- 学习资料
IBM SPSS Modeler 18.0 Applications 第4章
- 应用场景
为每个客户提供合适的报价方案以实现更高收益
- 数据源描述
数据源名称pm_customer_train1.sav

- 应用模型
自动分类器
- 分析思路
通过“自动分类器”节点,为标志(例如某个指定客户是否可能拖欠贷款或者是否对特定的报价做出响应)或名义(集合)目标自动创建多个不同的模型并进行比较排序,选择最有效的模型,然后将它们合并为一个汇总(整体)模型。此方法将自动化操作的方便性与组合多个模型的优势融为一体,从而产生任何单一模型所不能带来的更为准确的预测。
- 设计步骤
1、选取源节点“Statistics文件”,读取外部数据源;
Variable names选择Read names and labels
Values选择Read data and labels

2、添加类型节点
把response的Role设置为Target(输出/目标),Measurement(数据类型)设置为Flag(标志),
把campaign的Role设置为input(输入/预测变量),Measurement(数据类型)设置为Nominal(名义),
对于下列字段,将Role设置为无:CMSomer_id、response_date、purchase、purchase_date、product_id、Rowid 和 X_random(当构建模型时,将忽略这些字段),
其它字段保持不变,
接着点击Read Valuse读取值。

3、定义标签
在campaign字段的行上单机Values列的条目,在下拉列表中选择specify…(指定…),在弹出的指定窗口上,输入设置campaign字段4个值分别对应的标签,点击确定后,就可以通过点击显示字段和值标签工具栏按钮在输出窗口中显示标签



4、为单项活动筛选记录
尽管数据包含有关四项不同活动的信息,但每一次的分析应侧重于其中一项活动。由于 Premium account活动(在数据中编码为 campaign=2)中的记录数最大,因此可以使用Select选择节点实现仅在流中包含这些记录。

5、
附加一个自动分类器节点,然后选择总体准确性作为对模型进行排序的度量,
将要使用的模型数设置为 3,这意味着在执行节点时将构建三个最佳模型,
在“专家”选项卡上,可从最多11种不同模型算法中进行选择,由于在“模型”选项卡上将要使用的模型数设置为 3, 因此节点将计算11个算法的准确性, 并构建包含三个最准确算法的单个模型块。

在“设置”选项卡上, 对于整体方法,选择置信度加权投票(还可以选择最初倾向加权投票/最高置信度当选/平均原始倾向)。此选项确定如何为每条记录生成一个汇总评分。
- 置信度加权投票
置信度即可靠度,对结果有多少信心保证是正确的概率
使用简单投票方式时,若三个模型中有两个模型均预测“是”,则“是”将以 2 比 1 的投票结果取胜。在使用
置信度加权投票方式时,将基于各模型预测的置信度值进行加权投票。因此,如果一个预测“否”的模型的置信度比另外两个预测的模型“是”合在一起的置信度还高,则“否”取胜。
- 最高置信度当选
使用最高置信度当选方式时,在各模型中,预测的置信度值最高的模型取胜。因此还是上面的例子,如果一个预测“否”的模型的置信度比另外两个预测的模型“是”的置信度都高,则“否”取胜。
- 最初倾向加权投票
倾向评分指特定结果或响应的可能性,倾向评分仅适用于有标志目标的模型,并且指示为字段定义的值为真的可能性
计算原始倾向评分,然后基于各模型预测的倾向评分进行加权投票。因此还是上面的例子,如果三个模型预测“是”的倾向评分之和,大于预测“否”的倾向评分之和,则“是”取胜。
- 平均原始倾向
计算原始倾向评分平均值。因此还是上面的例子,如果三个模型预测“是”的倾向评分的平均值,大于预测“否”的倾向评分的平均值,则“是”取胜。
 6、运行
6、运行

- 结果分析与评估
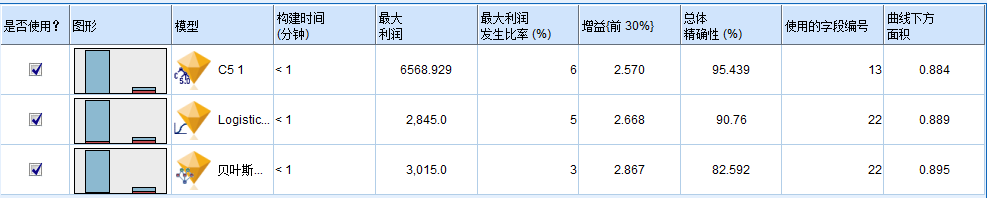
默认情况下, “自动分类器”节点的“模型”选项卡中选择了总体准确性度量,因此模型将根据此度量进行排序。(还可以选择曲线下面积/利润/增益/字段数)根据这一度量,C51 模型的精确性最高,但 C&R 树和 CHAID 模型的精确性与之相差不大。基于这些结果,您可以决定使用所有这三个最准确的模型。通过结合多个模型的预测,可以避免单个模型的局限性,从而使总体准确性更高。
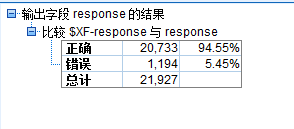
在模型块后面连接一个“分析”节点。右键单击分析节点,然后选择运行以运行流。由整体模型生成的汇总评分将显示在名为 SXF-response的字段中。根据训练数据进行度量时, 预测值与实际响应(如原始响应字段中的记录所示)相匹配的总体准确性为 92.82%。尽管该准确性低于此个案的三个模型中的最高准确性(C51 为 92.86%),但它们之间的差异非常小,可以忽略不计。一般来说, 在应用到除训练数据之外的数据集时, 整体模型通常更可能具有良好效果。基于总体准确性,“C51”、“C&R 树”和 CHAID 模型对于训练数据效果最佳。

- 补充
上面设计输入模型的记录都是campaign=2时的记录,当我们想把全部记录作为输入的时候,可以在上面的实验中把campaign的Measurement(数据类型)设置为拆分,那么自动分类器将为每个分割(campaign=1、campaign=2、campaign=3、campaign=4)构建模型