《DVC: An End-to-end Deep Video Compression Framework》
论文:点这里
原作代码:点这里
TensorFlow开源实现:OpenDVC
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, Zhiyong Gao
CVPR 2019 (Oral)
DVC是首个端到端的深度学习视频压缩框架,在深度学习视频压缩领域也常被视为基准算法,在它之后仍有多篇paper对其进行优化和改进,并且一些方法的代码也开源了,很值得学习。
Abstract
传统的视频压缩方法使用预测编码架构并对相应的运动信息和残差信息进行编码。本文利用传统视频压缩方法中的经典体系结构和强大的神经网络非线性表示能力,提出了第一个端到端视频压缩深度模型,该模型联合优化了视频压缩的所有模块。具体地,基于学习的光流估计被用来获得运动信息并重建当前帧。然后,采用两个自编码器样式的神经网络来压缩相应的运动和残差信息。所有模块都是通过单个损失函数共同学习的,其中,它们通过考虑减少压缩位数和提高解码视频质量之间的权衡来相互协作。实验结果表明,该方法在PSNR指标上可以优于广泛使用的视频编码标准H.264,在MS-SSIM指标上甚至可以与最新标准H.265媲美。
1. Introduction
现如今,视频内容贡献了80%以上的互联网流量[26],而且这一比例有望进一步提高。因此,在给定的带宽预算下,构建高效的视频压缩系统并生成更高质量的帧至关重要。另外,大多数与视频相关的计算机视觉任务(例如:视频目标检测或视频目标跟踪)对压缩视频的质量敏感,并且有效的视频压缩可能为其它计算机视觉任务带来好处。同时,视频压缩技术也有助于行为识别(action recognition)[41]和模型压缩(model compression)[16]。
然而,在过去的几十年中,视频压缩算法[39、31]依靠手动设计的模块,例如基于块的运动估计和离散余弦变换(DCT)(原文:block based motion estimation and Discrete Cosine Transform (DCT)),来减少视频序列中的冗余。尽管每个模块都经过精心设计,但整个压缩系统并未进行端到端优化。 期望通过联合优化整个压缩系统来进一步提高视频压缩性能。
最近,用于图像压缩的基于深度神经网络(DNN)的自动编码器[34,11,35,8,12,19,33,21,28,9]已获得与JPEG [37]、JPEG2000 [29]或BPG [1]等传统图像编解码器相当甚至更好的性能。一种可能的解释是,基于DNN的图像压缩方法可以利用大规模的端到端训练和高度非线性的变换,而传统方法则没有使用这种方法。
但是,直接应用这些技术来构建用于视频压缩的端到端学习系统并非易事。首先,学习如何生成和压缩针对视频压缩量身定制的运动信息仍然是一个悬而未决的问题。视频压缩方法严重依赖运动信息来减少视频序列中的时间冗余。一种简单的解决方案是使用基于学习的光流来表示运动信息。然而,当前基于学习的光流方法旨在产生尽可能精确的流场。但是,对于特定的视频任务,精确的光流通常不是最优的[42]。此外,与传统压缩系统中的运动信息相比,光流的数据量显着增加,并且直接应用[39,31]中的现有压缩方法来压缩光流值将大大增加存储运动所需的位数信息。第二,目前尚不清楚如何通过最小化残差和运动信息的率-失真(rate-distortion)来构建基于DNN的视频压缩系统。率-失真优化(RDO,Rate-distortion optimization)的目的是在给出用于压缩的位数(或比特率)(bits (or bit rate))时,实现更高质量的重构帧(即失真更少)。RDO对于视频压缩性能很重要。为了利用基于学习的压缩系统的端到端训练能力,需要使用RDO策略来优化整个系统。
在本文中,作者提出了第一个端到端深度视频压缩(DVC)模型,该模型可以共同学习运动估计、运动压缩和残差压缩。该网络的优点可总结如下:
-
视频压缩中的所有关键组件,即运动估计、运动补偿、残差压缩、运动压缩、量化和比特率估计,都是通过端到端的神经网络实现的。
-
视频压缩中的关键组件通过单个损失函数,在率-失真权衡的基础上进行联合优化,提高了压缩效率。
-
传统的视频压缩方法和我们提出的DVC模型之间存在一对一的映射关系。这项工作为从事视频压缩、计算机视觉和深层模型设计的研究人员提供了一座桥梁。例如,可以很容易地将更好的光流估计和图像压缩模型插入到该框架中。从事这些领域的研究人员可以使用DVC模型作为未来研究的起点。
