本节对知识问答的概念做一个概述并介绍KBQA实现过程中存在的挑战,而后对知识问答主流方法做一个介绍。
- 知识问答简介
- 知识问答简单流程与分类
- KBQA的基本概念和挑战
- 问答系统的基本组件
- 技术挑战
- 知识问答主流方法介绍
- 基于模板的方法
- 模板定义
- 模板生成
- 模板匹配与实例化
- 排序打分
- TBSL的主要缺点
- 基于语义解析的方法
- 资源映射
- 逻辑表达式
- 基于深度学习的方法
- 基于模板的方法
- Ref
知识问答简介
问答系统的历史如下图所示:

可以看出,整体进程由基于模板到信息检索到基于知识库的问答。基于信息检索的问答算法是基于关键词匹配+信息抽取、浅层语义分析。基于社区的问答依赖于网民贡献,问答过程依赖于关键词检索技术。基于知识库的问答则基于语义解析和知识库。
根据问答形式可以分为一问一答、交互式问答、阅读理解。一个经典的测评数据集为QALD,主要任务有三类:
- 多语种问答,基于Dbpedia
- 问答基于链接数据
- Hybrid QA,基于RDF and free text data
知识问答简单流程与分类

上图为知识问答的简单流程,首先将用户输入的问句经过语义匹配等转换为查询语言进行查询和推理,而后得到答案再进行组合以形成人类可阅读的文本。
传统的问答方法是基于符号表示的,常用的有:
- 基于关键词的检索
- 基于文本蕴含推理
- 基于逻辑表达式
一个简单的基于符号表示的例子如:

基于深度学习的问答方法是基于分布式表示的,常用的有:
- LSTM
- Attention Model
- Memory Network
KBQA的基本概念和挑战
下面对一些基本概念做一个总结:
- 问句短语定义问的是什么? 如wh-words: who, what, when…
- 问题类型:问题类型决定了后续采用什么样的回答处理策略,如事实型问题、观点型问题、因果型问题、方法型问题等。
- 答案类型: 如实体、地理位置、时间等。
- 问题主题:问题是关于哪方面的?如 “世界上最高的山是?” 它就和地理、山峰这两个相关。
- 问答来源类型: 包含是不是结构化的数据、数据的来源等。
- 领域类型:如开放领域还是特定领域、多模态问答还是其他的。
- 答案格式:是司法文书还是定义式的短答案等。
- ……
问答质量如何评估呢?一般有6个原则,包含相关度、正确度、精炼度、完备度、简单度、合理度。
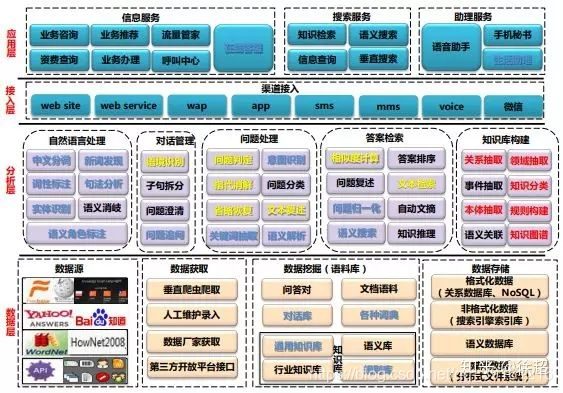
问答系统的基本组件
如下图所示:

该系统使用自然语言问题作为输入,经由:
- 数据预处理:处理数据库数据,包含索引、数据清理、特征提取等。
- 问题分析:执行语法分析,同时检测问题的核心特征,如NER、答案类型等。
- 数据匹配:将问题里的terms 和数据里的实体进行匹配。
- 查询创建:生成结构查询候选。
- 排序
- 结果返回与生成:执行查询并从结果里抽取答案。
技术挑战
- 怎样缩小自然语言和规范化结构化数据之间的鸿沟
- 怎样处理不完全、充满噪音和异构的数据集.
- 怎样处理大规模的知识图谱
- 怎样处理分布式数据集上的QA
- 怎样融合结构化和非结构化的数据
- 怎样降低维护成本
- 怎样能快速的复制到不同的领域
知识问答主流方法介绍
KBQA常用的主流方法有 基于模板的方法、基于语义解析的方法、基于深度学习的方法。下面分别对其进行详细介绍。
基于模板的方法
基于模板的方法包含模板定义、模板生成,模板匹配三大部分。论文参见TBSL(Unger et al.2012)。
为了理解用户的问题,我们要理解:
-
问题中的词汇:如died in →→ dbo:deathPalce
-
问题的语义结构:如 the most N →→ ORDER BY DESC(COUNT(?N)) LIMIT 1
基于模板问答的目标就是将语义结构分析和词映射到URIs,该方法有两个重要的步骤:
-
模板生成:将问题解析为SPARQL模板,该模板能直接反应问题的结构如filters 和 aggregation 这样的操作。
-
模板实例化:通过匹配自然语言表达式和本体概念来实例化SPARQL 模板。
举个例子:

