PS:这是我的文献阅读大作业~
文章目录
- 问答系统综述报告
- 1. 摘要
- 2. 引言
- 3. 基于文本的问答
- 3.1 数据集与评价指标
- 3.1.1 数据集
- 3.1.2 评价指标
- 3.2 基于文本的问答的主要框架
- 3.4 从深度学习角度的代表工作
- 3.5 基于文本的问答小结
- 4. 基于知识库的问答
- 4.1 数据集
- 4.2 基于知识库问答的基本框架
- 4.3 基于语义解析的代表工作
- 4.4 基于信息检索的代表工作
- 4.5 基于知识库的问答小结
- 5. 总结
- 参考文献
问答系统综述报告
1. 摘要
在科技发达和信息爆炸的现代社会中,如何从大规模的信息中准确地提取信息已成为人们研究的目标,智能问答系统也成为目前自然语言处理领域的一大研究方向。在过去的30年内,机器学习方法一直都是自然语言处理和问题回答的主要解决手段。最近的科学研究中,深度学习方法逐渐成为问答领域前沿的方法,并刷新了很多科研领域的记录。目前的智能问答系统仍旧面临许多挑战,通常需要结合自然语言处理、信息检索、深度学习和语义网络等多种技术。这篇综述主要是向大家介绍基于文本的问答和基于知识库的问答两个主流问答系统。我希望这篇调研能够为智能问答领域的学者提供一篇全面的概述,对此有一个全局的认识。也希望能为人工智能的多个研究的子领域建立一座桥梁。
关键字:智能问答、神经网络、知识库问答、文本问答
2. 引言
问答(Question Answering, QA)是计算机科学中一个快速发展的研究问题,其目的是为用户寻找简短而明确的答案。QA系统主要有两种方法:基于文本的问答和基于知识库的问答。下面,我来详细叙述一下这两个概念。
基于知识库的问答主要是依托知识库,进而来找到用户问题的答案。Freebase 是其中一个受欢迎的知识库[1],在最近的许多基于知识库的问答系统中往往被作为基线来使用。知识库是一大批事实的集合,知识库中的事实往往以三元组的形式进行存储。三元组的格式是(主语、谓语、宾语),其中主语和宾语是指实体,而谓语是表示主语和宾语这两个实体之间的关系。换句话来说,知识库包括实体、关系和事实。举例来说,“姚明的生日是什么时候?”,这个问题就可以被存储在知识库的一个三元组里面,这个三元组可以表示为:(姚明,生日,1980年9月12日)。在这个基于知识库的问答任务中,往往有两种类型的问题:单跳问题和多跳问题。单跳问答指的是该问题仅对应知识库中的一条事实,主要的数据库是:SimpleQuestions 。而多跳任务相对来说比较复杂,需要对知识库中的多个事实进行融合和推理,以找到问题爹答案,代表的数据库是:WebQSP 。
在基于文本的问答中,候选答案是通过搜索大规模文档找到相关候选答案,然后在其中寻找最相似的答案文本来获得的。给定问题和答案集合 ,基于文本的系统的目标是在这些答案中找到最佳的匹配答案。此处的问题是一个自然语言描述的问题;而传统的搜索引擎能做到的只是通过查询其中的关键词向用户返回一系列相关网页,对用户真正有用的信息还需要用户自己去进一步查找。而问答系统需要做的是返回满足用户需求的答案。因而,进来的研究对于基于文本的问答中提出了不同的深度神经模型。
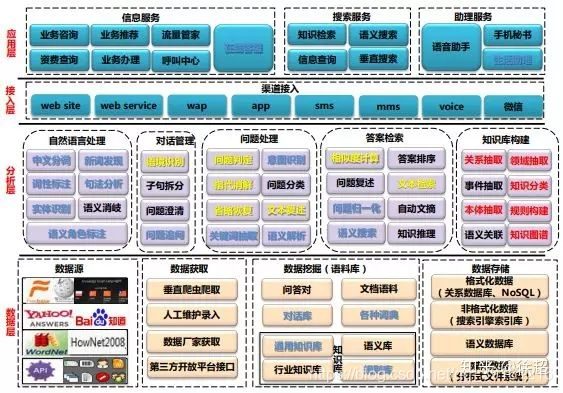
下图展示了本文中描述的QA系统的总体分类。

