开发技术
协同过滤算法、机器学习、LSTM、vue.js、echarts、django、Python、MySQL
创新点
协同过滤推荐算法、爬虫、数据可视化、LSTM情感分析、短信、身份证识别
补充说明
适合大数据毕业设计、数据分析、爬虫类计算机毕业设计
介绍
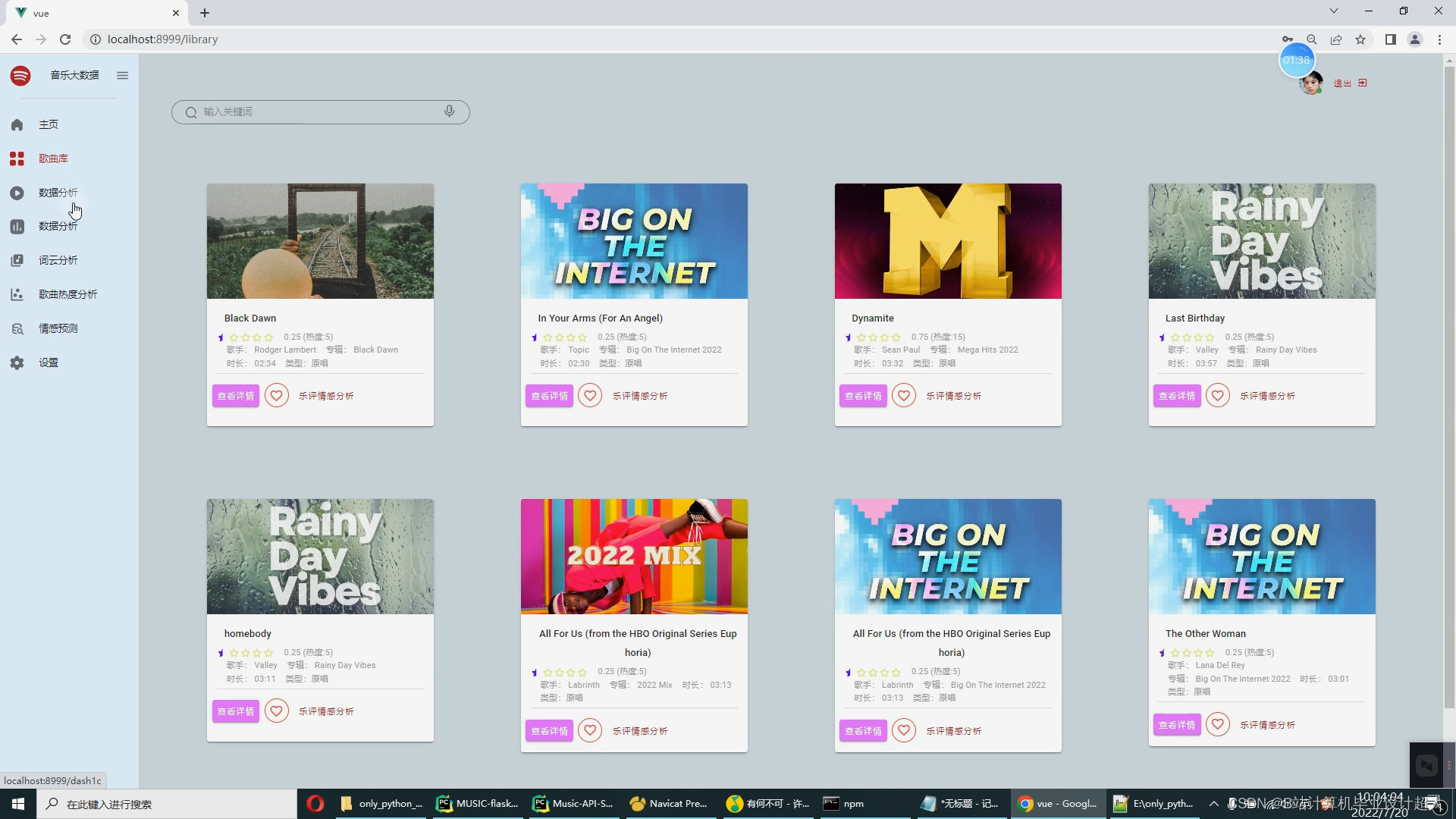
音乐数据的爬取:爬取歌曲、歌手、歌词、评论
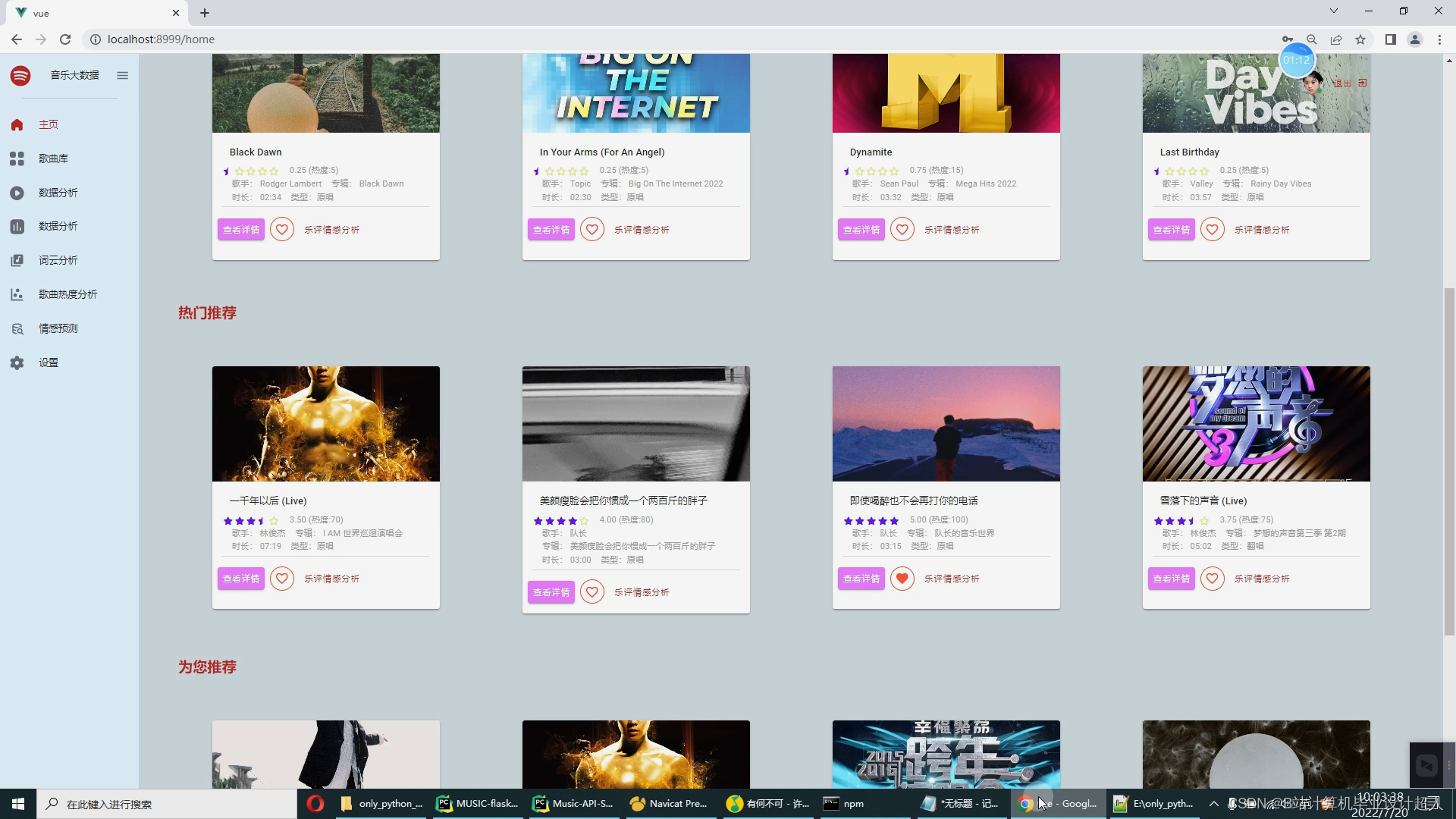
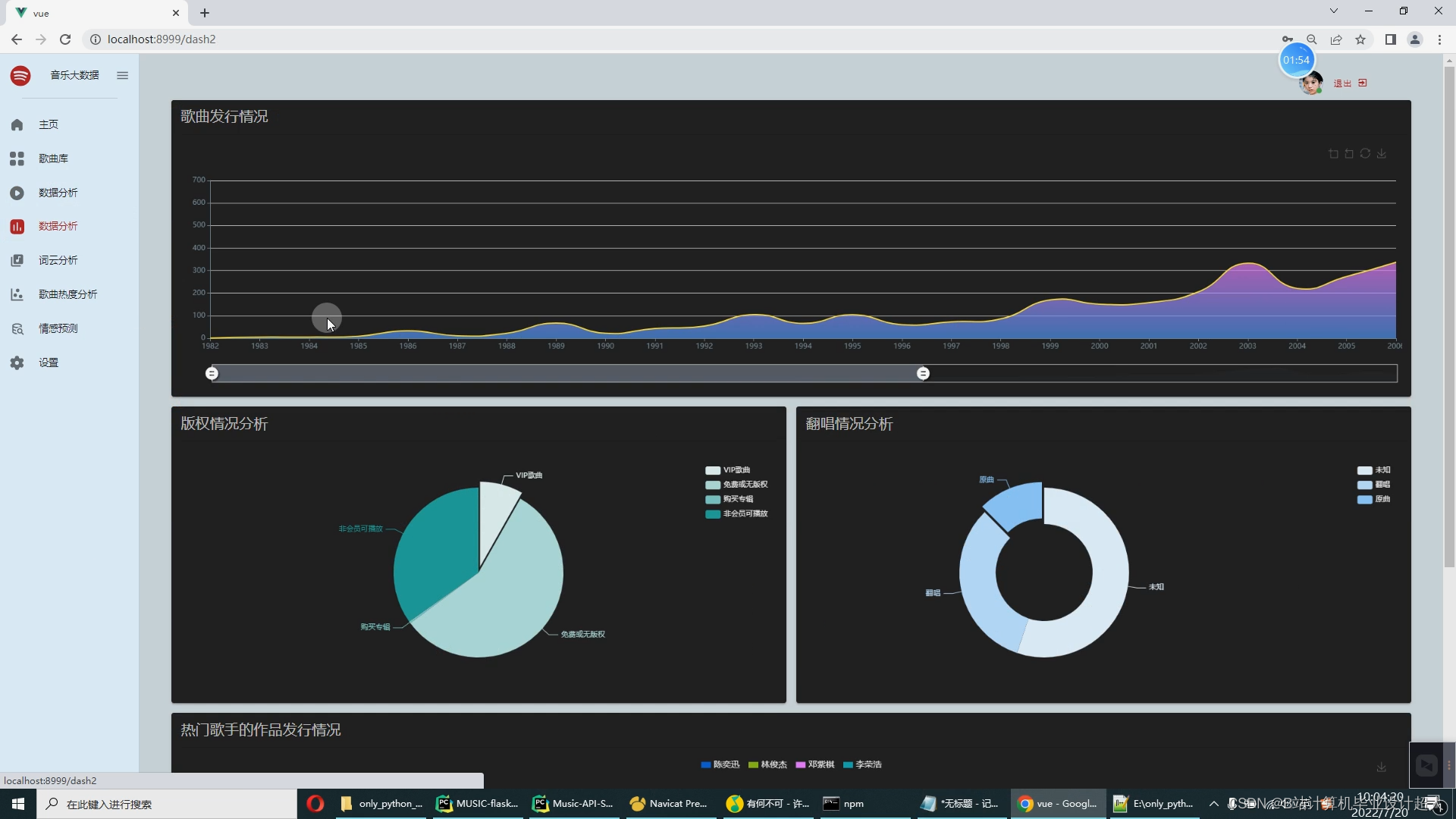
音乐数据的可视化:数据大屏+多种分析图【十几个图】
深度学习之LSTM 音乐评论情感分析
交互式协同过滤音乐推荐: 2种协同过滤算法、通过点击歌曲喜欢来修改用户对歌曲的评分
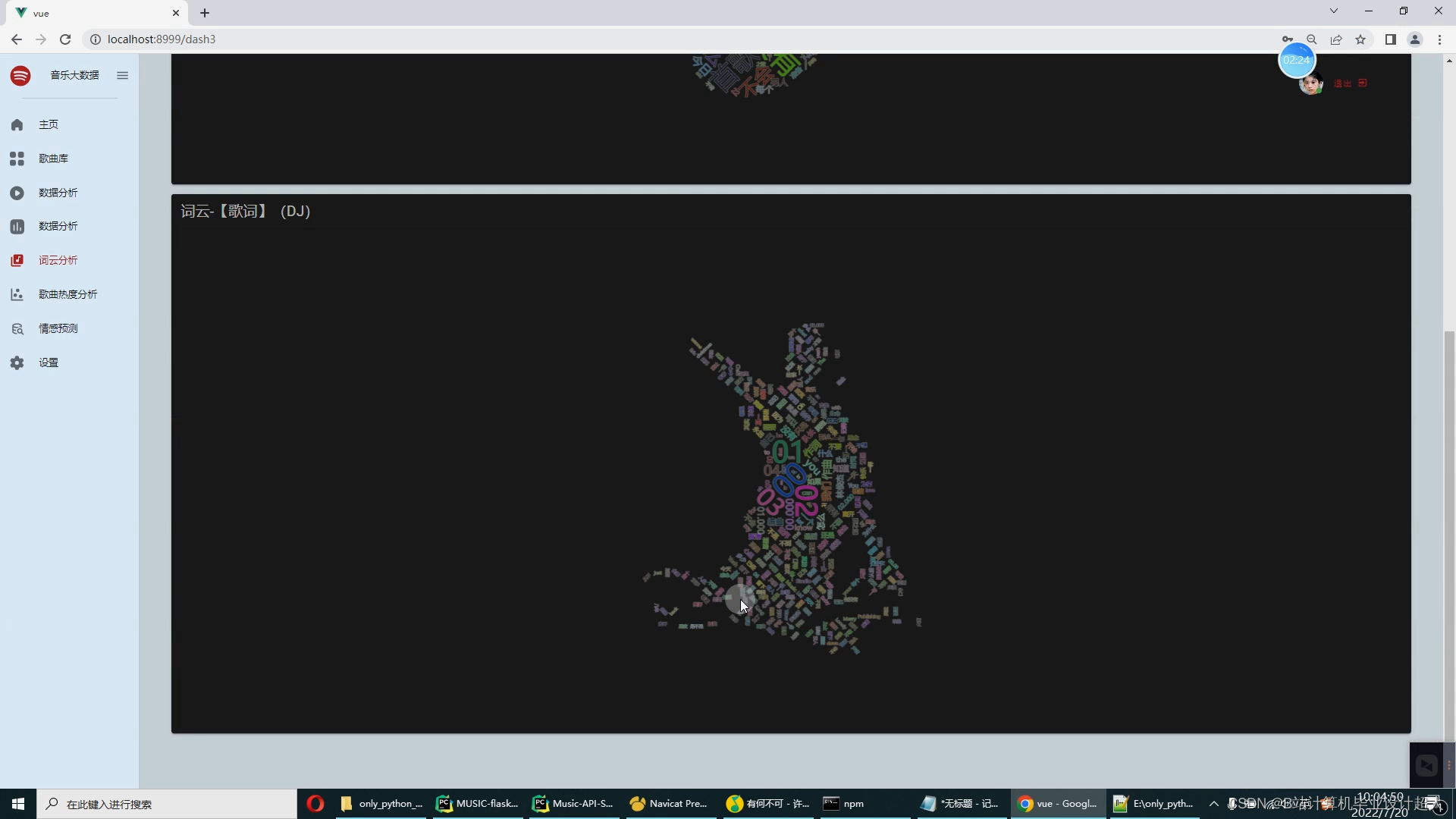
歌词、乐评的词云
登录、注册、修改个人信息等【集成身份证识别、短信验证码等】



黄河科技学院本科毕业设计 任务书
工 学部 大数据与计算机应用 科教中心 计算机科学与技术 专业
2018 级普本1/专升本1班 学号 学生 指导教师
毕业设计题目
基于实时音乐数据挖掘的个性化推荐系统设计与优化
毕业设计工作内容与基本要求(目标、任务、途径、方法,应掌握的原始资料(数据)、参考资料(文献)以及设计技术要求、注意事项等)
一、设计的目标和任务
- 第一部分:爬虫爬取音乐数据(网易云音乐网站),作为测试的数据集。
