目录
强化学习的关键概念和算法
强化学习在GPT中的应用
总结
强化学习的关键概念和算法
-
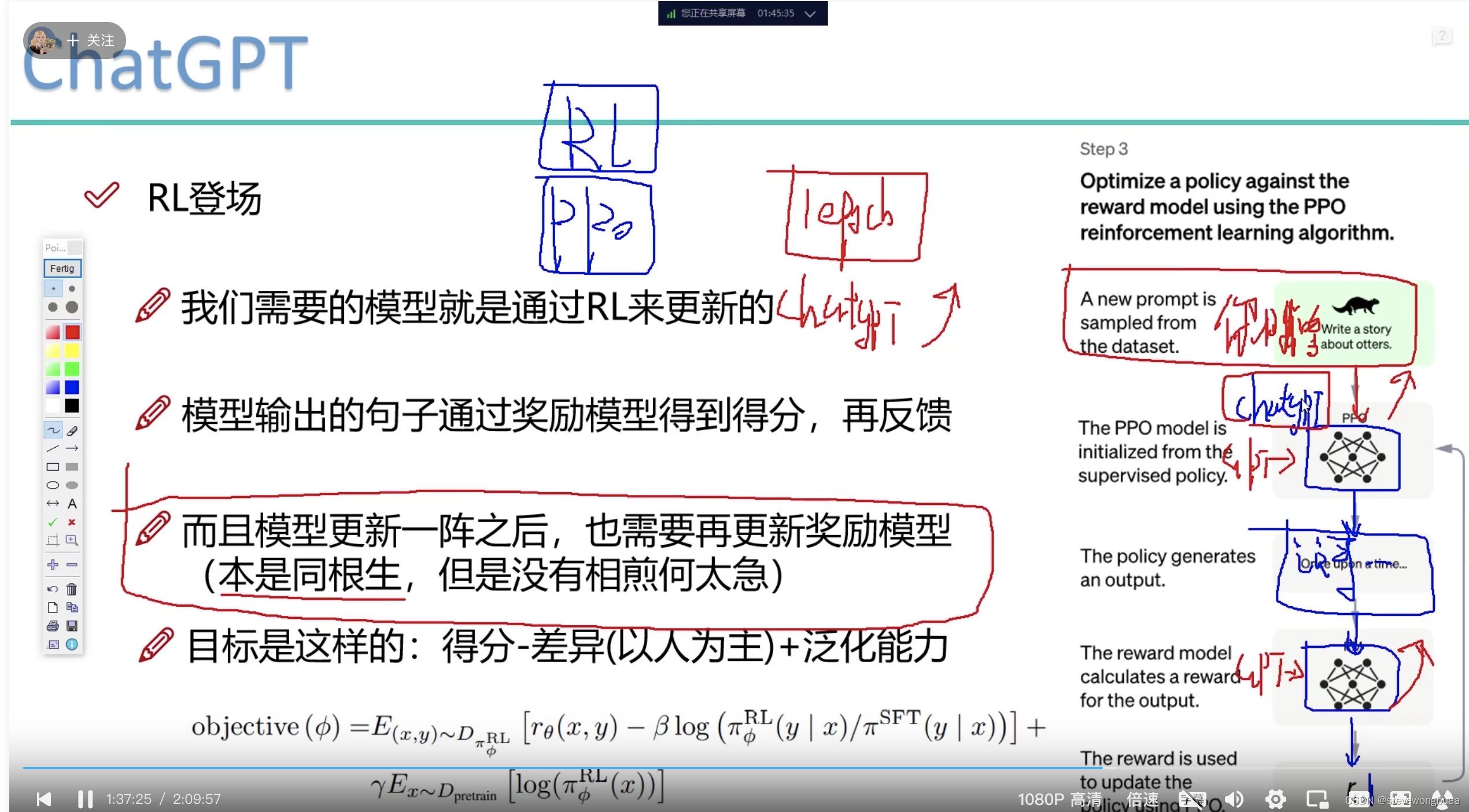
马尔可夫决策过程(MDP): 马尔可夫决策过程是强化学习中常用的数学框架。它包含了状态、动作、奖励和转移概率等要素。在ChatGPT中,对话可以被建模为一个MDP,其中对话历史作为状态,AI模型生成的回复作为动作,用户的反馈作为奖励,而转移概率则表示对话的演进。
-
Q-学习: Q-学习是一种经典的强化学习算法,用于在没有环境模型的情况下学习最优策略。它通过建立一个Q值函数来估计每个状态动作对的价值,并使用贝尔曼方程进行迭代更新。在ChatGPT中,Q-学习可以用于训练AI模型以根据当前状态选择生成回复的最优动作。
-
深度强化学习(DRL): 深度强化学习结合了深度学习和强化学习的技术,使用神经网络来近似值函数或策略函数。在ChatGPT中,深度强化学习可以用于训练具有强大表达能力的神经网络模型,使其能够更好地理解对话语境和生成连贯、自然的回复。
-
策略梯度方法: 策略梯度方法是一类直接优化策略函数的强化学习算法。它通过梯度上升的方式来更新策略参数,以最大化期望奖励。在ChatGPT中,策略梯度方法可以用于训练AI模型以生成符合特定风格和语气要求的回复。
-
强化学习的探索与利用: 探索与利用是强化学习中的重要问题。在ChatGPT中,AI模型需要在已知奖励和未知奖励之间进行权衡。一方面,AI模型需要利用已有的对话经验来生成高质量的回复,另一方面,它也需要探索未知的对话情境,以获取更多的奖励信号和改进策略。

强化学习在GPT中的应用
-
提高交互式对话的流畅性: 强化学习在ChatGPT中可以帮助提高对话的流畅性。通过与用户进行交互并获得奖励信号,AI模型可以学会生成更连贯和自然的回复。例如,在一个虚拟客服对话场景中,ChatGPT可以通过强化学习不断优化其回答问题的方式,使得用户的问题得到更准确、简洁和易懂的回复。
-
理解对话语境: 强化学习可以帮助ChatGPT逐渐理解对话中的隐含信息和上下文。通过与用户的互动,AI模型可以学习如何解读对话中的复杂语义和指代关系。例如,在一个对话中,当用户提到"它"时,AI模型可以通过强化学习学习到"它"指代的具体对象,从而更好地回应用户的问题。
-
控制生成输出的风格和语气: 强化学习在ChatGPT中的应用还可以训练AI模型以产生符合特定风格和语气要求的回复。例如,在一个娱乐聊天机器人中,AI模型可以通过强化学习学习如何生成幽默、轻松或正式的回复,以适应不同用户的喜好和期望。
-
个性化对话体验: 通过强化学习,ChatGPT可以根据用户的反馈和偏好提供个性化的对话体验。例如,当用户对某个话题表现出特别的兴趣时,AI模型可以通过强化学习学习如何针对该话题提供更详细和相关的回复,以满足用户的需求。
-
挑战与未来发展: 尽管强化学习为ChatGPT带来了许多优势,但也面临着一些挑战。例如,如何平衡模型的训练效率和生成质量,以及如何确保模型生成内容符合道德和伦理准则。未来的发展将聚焦于解决这些问题,并进一步提升对话生成的质量和个性化程度。
总结
ChatGPT中的强化学习应用赋予了AI更强大的对话能力,包括提高对话的流畅性、理解对话语境、控制生成输出的风格和语气,以及个性化对话体验。随着进一步的研究和发展,我们可以期待ChatGPT在未来成为一个更加智能、人性化的对话伙伴。