本文主要组织结构如下:
- 前两节分别是摘要和引言。介绍了基于文本和基于知识库问答的基本概念和详细概述。
- 第三节,详细介绍了基于文本的问答系统。首先,描述了基于文本的问答的基本框架,其次,从信息检索和深度学习的视角分别进行代表性工作介绍。最后进行小结。
- 第四节详细介绍了基于知识库的问答系统。首先,描述了基于知识库的问答的主要框架,其次,从语义解析和信息检索的方法上分别进行代表性工作介绍。最后进行小结。
- 第五节是本文的总结。
- 最后是参考文献。
3. 基于文本的问答
基于文本的问答系统比较复杂,它涉及了自然语言处理领域的很多工作,例如:信息检索、文本推理、信息抽取等等。近年来,发展很好的应用有IBM和德克萨斯大学联合研制的智能问答系统“沃森”。由于基于文本的问答是以自由文本为知识来源,没有显式的知识库,即不需要耗费大量人力物力资源构建结构化的知识库,所以我认为它将会是未来问答系统的发展趋势。
下面,我将对其进行详细的介绍。
3.1 数据集与评价指标
3.1.1 数据集
在本节中,我将描述五个被广泛用于评估QA任务的数据集。
(1)WikiQA
WikiQA 是一个开放域的QA数据集[3]。此数据集是从必应查询日志中收集的。本数据集中的数据是:选取至少5个不同用户发布并点击到维基百科页面的相似问题作为问题,并将对应维基百科页面的总结部分的句子作为相关问题的候选答案。通过众包将候选答案贴上正确或错误的标签,然后选出正确的答案。这个数据集由3047个问题和1473个答案组成,更多关于这个数据集的统计信息详见下表,其中详细列出了问题数量、正确答案、QA对以及数据集每个部分中问题和答案的平均长度。
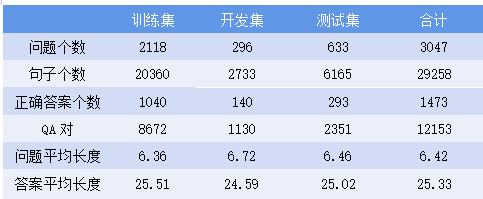
值得注意的是,WikiQA这个数据集中并不是所有问题都有正确的答案,所以这个数据集还可以用来实现判断问题是否有答案这一功能。
(2)TREC-QA
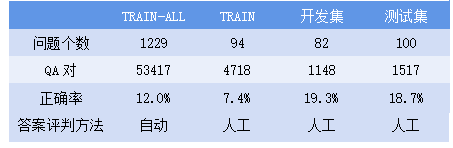
这个数据集是来自于文本检索会议(Text REtrieval Conference,TREC)的一个问答数据集[4]。采用TREC 8-12中的问题作为训练数据集,TREC 13中的问题作为开发和测试数据集。TREC-QA 数据集的统计情况见下表。TREC-QA 包含两个训练数据集:TRAIN和TRAIN- ALL。TRAIN 数据集包含TREC 8-12的前94个问题,候选答案是人工评判的,而TRAIN-ALL 数据集通过模式匹配来识别的正确答案。
(3)Movie-QA
这个数据集比较独特,因为数据是来自于不同的数据源[5]。它包含14944个问题,每个问题与五个答案相关,包括一个正确答案和错误答案。该数据集的统计数据见下表。
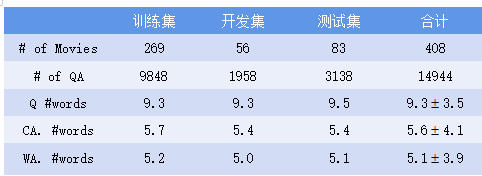
其中,# of Movies表示电影的个数,# of QA是QA对个数,Q #words代表问题中的词语平均个数,CA. #words是正确答案词语平均个数,WA. #words表示错误答案包含的词语的平均个数。
(4)InsuranceQA
这个数据集适用于保险领域的一个特定领域数据集[6]。此数据集的问题/答案对是从互联网上收集的。这个数据集包括训练集,开发集,测试集1.测试集2。关于 InsuranceQA 的更详细的统计信息见下表。
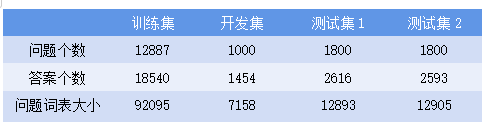
该语料库的内容由现实世界的用户提出,高质量的答案由具有深度领域知识的专业人士提供。在论文中,语料库用于答案选择任务。 另一方面,这种语料库的其他用法也是可能的。 例如,通过阅读理解答案,观察学习等自主学习,使系统能够最终拿出自己的看不见的问题的答案。
(5)Yahoo! Dataset
雅虎问答数据集包括142,627个问题/答案对。
3.1.2 评价指标
对于问答系统来说,其性能的评估方法也是一项重要的研究工作。目前,在论文中看到的评测指标主要是有以下几个:
(1)平均倒数排序(Mean Reciprocal Rank, MRR),公式如下:
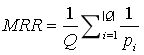
其中,是问题的个数;为第个问题中的第一个正确答案的排名位置。即把第一个正确答案在排序给出结果中的位置取倒数作为它的准确度,再对所有的问题取平均,这个评价指标只关心第一个正确答案。举个例子,用户输入三个问题,问答系统对第一个问题返回的候选答案排序中,第一个正确答案排名为2,对第二个问题是4,对第三个问题是6,那么该问答系统的MRR 为:(1/2+1/4+1/6)/3=11/36。
(2)平均精度均值(Mean Average Precision, MAP),公式如下:
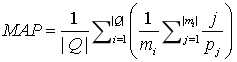
其中 是第个问题的正确答案的数量。为第个问题第个正确答案的排名位置。MAP关注所有的正确答案。举个例子,假设有两个问题,问题1有4个相关答案,问题2有5个相关答案。有一个问答系统对于问题1检索出的4个相关答案,其排名分别为1, 2, 4, 7;对于问题2检索出3个相关答案,其排名分别为1,3,5。那么对于问题题1,平均准确率为 (1/1+2/2+3/4+4/7)/4=0.83 。对于问题题2,平均准确率为 (1/1+2/3+3/5+0+0)/5=0.45。则 MAP = (0.83+0.45)/2=0.64。
(3)查准率(Precision, P),又称为精度,公式如下:
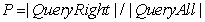
其中, Q u e r y R i g h t QueryRight QueryRight 是查询出的正确答案个数, Q u e r y A l l QueryAll QueryAll 是查询出的所有答案的个数。
(4)查全率(Recall, R),又称为召回,公式如下:
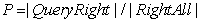
其中, Q u e r y R i g h t QueryRight QueryRight 是查询出的正确答案个数, R i g h t A l l RightAll RightAll 是问题的所有正确答案的个数。举个例子,比如问题“三原色是哪三种?”,正确答案是红色、蓝色、绿色。如果问答系统给出的答案是红色、蓝色,那么查准率就是1;查全率就是2/3(因为缺失了绿色)。
另外,问答系统的精度和召回又可以分为宏观和微观的。系统的微观精度和召回率是通过对所有已回答问题的精度和召回率取平均值来计算的,即不考虑未回答的问题。系统的宏观精度和召回率是通过对所有问题的精度和召回率取平均值来计算的。
(5)F-measure 是精度与召回率之间的加权平均,其计算方法如下:
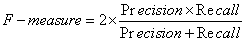
注意,如果精度或召回率都接近于0,则F-measure接近于0;只有当精度和召回率都为1时,F-measure才等于1。
(6)准确率
准确率是一种简单有效的评测方法,算法是:答对的问题数除以问题总数。
(7)运行时间(Runtime)
这通常表示为问答系统回答问题所花费的平均时间。
3.2 基于文本的问答的主要框架
基于文本的问答的主要框架包括三个主要阶段:问题处理模块、文本检索模块以及答案抽取模块。这三个阶段均在文献[2]中有详细描述,如下图所示,是文献中基于文本的问答的流程图。
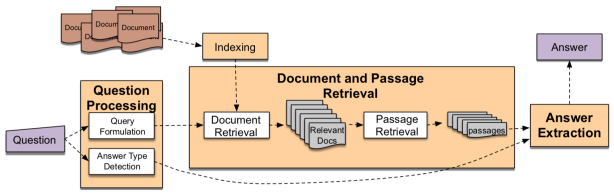
1.问题处理模块:这个模块需要做的就是将用户输入的自然语言问题进行预处理,这个处理包括一系列的文本操作,例如:句子分词、命名实体识别、词性标注、问题分割、消除歧义、依存分析等等。经过预处理之后会输出诸如问句类型、关键词、答案类型等的有关于问题的语义标签。那么这个阶段包括两个主要步骤,即查询公式化和答案类型检测。在查询公式化步骤中,使用信息检索(Information Retrieval, IR)技术生成的查询用来检索相关文档。在答案类型检测步骤中,使用分类器根据期望答案的类型对问题进行分类。在这一步中可以使用不同的基于神经网络或基于特征的分类器。这个模块输出的信息可以为之后的文本分析检索以及答案选择提供坚实的基础。