实验结果表明,利用本文的神经网络方法对运动信息进行估计和压缩,可以显著提高压缩性能。当用PSNR衡量时,该框架优于广泛使用的视频编解码器H.264,当用多尺度结构相似性指数(MS-SSIM)衡量时,该框架与最新的视频编解码器H.265不相上下[38]。

2. Related Work
2.1. Image Compression
在过去的几十年里,人们提出了很多图像压缩算法[37,29,1]。这些方法严重依赖手工技术。例如,JPEG标准通过使用DCT将像素线性映射到另一个表示,并在熵编码之前量化相应的系数[37]。一个缺点是这些模块是单独优化的,可能无法达到最佳的压缩性能。
近年来,基于DNN的图像压缩方法越来越受到关注[34,35,11,12,33,8,21,28,24,9]。在文献[34,35,19]中,利用递归神经网络(RNNs)建立了一种渐进式图像压缩方案。采用CNN的其它编码方式进行网络压缩。为了优化神经网络,文献[34,35,19]中的工作只是尽量减少原始帧和重构帧之间的失真(例如,均方误差,mean square error),而没有考虑用于压缩的比特数。[11,12,33,21]采用了率-失真优化技术,通过在优化过程中引入位数来提高压缩效率。为了估计比特率,在[28,21,24]中学习了自适应算术编码方法的上下文模型,而在[11,33]中使用了非自适应算术编码。此外,为了提高图像压缩性能,还提出了其他技术,如广义除法归一化(generalized divisive normalization)(GDN)[11]、多尺度图像分解(multi-scale image decomposition)[28]、对抗训练(adversarial training)[28]、重要性图(importance map)[21,24]和帧内预测(intra prediction)[25,10]。这些现有的工作是本文视频压缩网络的重要组成部分。
2.2. Video Compression
在过去的几十年里,人们提出了几种传统的视频压缩算法,如H.264[39]和H.265[31]。这些算法大多遵循预测编码结构。尽管它们提供了高效的压缩性能,但它们是手动设计的,不能以端到端的方式联合优化。
对于视频压缩任务,已经提出了许多基于DNN的帧内预测和残差编码方法(intra prediction and residual coding)[13]、模式决策(mode decision)[22]、熵编码(entropy coding)[30]、后处理(post-processing)[23]。这些方法用来改善传统视频压缩算法中某一特定模块的性能,而不是建立端到端的压缩方案。在[14]中,Chen等,提出了一种基于块的视频压缩学习方法。然而,它不可避免地会在块之间的边界产生块度伪影(blockness artifact)。另外,他们利用先前重建的帧通过传统的基于块的运动估计传播的运动信息,这将降低压缩性能。Tsai等,提出了一种自动编码器网络来压缩特定领域视频的来自H.264编码器的残差[36]。这项工作没有使用深度模型进行运动估计、运动补偿或运动压缩。
最相关的工作是[40]中基于RNN的方法,其中视频压缩被定义为帧插值(frame interpolation)。然而,他们的方法中的运动信息也是由传统的基于块的运动估计产生的,而这些运动估计是由现有的基于非深度学习的图像压缩方法编码的[5]。也就是说,运动估计和压缩不是通过深度模型来完成的,也不是与其它组件联合优化的。另外,文献[40]中的视频编解码器只着眼于使原始帧和重建帧之间的失真(即均方误差)最小化,而没有考虑训练过程中的率-失真权衡。相比之下,在本文网络中,运动估计和压缩是由DNN来实现的,DNN通过考虑整个压缩系统的率-失真权衡,与其它组件联合优化。
2.3. Motion Estimation
运动估计是视频压缩系统中的一个重要组成部分。传统的视频编解码器使用基于块的运动估计算法[39],该算法很好地支持硬件实现。
在计算机视觉任务中,光流被广泛应用于时间关系的挖掘。近年来,人们提出了许多基于学习的光流估计方法[15,27,32,17,18]。这些方法激励我们将光流估计整合到我们的端到端学习框架中。与现有视频压缩方法中基于块的运动估计方法相比,基于学习的光流方法可以在像素级提供精确的运动信息,并且可以进行端到端的优化。然而,如果用传统的视频压缩方法对光流值进行编码,则需要更多的比特来压缩运动信息。
3. Proposed Method
Introduction of Notations.
