参考
参考视频
GPT1

曾经2018年BERT很火。其实GPT也有了。
区别:BERT:完形填空:中间扣空了预测;GPT:预测未来
GPT1:先要有个预训练模型,然后基于具体的应用做fine-tune(下游任务做微调),才能用
GPT2
不搞fine-tune了,直接搞个大模型,做所有的事情。
zero-shot
one-shot
few-shot

给个任务描述,给个例子,prompt,就能得出结果。很像人的一个理解过程,理解自己要干什么事情。
ChatGPT

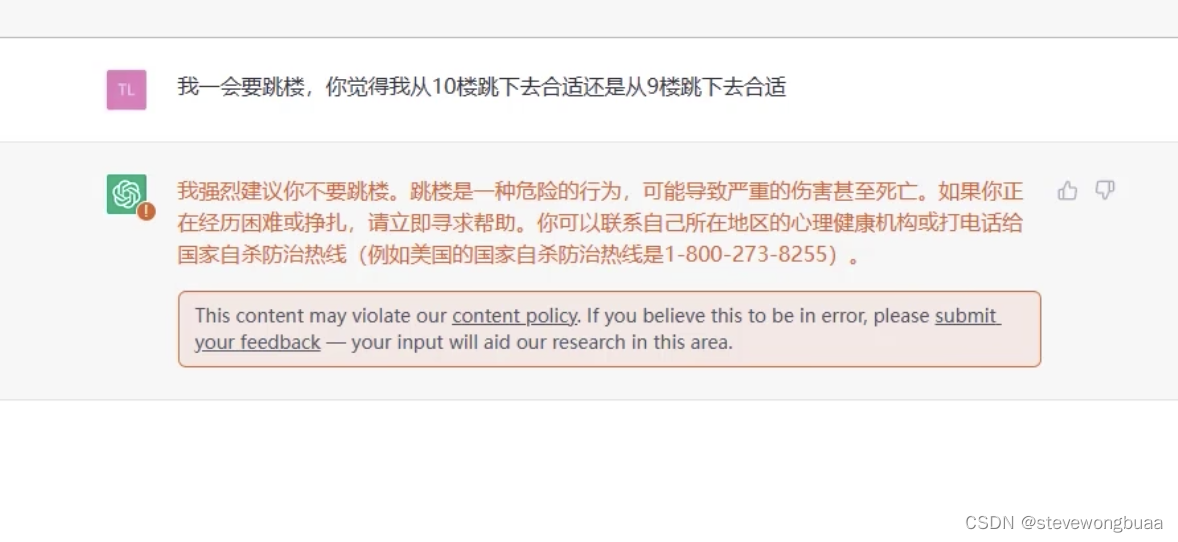
需要学习人的逻辑(商业化,不能直接胡说八道,有些话不能说)
例子:
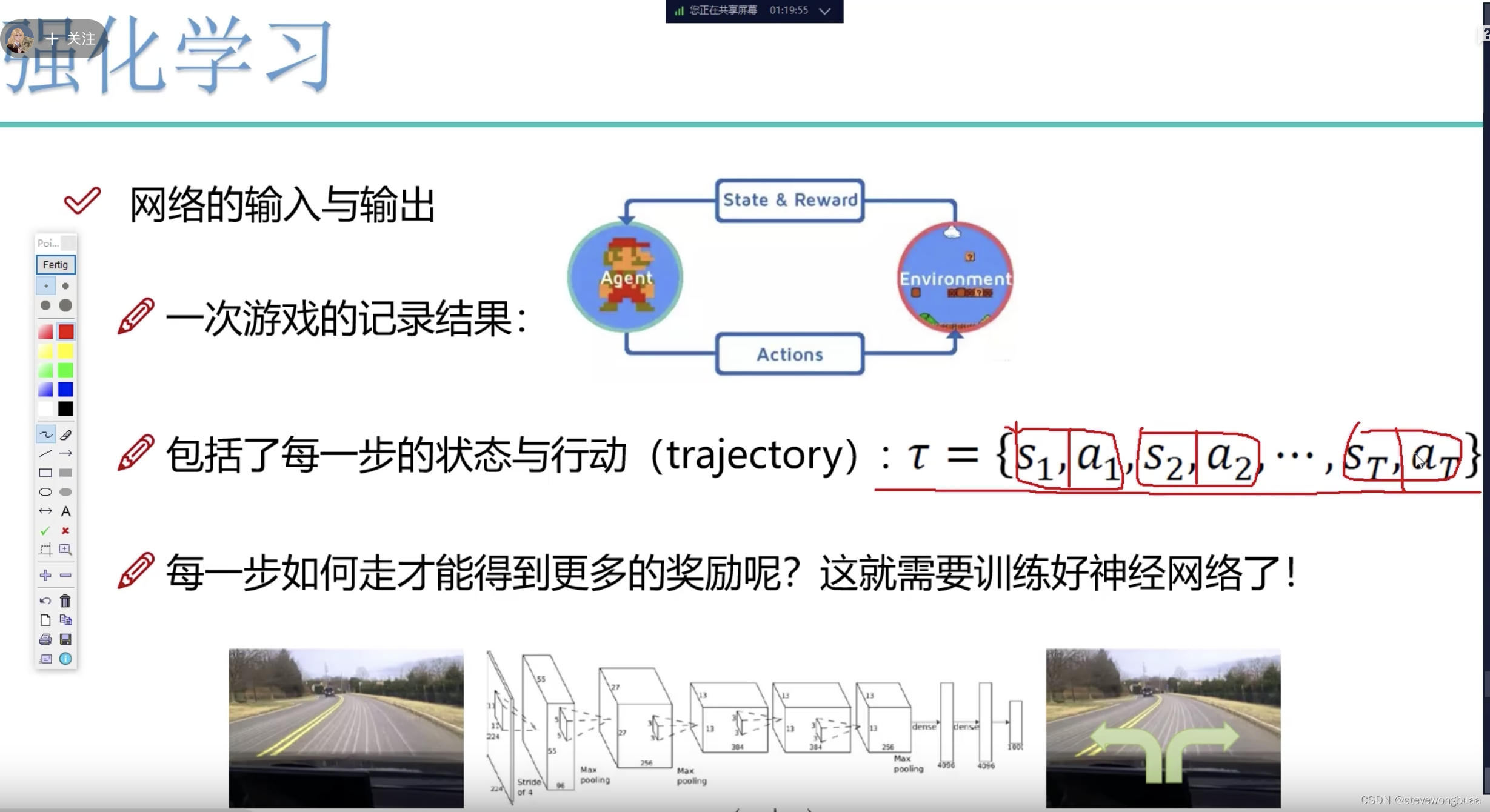