2.文本检索模块:本模块的主要任务就是从海量的文本段中检索出最符合用户需求的一些文档作为候选答案集合。那么上述步骤中的查询公式化中生成的查询,送入信息检索的引擎,并返回前个检索到的最相关的文档。这是问答的核心部分,可以找到与输入问题最为相似的段落。
3.答案抽取模块:这是问答系统的最后阶段,从给定的候选答案集合中抽取最相关的答案。在这一步中,我需要度量输入问题和提取答案的相似性。这里的答案,既可以是一个合适的句子,也可以是一个短语。那么根据答案的不同,也可以将其分为答案句子选择和机器阅读理解。显而易见,前者属于句子粒度的答案;后者是根据推理理解抽取出短语作为答案。
如前所述,答案抽取模块中的问题和答案句的相似度度量是基于文本的问答系统的重要组成部分。在这里,问题和答案句子的相似度可以通过信息检索或深度学习方法来衡量。在第3.3节和第3.4节中,我分别从信息检索的角度和深度学习的方法来回顾相关工作。
3.3从信息检索角度的代表工作
尽管基于词汇的信息检索模型在即席检索中得到了广泛的应用,但在问答任务中应用较少。注意,即席检索指的是:类似于图书馆里的书籍检索,即书籍库(数据库)相对稳定不变,不同用户的查询要求是千变万化的。它推动了在问答领域使用先进的信息检索的方法的研究。本节将介绍几个信息检索的方法。
(1)单词计数模型 Word Cnt[3]
通过计算在问题和回答句子中出现的非停用词的个数,重点在于Q和A中相同词的个数,主要重点在于文本结构的相似。
(2)加权单词计数模型 Wgt Word Cnt[3]
不同于上面这种方法,加权单词计数模型为每个词语分配一个权重,这种做法可以使得问题和答案句子的重点有所突出。这两种模型均为信息检索模型的baseline,效果均不是很好。
(3)词汇语义模型[7]
这个模型是为了解决答案选择中的语义匹配问题,其中背后的思想是:采用概率分类器并且使用问题和答案的语义模型来预测它们之间是否相关。他们利用问答句中每对词的同义词/反义词、上位词/下位词和语义词相似性来创建语义模型。他们采用学习受限潜在表示(LCLR)对问题和答案进行分类。分类器的细节如下所示:
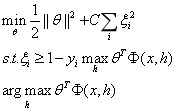
以上就是LCLR的目标函数的定义,注意,对齐是潜在的,所以LCLR使用训练数据中的二值标签作为反馈,为每个例子查找到对齐。另外,LCLR的思想是使用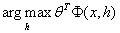 来替代标准线性模型
来替代标准线性模型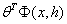 。
。
(4)Sanity check模型[8]
该模型分三个步骤计算每个问题-答案对的匹配分数。
第一步,每个单词的IDF权重计算公式如下:
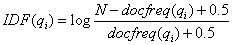
其中是问题的个数, d o c f r e q ( q i ) docfreq(q_i) docfreq(qi) 是包含单词 q i q_i qi 的问题的个数。
在第二步中,在问题和答案中的词语之间执行一对多的对齐。计算每个问题词 q i q_i qi 和每个回答词 a i a_i ai 的相似度,这里指的是 Glove 词向量[9]之间的余弦相似度。然后可以得到前 K + K^+ K+ 个最相似的单词 { a q i , 1 + , a q i , 2 + , a q i , 3 + , . . . , a q i , K + + } \{ a_{{q_i},1}^ + ,a_{{q_i},2}^ + ,a_{{q_i},3}^ + ,...,a_{{q_i},{K^ + }}^ + \} {aqi,1+,aqi,2+,aqi,3+,...,aqi,K++} 和后 K − K^- K− 个最不相似的单词 { a q i , 1 − , a q i , 2 − , a q i , 3 − , . . . , a q i , K + − } \{ a_{{q_i},1}^ - ,a_{{q_i},2}^ - ,a_{{q_i},3}^ - ,...,a_{{q_i},{K^ + }}^ - \} {aqi,1−,aqi,2−,aqi,3−,...,aqi,K+−}。
最后,在第三步中,通过以下公式计算每个问答句之间的相似度评分 S ( Q , A ) S(Q,A) S(Q,A):
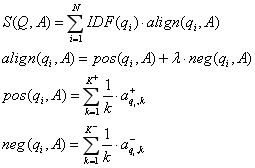
其中, a l i g n ( q i , A ) align({q_i},A) align(qi,A)是问题词 q i q_i qi 与答案 A A A 的对齐分数。 λ \lambda λ 是负面信息的权重。 p o s ( q i , A ) pos({q_i},A) pos(qi,A) 和 n e g ( q i , A ) neg({q_i},A) neg(qi,A) 分别代表 K + K^+ K+ 个最相似的单词和后 K − K^- K− 个最不相似的单词的一对多对齐得分。他们还提出了另外两个基线,单对齐(一对一)和一对所有。在一对一方法中,只使用最相似的单词 K + = 1 K^+=1 K+=1 这个单一对齐得分。在一对多的方法中,在计算 a l i g n ( q i , A ) align({q_i},A) align(qi,A) 的时候,以相同的权重考虑问题词与所有答案词的相似性,使得 a l i g n ( q i , A ) align({q_i},A) align(qi,A) 变为:
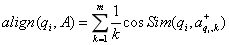
这样的文本匹配算法还有很多,在此就不一一列举了。下面,我重点从深度学习的视角来看看基于文本的问答系统是如何工作的。
3.4 从深度学习角度的代表工作
深度学习模型可以分为三类:基于表示、基于交互和混合模型。
基于表示的模型分别构造问题和候选答案的固定维向量表示,然后在潜在空间内进行文本匹配。
基于交互的模型计算问题和候选答案句子的每个词语之间的交互,其中交互可以是句法/语义相似。
混合模型结合了交互模型和表示模型。它们由一个表示模块(将一系列单词组合成固定 d d d 维的表示)和一个交互模块组成。这些组件可以并行或串行出现。
下面,我来挑几个深度学习的代表模型进行描述。
(1)基于生成神经网络的问题/答案对相似度匹配[10]
这是一种二分类模型,基于生成神经网络旨在判断问题/答案对是否相关。该模型捕捉了问题和答案句的语义特征。每个样本都用一个三元组 ( q i , a i j , y i j ) ({q_i},{a_{ij}},{y_{ij}}) (qi,aij,yij) 表示,其中 q i ∈ Q {q_i} \in Q qi∈Q 是一个问题, a i j a_{ij} aij 是的 q i q_i qi 一个候选答案,标签 y i j y_{ij} yij 表示 q i q_i qi 是否为的正确答案。对每个答案,生成一个相关的问题,然后使用点积来获取所生成问题与给定问题的语义相似性。这种相似性用于预测候选答案是否为给定问题的答案。答案正确的概率可以表述为:
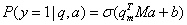
其中, q ′ = M a q' = Ma q′=Ma 是生成的问题。
每个句子都是由词袋和Bi-gram建模的。在词袋模型中,一个句子是通过平均所有单词(停用词除外)的嵌入来表示的。Bi-gram模型能够独立于bi-grams在句子中的位置来捕捉它们的特征。在Bi-gram模型中使用了一个卷积层和一个池化层对句子进行建模。每个 bi-gram 被映射到一个特征值 c i c_i ci,计算如下:
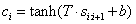
其中,s是句子的向量表示。在平均池化层中组合所有 Bi-gram 特征,最终得到与初始词嵌入具有相同维数的全句表示,计算如下:
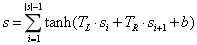
论文中描述的模型架构如下所示:

(2)CNN-based 答案选择框架[11]
本论文提出了一个选择答案的框架。和一般形式的文本处理方式一样,并没有特别大的差异,文章的重点在于提出了一个相似度矩阵。
将任务分为两个主要子任务:a. 将单词的原始空间映射到特征空间编码,b学习对象对之间的相似性函数。
query和document首先通过word embedding处理后获得对应的表示矩阵;然后利用CNN网络进行处理获得各自的feature map,接着pooling后获得query对应的向量表示 x q x_q xq 和document的向量 x d x_d xd,不同于传统的语义网络在这一步利用欧式距离或余弦距离直接对 x q x_q xq 和 x d x_d xd 进行相似性计算后预测结果,网络采用一个相似矩阵来计算和的相似度,然后将 x q x_q xq 和 x d x_d xd 和 s i m ( x q , x d ) sim({x_q},{x_d}) sim(xq,xd) 进行拼接,并添加了word overlap和IDF word overlap的特征后作为特征向量输入一个神经网络层,神经网络层的输出经过一个全连接层,利用softmax函数得出预测结果。(以上解释来源于网络,我表示很认同)
他们使用卷积神经网络(CNN)架构来学习将输入文本(查询或文档)映射到向量空间模型。在第二部分中,他们使用了噪声信道方法来寻找一个文档的转换,使其尽可能接近查询: S i m ( x q , x d ) = x q T M x d Sim({x_q},{x_d}) = x_q^TM{x_d} Sim(xq,xd)=xqTMxd。为此,他们使用神经网络架构来训练相似度矩阵M。根据下图的框架,来自第一个CNN模型的查询和文档的向量表示拼接后送入第二个CNN,训练并构建相似度矩阵。

