爬虫
2024/9/13 22:30:04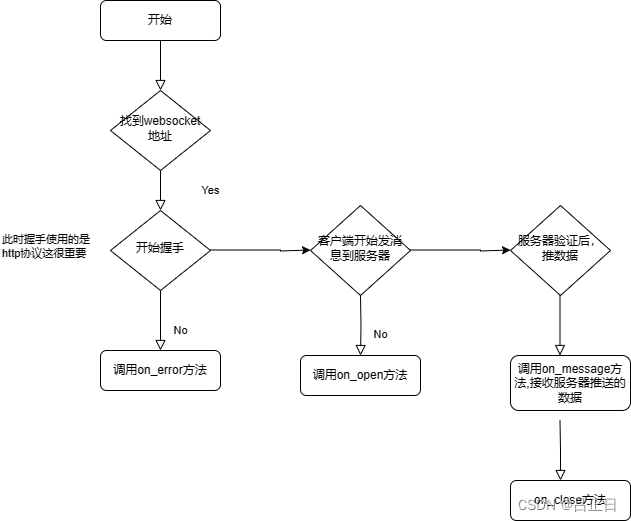
websocket爬虫
人群看板需求分析
先找到策略中心具体的数据。对应数据库中的数据
看看接口是否需要被逆向 点开消费者细分,可以找到人群包(人群名称) 点击查看透视
label字段分类:
在这里插入图片描述
预测年龄:tagTitle 苹果id&#x…

python爬虫爬取淘宝商品比价||淘宝商品详情API接口
最近在学习北京理工大学的爬虫课程,其中一个实例是讲如何爬取淘宝商品信息,现整理如下:
功能描述:获取淘宝搜索页面的信息,提取其中的商品名称和价格 探讨:淘宝的搜索接口 翻页的处理 技术路线:requests‐…

python网络爬虫(四)——实战练习
0.为什么要学习网络爬虫 深度学习一般过程: 收集数据,尤其是有标签、高质量的数据是一件昂贵的工作。 爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,…

爬虫7:多线程与协程
多线程
进程是资源单位 ,每个进程至少要有一个线程 线程是执行单位 创建线程比创建进程花销小,故使用前者
我们可以使用线程池:一次性开辟一些线程,我们用户直接给线程池子提交任务,线程任务的调度交给线程池来完成 …
【Python爬虫】Selenium使用
安装配置教程自行搜索
所用驱动chromedriver应与chrome浏览器版本相对应
pip install selenium
笔者selenium所用版本为4.11.2,新旧版之间会有差别
from selenium import webdriver
driver webdriver.Chrome()实例化driver对象后,driver对象有一些常…

Python 爬虫项目实战(一):爬取某云热歌榜歌曲
前言
网络爬虫(Web Crawler),也称为网页蜘蛛(Web Spider)或网页机器人(Web Bot),是一种按照既定规则自动浏览网络并提取信息的程序。爬虫的主要用途包括数据采集、网络索引、内容抓…

python scrapy爬虫框架 抓取BOSS直聘平台 数据可视化统计分析
使用python scrapy实现BOSS直聘数据抓取分析
前言 随着金秋九月的悄然而至,我们迎来了业界俗称的“金九银十”跳槽黄金季,周围的朋友圈中弥漫着探索新机遇的热烈氛围。然而,作为深耕技术领域的程序员群体,我们往往沉浸在代码的浩…

打卡学习Python爬虫第三天|python的re模块的使用
如何在python程序中使用正则表达式?就是使用re模块
re模块使用:
1、findall查找所有,返回list
list re.findall("n","I love learning English and Chinese!")
print(list) # 输出结果:[n,n,n,n,n]
list…

python网络爬虫(零)——认识网页结构
网页一般有三部分组成,分别是HTML(超文本标记语言)、CSS(层叠样式表)、JScript(活动脚本语言)
1.HTML HTML是整个网页的结构,相当于整个网站的框架。带“<”“>”符号都属于H…
爬虫使用代理IP返回405:原因及解决方法
在进行网络爬虫时,使用代理IP是常见的做法,可以有效地绕过IP限制和反爬虫机制。然而,有时你可能会遇到HTTP状态码405(Method Not Allowed),这意味着请求方法不被服务器允许。本文将详细探讨爬虫使用代理IP返…

python爬虫——入门
一、概念
万维网之所以叫做网,是因为通过点击超链接或者进入URL,我们可以访问任何网络资源,从一个网页跳转到另一个网页,所有的相关资源连接在一起,就形成了一个网。
而爬虫呢,听名字就让人想起来一个黏糊…
Colly官方文档入门教程
Colly
Colly 是用于构建 Web 爬虫的 Golang 框架。使用 Colly , 你可以构建各种复杂的 Web 抓取工具,从简单的抓取工具到处理数百万个网页的复杂的异步网站抓取工具。 Colly 提供了一个 API, 用于执行网络请求和处理接收到的内容(例如,与 HT…

Python爬虫如何通过滑块验证
一:定位元素的坐标
当 Selenium 定位到元素后,如果想获取元素在页面中的具体坐标位置,可以通过 element.location 的方式来得到元素的起始坐标字典(元素的左上顶点)。然后再通过 element.size 的方式来获取该元素的宽…
python网络爬虫(五)——爬取天气预报
1.注册高德天气key 点击高德天气,然后按照开发者文档完成key注册;作为爬虫练习项目之一。从高德地图json数据接口获取天气,可以获取某省的所有城市天气,高德地图的这个接口还能获取县城的天气。其天气查询API服务地址为https://re…
python爬虫爬取淘宝商品比价||淘宝商品详情API接口
最近在学习北京理工大学的爬虫课程,其中一个实例是讲如何爬取淘宝商品信息,现整理如下:
功能描述:获取淘宝搜索页面的信息,提取其中的商品名称和价格 探讨:淘宝的搜索接口 翻页的处理 技术路线:requests‐…