前几天有写过一篇 【爬虫】爬取A股数据写入数据库(一),现在继续完善下,将已有数据通过ORM形式批量写入数据库。
2024/05,本文主要内容如下:
- 对东方财富官网进行分析,并作数据爬取,使用python,使用pip install requests 模拟http数据请求,获取数据。
- 将爬取的数据写入通过 sqlalchemy ORM 写入 sqlite数据库。
- 记录爬取股票的基本信息,如果库中已存在某个股票代码,则进行更新。
- 后续计划:会不断完善,最终目标是做出一个简单的股票查看客户端。
- 本系列所有源码均无偿分享,仅作交流无其他,供大家参考。
python依赖环境如下:
conda create --name xuan_gu python=3.9 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda remove --name xuan_gu --all
conda activate xuan_gu#pip install PyQt5==5.15.10 -i https://pypi.tuna.tsinghua.edu.cn/simple
#pip install pyqtgraph==0.13.6 -i https://pypi.tuna.tsinghua.edu.cn/simple
#python -m pyqtgraph.examples 查看图形化的pyqtgraph示例pip install requests==2.31.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas==2.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jsonpath==0.8.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sqlalchemy==2.0.30 -i https://pypi.tuna.tsinghua.edu.cn/simple
1. 对东方财富官网的分析
东方财富网页地址:https://data.eastmoney.com/gdhs/
通过分析网页,发现https://datacenter-web.eastmoney.com/api/data/v1/get?请求后面带着一些参数即可以获取到相应数据,我们不断调试,模拟这类请求即可。分析过程如下图所示,F12调出调试框,不断尝试:


在这里插入图片描述
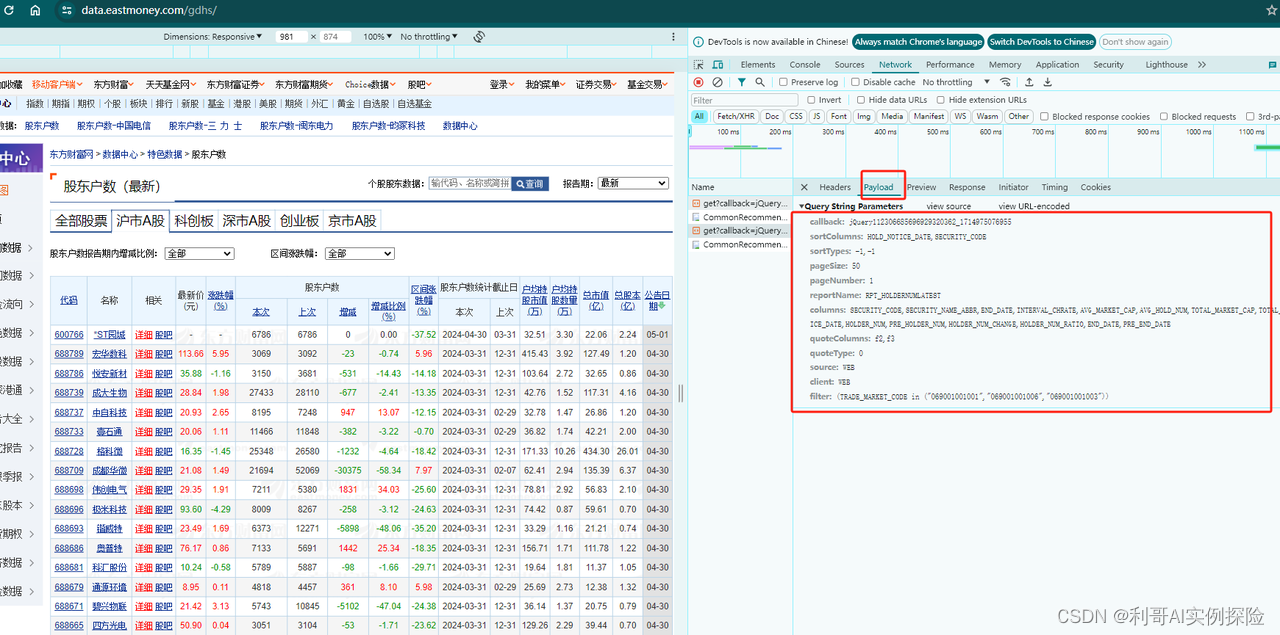
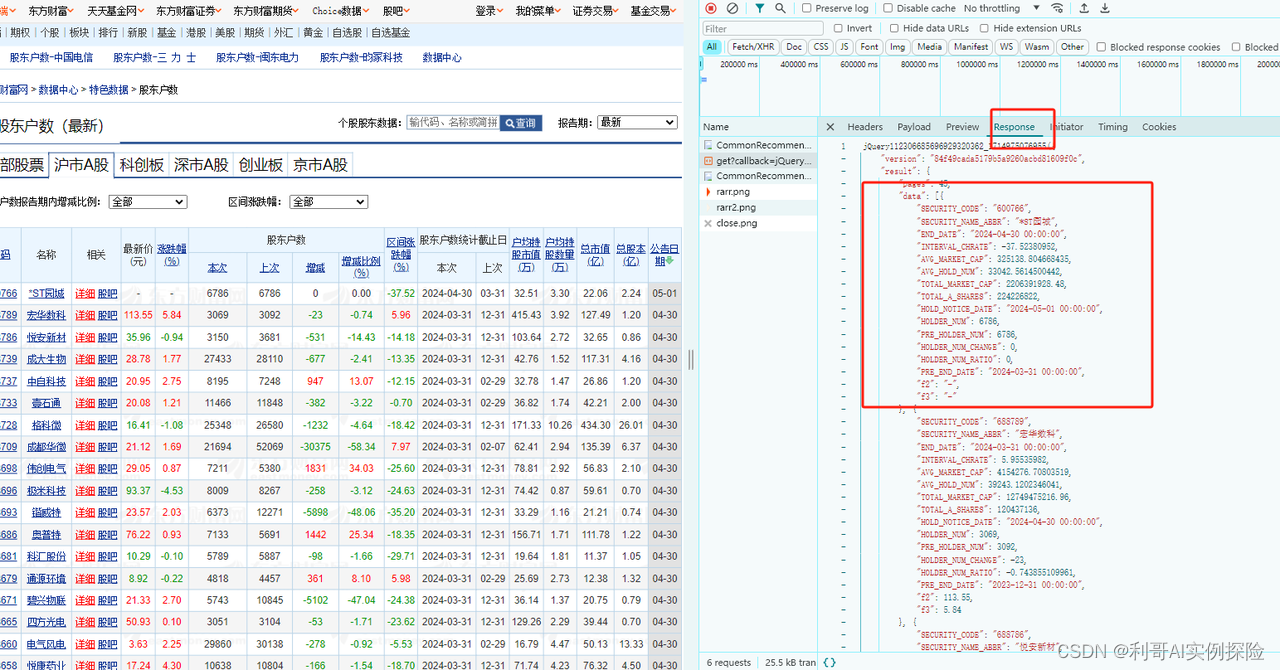
2. 爬取数据代码逻辑
如下即爬取数据的可运行代码,复制后直接能跑:
import pandas as pd
from typing import List
import requestsclass CustomedSession(requests.Session):def request(self, *args, **kwargs):kwargs.setdefault('timeout', 60)return super(CustomedSession, self).request(*args, **kwargs)
session = CustomedSession()
adapter = requests.adapters.HTTPAdapter(pool_connections = 50, pool_maxsize = 50, max_retries = 5)
session.mount('http://', adapter)
session.mount('https://', adapter)# 请求地址
QEURY_URL = 'http://datacenter-web.eastmoney.com/api/data/v1/get'