(3)Holographic-dual LSTM (HD-LSTM)[12]
本文一共提出了四种基于LSTM的模型,首先是基于LSTM的最基本的答案选择框架,称为QA-LSTM,然后是两种结合CNN和LSTM的混合模型,最后是带attention的LSTM模型。
基本的QA-LSTM框架如下图所示:

给定一个(q,a)对,q是问题,a是一个候选答案,首先得到问题和答案的词向量,然后将两个词向量序列分别输入到biLSTM中,最后得到一个固定长度的分布式向量表示,有以下三种方法去得到这个固定长度的向量:(1)将双向LSTM的两个方向的最后一个输出向量进行拼接;(2)对双向LSTM的所有输出向量做average pooling;(3)对所有输出向量做max pooling,然后用余弦相似度去计算问题和答案的向量相似度。
模型训练用合页损失函数作为目标函数,如下所示:
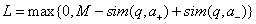
这里 a + {a_ + } a+ 是正确答案, a − {a_ - } a− 是随机选出的一个错误答案,如果一个问题有多个正确答案,那么就将其看作多个训练样本,对于错误答案,则随机选择K个错误答案,计算它们的L值,只用L值最大的那个错误答案去更新模型。
LSTM在捕获长期依赖关系方面是一个强大的架构,但它的缺点是没有注意到局部 n-gram,然而卷积结构与之相反;因此,每个CNN和RNN块都有各自的优缺点。所以以下是几个改进模型。
首先是Convolutional pooling LSTM。这是一个混合模型。这个模型用一个卷积层代替了上一个模型中简单的池化操作,在LSTM的输出序列上加入这个卷积层使得模型能够获取更丰富的局部信息,并在该层之上放置输出层,用于生成输入句子的表示。如下图所示:

具体模型说明如下:
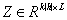
Z是一个矩阵,矩阵的第m列表示的是以biLSTM输入序列的第m个词为中心得到的k个隐层输出向量的拼接,L是卷积结果的序列长度。
接下来也是一个混合模型,基于卷积的模型。上一个混合模型可以称为convolutional-pooling,即用一个卷积层去做池化,而这个混合模型则是在整个网络更低层的地方去获取局部n-gram间的相互关系,在这个卷积层之上再加一个双向LSTM。带有c个滤波器的卷积层输出如下所示:
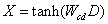
矩阵 D ∈ R k E × L D \in {R^{kE \times L}} D∈RkE×L 的第 l l l 列是由以输入序列中的第 l l l 个词为中心的 k k k 个词的词向量拼接而成, E E E 是词向量的维数。将矩阵 X ∈ R c × L X \in {R^{c \times L}} X∈Rc×L 作为双向LSTM的输入,对双向LSTM的输出向量做最大池化,从而得到问题和答案的最终向量表示。框架图如下所示:

最后一个便是带有注意力的LSTM。由于答案中可能包含许多无用的信息,所以利用attention model去学习答案向量,使得这个向量包含更多与问题相关的信息量。

(4)aNMM 神经匹配模型[13]
首先,先来介绍一下ANMM-1的主要工作步骤如下:
a. 构建QA匹配矩阵:矩阵中的每个单元格表示对应的问答词的相似度。相似度是通过对单词嵌入的点积进行标准化来计算的。
b. 学习语义匹配:不同的答案句子长度导致了QA矩阵的大小的变化。为了解决这个问题,使用权值共享方法。这个方法中,每个节点的权重都是基于其自身的值,其中一个节点的值表示两个单词之间的相似性。
c. 问题注意力网络:在隐状态中应用带有问题词嵌入权值的注意层。最后,计算匹配分数。
在aNNM-2中,每个问题答案匹配向量使用多个共享权值,那么在第一隐层中存在多个中间节点。 aNMM-2 的架构如下图所示:

(5)BERT 模型[14]
谷歌团队在2019年提出了 Bidirectional Encoder Representations from Transformers (BERT) 模型,是一个语言模型神经网络。
下图是BERT的预训练和微调的架构图:

下图是BERT的输入表示构建过程:
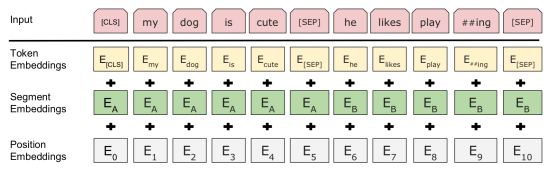
BERT采用多层双向架构,每一层是一个Transformer[15]编码器。BERT采用了与Transformer模型相同的解码段。BERT广泛应用于各种NLP下游任务,包括QA、自然语言推理和文本分类,其用于捕获给定序列之间的文本依赖关系。BERT在大型语料库上通过masked语言模型和下一句预测两种不同的方法进行预训练,然后根据应用对每个具体的下游任务进行微调。BERT的架构包括预处理和微调步骤,如上图。BERT的输入是单词的输入表示序列。将单词嵌入、分段嵌入和位置嵌入相加,构建每个单词的输入表示,如上图。在QA领域中,在序列的第一个位置使用一个 (CLS),然后将问题和候选答案分别跟一个(SEP)放在序列中。BERT的输出是每个token的编码表示。BERT也被用于问答任务中,由于BERT在问答句子中使用了交叉匹配的注意力,因此它被认为是一种基于交互的模型。
(6)TANDA模型[16]
它利用BERT和RoBERTa预训练的语言模型来建模两个句子序列之间的依赖关系,用于答案句子选择(AS2)。对BERT进行微调的数据量太小,可能会导致模型不稳定、有噪声。为了缓解这个问题,他们为AS2使用了两个不同的微调步骤。在为AS2任务在大型语料库上执行的第一个微调步骤中,BERT被转换成AS2模型 ,而不仅仅是语言模型。然后通过对目标数据集上的模型进行微调,使模型适用于特定的问题类型领域。TANDA模型的架构如下图所示。
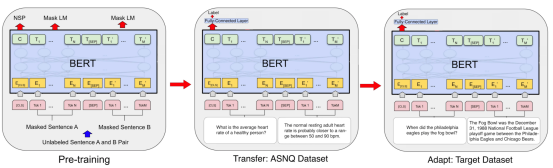
问题和答案对附加一个 [SEP] 并传递给BERT模型。token [CLS]的编码表示被传到一个全连接层,然后是一个sigmoid函数,用于预测给定问题和答案对的匹配分数。
(7)成对词交互模型[17]
这个QA任务模型,该模型由四个主要部分组成。
上下文建模:这是第一个组件,它使用一个BiLSTM来建模每个单词的上下文。
成对词交互建模:这个组件比较了 BiLSTM 的两个隐藏状态与余弦,L2欧几里得,和点积距离度量。公式表示如下:
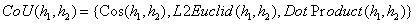
相似度聚焦:在这一层中,单词交互通过最大化重要单词交互的权重来分配权重。该组件的输出是一个名为 FocusCube 的三维组,被识别为重要的单词在该三维空间中有更大的权重。
相似性分类:在这一层中,CNN用于寻找强成对词交互的模式。FocusCube中的问答语句被输入到这一层,并计算相似度评分。
模型的架构图如下:

(8)内注意力RNN模型[18]
这篇文章提出了四种基于内注意力的RNN模型。这些模型试图缓解传统的基于注意的RNN模型存在的注意力偏差问题。首先介绍了传统的基于注意力的神经网络模型,然后介绍了四种基于内注意力 (IARNN) 的神经网络模型。
首先是传统的基于注意力的RNN模型(OARNN),该算法首先利用RNN块对句子进行编码,然后利用问题嵌入的注意力权值生成答案句子的表示。这种注意力机制是在学习了嵌入、后面的隐藏状态的偏差后进行的 ,因为它们包含的信息比邻近的句子更多。OARNN 的架构如下图所示。该模型在RNN块之后加入了注意层,因此被命名为OARNN(即outer attention-based RNN)。最后一个隐含层或所有隐含状态的平均值作为问题句子的表示,其中答案的表示是利用问题表示中的注意权值得到的。
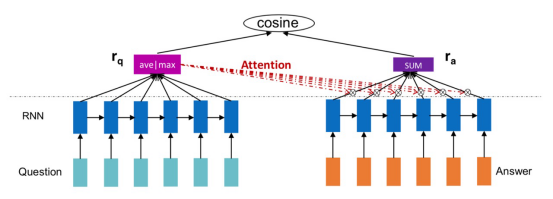
接下来,介绍四种Inner attention-based RNNs (IARNN)。IARNN模型的提出,为了缓解 OARNN 在生成答案语句表示时存在的偏差问题。在这些模型中,在RNN块生成隐藏层之前添加注意力权重;下面介绍四种不同IARNN模型的体系结构。
a. IARNN-WORD:利用问题注意力权重生成每个词的表示,然后利用RNN模型得到整个句子的表示。GRU参数较少,训练速度快,因此在RNN块中选择GRU。句子的表示是由隐含状态 ht的加权平均值生成的。以下是提出的IARNN-word 模型架构:

b.IARNN-Context:由于IARNN-WORD模型无法捕捉多个相关词,在IARNN-Context中,答案句的上下文信息被输入注意力权重。该模型的架构如下图所示:

c. IABRNN-GATE:由于GRU门在隐藏阶段控制信息流,因此注意力信息将馈送到这些门。 该模型的架构如图所示:

d. IARNN-OCCAM:这个模型是以奥卡姆剃刀的名字命名的,该意思是:“ 在整个单词集合之间,必须选择能代表句子的最少的单词。”根据问题的类型,回答问题需要不同数量的相关单词。例如,在答案句子中,“what” 和 “where” 的问题比 “why” 和 “how” 的问题需要更少的相关词。这个问题在 IARNN-OCCAM 中通过使用一个调节值来处理。因此,“what” 和 “where” 问题的注意力总和应该更加稀疏, “why” 和 “how” 问题应该分配较小的调节值。该调控模型可用于IARNN-context 和 IARNN-word 模型。
3.5 基于文本的问答小结
这个章节首先概述了基于文本的QA的发展趋势以及挑战。然后介绍了其数据集以及评价指标。最后分别从两个大的视角介绍了基于文本的问答系统。基于信息检索的QA性能不够优异,基于深度学习的QA缺乏一定的可解释性。其中,基于深度学习的模型又可以分为表示模型、交互模型和混合模型。基于表示的模型在不同的组件上分别为每个句子构建嵌入。尽管它们很简单,并且通常在两个独立组件之间使用共享参数,但它们无法从问答句中捕获每对 token 之间的匹配。基于交互的模型通过在给定句子的每个词之间直接交互来解决这个问题。混合模型结合了交互模型和表示模型。它们由一个表示组件和一个交互组件组成。该表示组件将一个单词序列组合成一个固定的 d 维表示。在大多数混合模型中,注意力机制用于通过关注其他句子来生成更丰富的答案或者问题句子的表征。
整体上说,基于文本的QA不需要耗费人力物力资源去构建结构化的知识库,应该是未来智能问答系统发展的趋势所在。
4. 基于知识库的问答
随着信息技术的快速发展,一大批结构化的知识库如Freebase、Dbpedia、Probase等等如雨后春笋似的涌现出来。
相比于上述的基于文本的问答系统,利用知识库进行自然语言的问题回答可以为用户提供更为准确、更为具体的答案。所以,基于知识库的问答系统(Question Answering over Knowledge Base, KBQA)越来越受到国内外广大学者的密切关注和深入研究。
目前基于知识库的问答技术大致可以分为两大类,第一类是基于语义解析的方法,第二类是基于信息检索的方法。
4.1 数据集
基于知识库的问答领域的研究已经从基于手工的特征工程的转向以神经网络为基础,数据驱动的方法。这些数据驱动方法的关键需求之一是大数据集的可用性。下表总结了最流行的KGQA数据集的属性[19]。

