大数据时代,
数据收集不仅是科学研究的基石,
更是企业决策的关键。
然而,如何高效地收集数据
成了摆在我们面前的一项重要任务。
本文将为你揭示,
一系列实时数据采集方法,
助你在信息洪流中,
找到真正有价值的信息。
提升方法
今天,我们就用python爬取淘宝上某一商品的数据
Python版本:Python3.6
浏览器:谷歌![]() 一键爬取
一键爬取
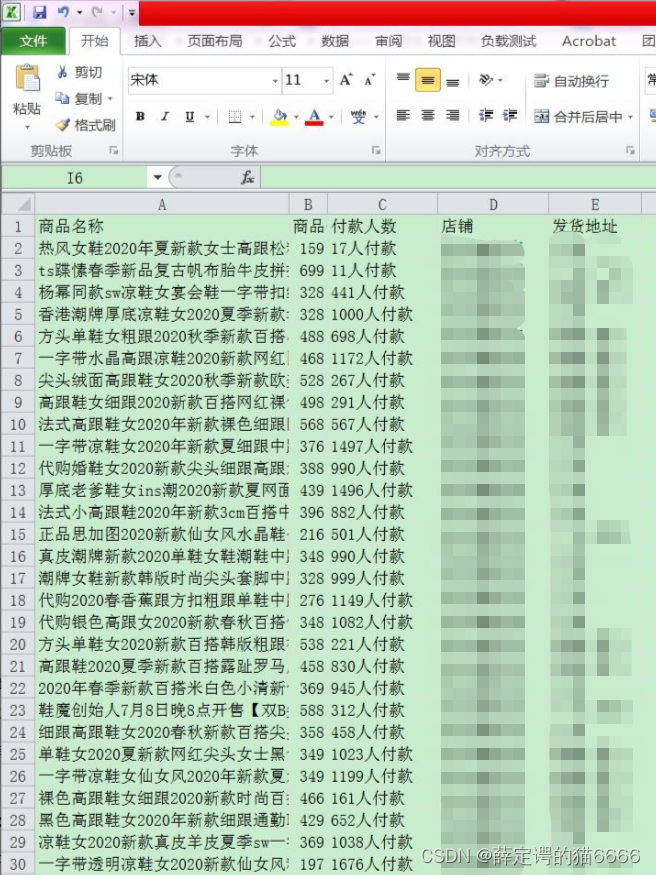
目的:爬取淘宝上所有卖高跟鞋的商家的商品名称、商品价格、付款人数、店铺和发货地址,将爬取到的数据保存在data.csv文件中
一、输入关键词和网址
keywords = '高跟鞋'
while 1:try:driver = webdriver.Chrome()breakexcept:time.sleep(1)
driver.get('https://www.taobao.com/')
page = search_product(keywords)
关键词keywords为高跟鞋,while的目的是防止出现因为网不好导致报错。这一部分运行后,会自动打开淘宝官网,并将关键词自动输入。
二、构建存储表格
with open('data.csv','a',newline='') as filecsv:csvwriter = csv.writer(filecsv,delimiter = ',')csvwriter.writerow(['商品名称','商品价格','付款人数','店铺','发货地址'])get_product()page_num = 1
三、爬取每一页的商品数据
while page_num != page:print('正在爬取第'+str(page_num)+'页数据')driver.get('https://s.taobao.com/search?q='+keywords+'&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.2&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s='+str(page_num*44))driver.implicitly_wait(2) #浏览器等待 因为爬取速度过快driver.maximize_window() #浏览器最大化get_product()page_num = page_num+1def get_product():divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')product = {}product_all = {}with open('data.csv','a',newline='') as filecsv:csvwriter = csv.writer(filecsv,delimiter = ',')for id_product,div in enumerate(divs):product['info'] = div.find_elements_by_xpath('.//div[@class="row row-2 title"]')[0].textproduct['price'] = div.find_elements_by_xpath('.//div[@class="price g_price g_price-highlight"]/strong')[0].text+'元'product['Number_of_people'] = div.find_elements_by_xpath('.//div[@class="deal-cnt"]')[0].textproduct['address'] = div.find_elements_by_xpath('.//div[@class="location"]')[0].textproduct['Shop'] = div.find_elements_by_xpath('//div[@class="shop"]/a/span[2]')[0].text# with open('data.csv','a',newline='') as filecsv:# csvwriter = csv.writer(filecsv,delimiter = ',')csvwriter.writerow([product['info'],product['price'],product['Number_of_people'],product['Shop'],product['address']])page为需要爬取的总页数,在本代码中为所有页码,如果只需要前10页,可手动将其改为10。
driver.implicitly_wait(2) 为页面等待两秒,是为了防止网址发现是爬虫而不让爬取数据。
driver.implicitly_wait(2) 函数为提取每一页商品的具体数据。
最后的保存结果为:

![[华为OD] 给航天器一侧加装长方形或正方形的太阳能板 100](https://img-blog.csdnimg.cn/direct/51754d605de44c40aec2e6d0fecada95.png)