一个自动问答系统可分为问句处理和答案检索两大部分。
在一个面向电影领域知识的问答系统中,把所有数据存放在mysql数据库中,用非结构数据库neo4j(也称图形属性数据库)构造电影图谱,在电影图谱的基础上进行答案检索。之所以不直接从mysql数据库中检索所有数据是因为关系型数据库mysql的查询效率不高。那么又为什么不直接把所有信息存放在非结构数据库neo4j上呢?反正我们是通过这个数据库进行检索的。这是因为mysql数据库增删查改操作更加方便,而neo4j的每次改动都需要重新构造图谱以覆盖。事实上这也是比较“工程性”的思想。
首先是我们的数据格式。对于每一部电影我们的信息组织如下:
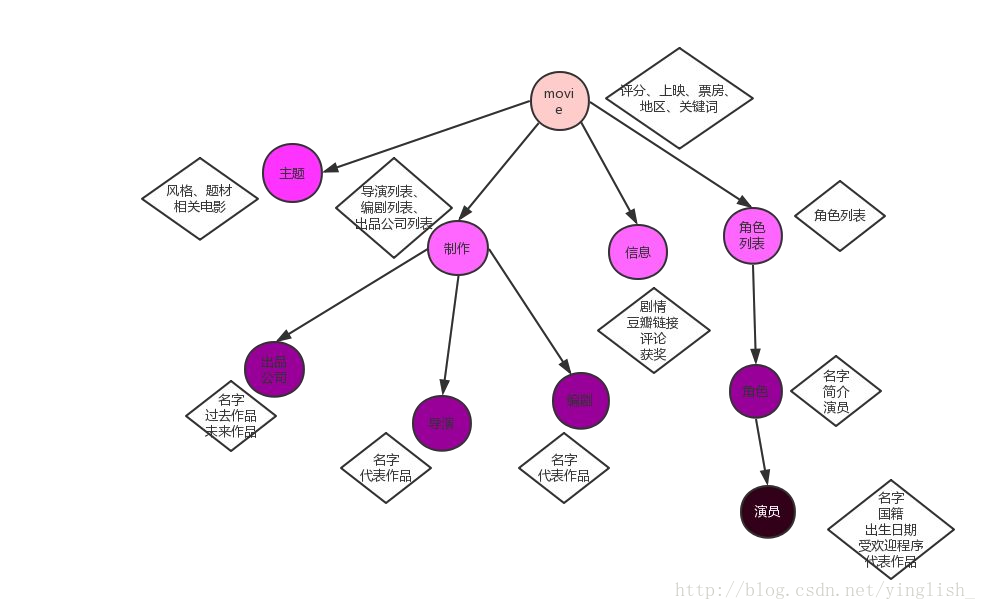
这个图也是neo4j数据库将构造出来的图谱,基于其中的结点、关系、属性,我们进行答案检索。
接着问句处理,包括:命名实体词典的构建、问题抽象、问题分类和问题还原、答案生成。
对于用户输入的一个问句,我们首先都是进行hanlp分词,由于hanlp自己提供的通用型命名实体工具包在电影领域上的分词效果可能没有想象中那么好,很多电影名诸如“我不是潘金莲”“爱乐之城”“巴黎危机”等等都无法识别出来,因此我们人工标注了很多词典,包括演员名、导演名和电影名等作为Hanlp的自定义词典,把这些词典放在hanlp词典的data/dictionary/custom/文件目录下。在项目的hanlp.properties(bin目录下)里改动root路径为hanlp词典所在文件路径,在CustomDictionaryPath中添加词典名,空格表示同个目录下。我们自定义的词性包括:电影名 nm;电影角色名 nnt等等。
而问题的抽象,说白了就是用电影名、角色名的词性nm和nnt来代替这些专有词。这样做是为了简化下一步的问句分类器的选取工作量,也缩减训练集的规模,毕竟电影名和角色名是层出不穷、五花八门的,干扰性比较强。一个问句“长城的导演是谁”会被抽象为“nm 的导演是谁”,问句“美人鱼中谁演八哥”被抽象为“nm中谁演nnt”。
