团队博客: CSDN AI小组
相关阅读
- ChatGPT 简介
- 大语言模型浅探一
- 关于 ChatGPT 必看的 10 篇论文
- 从 ELMo 到 ChatGPT:历数 NLP 近 5 年必看大模型
1 前言
在当今数字化的时代,ChatGPT 的火热程度不断升级。ChatGPT 可以处理复杂的语言任务,从而解放人力资源,提高工作效率,减少成本。ChatGPT 的先进技术和广泛应用,使得它成为了当今最炙手可热的人工智能技术之一。无论是企业、学术机构,还是科技爱好者,都对 ChatGPT 的应用前景充满期待。
在这样的背景之下,CSDN AI 团队也想对 ChatGPT 进行简单的复现。根据ChatGPT 官方博客可知,ChatGPT的训练方法与 InstructGPT 的训练方法基本一致 (如图1所示),只是使用的数据集不一样。故在训练方法上,我们主要参考 InstructGPT 进行复现,基础模型使用的是 RWKV,拆分后共包含以下四个阶段:
- (1) 语言模型预训练 (Language Model Pre-training);
- (2) 有监督指令微调 (Supervised Fine-Tuning, SFT);
- (3) 奖励模型的训练 (Reward Modeling, RM);
- (4) 使用近端策略优化算法进行强化学习 (Proximal Policy Optimization, PPO).
第 (1)、(2) 阶段的 Pre-training 和 SFT 由 @zxm2015 完成,可参考文章 大语言模型浅探一。本文主要介绍第 (3)、(4) 阶段的内容,即人类反馈强化学习 (Reinforcement Learning from Human Feedback, RLHF)。
! 在这里插入图片描述
2 人类反馈强化学习 (RLHF)
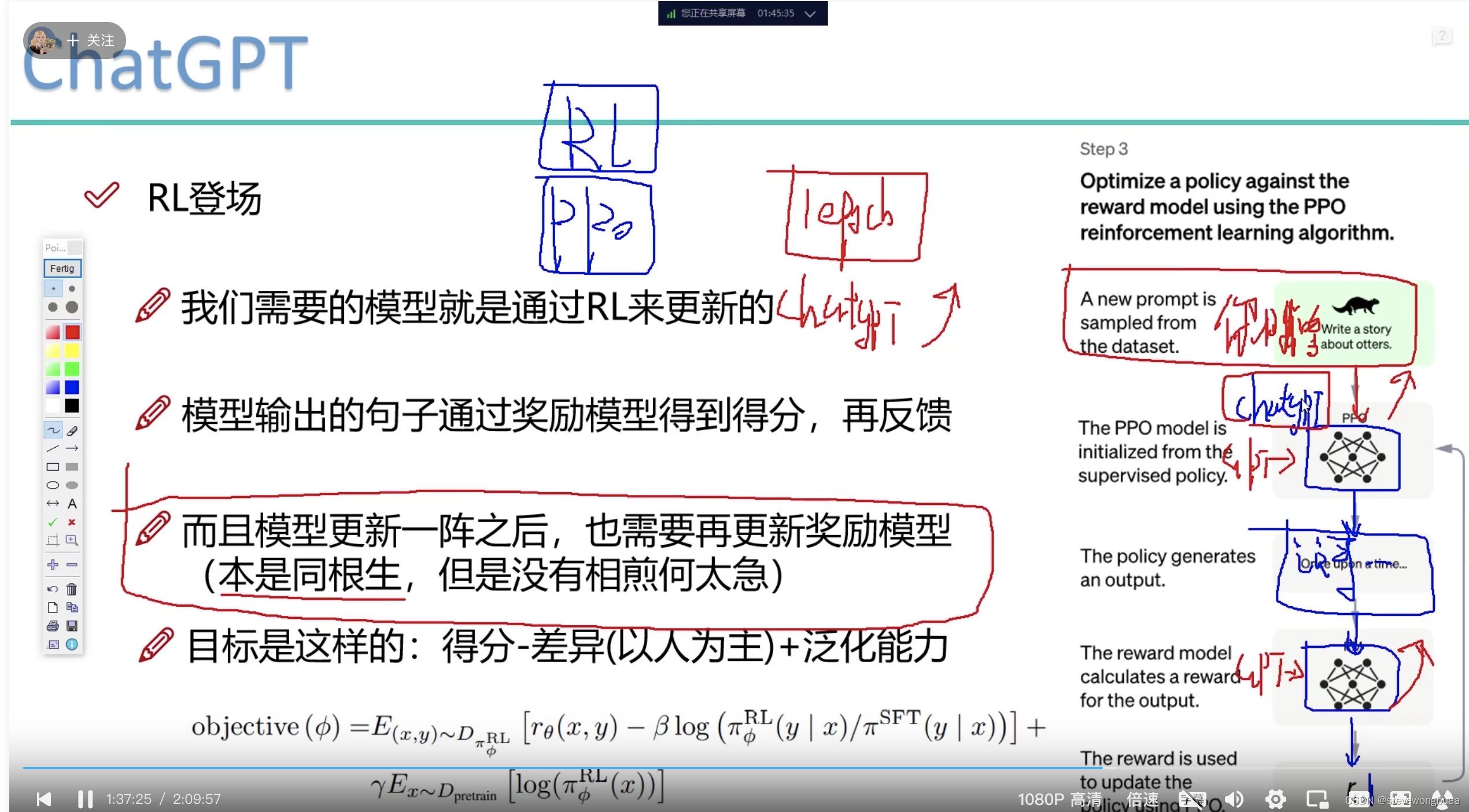
人类反馈强化学习 (RLHF) 是 ChatGPT 中一种用于改善其回答效果的算法。它是一种基于强化学习的方法,通过结合人类反馈来优化 ChatGPT 的回答。
在 RLHF 中,ChatGPT 学习通过和人类用户的交互来提高其回答的质量。当 ChatGPT 生成一个回答时,它会将回答展示给用户并请求用户的反馈。用户可以对回答进行评分,比如“好”、“不错”、“一般”、“差”等。ChatGPT 会将用户的反馈作为奖励或惩罚信号,以此来更新自己的模型,以更好地满足用户的需求。
RLHF 可分为两个部分。第一部分是奖励模型,人类反馈主要就体现在这个地方;第二部分采用近端策略优化算法的强化学习阶段,基于奖励模型的反馈来优化模型,最终得到满足人类偏好的语言模型。下面将对这两个部分进行详细的说明。