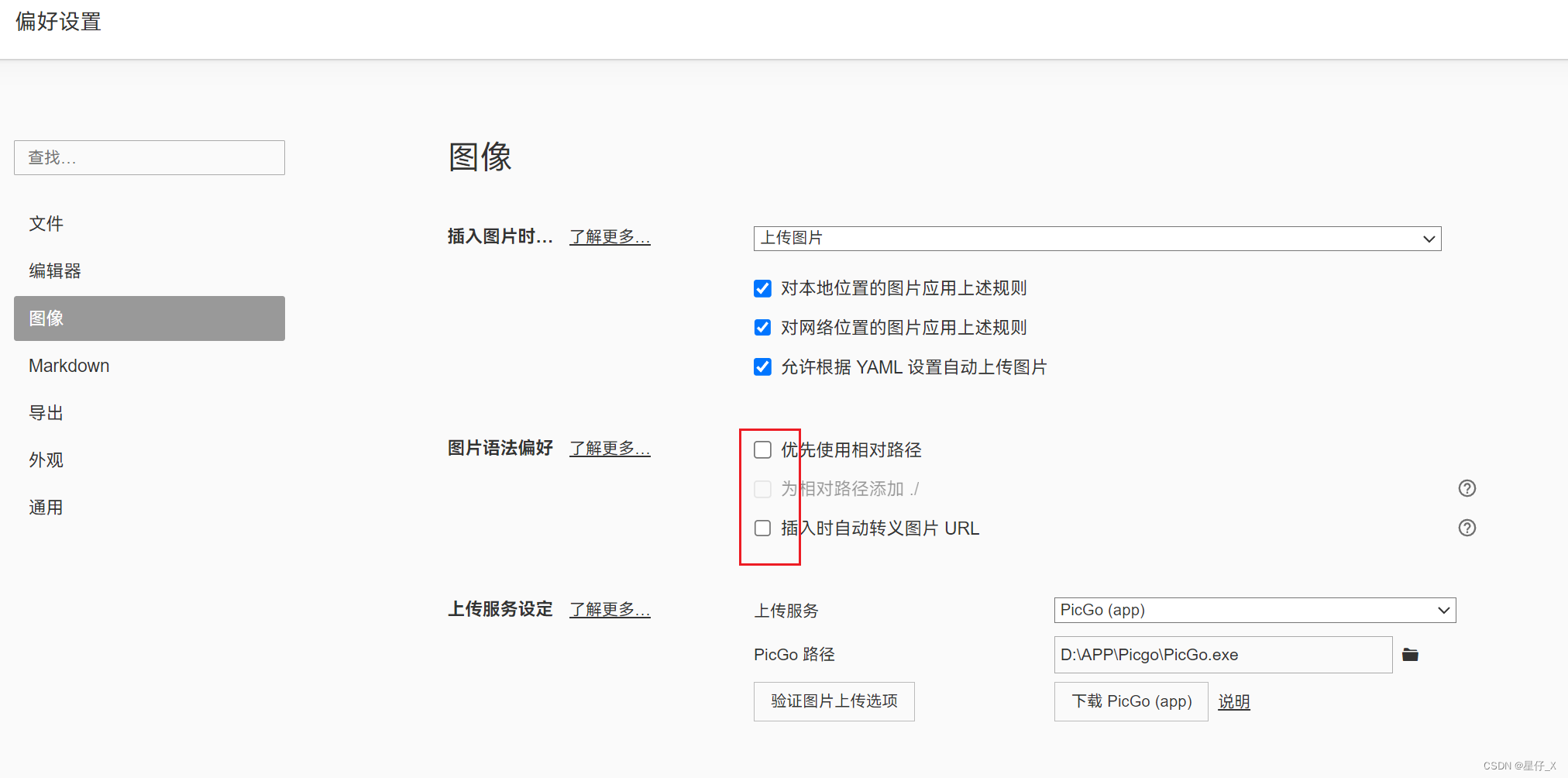
如何解决数据分析问题:IPython与Pandas结合
数据分析是现代科学研究、商业决策和技术开发中的一个重要环节。IPython和Pandas是两个强大的工具,它们可以大大简化和加速数据分析的过程。本文将为初学者详细介绍如何结合使用IPython和Pandas来解决数据分析问题。
目录
- IPython简介
1.1 什么是IPython
1.2 IPython的基本功能
1.3 安装和设置 - Pandas简介
2.1 什么是Pandas
2.2 Pandas的基本数据结构
2.3 安装和设置 - IPython与Pandas结合的优势
- 数据导入与预处理
4.1 数据导入
4.2 数据清洗
4.3 数据转换 - 数据分析与操作
5.1 数据选择与过滤
5.2 数据分组与聚合
5.3 数据透视表 - 数据可视化
6.1 基本绘图
6.2 高级绘图 - 实际案例分析
7.1 案例背景介绍
7.2 数据分析步骤
7.3 分析结果与结论 - 总结与展望
1. IPython简介
1.1 什么是IPython
IPython是一个增强的交互式Python shell,旨在提高Python编程的易用性和功能性。它为用户提供了丰富的工具,可以进行快速的代码测试、调试和执行。
1.2 IPython的基本功能
- 交互式计算:IPython提供了强大的命令行界面,可以快速执行Python代码。
- 代码补全:智能代码补全功能帮助用户快速输入代码。
- 调试工具:内置的调试工具可以帮助用户快速定位和解决代码中的问题。
- 可扩展性:IPython支持多种插件和扩展,可以根据需要进行定制。
1.3 安装和设置
要安装IPython,可以使用以下命令:
pip install ipython
安装完成后,可以通过以下命令启动IPython:
ipython
2. Pandas简介
2.1 什么是Pandas
Pandas是Python中最流行的数据分析库之一,它提供了高效、便捷的数据操作和分析功能。Pandas特别擅长处理表格型数据,如电子表格或数据库中的数据。
2.2 Pandas的基本数据结构
- Series:一种类似于一维数组的对象,可以存储任意数据类型。
- DataFrame:一种二维的表格数据结构,类似于电子表格或SQL表格。
2.3 安装和设置
要安装Pandas,可以使用以下命令:
pip install pandas
安装完成后,可以通过以下方式导入Pandas库:
import pandas as pd
3. IPython与Pandas结合的优势
IPython和Pandas的结合可以大大提高数据分析的效率和便捷性。IPython提供了一个强大的交互式计算环境,而Pandas则提供了丰富的数据操作功能。两者结合使用,可以快速导入、处理、分析和可视化数据。
4. 数据导入与预处理
数据导入和预处理是数据分析过程中最重要的步骤之一。在这一部分,我们将介绍如何使用Pandas导入数据并进行预处理。