问题分类,我们采用的是分类到模板的方法。比如说我们猜想关于询问一部电影的导演的相关信息可能有“nm的导演是谁”“谁是nm的导演”“nm是谁执导的”“谁执导了nm”四种问法,然后我们希望通过分类器,只要抽象化后的问句是这以上四种,就统一返回模板“nm 制作 导演列表”或者“nm 制作 导演 代表作品”(取决于更具体一点的问句信息),之所以采用模板,是为了图的检索便利,观察我们上面的那个电影信息组织方式,归一化后的模板都是严格按照图的结点/属性/关系排列的。但是这种方法的缺点是人工量比较大,所能处理的问句远达不到口语化的程度,因为问句都是我们人工尽最大可能想出来,也只是我们所能想到的。在此基础上,我们整合一张所有问句分词后的高频词语,用以构造新问句的特征矩阵,采用spark的贝叶斯分类器,实现对输入的问句归一化到最终的24个模板的目的。流程图如下:

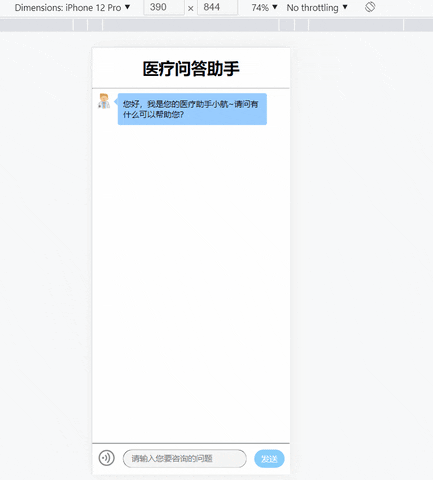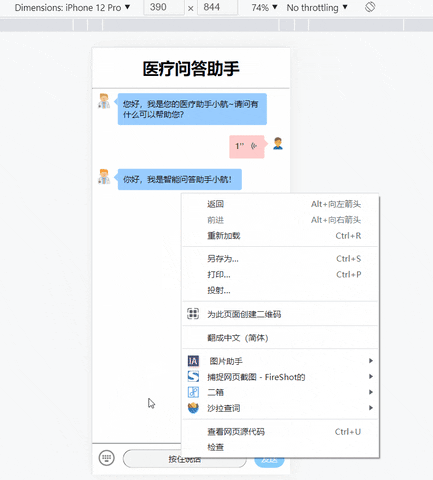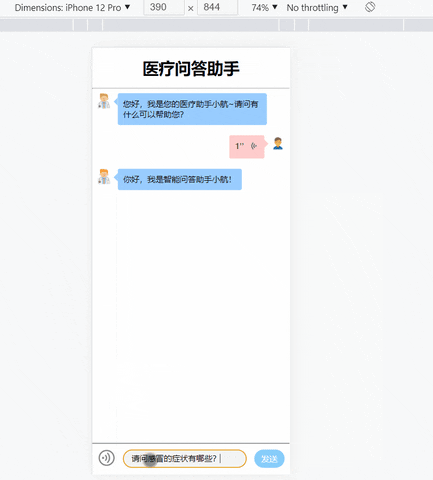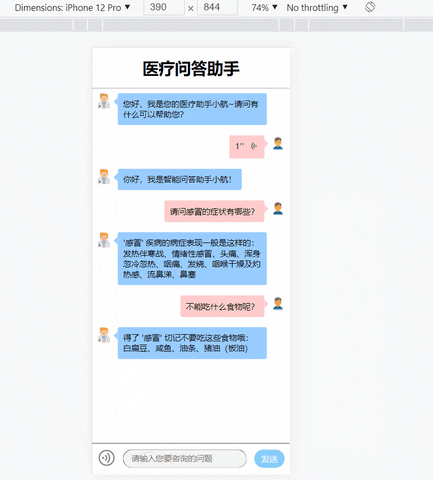
通过以上的步骤,对于一个问句“美人鱼中谁演八哥”-》“nm 中谁演nnt” -》归化到模板:“nm 角色列表 角色 nnt 演员 名字”,问句还原就是还原nm和nnt,最后得到“美人鱼 角色列表 角色 八哥 演员 名字”并到我们的neo4j图形数据库中检索。关于neo4j的部分,这里将不写了,详细可以看我写的其他博客。项目中需要导入neo4j/hanlp/spark相关jar包,这是我们的问句处理和最后检索答案的效果:

相关代码可见我的github
关于两个数据库的操作,有心得以后可以再写。