请求腾讯新闻页面,返回的页面数据有时会经过gzip压缩,如果直接读取会出现二进制码,所以在处理返回的页面时需要做gizp解压的处理
#如果经过gzip压缩则先解压,否则直接读取
if response.info().get('Content-Encoding') == 'gzip':buf = StringIO(response.read())f = gzip.GzipFile(fileobj=buf)html = f.read()
else:html = response.read()
整理代码段,最后封装成页面请求接口
#user-agent
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"#抓取页面接口,参数为地址和referer
def getHtml(url, referer = None):try:#构建页面请求的头部headers = {'User-Agent':user_agent, "Referer":referer}#构建页面请求request = urllib2.Request(url, headers=headers)#请求目的页面,设置超时时间为45秒response = urllib2.urlopen(request, timeout = 45)html = None#如果经过gzip压缩则先解压,否则直接读取if response.info().get('Content-Encoding') == 'gzip':buf = StringIO(response.read())f = gzip.GzipFile(fileobj=buf)html = f.read()else:html = response.read()return html#如果请求异常except urllib2.URLError, e:if hasattr(e, "code"):print e.codeelif hasattr(e, "reason"):print e.reasonreturn None#其他异常except Exception,e:return None页面请求接口写好后,接下来分析如何要闻页签下的所有数据,要闻页签下有几个分页,当我们在请求分页时可以看出腾讯要闻分页的请求时通过ajax实现的,打开Google浏览器的network,可以看到请求分页时的信息。如图:
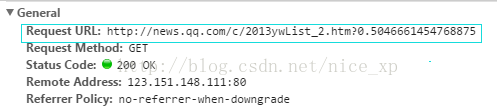
分析请求地址会发现,每一次的分页请求都是一个地址后面加上一个随机数,而地址中会有本次请求的索引。
这样我们就可以构建分页的请求地址,获取每个分页的信息。但是在这之前我们不清楚腾讯要闻中会有多少个分页。
分析腾讯新闻的页面,我们最后会发现首页中的一段js标出了腾讯要闻中有多少分页。

因此我们首先抓取腾讯新闻页面内容,获取到要闻有多少分页,在构建分页请求,最后取出页面信息中所有的新闻
标题和原文链接就好了。代码如下:
def tencentStart():#腾讯新闻地址INDEX_URL = 'http://news.qq.com/top_index.shtml#hotnews'#腾讯要闻请求地址SUB_URL = "http://news.qq.com/c/2013ywList_{0}.htm"#页面数获取正则PAGE_PATTERNS = 'getString.pageCount.*?=.*?(\d+);'#标题和链接获取正则NEWS_PATTERNS = '<em.*?<a.*?href="(.*?)".*?>(.*?)</a>.*?</em>'#头部信息相关TENCENT_REFER = "http://news.qq.com/"#获取腾讯新闻页面html = getHtml(INDEX_URL)#取得要闻页面总数pattern = re.compile(PAGE_PATTERNS, re.S)countRe = re.search(pattern, html)if html == None:print("未获取到页面")return Nonecount = 1if countRe != None:count = int(countRe.group(1))#构建分页地址,请求分页数据for index in range(count):realIndex = index + 1#构建地址url = SUB_URL.format(realIndex)+'?'+str(random.random())html = getHtml(url, TENCENT_REFER)if html == None:continue#编译标题和链接获取正则pattern = re.compile(NEWS_PATTERNS, re.S)#获取所有标题和链接Res = re.findall(pattern, html)if Res == None:continue#打印所有标题和链接for item in Res:print(item[0]+"\n")print(item[1]+"\n")if __name__ == '__main__':tencentStart()
最后运行脚本,可以看到打印出的腾讯要闻页签中的所有标题和链接