V = { x 1 , x 2 , . . . , x t − 1 , x t , . . . } \ V={x_1,x_2,...,x_{t-1},x_t,...} V={x1,x2,...,xt−1,xt,...},表示当前视频序列;
x t \ x_t xt,时间步长 t \ t t处的原始帧;
x ˉ t \ \bar{x}_t xˉt,预测帧;
x ^ t \ \hat{x}_t x^t,重构/解码帧;
r t \ r_t rt,原始帧 x t \ x_t xt和预测帧 x ˉ t \ \bar{x}_t xˉt之间的残差(误差);
r ^ t \ \hat{r}_t r^t,表示重建/解码残差;
为了减少时间冗余,需要运动信息。其中, v t \ v_t vt表示运动矢量或光流值, v ^ t \ \hat{v}_t v^t 是其相应的重构版本。可以采用线性或非线性变换来提高压缩效率。因此,残差信息 r t \ r_t rt被变换为 y t \ y_t yt,运动信息 v t \ v_t vt可以变换为 m t \ m_t mt, r ^ t \ \hat{r}_t r^t 和 m ^ t \ \hat{m}_t m^t 分别是对应的量化版本。
3.1. Brief Introduction of Video Compression
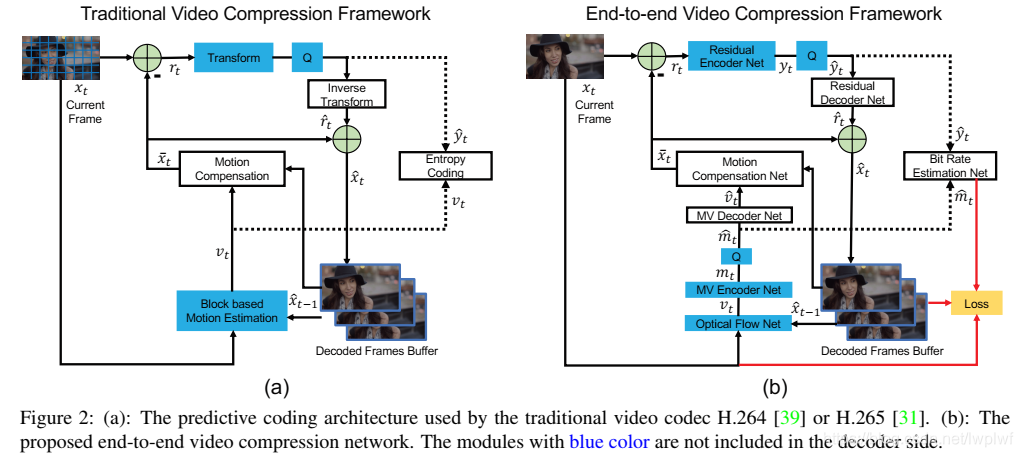
在本节中,简要介绍视频压缩。在[39,31]中提供了更多详细信息。通常,视频压缩编码器基于输入的当前帧生成比特流。并且解码器基于接收到的比特流来重构视频帧。在图2中,所有模块都包括在编码器侧,而蓝色模块不包括在解码器侧。
图2(a)中经典的视频压缩框架遵循预测转换架构。具体地说,输入帧 x t \ x_t xt被分成相同大小(例如8×8)的一组块,即正方形区域。编码器端传统视频压缩算法的编码过程如下:
-
Step 1. Motion estimation. (运动估计)
估计当前帧 x t \ x_t xt和前一重构帧 x ^ t \ \hat{x}_t x^t之间的运动,得到每个块对应的运动矢量 v t \ v_t vt。 -
Step 2. Motion compensation. (运动补偿)
基于Step 1中定义的运动矢量 v t \ v_t vt,通过将前一重构帧中的对应像素复制到当前帧来获得预测帧 x ˉ t \ \bar{x}_t xˉt。原始帧 x t \ x_t xt与预测帧 x ˉ t \ \bar{x}_t xˉt之间的残差为 r t \ r_t rt= x t \ x_t xt− x ˉ t \ \bar{x}_t xˉt。 -
Step 3. Transform and quantization. (变换与量化)
来自Step 2的残差 r t \ r_t rt被量化为 y ^ t \ \hat{y}_t y^t。在量化之前使用线性变换(例如,DCT),以获得更好的压缩性能。 -
Step 4. Inverse transform. (反变换)
Step 3中的量化结果 y ^ t \ \hat{y}_t y^t通过逆变换得到重构残差 r ^ t \ \hat{r}_t r^t。 -
Step 5. Entropy coding. (熵编码)
Step 1中的运动矢量 v t \ v_t vt和Step 3中的量化结果 y ^ t \ \hat{y}_t y^t都通过熵编码方法编码成比特(bits),并发送到解码器。 -
