数据和模型版本控制是 DVC 的基础层用于管理大型文件、数据集和机器学习模型。使用常规的 Git 工作流程,但不要在 Git 库中存储大文件。 大数据文件单独存储,来实现高效共享。想象一下,让 Git 以与处理小代码文件相同的性能来处理任意大的文件和目录,该有多酷?例如,使用git clone并在工作区查看数据文件和机器学习模型。或者使用 git checkout 在不到一秒的时间内切换到 100Gb 文件的不同版本。
DVC 的基础由一些命令组成,通过与 Git 一起运行以跟踪大文件、目录或 ML 模型文件。 简而言之,DVC 就是“用于管理数据的Git”。
在我的上一篇文章快速入门DVC(二):安装及初始化中创建了一个Git项目,并进行了初始化。现在,我们使用dvc add来跟踪文件或目录。
下载文件(dvc get)
跟踪文件之前,我们使用dvc get预先下载数据文件。
# 进入到之前初始化好的项目目录下
$ cd example-get-started$ dvc get https://github.com/iterative/dataset-registry \get-started/data.xml -o data/data.xml跟踪文件(dvc add)
接下来,跟踪文件。
dvc add data/data.xml
通过以上命令,DVC 将关于添加的文件(或目录)的信息存储在名为 data/data.xml.dvc 的特殊 .dvc 文件中(这是一个人类可读格式的小文本文件)。这个元数据文件是原始数据文件的占位符,这样就可以像使用 Git 的源代码一样轻松地进行版本控制。同时,原始数据文件会被放在 .gitignore文件中。
$ cat data/.gitignore/data.xml
将元数据文件添加到Git中进行跟踪。
$ git add data/data.xml.dvc data/.gitignore
$ git commit -m "Add raw data"
dvc add 会将数据移动到项目的缓存中,并将其链接回工作区。
$ tree .dvc/cache../.dvc/cache
└── a3└── 04afb96060aad90176268345e10355
我们刚刚添加的data.xml文件的hash值(a304afb...)决定了上面的缓存路径。
如果你检查 data/data.xml.dvc,你也会在这里发现它:
$ cat data/data.xml.dvc outs:- md5: a304afb96060aad90176268345e10355path: data.xml
存储数据文件到远程存储库(dvc push)
您可以使用 dvc push 上传 DVC 跟踪的数据或模型文件,以便安全地远程存储它们。 这也意味着后面您可以使用 dvc pull 在其他环境中恢复它们。
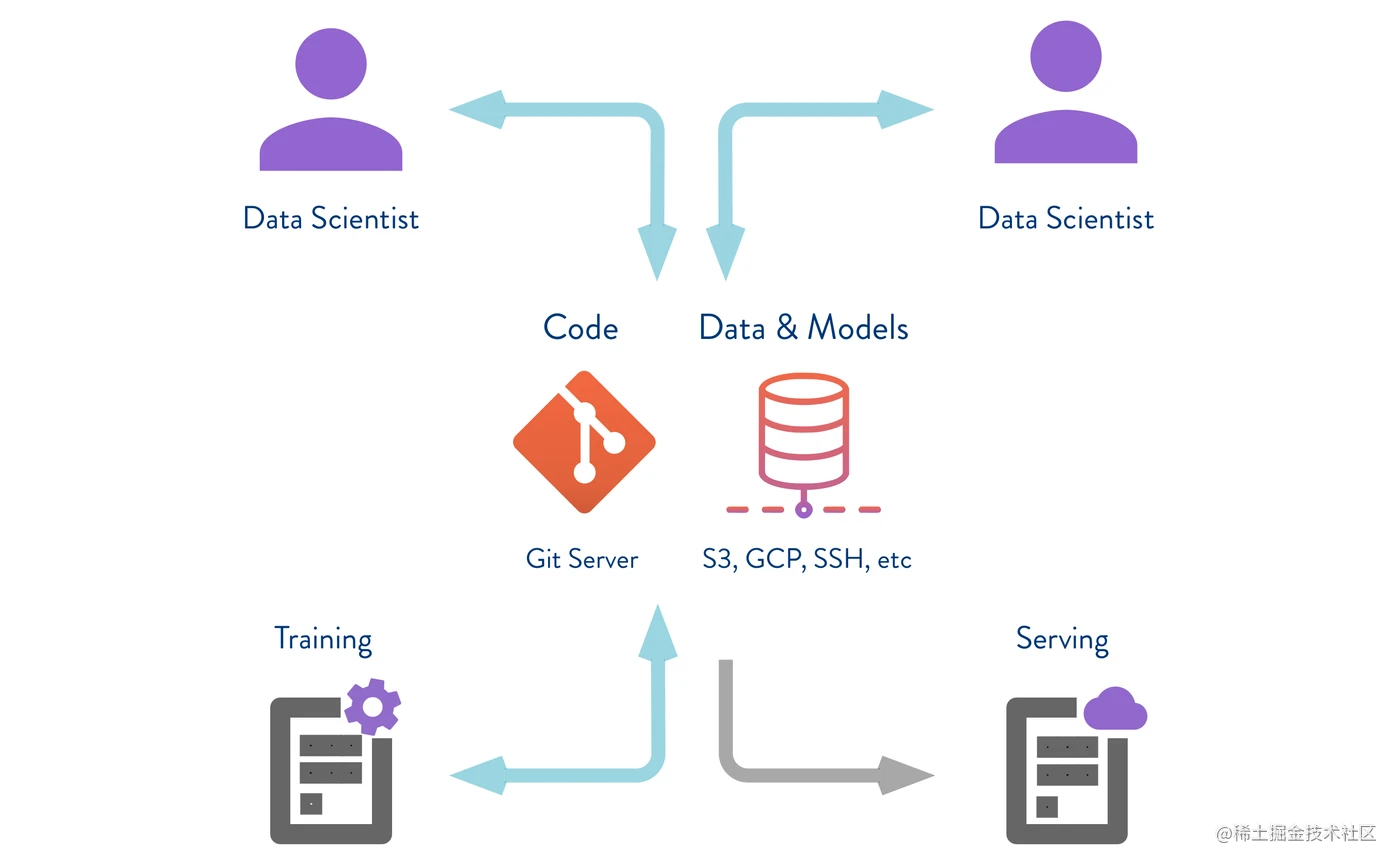
首先,我们需要设置一个远程存储库的地址,DVC 支持许多远程存储类型,包括 Amazon S3、SSH、Google Drive、Azure Blob Storage 和 HDFS,从上图我们也可以看到,代码与模型和数据文件是分开存储的。
# 配置远程Git仓库
$ git remote add origin https://gitee.com/xxxx/dvc-samples.git# 配置远程数据存储库(注:简单起见,这里我用的是本地的其他文件夹作为远程存储库,不推荐)
$ mkdir -p /home/lgd/dvc/local_remote_data_register
$ dvc remote add -d local_remote /home/lgd/dvc/local_remote_data_register# 查看配置
$ cat .dvc/config[core]remote = local_remote
['remote "local_remote"']url = /home/lgd/dvc/local_remote_data_register# 添加dvc配置文件到本地Git仓库
