视觉问答项目
1. 项目地址
本笔记项目包括如下:
-
MCAN(Deep Modular Co-Attention Networks for Visual Question Answering)用于VQA的深层模块化的协同注意力网络
- 项目地址:MCAN_paper
- 代码地址:MCAN_code
-
murel(Multimodal Relational Reasoning for Visual Question Answering)视觉问答VQA中的多模态关系推理
- 项目地址:murel_paper
- 代码地址:murel_code
-
block(Multimodal Relational Reasoning for Visual Question Answering)用于VQA的双线性超对角融合模型
- 项目地址:block_paper
- 代码地址:block_code
-
ReGAT(Relation-Aware Graph Attention Network for Visual Question Answering)关系感知图注意力网络来提高VQA对图像中复杂语义的理解
- 项目地址:ReGAT_paper
- 代码地址:ReGAT_code
-
CMR(Cross-Modality Relevance for Reasoning on Language and Vision)语言和视觉推理的跨模态关联
- 项目地址:CMR_paper
- 代码地址:CMR_code
2. 项目具体
2.1 MCAN项目
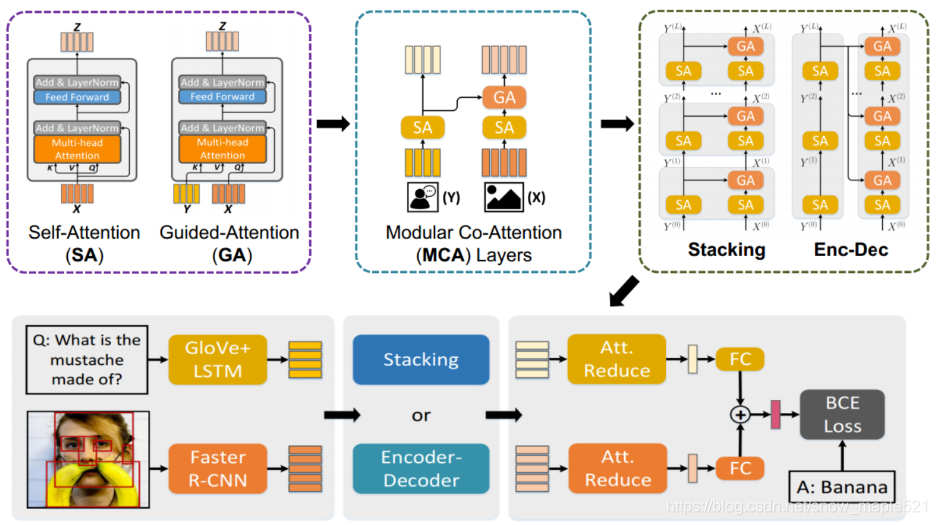
作者认为协同注意力只能够学习到多模态之间粗糙的交互,而且也不能进行图像和问题关键词之间的关系推断,为了解决协同注意力不能够进行多模态之间的充分交互问题,目前提出了两个密集协同注意力模型(dense co-attention model)——BAN和DCN。有趣的是,这两个模型是可以串联在一起解决更深层次的视觉推理。但是这两个模型相较于浅层模型却仅有很小的性能提升,作者认为原因在于这两个模型没有同时在每一个模态中对密度自注意力建模。
作者提出了深层协同注意力网络MCAN(由协同注意力模块MCA层串联构成)。每一个MCA层都能够对图像和问题的注意力进行建模。一个自注意力单元(self-attention (SA) unit)进行模态内部交互和一个导向注意力单元(guided-attention (GA) unit)进行模态之间交互。之后再用一个协同注意力模块层(Modular Co-Attention (MCA) layers)将两个单元串联起来,最后将多个模块层串联起来,组成MCAN网络(Modular Co-Attention Network (MCAN)
2.1.1 MCAN项目架构
2.1.2 MCAN项目数据集
MCAN数据集也是采用Bottom up处理好的图像特征不过这里不是tsv文件格式也不是pth文件格式也不是hdf5文件格式,而是转换成npz文件格式。如下:

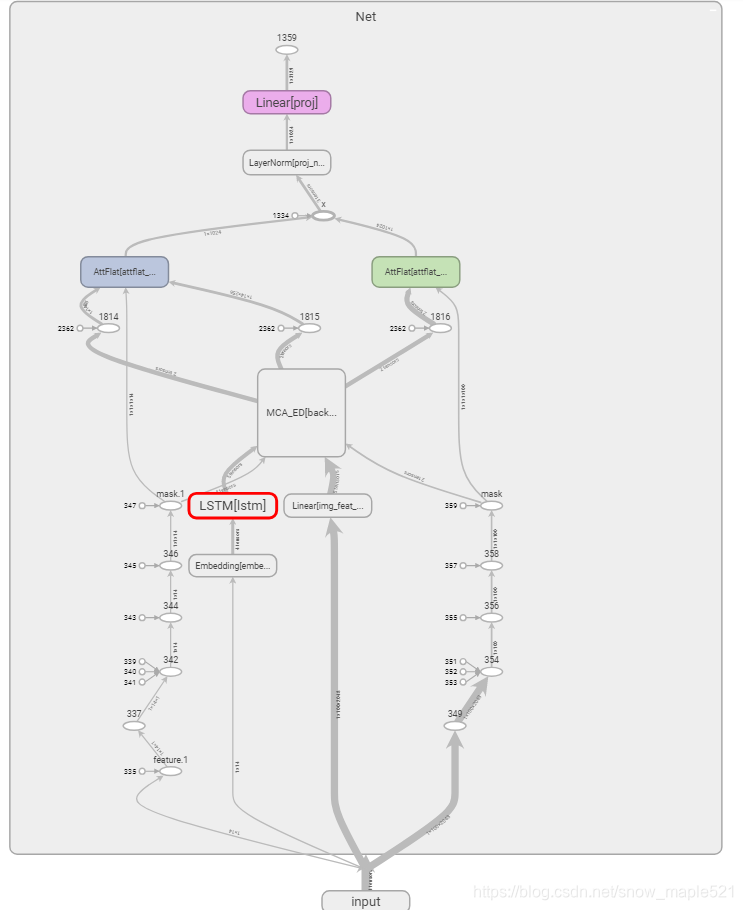
2.1.3 MCAN项目模型
2.2 block项目
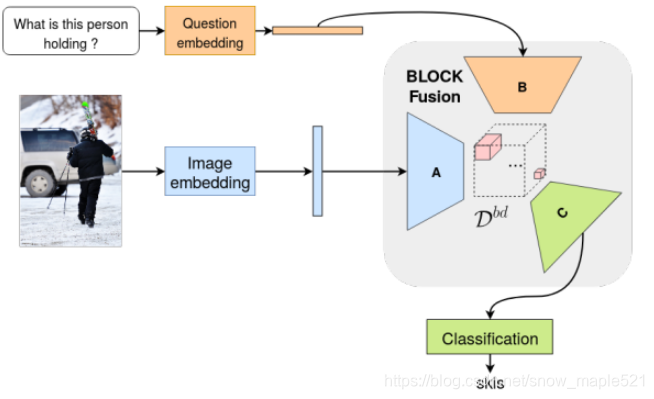
block项目是关于视觉问答的多模态融合策略开发的,作者认为多模态如果仅经过简单的内积会产生非常高维度的权重张量,为了解决这个问题,作者引入新的多模态融合策略,它基于块-超对角张量分解技术。它使用了块项秩(block-term ranks)的概念,能够对张量的“秩”和“模态秩”的概念进行泛化,已多用于多模态融合
2.2.1 block在VQA中应用的框架
2.2.2 block数据集
block项目作者为了比较其性能,分别在VRD和VQA任务上都做了实验,本文只针对VQA进行讲解。