# HTTP 请求头
EASTMONEY_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',# 'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
}# 请求返回值过滤
RESULT_FIELDS = {'SECURITY_CODE': '股票代码','SECURITY_NAME_ABBR': '股票名称','END_DATE': '本次股东户数统计截止日','PRE_END_DATE': '上次股东户数统计截止日','INTERVAL_CHRATE': '区间涨跌幅','AVG_MARKET_CAP': '户均持股市值','AVG_HOLD_NUM': '户均持股数量','TOTAL_MARKET_CAP': '总市值','TOTAL_A_SHARES': '总股本','HOLD_NOTICE_DATE': '公告日期','HOLDER_NUM': '本次股东户数','PRE_HOLDER_NUM': '上次股东户数','HOLDER_NUM_CHANGE': '股东户数增减','HOLDER_NUM_RATIO': '股东户数较上期变化百分比', 'f2': '最新价','f3': '涨跌幅百分比',
}"""
获取沪深A股市场最新公开的股东数目变化情况: 当作获取所有股票
"""
def get_latest_holder_number() -> pd.DataFrame:# 请求页码QEURY_PAGE = 1PAGE_COUNT = 100dfs: List[pd.DataFrame] = []while 1:if QEURY_PAGE > PAGE_COUNT:break# 请求参数QUERY_PARAM = [('sortColumns', 'HOLD_NOTICE_DATE,SECURITY_CODE'),('sortTypes', '-1,-1'),('pageSize', 500),('pageNumber', QEURY_PAGE),('columns', 'SECURITY_CODE,SECURITY_NAME_ABBR,END_DATE,INTERVAL_CHRATE,AVG_MARKET_CAP,AVG_HOLD_NUM,TOTAL_MARKET_CAP,TOTAL_A_SHARES,HOLD_NOTICE_DATE,HOLDER_NUM,PRE_HOLDER_NUM,HOLDER_NUM_CHANGE,HOLDER_NUM_RATIO,END_DATE,PRE_END_DATE',),('quoteColumns', 'f2,f3'),('source', 'WEB'),('client', 'WEB'),('reportName', 'RPT_HOLDERNUMLATEST'),]params = tuple(QUERY_PARAM)response = session.get(QEURY_URL, headers=EASTMONEY_REQUEST_HEADERS, params=params)resultJson = response.json()PAGE_COUNT = resultJson.get('result').get('pages')print('json len=', len(str(resultJson)), 'page count=', PAGE_COUNT, 'page number=', QEURY_PAGE)if PAGE_COUNT is None:breakdata = resultJson.get('result').get('data')if data is None:breakdf = pd.DataFrame(data)df = df.rename(columns=RESULT_FIELDS)[RESULT_FIELDS.values()]dfs.append(df)QEURY_PAGE += 1if len(dfs) == 0:df = pd.DataFrame(columns=RESULT_FIELDS.values())return dfdf = pd.concat(dfs, ignore_index=True)return dfif __name__ == "__main__":data = get_latest_holder_number()print(data)