4.1 数据导入
Pandas支持多种数据导入方式,包括从CSV、Excel、SQL数据库等导入数据。以下是一些常见的数据导入示例:
- 从CSV文件导入数据:
df = pd.read_csv('data.csv')
- 从Excel文件导入数据:
df = pd.read_excel('data.xlsx')
- 从SQL数据库导入数据:
import sqlite3conn = sqlite3.connect('database.db')
df = pd.read_sql_query('SELECT * FROM table_name', conn)
4.2 数据清洗
数据清洗是指对原始数据进行整理和修正,以便进行后续分析。常见的数据清洗操作包括处理缺失值、重复数据和异常值等。
- 处理缺失值:
df.dropna() # 删除包含缺失值的行
df.fillna(value=0) # 用指定值填充缺失值
- 处理重复数据:
df.drop_duplicates() # 删除重复行
- 处理异常值:
df[df['column'] < threshold] # 筛选出小于阈值的行
4.3 数据转换
数据转换是指将数据从一种形式转换为另一种形式,以便进行分析。例如,可以对数据进行类型转换、编码转换和格式化等操作。
- 类型转换:
df['column'] = df['column'].astype('int') # 将列转换为整数类型
- 编码转换:
df['column'] = df['column'].apply(lambda x: x.encode('utf-8')) # 将列中的字符串进行编码转换
- 格式化:
df['column'] = pd.to_datetime(df['column']) # 将列转换为日期时间格式
5. 数据分析与操作
数据分析与操作是数据分析的核心部分。在这一部分,我们将介绍如何使用Pandas进行数据选择、过滤、分组、聚合和透视表操作。
5.1 数据选择与过滤
数据选择与过滤是指从数据集中选择出符合条件的数据子集。
- 选择列:
df['column'] # 选择单列
df[['column1', 'column2']] # 选择多列
- 选择行:
df.loc[0] # 选择第0行
df.iloc[0] # 选择第0行(按位置)
- 过滤数据:
df[df['column'] > threshold] # 选择列值大于阈值的行
5.2 数据分组与聚合
数据分组与聚合是指根据一个或多个列对数据进行分组,然后对每个组进行聚合操作。
- 分组:
grouped = df.groupby('column')
- 聚合:
grouped.mean() # 计算每个组的均值
grouped.sum() # 计算每个组的总和
5.3 数据透视表
数据透视表是一种强大的数据汇总工具,可以对数据进行快速的统计分析。
- 创建数据透视表:
pivot_table = pd.pivot_table(df, values='value_column', index='index_column', columns='column', aggfunc='mean')
6. 数据可视化
数据可视化是数据分析的重要组成部分,可以帮助我们直观地理解数据。在这一部分,我们将介绍如何使用Pandas和Matplotlib进行数据可视化。
6.1 基本绘图
Pandas内置了基本的绘图功能,可以快速创建简单的图表。
- 绘制折线图:
df.plot()
- 绘制柱状图:
df.plot.bar()
- 绘制散点图:
df.plot.scatter(x='column1', y='column2')
6.2 高级绘图
对于更复杂的图表,可以使用Matplotlib库。
- 导入Matplotlib:
import matplotlib.pyplot as plt
- 创建高级图表:
plt.figure(figsize=(10, 6))
plt.plot(df['column1'], df['column2'])
plt.title('Title')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()
7. 实际案例分析
在这一部分,我们将通过一个实际案例来演示如何结合使用IPython和Pandas进行数据分析。
7.1 案例背景介绍
假设我们有一份包含全球各国GDP数据的CSV文件,我们希望分析不同国家的GDP情况并进行可视化展示。
7.2 数据分析步骤
- 导入数据:
df = pd.read_csv('global_gdp.csv')
- 数据清洗:
df.dropna() # 删除包含缺失值的行
- 数据分析:
- 计算各国的平均GDP:
mean_gdp = df.groupby('Country')['GDP'].mean()
- 找出GDP最高的国家:
max_gdp = df[df['GDP'] == df['GDP'].max()]
- 数据可视化:
- 绘制各国GDP的柱状图:
mean_gdp.plot.bar()
plt.title('AverageGDP by Country')
plt.xlabel('Country')
plt.ylabel('Average GDP')
plt.show()
7.3 分析结果与结论
通过上述步骤,我们可以得出各国的平均GDP并找出GDP最高的国家。可视化图表可以帮助我们更直观地理解数据分布情况。
8. 总结与展望
本文详细介绍了如何结合使用IPython和Pandas解决数据分析问题。从数据导入、预处理、分析到可视化,我们演示了完整的流程和具体操作。通过实际案例,我们可以看到IPython和Pandas在数据分析中的强大功能和便捷性。对于初学者来说,掌握这些工具和方法可以大大提高数据分析的效率和效果。未来,我们可以进一步学习更高级的数据分析和机器学习方法,充分利用数据的价值。