- 数据集下载:
-
coco:MSCOCO原始图像数据集
-
vqa2:VQA相关的原始json文件

经过数据预处理后的文件:
-
coco_extract_rcnn:根据MSCOCO原始数据集以及其annotations的json文件并添加了注意力信息后,利用faster-r-cnn提取的图像特征提取的包含图像空间位置特征等信息的图像特征。
-
2.2.3 block模型
模型中传入需要用到的特征
def forward(self, batch):v = batch['visual']q = batch['question']l = batch['lengths']q = self.process_question(q, l)v = self.attention(q, v)logits = self.fusion([q, v])out = {'logits': logits}return out
2.3 murel项目
murel项目是在VQA任务中引入一个MUREL,一种能够在真实图像中学习端到端推理的多模态关系网络,作者认为虽然目前注意力机制在VQA中表现了很好的效果,但是这种简单的机制不足以处理复杂的推理特征。
VQA任务的关键是解决两种特征向量的高层次相关性的表示,在目前的多模态融合方法里面,比较有效的是二阶交互或张量分解,在VQA关系推理中,目前多用的是软注意力机制,根据问题,模型会对每个区域进行重要性评分,然后再用权重求和的池化方法进行可视化表示,多重注意力可以通过并行或者顺序计算。
本文贡献:本文作者移除了传统的注意力结构,采用了向量化表示,对每个区域的视觉内容和问题之间的语义进行建模,此外作者还在表示中加入了空间和语义上下文的概念,即通过视觉嵌入和空间坐标之间的交互来表示成对的图像区域。
2.3.1 murel在VQA中应用的框架
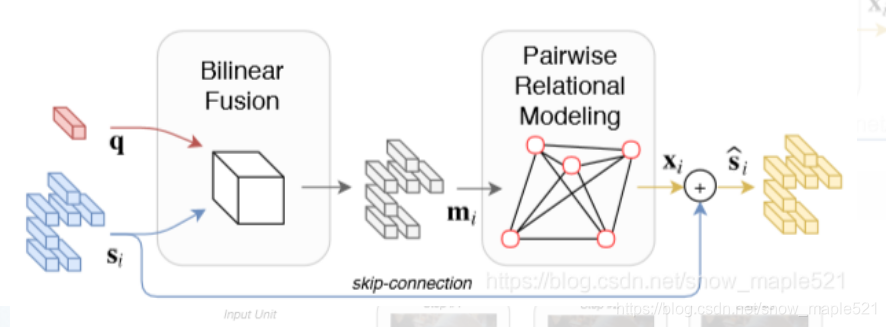
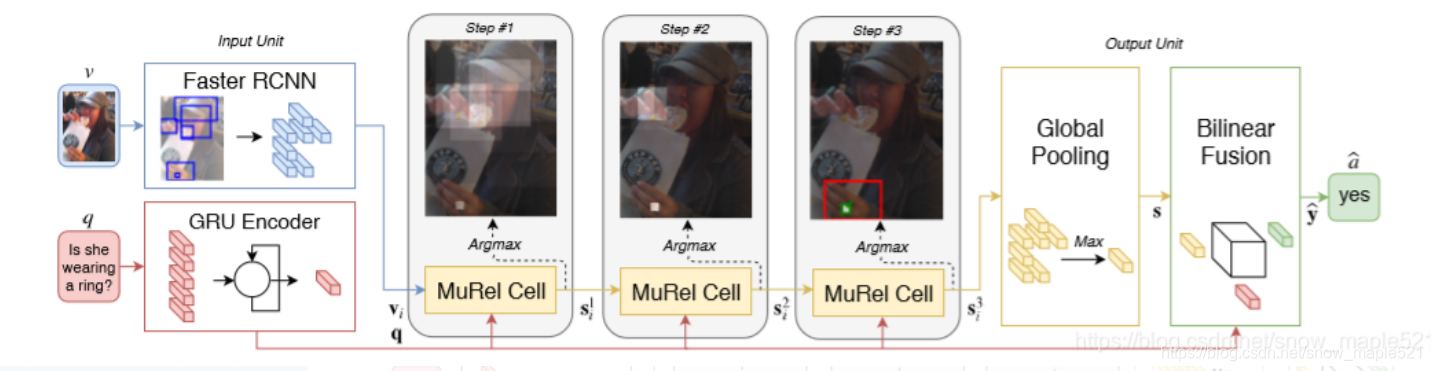
2.3.2 murel数据集
Murel用的数据集同block相同,murel数据集中图像的特征不仅只是像素还包括了位置信息。提取一个batch时采用如下:
2.3.3 murel模型
模型需要传入的特征如下(发现比block多了个 c = batch[‘norm_coord’]):