- 第二部分:离线推荐系统:python+机器学习离线推荐(基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度) ,必要时可以集成算法框架比如tensflow pytroch等,推荐结果通过pymysql写入mysql。同时当出现算法精准度低、计算速度慢时可以优化参数、算法逻辑、数据库索引等提升推荐算法的效率。
- 第三部分:在线应用系统: springboot进行在线推荐 vue.js构建推荐页面(含知识图谱)。
- 第四部分:使用Spark构建大屏统计。
二、设计途径和方法
- Selenium自动化Python爬虫工具采集网易云音乐、评论数据约1000万条存入.csv文件作为数据集;
- 使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs;
- 使用hive数仓技术建表建库,导入.csv数据集;
- 离线分析采用hive_sql完成,实时分析利用Spark之Scala完成;
- 统计指标使用sqoop导入mysql数据库;
- 使用springboot+vue.js+echarts进行可视化大屏开发;
- 使用基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度等算法实现个性化音乐推荐并进行参数优化、算法二次开发升级;
- 使用卷积神经网络KNN、CNN实现音乐流量预测;
- 搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、流量预测界面、知识图谱等实现;
三、应掌握的原始资料和技术
- 前端技术方案:登录vue官网,效仿案例Demo完成基本语法的入门,熟悉后积累本系统需要的开发组件,封装成.vue文件来回复用。学习vue.js前端框架,寻找符合本系统的框架,引入后完成页面开发。