(1)Free917
这是首个构建大规模KBQA的数据集,包含了917条问句-规范查询对,覆盖了600种Freebase关系。DBpedia和Freebase之间的主要区别在于信息的结构。Freebase既包含二元关系,也包含非二元关系。非二元关系是使用中介节点的具体化来存储的。在DBpedia中则不是这样,其中只存储二元关系。
(2)WebQuestions
这个规模会前面大了不少。但是有两个缺点:一是只提供了答案而没有对应的查询,不利于基于逻辑表达式模型的训练;二是简单问句多而复杂问句少。
(3)WebQuestionsSP
针对WebQuestions的问题,提出了WebQuestionsSP,是WebQuestions的子集,补全了对应的查询句。
(4)ComplexQuestions
为了增强问句的结构、表达多样性,分别提出了ComplexQuestions和 GraphQuestions,进一步增强了WebQuestionsSP,包括类型约束,显\隐式的时间约束,聚合操作。
(5)GraphQuestions
为了增强问句的结构、表达多样性,分别提出了ComplexQuestions和 GraphQuestions,进一步增强了WebQuestionsSP,包括类型约束,显\隐式的时间约束,聚合操作。
(6)SimpleQuestions
上述的数据集规模相对较小,并不能完整的覆盖知识图谱中的实体和关系。构建了SimpleQuestions,共100k例,一定程度上弥补这个问题。这个数据集中的问题可以用一个三元组进行回答。数据集含查询句。
(7)30M-Factoid-Questions
将SimpleQuestion扩展为含30M句的FACTOID QUESTIONS,只包含答案不含问句。
(8)QALD
虽然规模规模小,不利于监督学习,但是表达更加复杂、口语化。QALD的问题每年都由挑战赛的组织者准备。通常最多可以使用三个二元关系来回答这些问题,并且通常需要像 ORDER BY 和 COUNT 这样的修饰符。SimpleQuestion 和 QALD 数据集使用SPARQL查询进行标注。
(9)LC-QuAD
2017年发布。LC-QuAD是一个包含5000对问题及其相应的SPARQL查询的问答数据集。
(10)LC-QuAD 2.0
2019年发布。类似于LC-QuAD,但是数据量更大。
4.2 基于知识库问答的基本框架
下图是KBQA的基本框架:

首先将自然语言问题解析为某种语义表示,然后通过语义匹配、推理和查询在知识库中找到相应的答案并返回。
KBQA系统的传统框架大致可以分为四个模块:问题分析、短语映射、消歧和查询构造。
目前解决知识库问答的方法主要有两种:语义解析和信息检索。实际上,这两种方法并没有严格的区分,甚至可以一起使用。在接下来的小节中,将重点介绍这两种方法来分析近年来的相关研究和成果。
4.3 基于语义解析的代表工作
语义解析是一种比语法分析更高层次的分析。其主要思想是将非结构化的自然语言问题转化为用来描述语义的形式化语言,如逻辑表达式等。通过对逻辑形式的自底向上分析,再查询知识库得到能够表达语义的逻辑形式,即无二义性的表达式。还有一个问题就就是,构建这样的知识库需要一大批标注数据,即自然语言问题以及其对应的语义描述形式,然而事实上高质量的训练语料是很难获取的;另外就是,句子的语义描述形式与知识库结构的不匹配问题也是一个普遍存在的严重问题。
(1)传统方法
传统语义解析风格的KBQA方法主要依靠 人工构造规则、监督学习、基于经典组合类别语法(CCG) ]、词汇树伴随语法(LTAG) 等方法,将自然语言问题转化为逻辑表达式和知识库查询语言。例如,逻辑语言lambda演算[20]将 “number of dramas starring Tom Cruise ”转换为:
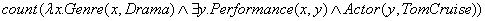
这些传统方法不可扩展,需要手工标注。
(2)基于监督学习的语义解析器[21]
作者提出训练一个语义解析器,基于该语义解析器进行KBQA,具体步骤是语义解析器把输入问题解析为逻辑形式,再基于这种结构化的表达从知识库中寻找答案。
描述一下任务就是:在给定的知识库 K K K 和训练集问答对 { ( x i , y i ) i = 1 n } \{ ({x_i},{y_i})_{i = 1}^n\} {(xi,yi)i=1n} 下,训练出一个语义解析器,然后对新问题x进行解析得到逻辑形式,在通过查询知识库得到答案 y y y 。
(3)模板方法[22]
使用模板来表示自然语言问题并解决BFQ ( binary factoid questions )问题,它从QA语料库中学习自动学习模板,而不是手动对模板进行标注。基于这些模板,他们的QA系统KBQA 有效地支持 binary factoid questions 以及由一系列 binary factoid questions 组成的复杂问题。
这样的方法还有很多代表的工作,在此就不一一列举了。其主要思想是将非结构化的自然语言问题转化为用来描述语义的形式化语言,再结合知识库进行查询。
4.4 基于信息检索的代表工作
基于信息检索的技术不同于语义解析,不会将自然问题完全转化为形式化的逻辑描述。相反,它们会使用实体链接技术,利用知识库来收集候选答案的集合。其思想是从问题中提取信息,利用知识库获取候选答案,然后对候选答案进行排序,得到最终答案。与语义解析相比,它的性能不是很好,但构造训练数据的过程相对简单,只需收集问题答案对即可,可以应用在很多领域。他的缺点显而易见,只能处理语义简单的问题,对于那些包含多种实体以及关系的复杂的需要推理的问题则性能较差。
(1)Seq2Seq with CNN[23]
作者提出了一种基于Freebase的自动问答模型,利用多列卷积神经网络(MCCNNs)在不使用任何人工特征和词汇的情况下进行特征提取和分类。该模型从不同方面考虑了问题与答案的匹配程度:一个是答案的类型,一个是答案的上下文,另一个是答案与主体之间的路径。
在问题的表达中,分别使用三个卷积神经网络学习问题的语义表示。同时,将候选答案的答案类型、答案上下文和答案路径信息分别在知识库中呈现,并学习它们的分布式表示。计算了这三种CNN 与问题向量表示的相似性,并给出了得分。对模型进行了误差分析,误差主要由候选生成问题、时间感知问题和二义性问题引起。该模型充分考虑了候选答案的各种信息,并基于深度学习取得了良好的效果。在误差分析方面,可以为作者以后的工作带来一些突破。
以下是模型的概述:

上图描述了问答对(when did Avatar release in UK, 2009-12-17)的概述,左边是问题理解的网络结构,右边是嵌入候选答案的过程。
(2)Seq2Seq with Attention
注意力机制的使用已成为解决KBQA问题的有效方法。 [24]不仅引入了注意力机制,而且从字符级解决了KBQA问题。不同于以前的方法,它不再使用词级别的编码器和解码器,而是提出了一种字符级encoder-decoder 框架,并介绍了注意力机制来有效改善QA系统中的OOV 问题。

如上图所示,整个框架分为三个部分:问题编码器、实体和谓词编码器和KB查询解码器。信息检索风格方法的核心在于学习问题和候选答案的分布式表达。
首先,使用one-hot对问题中每一个字符编码,包括空格、标点符号;使用两层门控LSTM从左到右编码。然后对实体和谓词进行编码,使用两个不同的CNN编码器。最后,进行知识库查询解码,使用基于注意力机制的LSTM,最然后语义相似度评分。
4.5 基于知识库的问答小结
这个小节综述了基于知识库的问题回答,介绍了语义解析和信息检索的方法。虽然现有的知识库回答问题在处理复杂问题方面还比较薄弱,并且存在句子与知识库内容不匹配等问题,但是随着科技的发展和科研人员的不懈研究,解决知识库问题的解答充满了希望。
5. 总结
在本文中,我对基于文本的QA系统和基于知识库的QA系统进行了概述与总结。在每个章节里,首先介绍了QA系统的架构;其次介绍了一些代表性的数据集以及一些性能评估的指标;然后提出了该领域现有的发表的一些代表性工作。基于文本的QA,被分为两类:基于信息检索的技术和基于深度学习的技术。先回顾了前一个类别的一些方法,然后依据神经文本匹配的分类法,即基于表示、基于交互和混合模型,更详细地强调了基于深度学习的方法。基于知识库的QA,被分为两类,基于语义解析和信息检索的技术,我分别对这两个类别的代表性工作进行了简要的叙述,虽然现有的知识库回答问题在处理复杂问题方面还比较薄弱,并且存在句子与知识库内容不匹配等问题,但是随着科技的发展和科研人员的不懈研究,解决知识库问题的解答充满了希望。最后进行了总结。
参考文献
[1].Bollacker K D , Evans C , Paritosh P , et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]// Sigmod Conference. ACM, 2008.
[2].Jurafsky, D. and Martin, J. H. (2009) Speech and Language Processing (2Nd Edition). Upper Saddle River, NJ, USA: Prentice-Hall, Inc.
[3].Yang Y, Yih W, Meek C. Wikiqa: A challenge dataset for open-domain question answering[C]//Proceedings of the 2015 conference on empirical methods in natural language processing. 2015: 2013-2018.
[4].Wang M, Smith N A, Mitamura T. What is the Jeopardy model? A quasi-synchronous grammar for QA[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL). 2007: 22-32.
[5].Tapaswi M, Zhu Y, Stiefelhagen R, et al. Movieqa: Understanding stories in movies through question-answering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4631-4640.
[6].Feng M, Xiang B, Glass M R, et al. Applying deep learning to answer selection: A study and an open task[C]//2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015: 813-820.
[7].Yih W T , Chang M W , Meek C , et al. Question Answering Using Enhanced Lexical Semantic Models[C]// Meeting of the Association for Computational Linguistics. 2013.
[8].Yadav V , Sharp R , Surdeanu M . Sanity Check: A Strong Alignment and Information Retrieval Baseline for Question Answering[J]. 2018.
[9].Pennington J , Socher R , Manning C . Glove: Global Vectors for Word Representation[C]// Conference on Empirical Methods in Natural Language Processing. 2014.
[10].Yu L, Hermann K M, Blunsom P, et al. Deep learning for answer sentence selection[J]. arXiv preprint arXiv:1412.1632, 2014.
[11].Severyn A , Moschitti A . Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks[C]// the 38th International ACM SIGIR Conference. ACM, 2015.
[12].Tan M , Santos C D , Xiang B , et al. Improved Representation Learning for Question Answer Matching[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016.
[13].Yang L , Ai Q , Guo J , et al. aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model[C]// the 25th ACM International. ACM, 2016.
[14].Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[15].Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[16].Garg S, Vu T, Moschitti A. Tanda: Transfer and adapt pre-trained transformer models for answer sentence selection[J]. arXiv preprint arXiv:1911.04118, 2019.
[17].He H, Lin J. Pairwise word interaction modeling with deep neural networks for semantic similarity measurement[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 937-948.
[18].Wang B, Liu K, Zhao J. Inner attention based recurrent neural networks for answer selection[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016: 1288-1297.
[19].Chakraborty N, Lukovnikov D, Maheshwari G, et al. Introduction to neural network based approaches for question answering over knowledge graphs[J]. arXiv preprint arXiv:1907.09361, 2019.
[20].Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013: 1533-1544.
[21].Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013: 1533-1544.
[22].Cui W, Xiao Y, Wang H, et al. KBQA: learning question answering over QA corpora and knowledge bases[J]. arXiv preprint arXiv:1903.02419, 2019.
[23].Dong L, Wei F, Zhou M, et al. Question answering over freebase with multi-column convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015: 260-269.
[24].Golub D , He X . Character-Level Question Answering with Attention[J]. 2016.
[25].Zhang Y , Liu K , He S , et al. Question Answering over Knowledge Base with Neural Attention Combining Global Knowledge Information[J]. 2016.