调用如上函数即可:
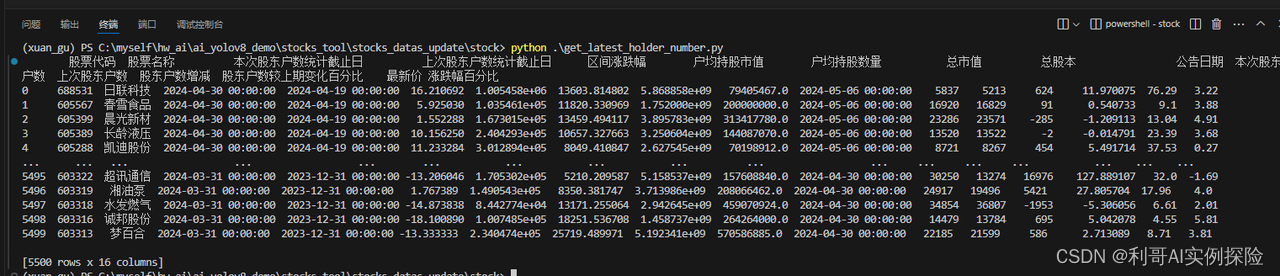
3. 将爬取的数据通过ORM形式写入数据库
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float, Index
from sqlalchemy.orm import declarative_base, sessionmaker
from sqlalchemy.orm import scoped_session
from datetime import datetime# 声明一个基类,所有的ORM类都将继承自这个基类
Base = declarative_base()# 创建引擎
engine = create_engine('sqlite:///a.db', echo=False)
# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象conn
session = scoped_session(Session)# 股票基础信息表
class stock_base_info(Base):__tablename__ = 'stock_base_info'SECURITY_CODE = Column(String, primary_key=True, index=True, nullable=False, comment="股票代码")SECURITY_NAME_ABBR = Column(String, nullable=False, comment="股票名称")TOTAL_MARKET_CAP = Column(Float, comment="总市值")TOTAL_A_SHARES = Column(Float, comment="总股本")HOLD_NOTICE_DATE = Column(String, comment="公告日期")HOLDER_NUM = Column(Integer, comment="本次股东户数")HOLDER_NUM_RATIO = Column(String, comment="股东户数较上期变化百分比")PRE_HOLDER_NUM = Column(Integer, comment="上次股东户数")f2 = Column(String, comment="股票价格")last_updated = Column(DateTime, default=datetime.now, onupdate=datetime.now, comment="最后更新时间")__table_args__ = (Index('idx_SECURITY_CODE_index', SECURITY_CODE, unique=True),)# 创建表, 创建所有class xx(Base)
Base.metadata.create_all(engine) def insert_or_update_stock_info(net_list):all_instances = session.query(stock_base_info).all()db_list = []for v in