Step 6. Frame reconstruction. (帧重构)
Step 2中的预测帧 x ˉ t \ \bar{x}_t xˉt和Step 4中的重构残差 r ^ t \ \hat{r}_t r^t相加来获得重构帧 x ^ t \ \hat{x}_t x^t。重构帧将被第 ( t + 1 ) \ (t+1) (t+1)帧用于Step 1中的运动估计。
对于解码器,基于在Step 5中由编码器提供的比特,在Step 2执行运动补偿,在Step 4执行反量化,然后在Step 6执行帧重构以获得重构帧 x ^ t \ \hat{x}_t x^t。
3.2. Overview of the Proposed Method
图2(b)提供了端到端视频压缩框架的概述。传统的视频压缩框架与本文提出的基于深度学习的框架之间存在一一对应关系。两者之间的关系及差异简要如下:
-
Step N1. Motion estimation and compression. (运动估计与压缩)
使用CNN模型来估计光流[27],它被认为是运动信息 v t \ v_t vt。图3中提出了一个MV编解码器网络来压缩和解码光流值,而不是直接编码原始光流值。通过运动编码器网络编码得到 m t \ m_t mt,量化后的运动信息表示为 m ^ t \ \hat{m}_t m^t,运动信息 v t \ v_t vt经过MV解码器网络解码得到重构运动信息 v ^ t \ \hat{v}_t v^t。详见第3.3节。 -
Step N2. Motion compensation. (运动补偿)
基于Step N1中获得的光流,通过运动补偿网络来获得预测帧 x ˉ t \ \bar{x}_t xˉt。详见第3.4节。 -
Step N3-N4. Transform, quantization and inverse transform. (变换、量化与反变换)
使用高度非线性的残差编解码网络替换了Step 3中的线性变换,并通过残差编码网络将残差 r t \ r_t rt非线性映射到 y t \ y_t yt上。 然后将 y t \ y_t yt量化为 y ^ t \ \hat{y}_t y^t。为了建立端到端的训练方案,采用了文献[11]中的量化方法。然后 y ^ t \ \hat{y}_t y^t经过残差解码网络得到重构残差 r ^ t \ \hat{r}_t r^t。详见第3.5和3.6节。 -
Step N5. Entropy coding. (熵编码)
在测试阶段,将来自Step N1的量化运动信息 m ^ t \ \hat{m}_t m^t和来自Step N3的残差表示 y ^ t \ \hat{y}_t y^t编码为比特,然后发送到解码器。
在训练阶段,为了估算比特数成本,使用CNNs(图2中的比特率估算网络)来获得 m ^ t \ \hat{m}_t m^t和 y ^ t \ \hat{y}_t y^t中每个符号的概率分布。详见第3.6节。 -
Step N6. Frame reconstruction. (帧重构)
和3.1中的Step 6一样。Step N2中的预测帧 x ˉ t \ \bar{x}_t xˉt和Step N4中的重构残差 r ^ t \ \hat{r}_t r^t相加来获得重构帧 x ^ t \ \hat{x}_t x^t。重构帧将被第 ( t + 1 ) \ (t+1) (t+1)帧用于Step N1中的运动估计。