def forward(self, batch):v = batch['visual']q = batch['question']l = batch['lengths'].datac = batch['norm_coord'] #规范化目前坐标q = self.process_question(q, l)bsize = q.shape[0]n_regions = v.shape[1]q_expand = q[:,None,:].expand(bsize, n_regions, q.shape[1])q_expand = q_expand.contiguous().view(bsize*n_regions, -1)# cellmm = vfor i in range(self.n_step):cell = self.cell if self.shared else self.cells[i]mm = cell(q_expand, mm, c)if self.buffer is not None: # for visualizationself.buffer[i] = deepcopy(cell.pairwise.buffer)if self.agg['type'] == 'max':mm = torch.max(mm, 1)[0]elif self.agg['type'] == 'mean':mm = mm.mean(1)if 'fusion' in self.classif: #如果存在融合策略,则融合logits = self.classif_module([q, mm])elif 'mlp' in self.classif: #如果存在mlp,则采用感知器logits = self.classif_module(mm)out = {'logits': logits}return out
2.4 ReGat项目
作者认为只是考虑显示关系或者隐式关系是不够的,为了充分理解图像中的视觉场景,特别是不同对象之间的交互,我们提出一个关系感知图注意网络:它将每幅图片编码成一个图,并通过图注意机制建立多类型的对象间关系模型,以学习问题自适应关系表示,同时探讨了两种视觉对象关系:(1)表示对象之间几何位置和语义交互的显示关系。(2)捕捉图像区域之间隐藏动态的隐式关系。
2.4.1 ReGAt项目框架
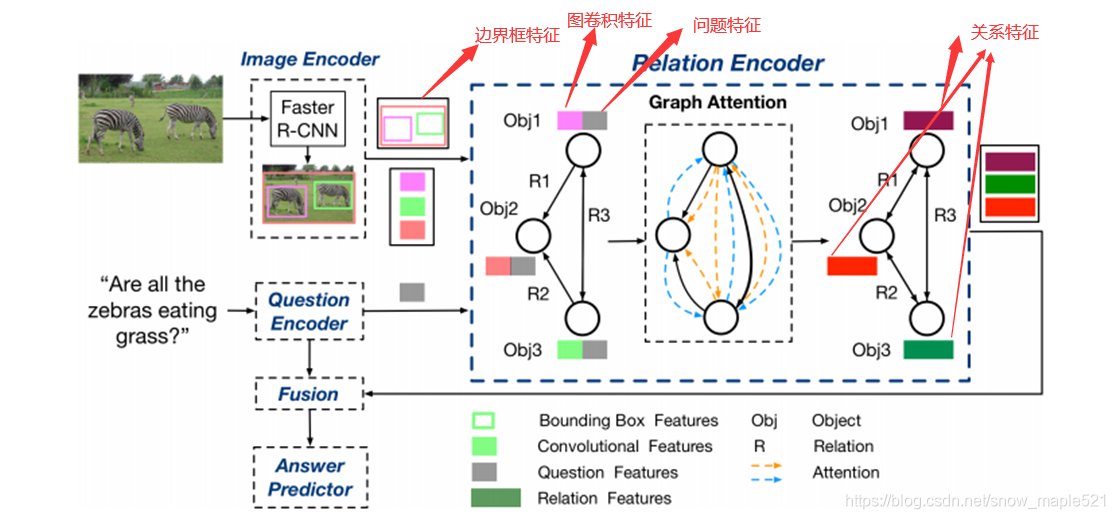
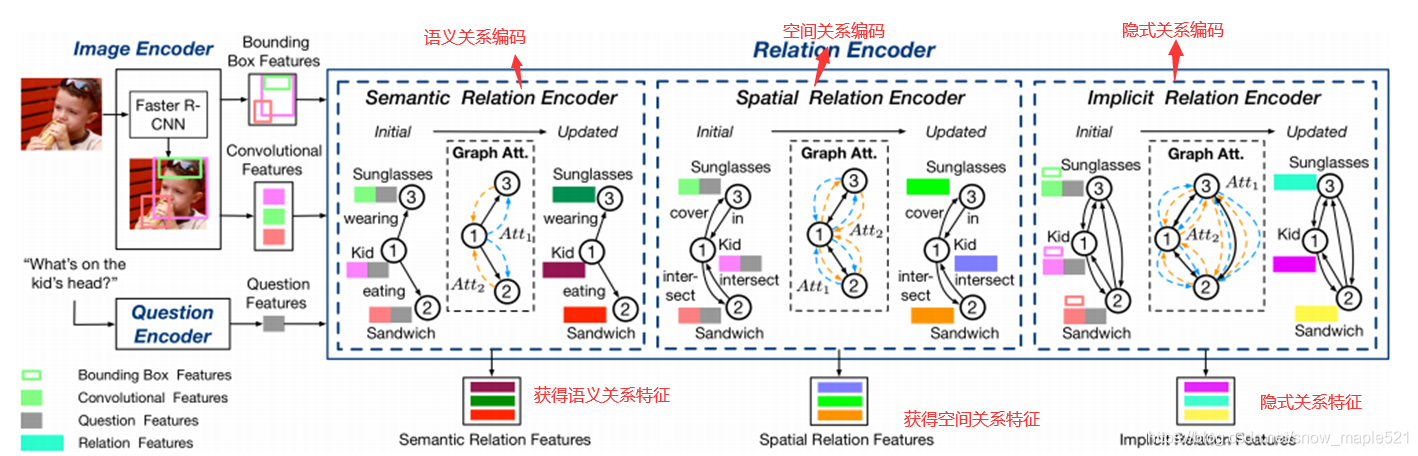
2.4.2 ReGAt项目数据集
ReGAt项目也是用到了bottom-up attention features ,如下:

下载后会得到trainval_resnet101_faster_rcnn_genome_36.tsv行式的tsv文件,其中文件中包含如下内容:
FIELDNAMES = ['image_id', 'image_w','image_h','num_boxes', 'boxes', 'features']
其中item['boxes']为对应检测框的位置信息 x,y,w,h
item[''boxes'].shape=(num_boxes,4)
item['features']为对应检测框 在pool5_flat 层的特征
item['features'].shape=(num_boxes, feature_dim)
item['num_boxes'] 为该张图片对应的检测框数目
注意到源码中写到
return {'image_id': image_id,'image_h': np.size(im, 0),'image_w': np.size(im, 1),'num_boxes' : len(keep_boxes),'boxes': base64.b64encode(cls_boxes[keep_boxes]),'features': base64.b64encode(pool5[keep_boxes])} 所以在读取 .tsv文件是,需要用到base64.decodestring()解码
不过本文在作者提供下载的链接中是下载了已经通过读取tsv文件转换成hdf5文件的格式。
图像:

问题:

答案:

glove数据集

处理好的图像id:
预训练模型
预训练模型需要的pickle缓存

2.4.3 ReGat模型

(模型图:后续补上)
3. 项目总结
这几个项目所用到的都是Bottom up提取好的图像特征,只是存储方式不同,具体如下
| 项目 | 图像特征格式 | 数据集 |
|---|---|---|
| MCAN | ****.img.nbz | 36个固定区域特征 |
| block | ****.img.pth | 36个固定区域特征 |
| murel | ****.img.pth | 36个固定区域特征 |
| ReGat | train.hdf5,test.hdf5,val.hdf5 | 36个固定区域特征和10-100自适应特征 |