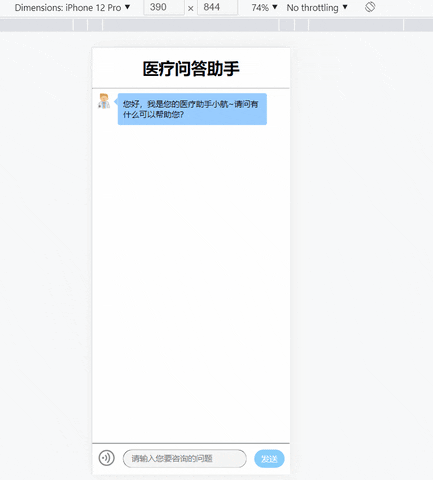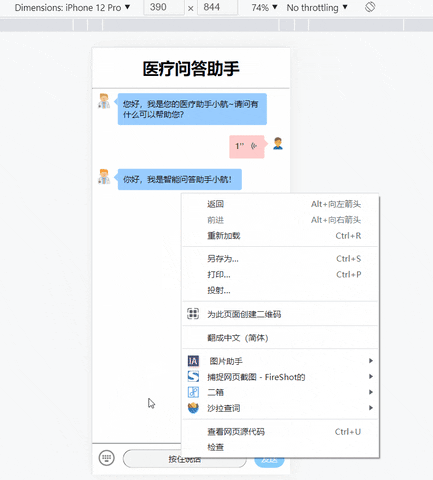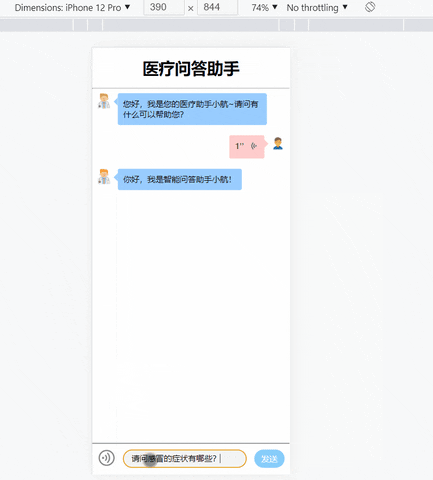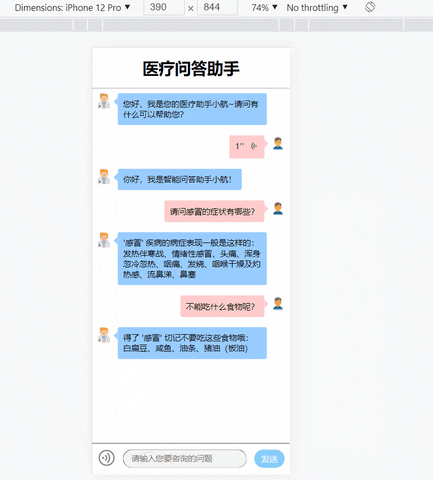
基于知识图谱的问答系统
发布时间:2018-06-10 21:27,
浏览次数:561
基于知识图谱的问答系统
一.准备工作:
1.下载好java8,并用mysql创建好数据库–重点在于存储数据
2.spark安装–用来进行提问问题的分类算法的编写
3.进行neo4j–用来存储mysql对应的数据库的关系–重点在于存储关系
4.之后在mysql当中将相应数据库当中的表格进行导出为csv文件,便于neo4j图形数据库的读取.将导出的csv文件放在import文件夹当中.
5.安装hanlp中文分词器—这个主要是用来对
所输入的问题进行词语提取,形成一个词向量,之后使用后面会讲到的贝叶斯分类算法,得到该问题在不同问题模版上的匹配概率,取最大的概率,确定为该问题的匹配模版.第三节会讲到.
二.设计贝叶斯分类算法
1.创建进程—(为了后面并行处理分类问题的计算,提高训练速度与测试速度)
2.创建向量–(denseVecto与sparseVector)–稠密向量与稀疏向量
Dense Vector and Sparse Vector。在spark.ml.linalg里有两种vector——DenseVector 和
Sparse Vector,两者都继承于Vectors。
区别:
DenseVector: a value array--(直接把所有的元素都列出来了)` def: Vectors.dense(values:
Array[Double]) SparseVector : an indexand a value
array--(存储元素的个数、以及非零元素的编号index和值value)def: Vectors.sparse(size: Int, indices:
Array[I