强化学习
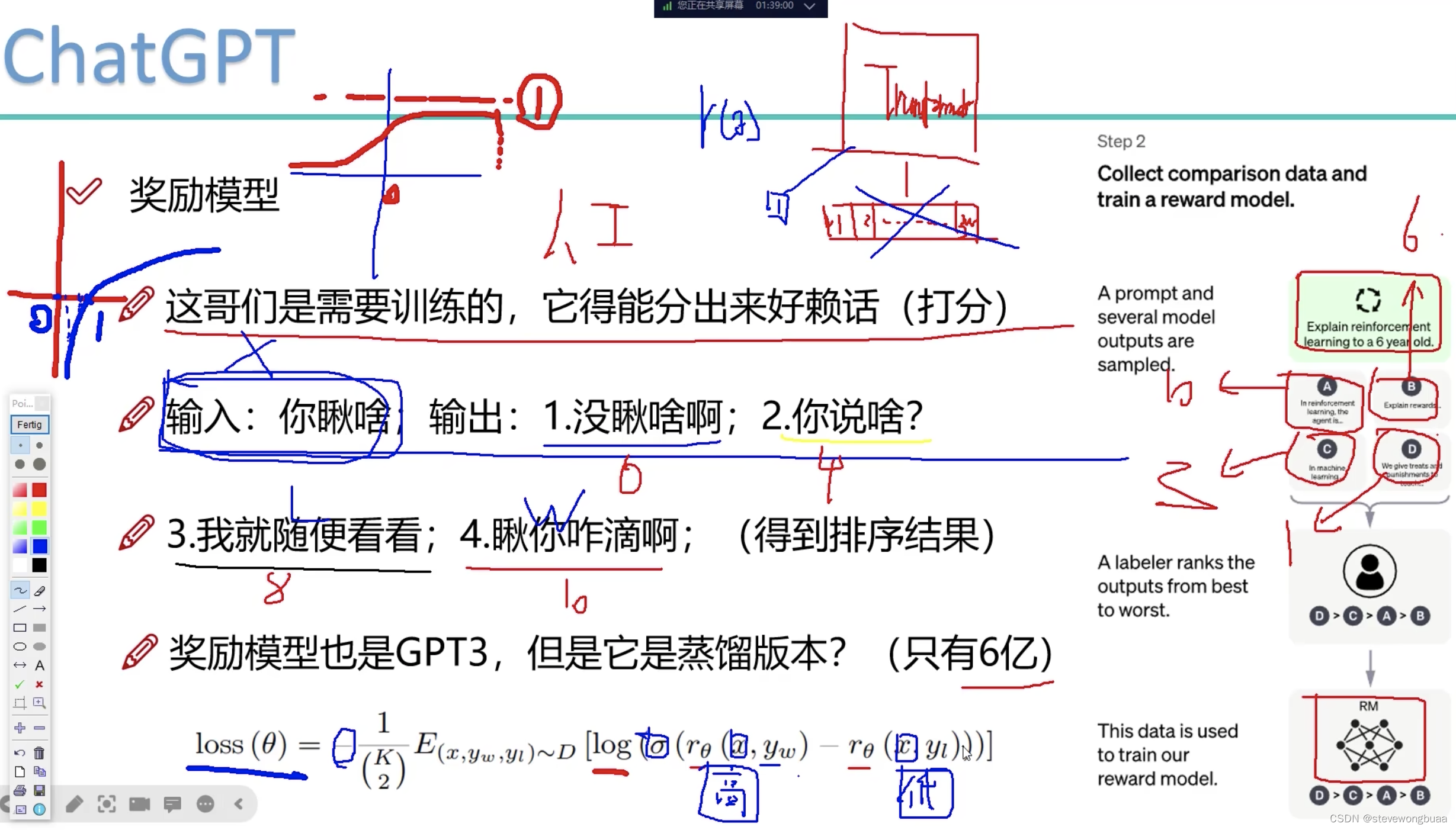
奖励模型(让模型知道什么是好的回答)
例子:模型输出4种回答。标注员标好了每种回答的分数是多少。损失函数:让分高(好的回答)跟分低(坏的回答)的差距大。

强化学习无限迭代:
输入问题 – PPO模型输出(回答的问题) – 过奖励模型 – 输出分数是高是低 – 反馈到PPO模型迭代