- 后端技术方案:选用Springboot作为后端开发框架,相比SSM简洁高效,语法灵活,更适合小白新手快速入手,如Python开发中的Flask框架一样简单方便;
- 数据库技术方案:去CSDN寻找音乐推荐系统相关的建表经验,以多个系统建表的方案为依托,安装mysql,学习mysql语法,把数据库完整创建好;
- 爬虫技术方案:使用网易云代理站点完成数据爬取,包括音乐信息、评论、歌词等,主要运用Python爬虫技术,包括selenium、requests等;
- 推荐算法技术方案:充分研究协同过滤算法基于用户、基于物品两种实现,以及算法冷却问题,使用Python熟悉算法的调用过程,把调用代码集成到系统中,实现个性化音乐推荐.同时对算法参数、工作逻辑进行优化提升推荐效率;
(六)大数据技术方案:搭建hadoop、spark、hive大数据环境,进行数据可视化分析;
四、进度安排
第1周:查阅相关资料,完成文献综述。
第2周:结合课题要求,提交开题报告,并完成开题答辩。
第3~5周:进行系统分析、总体设计和详细设计。
第6~9周:实现系统编码、调试及软件测试。撰写毕业设计。
第10~12周:修改毕业设计至定稿,资格审查。
第13~14周:毕业设计答辩及资料归档。
核心算法代码分享如下:
package com.sqlimport org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.junit.Testimport java.util.Propertiesclass MusicSpark2024_FixBug {val spark = SparkSession.builder().master("local[6]").appName("音乐数据实时计算V1.0").getOrCreate()//歌曲数仓CSV 模式val ods_songs_Schema = StructType(List(StructField("id", IntegerType),StructField("songId", StringType),StructField("songName", StringType),StructField("alia",StringType),StructField("pic", StringType),StructField("singerId", StringType),StructField("singerName",StringType),StructField("albumId", StringType),StructField("albumName", StringType),StructField("dt", StringType),StructField("pop", IntegerType),StructField("fee", IntegerType),StructField("mv", StringType),StructField("cd", IntegerType),StructField("no", IntegerType),StructField("originCoverType", IntegerType),StructField("publishTime", StringType)))val ods_songs_Df = spark.read.option("header", "false").schema(ods_songs_Schema).csv("hdfs://bigdata:9000/music2024/songs/songs.csv")@Testdef init(): Unit = {//school_province_score_Df.show()//ods_courses_Df.show()//ods_songs_Df.show()ods_songs_Df.show()//school_special_score_Df.show()//school_Df.show()//ruanke_rank_Df.show()//qs_world_Df.show()}// ----剩余使用spark_sql完成
//--指标9:Spark完成词云@Testdef tables09(): Unit = {ods_songs_Df.createOrReplaceTempView("ods_songs")val df2 = spark.sql("""select songName,popfrom ods_songsorder by pop desc,publishTime desclimit 10""")df2// .show(50).coalesce(1).write.mode("overwrite").option("driver", "com.mysql.cj.jdbc.Driver").option("user", "root").option("password", "123456").jdbc("jdbc:mysql://bigdata:3306/hive_music2024?useSSL=false","table09",new Properties())}}