$ git add .dvc/config
$ git commit -m "Configure local remote storage"# 或者使用以下命令代替上面两条命令
# git commit .dvc/config -m "Configure local remote"
DVC 远程可让您将 DVC 跟踪的数据副本存储在本地缓存之外(通常是云存储服务)。
注意: 我这里Demo使用的是“本地远程”,虽然“本地远程”看起来似乎自相矛盾,但其实并非必须如此。 “本地”指的是文件位置为本地文件系统中的另一个文件夹。 “远程”就是我们所说的 DVC 项目的远程存储。 它本质上是一个本地数据备份。
然后,我们使用dvc push 将本地缓存的数据复制到我们之前设置的远程存储中。
$ dvc push
您可以使用以下命令检查数据是否已存储在 DVC 远程存储库中:
$ ls -R /home/lgd/dvc/local_remote_data_register/home/lgd/dvc/local_remote_data_register/:
a3/home/lgd/dvc/local_remote_data_register/a3:
04afb96060aad90176268345e10355
通常,我们也需要 git commit 和 git push 对应的 .dvc 文件,将.dvc元数据文件提交本地仓库并推送到Git远程仓库,示例如下:
$ git push origin main
下载与恢复数据(dvc pull)
将 DVC 跟踪的数据和模型文件存储在远程仓库之后,我们可以在需要时使用 dvc pull 将其下载到该项目的其他副本中。 通常,我们在 git clone 和 git pull 之后运行它。
在其他环境下载项目的数据,示例如下:
$ git clone https://gitee.com/xxxx/dvc-samples.git$ cd dvc-samples$ git pull origin main$ dvc pull
在本项目中恢复数据,示例如下:
$ cd example-get-started# 假设我们删除了本地缓存的数据
$ rm -rf .dvc/cache
$ rm -f data/data.xml# 恢复数据
$ dvc pull origin main
修改数据文件
当您对文件或文件夹进行更改时,再次运行 dvc add 以跟踪最新版本。
# 通过将数据集加倍来模拟修改数据
$ cp data/data.xml /tmp/data.xml
$ cat /tmp/data.xml >> data/data.xm# 跟踪最新版本
dvc add data/data.xml
通常情况下,我们还需要运行 git commit 和 dvc push 来保存更改。
$ git commit data/data.xml.dvc -m "Dataset updates"
$ dvc push
在版本之间进行切换(dvc checkout)
通常的工作流程是先使用git checkout(切换分支或切换.dvc文件版本),然后运行dvc checkout以同步数据。
# 首先,获取数据集的先前一个版本,让我们回到数据的原始版本
$ git checkout HEAD~1# 同步数据
$ dvc checkout
之后,让我们提交.dvc文件到本地Git仓库(这次不需要做 dvc push,因为这个原始版本的数据集已经保存在本地缓存和远程存储库了)。
$ git commit data/data.xml.dvc -m "Revert dataset updates"$ git push origin main
总结
其实,从技术上来讲,DVC 甚至不是版本控制系统! .dvc 元数据文件内容定义了数据文件的版本,本质上是通过 Git 来提供版本控制。 DVC 反过来创建这些 .dvc 文件,然后更新它们,并有效地同步工作空间中 DVC 跟踪的数据以匹配它们。