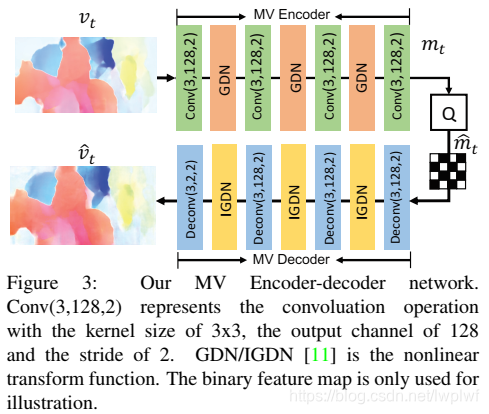
3.3. MV Encoder and Decoder Network
为了在Step N1压缩运动信息,设计了一个CNN将光流转换为相应的表示形式,以获得更好的编码效果。 具体来说,利用自动编码器样式的网络来压缩光流,这是[11]首次提出的用于图像压缩的任务。整个MV压缩网络如图3所示。光流 v t \ v_t vt进过一系列的卷积运算和非线性变换。除最后一个反卷积层等于2之外,用于卷积(反卷积)的输出通道数为128。给定光流 v t \ v_t vt的大小为M×N×2,MV编码器将生成大小为M/16×N/16×128的运动表示 m t \ m_t mt,然后 m t \ m_t mt被量化为 m ^ t \ \hat{m}_t m^t。MV解码器接收量化表示 m ^ t \ \hat{m}_t m^t并重构运动信息得到 v ^ t \ \hat{v}_t v^t。此外,量化表示 m ^ t \ \hat{m}_t m^t还将用于熵编码。
3.4. Motion Compensation Network
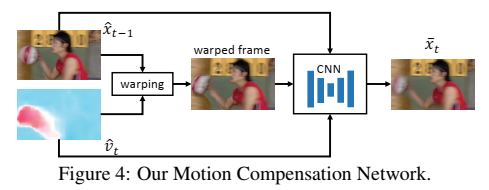
给定前一重构帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1和运动矢量 v ^ t \ \hat{v}_t v^t,运动补偿网络将获得预测帧 x ˉ t \ \bar{x}_t xˉt,该预测帧预计尽可能接近当前帧 x t \ x_t xt。首先,基于运动信息 v ^ t \ \hat{v}_t v^t将前一重构帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1变换到当前帧(current frame )。变换的帧仍然有伪影。为了消除伪影,将变换的帧 w ( x ^ t − 1 , v ^ t ) \ w(\hat{x}_{t-1},\hat{v}_t) w(x^t−1,v^t)、参考帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1和运动矢量 v ^ t \ \hat{v}_t v^t连接起来作为输入,然后将它们输入到另一个CNN中,以获得精确的预测帧 x ˉ t \ \bar{x}_t xˉt。网络的总体架构如图4所示。图4中CNN的细节在补充材料中提供。本文提出的方法是一种像素级的运动补偿方法,它可以提供更精确的时间信息,并且避免了传统的基于块的运动补偿方法中的块效应。这意味着不需要手工制作的循环滤波器或样本自适应偏移技术(loop filter or the sample adaptive offset technique)[39,31]来进行后期处理。
3.5. Residual Encoder and Decoder Network
如图2所示,原始帧 x t \ x_t xt和预测帧 x ˉ t \ \bar{x}_t xˉt之间的残差信息 r t \ r_t rt由残差编码器网络编码。本文利用文献[12]中高度非线性的神经网络将残差转化为相应的潜在表示。与传统视频压缩系统中的离散余弦变换相比,该方法可以更好地利用非线性变换的能力,获得更高的压缩效率。
3.6. Training Strategy
Loss Function.
