批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
</h1><div class="clear"></div><div class="postBody">
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)以及小批量梯度下降(Mini-Batch Gradient Descent)。其中小批量梯度下降法也常用在深度学习中进行模型的训练。接下来,我们将对这三种不同的梯度下降法进行理解。
为了便于理解,这里我们将使用只含有一个特征的线性回归来展开。此时线性回归的假设函数为:
hθ(x(i))=θ1x(i)+θ0hθ(x(i))=θ1x(i)+θ0
(for j =0,1)
}
}
优点:
(1)通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
(2)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代3000次,远小于SGD的30W次)
(3)可实现并行化。
缺点:
(1)batch_size的不当选择可能会带来一些问题。
batcha_size的选择带来的影响:
(1)在合理地范围内,增大batch_size的好处:
a. 内存利用率提高了,大矩阵乘法的并行化效率提高。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
c. 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
(2)盲目增大batch_size的坏处:
a. 内存利用率提高了,但是内存容量可能撑不住了。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
c. Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
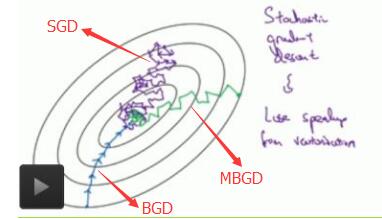
下图显示了三种梯度下降算法的收敛过程:
引用及参考:
[1] https://www.cnblogs.com/maybe2030/p/5089753.html
[2] https://zhuanlan.zhihu.com/p/37714263
[3] https://zhuanlan.zhihu.com/p/30891055
[4] https://www.zhihu.com/question/40892922/answer/231600231
写在最后:本文参考以上资料进行整合与总结,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!
若需转载请注明:https://www.cnblogs.com/lliuye/p/9451903.html
分类: Machine Learning
<div id="blog_post_info">
好文要顶 关注我 收藏该文 


18
0
<div class="clear"></div>
<div id="post_next_prev"><a href="https://www.cnblogs.com/lliuye/p/9449190.html" class="p_n_p_prefix">« </a> 上一篇: <a href="https://www.cnblogs.com/lliuye/p/9449190.html" title="发布于 2018-08-09 15:23">Ubuntu下tensorboard的使用</a>
<br>
<a href="https://www.cnblogs.com/lliuye/p/9471231.html" class="p_n_p_prefix">» </a> 下一篇: <a href="https://www.cnblogs.com/lliuye/p/9471231.html" title="发布于 2018-08-13 21:49">学习率(Learning rate)的理解以及如何调整学习率</a>
posted @ 2018-08-10 11:57 LLLiuye 阅读(41513) 评论(17) 编辑 收藏