Q-learning算法是强化学习中最基础的算法之一。
在Q-learning中,计算机会学习一个Q值表,该表将每个状态和每个可能的行动与相应的Q值相关联。Q值可以理解为一个行动的价值,可以帮助计算机做出最优的决策。
具体来说,Q-learning算法分为以下几步:
初始化Q值表为0。
让计算机在当前状态下选择一个行动。
根据选择的行动,计算出下一个状态以及相应的奖励。
使用下一个状态和奖励更新Q值表。
重复上述步骤直到达到停止条件。
#!/usr/bin/env python
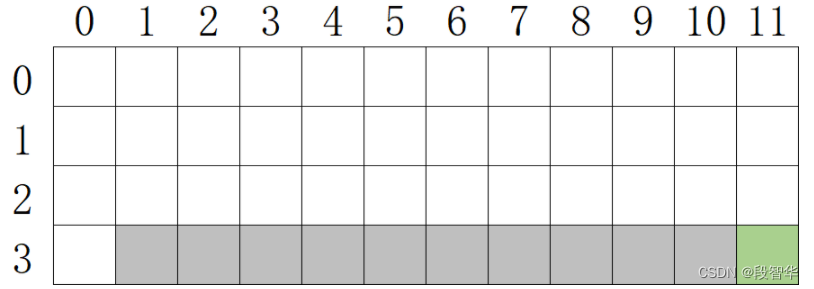
# coding: utf-8# In[1]:#获取一个格子的状态
def get_state(row, col):if row != 3:return 'ground'if row == 3 and col == 0:return 'ground'if row == 3 and col == 11:return 'terminal'return 'trap'get_state(0, 0)# In[2]:#在一个格子里做一个动作
def move(row, col, action):#如果当前已经在陷阱或者终点,则不能执行任何动作if get_state(row, col) in ['trap', 'terminal']:return row, col, 0#↑if action == 0:row -= 1#↓if action == 1:row += 1#←if