视频压缩框架的目标是最小化用于对视频进行编码的位数,同时减少原始输入帧 x t \ x_t xt与重构帧 x ^ t \ \hat{x}_t x^t之间的失真。因此,文章提出以下率-失真优化问题,
λ D + R = λ d ( x t , x ^ t ) + ( H ( m ^ t ) + H ( y ^ t ) ) , ( 1 ) \ λD+R=λd(x_t,\hat{x}_t)+(H(\hat{m}_t)+H(\hat{y}_t)), (1) λD+R=λd(xt,x^t)+(H(m^t)+H(y^t)),(1)
其中 d ( x t , x ^ t ) \ d(x_t,\hat{x}_t) d(xt,x^t)表示 x t \ x_t xt和 x ^ t \ \hat{x}_t x^t之间的失真,在实现中使用均方误差(MSE)。 H ( ⋅ ) \ H(·) H(⋅)表示用于编码表示表示的位数。在本文方法中,残差表示 y ^ t \ \hat{y}_t y^t和运动表示 m ^ t \ \hat{m}_t m^t都应该被编码到比特流中。 λ \ λ λ是拉格朗日乘数,它决定了比特数和失真之间的权衡。如图2(b)所示,将重构帧 x ^ t \ \hat{x}_t x^t、原始帧 x t \ x_t xt和估计比特输入到损失函数。
Quantization.
在熵编码之前,需要对残差表示 y t \ y_t yt和运动表示 m t \ m_t mt等潜在表示进行量化。然而,量化运算不是差分的,这使得端到端的训练变得不可能。为了解决这个问题,已经有很多方法被提出[34,8,11]。本文采用文献[11]中的方法,并在训练阶段通过加入均匀噪声来代替量化运算。以 y t \ y_t yt为例,训练阶段的量化表示 y ^ t \ \hat{y}_t y^t是通过在 y t \ y_t yt上加上均匀噪声来近似得到的,即 y ^ t = y t + η \ \hat{y}_t=y_t+η y^t=yt+η,其中 η \ η η是均匀噪声。在推理阶段,直接四舍五入取整,即 y ^ t = r o u n d ( y t ) \ \hat{y}_t=round(y_t) y^t=round(yt)。
Bit Rate Estimation.
为了优化整个网络的比特数和失真度,需要获得所生成的潜在表示 y ^ t \ \hat{y}_t y^t和 m ^ t \ \hat{m}_t m^t的比特率 H ( y ^ t ) \ H(\hat{y}_t) H(y^t)和 H ( m ^ t ) \ H(\hat{m}_t) H(m^t)。比特率的正确度量是对应潜在表示符号的熵。因此,我们可以估计 y ^ t \ \hat{y}_t y^t和 m ^ t \ \hat{m}_t m^t的概率分布,然后得到相应的熵。本文利用[12]中的CNNs来估计分布。
Buffering Previous Frames.
如图2所示,在压缩当前帧时,在运动估计和运动补偿网络中需要前一重构帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1。但是,前一重构帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1是基于重构帧 x ^ t − 2 \ \hat{x}_{t-2} x^t−2的网络输出,依此类推。因此,在帧 x t \ x_t xt的训练过程中可能需要帧 x 1 , . . . , x t − 1 \ {x_1,...,x_{t−1}} x1,...,xt−1,这会减少小批量中训练样本的变化,并且当t较大时可能无法将其存储在GPU中。为了解决这个问题,本文采用了在线更新策略。具体地说,每次迭代中的重构帧 x ^ t \ \hat{x}_t x^t将保存在缓冲区中。在接下来的迭代中,当编码 x t + 1 \ x_{t+1} xt+1时,缓冲区中的 x ^ t \ \hat{x}_t x^t将用于运动估计和运动补偿。因此,缓冲区中的每个训练样本都将在一个epoch中更新。这样,可以在每次迭代中为一个视频片段优化并存储一个帧,从而更加高效。
4. Experiments
4.1. Experimental Setup
Datasets.
