目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据爬取及处理
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
前段时间,博主分享过关于一篇使用协同过滤算法进行智能电影推荐系统的博文《基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集》,有读者反映该项目有点复杂,于是我决定再给大家分享个使用机器学习算法简单实现电影推荐的项目。
本项目基于Movielens数据集,采用协同过滤、矩阵分解以及建立LDA主题模型等机器学习算法,旨在设计和训练一个合适的智能电影推荐模型。最终的目标是根据电影的相似性以及用户的历史行为,生成一个个性化的电影推荐列表,从而实现网站为用户提供精准电影推荐的功能。
首先,项目收集了Movielens数据集,其中包含了大量用户对电影的评分和评论。这个数据集提供了有关用户和电影之间互动的信息,是推荐系统的核心数据。
然后,项目使用协同过滤算法,这可以是基于用户的协同过滤(User-Based Collaborative Filtering)或基于item的协同过滤(Item-Based Collaborative Filtering)。这些算法分析用户之间的相似性或电影之间的相似性,以提供个性化推荐。
此外,矩阵分解技术也被应用,用于分解用户-电影交互矩阵,以发现潜在的用户和电影特征。这些特征可以用于更准确地进行推荐。
另外,项目还使用了LDA主题模型,以理解电影的主题和用户的兴趣。这有助于更深入地理解电影和用户之间的关联。
最终,根据电影的相似性和用户的历史行为,系统生成了一个个性化的电影推荐列表。这个列表可以根据用户的兴趣和偏好提供电影推荐,从而提高用户体验。
总结来说,这个项目结合了协同过滤、矩阵分解和主题建模等技术,以实现一个个性化电影推荐系统。这种系统有助于提高用户在网站上的互动和满意度,同时也有助于电影网站提供更精准的内容推荐。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
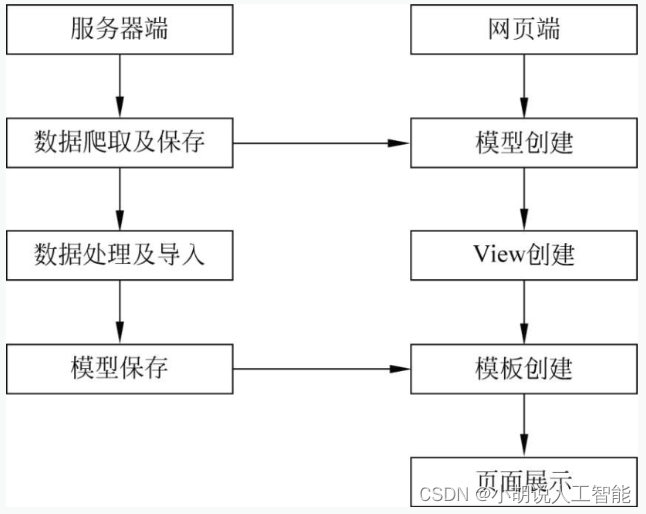
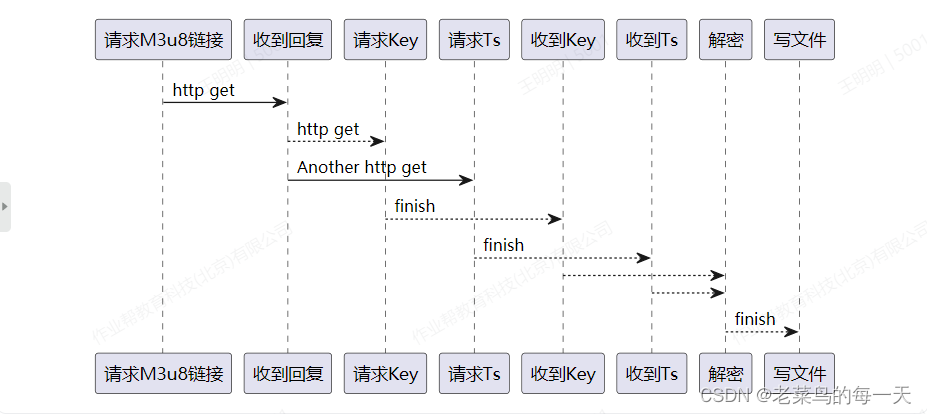
系统流程图
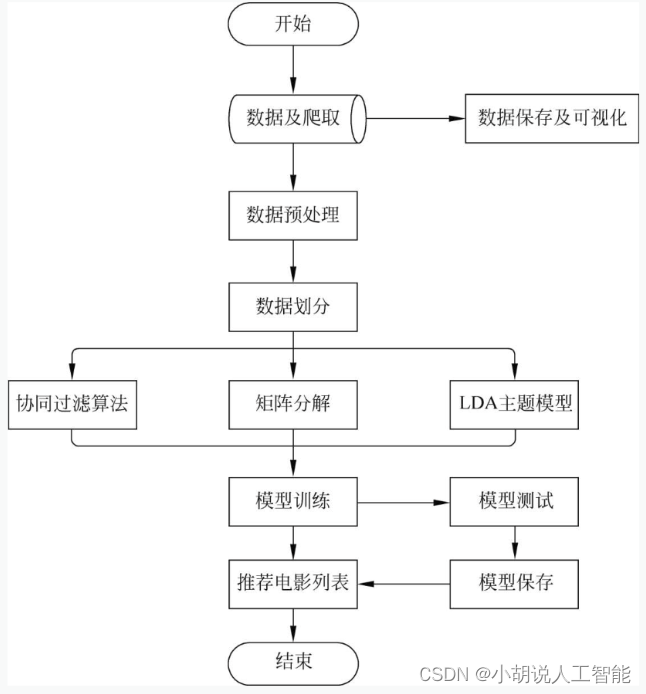
系统流程如图所示。
运行环境
本部分包括 Python 环境、Pycharm 环境及数据库环境。
详见博客。
模块实现
本项目包括5个模块:数据爬取及处理、模型训练及保存、接口实现、收集数据、界面设计。下面分别介绍各模块的功能及相关代码。
1. 数据爬取及处理
在Python环境下执行命令,生成数据库表。
python manage.py makemigrations
python manage.py migrate --run-syncdb
安装所需第三方库。
python -m pip install -r requirement.txt
数据来源:爬取Movielens上相关电影数据、简介及评分。也可以直接从下面网址进行下载:数据集网站地址为http://files.grouplens.org/datasets/movielens/ml-1m-README.txt
python populate_ratings.py
python populate_movie.py
python populate_movie_description.py
python populate_ratings.py
相关代码如下:
#导入需要的库
import os
import urllib.request
import django
import datetime
import decimal
from tqdm import tqdm
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Recs.settings')
django.setup()
from Analytics.models import Rating
#插入评分记录
defcreate_rating(user_id,content_id,rating,timestamp):ating=Rating(user_id=user_id,movie_id=content_id,rating=decimal.Decimal(rating), rating_timestamp=datetime.datetime.fromtimestamp(float(timestamp)))rating.save()return rating
#爬取评分记录
def download_ratings():URL= 'https://raw.githubusercontent.com/sidooms/MovieTweetings/master/latest/ratings.dat'response = urllib.request.urlopen(URL)data = response.read()print('download finished')return data.decode('utf-8')
#删除已有的评分数据
def delete_db():print('truncate db')Rating.objects.all().delete()print('finished truncate db')
def populate():delete_db()ratings = download_ratings()for rating in tqdm(ratings.split(sep="\n")):r = rating.split(sep="::")if len(r) == 4:create_rating(r[0], r[1], r[2], r[3])
if __name__ == '__main__':print("Starting MovieRecs Population script...")populate()
#python populate_movie.py相关代码
#导入需要的库
import os
import urllib.request
from tqdm import tqdm
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Recs.settings')
import django
django.setup()
from Movies.models import Movie, Genre
#创建每一条电影数据并保存
def create_movie(movie_id, title, genres):movie = Movie.objects.get_or_create(movie_id=movie_id)[0]title_and_year = title.split(sep="(")movie.title = title_and_year[0]movie.year = title_and_year[1][:-1]if genres:for genre in genres.split(sep="|"):g = Genre.objects.get_or_create(name=genre)[0]movie.genres.add(g)g.save()movie.save()return movie