TBSL的架构如下图所示:

模板定义
结合KG的结构,以及问句的句式,进行模板定义。通常没有统一的标准或格式。TBSL的模板定义为SPARQL query模板,将其 直接与自然语言相映射。
模板生成
模板生成大致分为如下四个步骤:
- 获取自然语言问题的POS 标记信息
- 基于POS 标记、语法规则表示问句
- 利用领域相关或领域无关词汇辅助解决问题
- 最后将语义表示转化为一个SPARQL 模板
例如:

模板匹配与实例化
有了SPARQL模板以后,需要进行实例化与具体的自然语言问句相匹配。即将自然语言问句与知识库中的本体概念相映射的过程。
对于resource 和 class实体识别,用WordNet 定义知识库中标签常用方法或计算字符串相似度。对于property标签,将还需要与存储在BOA 模式库中的自然语言进行比较,最高排位的实体将作为填充查询槽位的候选答案。如:

排序打分
首先每个entity 根据 string similarity 和 prominence 获得一个打分。一个query 模板的分值根据填充slots 的多个entities 的平均打分。在检查type 类型后,对于全部的查询机和,仅返回打分最高的。
TBSL的主要缺点
-
创建的模板未必和知识图谱中的数据建模相契合
-
考虑到数据建模的各种可能性,对应到一个问题的潜在模板数量会非常多,同时手工准备海量模板的代价也非常大。
那模板能否自动生成呢?据此有人提出了 QUINT,它能够根据utterance-answer 对, 根据依存树自动学习utterance-query 模板。该方法利用了自然语言组成的特点,可以使用从简单问题中学到的模板来解决复杂问题。QUINT架构如下图所示:

基于语义解析的方法
语义解析经典方法参考
基于语义解析的方法大致包含四个部分: 资源映射、逻辑表达式、候选答案生成、排序。

资源映射
资源映射将自然语言短语或单词节点映射到知识库的 实体 或 实体关系。 可以通过构造一个词汇表(Lexicon)来完成这样的映射。而后通过逻辑表达式解决文本的歧义。对于复杂映射如”was also born in” 到 PlaceOfBirth这种,就较难通过字符串匹配的方式建立映射,对此我们可以采用统计方法。如e1 和 e2经常出现在这两个词的两侧,那么我们就认为可以建立映射。

逻辑表达式
逻辑表达式是一种能让知识库”看懂“的表示,可以表示知识库中的实体、实体关系,并且可以想数据库语言一样,进行Join,求教及和聚合等操作。逻辑形式通常可分为一元形式和二元形式,一元实体是指对应知识库中的实体,二元实体关系是对应知识库中所有与该实体相关的三元组中的实体对。
基于深度学习的方法
KBQA 与深度学习结合的两个方向,第一个是利用深度学习对于传统问答方法进行改进,另一个是基于深度学习的端到端模型。

目前基于深度学习的方法无须像模板方法那样人工编写大量模板,也无须像语义分析方法中人工编写大量规则,整个过程都是自动进行。但缺点也很明显,它目前只能处理简单问题和单边关系,对于复杂问题不如两种传统方法效果好。同时由于DL方法通常不包含聚类操作,因此对于一些时序敏感性问题无法很好的处理。
Ref
王昊奋知识图谱教程
Semantic parsing via paraphrasing
Template-based question answering over RDF data
Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base
Semantic parsing on freebase from question-answer pairs
An End-to-End Model for Question Answering over Knowledge Base with Cross-Attention Combining Global Knowledge Information
Question Answering over Freebase with Multi-Column Convolutional Neural Networks
Question Answering with Subgraph Embedding
A Graph Traversal Based Approach to Answer Non-Aggregation Questions over DBpedia
Automated Template Generation for Question Answering over Knowledge Graphs