all_instances:db_list.append({'SECURITY_CODE': v.SECURITY_CODE,'SECURITY_NAME_ABBR': v.SECURITY_NAME_ABBR,'TOTAL_MARKET_CAP': v.TOTAL_MARKET_CAP,'TOTAL_A_SHARES': v.TOTAL_A_SHARES,'HOLD_NOTICE_DATE': v.HOLD_NOTICE_DATE,'HOLDER_NUM': v.HOLDER_NUM,'HOLDER_NUM_RATIO': v.HOLDER_NUM_RATIO,'PRE_HOLDER_NUM': v.PRE_HOLDER_NUM,'f2': v.f2,})# 查询出库中所有的数据 db_list; 从爬取的数据 net_list 中找到库中已有的数据进行更新 形成 db_map 并批量更新# 将 net_list 中不在 db_list 中的数据,形成 net_map 并批量插入db_map, not_exist_map = {}, {}for v in db_list:db_map[v['SECURITY_CODE']] = vfor item in net_list:code = item['SECURITY_CODE']if code in db_map:db_map[code].update(item)else: not_exist_map[code] = itemupdate_result = list(db_map.values())insert_result = list(not_exist_map.values())if len(update_result) > 0:session.bulk_update_mappings(stock_base_info, update_result)if len(insert_result) > 0:session.bulk_insert_mappings(stock_base_info, insert_result)session.commit()if __name__ == "__main__":pass
4. 整体逻辑流程
步骤:
- 爬取数据得到返回结果
- 将返回结果组成数组,并写入数据库
- 对于库中已存在的信息根据 股票代码 进行批量更新,对于不存在的进行批量插入
import stock
import db_ormdef update_base_info_db():data_df = stock.get_latest_holder_number()print('获取的股票数量=', data_df.shape)net_list = []for index, row in data_df.iterrows():code = row['股票代码']name = row['股票名称']cap = row['总市值']shares = row['总股本']data = row['公告日期']num = row['本次股东户数']pre_num = row['上次股东户数']ratio = row['股东户数较上期变化百分比']f2 = row['最新价'] # float类型net_list.append({'SECURITY_CODE': code,'SECURITY_NAME_ABBR': name,'TOTAL_MARKET_CAP': cap,'TOTAL_A_SHARES': shares,'HOLD_NOTICE_DATE': data,'HOLDER_NUM': num,'HOLDER_NUM_RATIO': ratio,'PRE_HOLDER_NUM': pre_num,'f2': str(f2),})if len(net_list) > 0:db_orm.insert_or_update_stock_info(net_list=net_list)if __name__ == "__main__":update_base_info_db()
最终结果保存在 a.db中,例如:
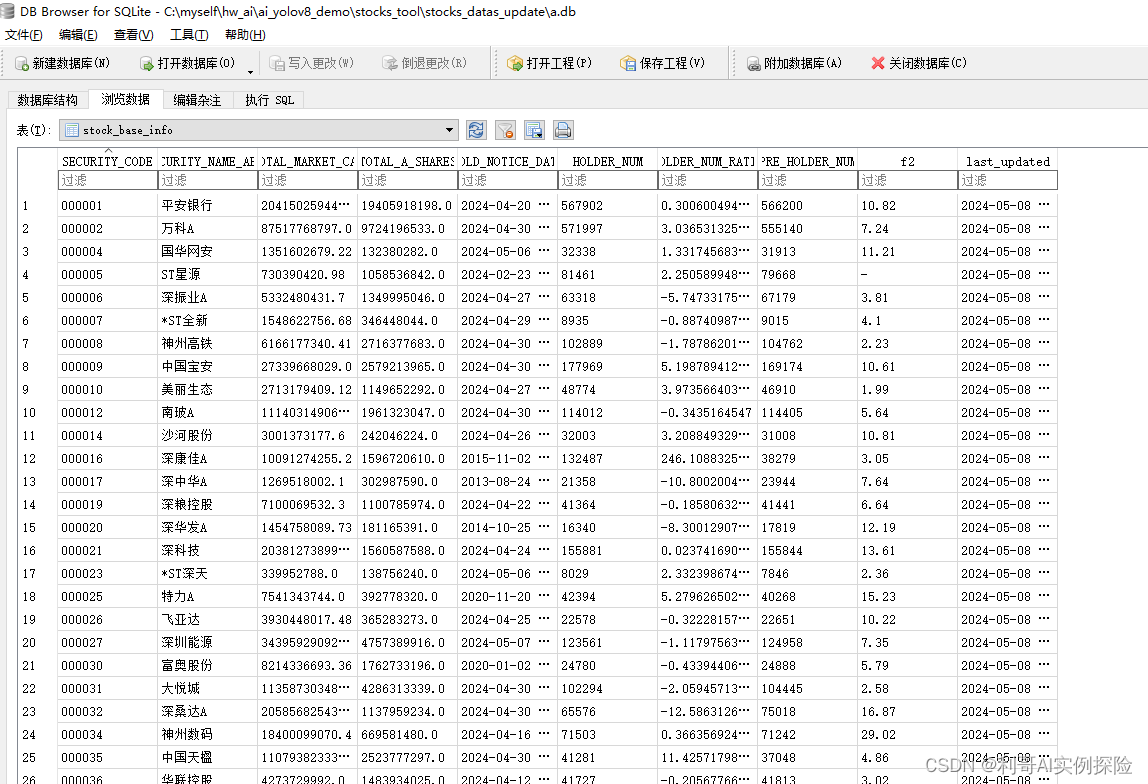
更多内容可关注我,后续源码包均在上面回复下载:
【爬虫】爬取A股数据系列工具