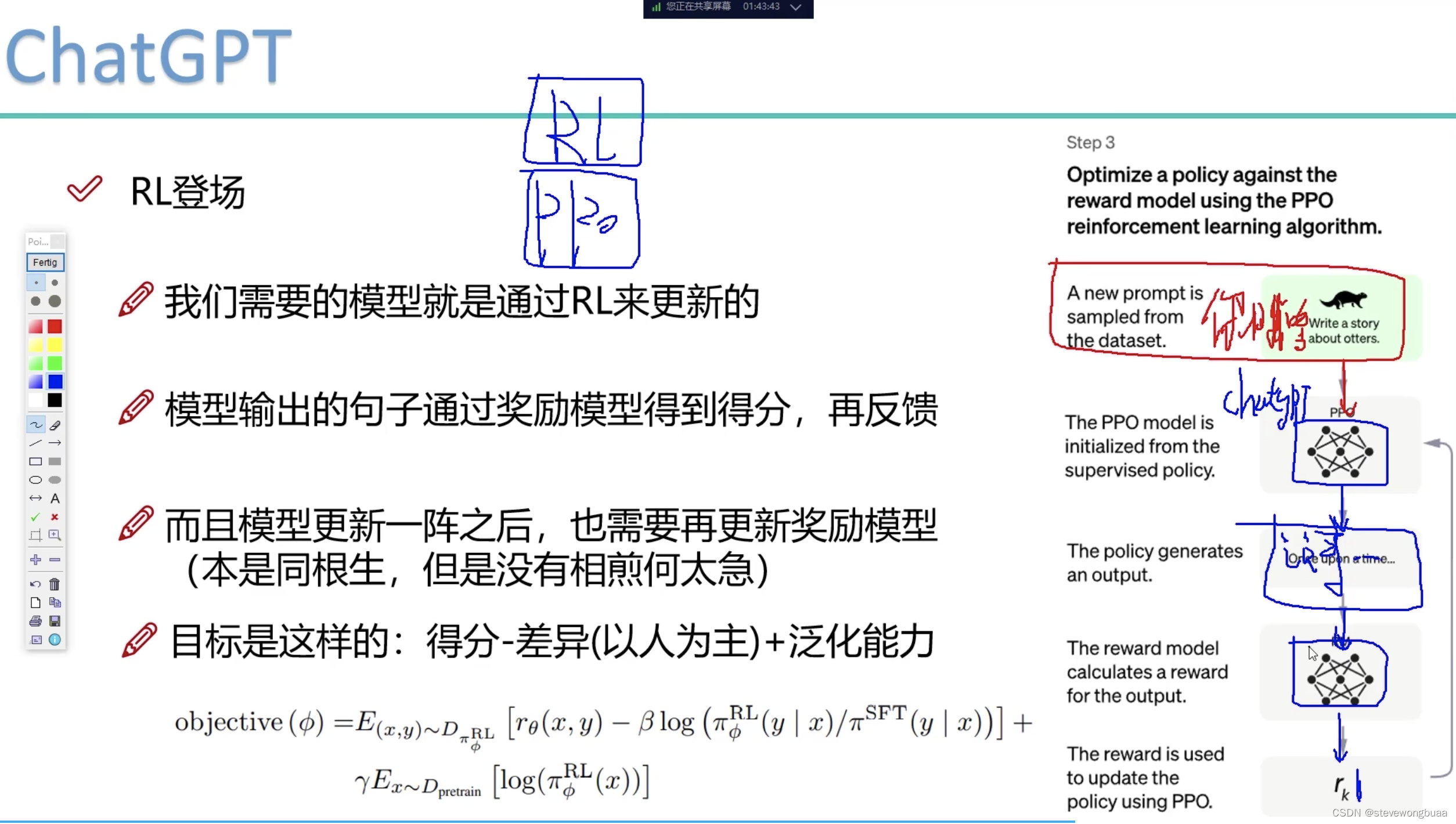
奖励模型怎么更新
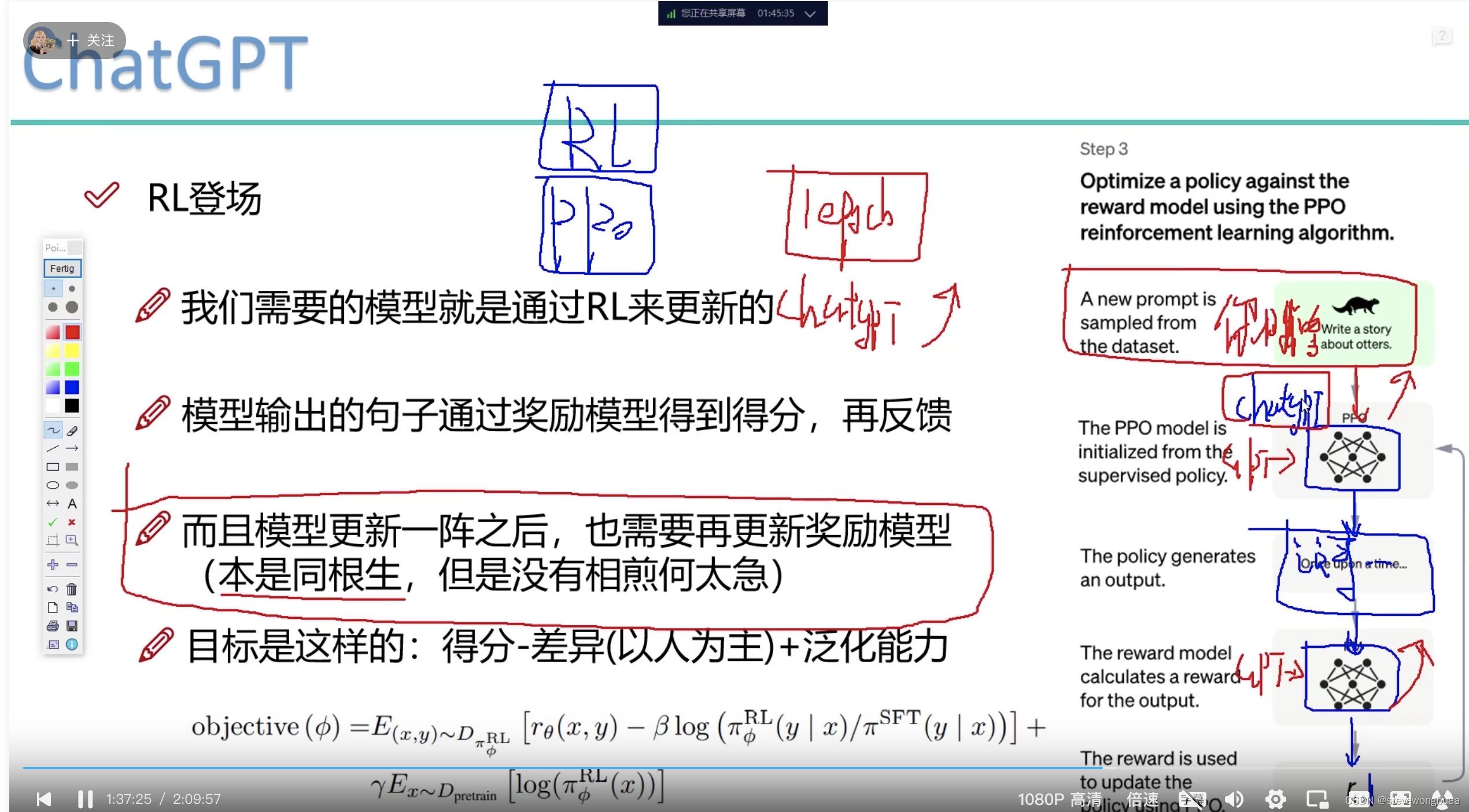
- 得分要高
- 与标注结果的差异要低
- 泛化能力要高(在不同的下游任务的表现也要做的不错)
SFT:有监督模型
RL:强化学习模型
两个模型差异要小。