#爬取电影数据
def download_movies(URL='https://raw.githubusercontent.com/sidooms/MovieTweetings/master/latest/movies.dat'): #下载电影数据response = urllib.request.urlopen(URL)data = response.read()return data.decode('utf-8')
#如果之前存在数据则先删除
def delete_db():print('truncate db')movie_count = Movie.objects.all().count()if movie_count > 1:Movie.objects.all().delete()Genre.objects.all().delete()print('finished truncate db')
def populate(): movies = download_movies()if len(movies) == 0:print('The latest dataset seems to be empty. Older movie list downloaded.')print('Please have a look at https://github.com/sidooms/MovieTweetings/issues and see if there is an issue')movies = download_movies(
'https://raw.githubusercontent.com/sidooms/MovieTweetings/master/snapshots/100K/movies.dat')print('movie data downloaded')for movie in tqdm(movies.split(sep='\n')):m = movie.split(sep="::")if len(m) == 3:create_movie(m[0], m[1], m[2])
if __name__ == '__main__':print("Starting MovieGeeks Population script...")delete_db()populate()
#python populate_movie_description.py相关代码
#导入需要的库
import os
import django
import json
import pandas as pd
import requests
from tqdm import tqdm
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Recs.settings')
django.setup()
from Recommender.models import MovieDecriptions
#获取电影数据并保存
from Analytics.models import Rating
def get_descriptions_with_movieid(movie_id):url = "https://api.themoviedb.org/3/find/tt{}?external_source=imdb_id&api_key={}"api_key = get_api_key()format_url = url.format(movie_id, api_key)r = requests.get(format_url)for film in r.json()['movie_results']:md = MovieDecriptions.objects.get_or_create(movie_id=movie_id)[0]
#保存电影名md.imdb_id = movie_idif 'title' in film:md.title = film['title']
#保存电影简介if 'overview' in film:md.description = film['overview']
#保存电影类型if 'genre_ids' in film:md.genres = film['genre_ids']if len(md.description) > 0:md.save()# print("{}: {}".format(movie_id, r.json()))
#如果之前存在数据则先删除
def delete_db():print('truncate db')MovieDecriptions.objects.all().delete()print('finished truncate db')
def get_api_key(): #获取API的KEYcred = json.loads(open(".prs").read())return cred['themoviedb_apikey']
#加载评分数据
def load_all_ratings():#提取相关列的数据columns = ['movie_id']ratings_data = Rating.objects.all().values(*columns)movie_ids = pd.DataFrame.from_records(ratings_data, columns=columns)movie_ids = movie_ids.drop_duplicates(subset=None, keep='first', inplace=False)movie_ids = movie_ids.reset_index()return movie_ids
if __name__ == '__main__': #主函数print("Starting MovieRecs Population script...")delete_db()movie_ids = load_all_ratings()movie_ids = movie_ids.iloc[:, 1]for movie_id in tqdm(movie_ids.values):get_descriptions_with_movieid(movie_id)
爬取的数据保存在pgAdmin4中,如图所示。
Python命令行爬取数据成功,如图所示。
相关其它博客
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(一)
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(三)
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。