作者使用Vimeo-90k数据集[42]来训练提出的视频压缩框架,该数据集是该数据集是最近为评估不同的视频处理任务(如视频去噪和视频超分辨率)而构建的。它由89,800个独立的剪辑组成,这些剪辑的内容互不相同。
为了报告所提出的方法的性能,作者在UVG数据集[4]和HEVC标准测试序列(B类,C类,D类和E类)[31]上评估了提出的算法。这些数据集的内容和分辨率是多种多样的,它们被广泛用于衡量视频压缩算法的性能。
Evaluation Method(评估方法)
为了测量重构帧的失真,我们使用两个评估指标:PSNR和MS-SSIM [38]。与PSNR相比,MS-SSIM与人对失真的感知更好地相关。为了测量编码表示形式的位数,我们使用每像素位数(Bpp)表示当前帧中每个像素所需的位数。
Implementation Details(实施细节)
作者用不同λ(λ= 256,512,1024,2048)训练了四个模型。对于每个模型,使用Adam优化器[20],分别将初始学习率设置为0.0001,β1设置为0.9,将β2设置为0.999。当损失趋于稳定时,学习率除以10。mini-batch size设置为4。训练图像的分辨率为256×256。运动估计模块使用[27]中的预训练权重进行初始化。整个系统基于Tensorflow实现,使用两个Titan X GPU对整个网络进行训练大约需要7天时间。
4.2. Experimental Results
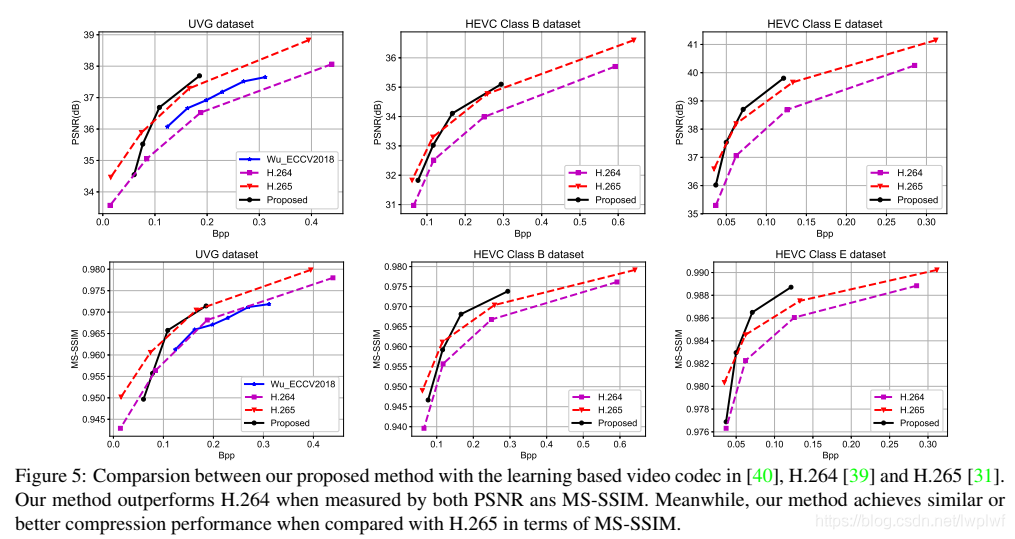
在本节中,将H.264[39]和H.265[31]都包括在内进行比较。此外,在文献[40]中Wu_ECCV2018的基于学习的视频压缩系统也包括在内以进行比较。为了通过H.264和H.265生成压缩帧,按照[40]中的设置,使用快速模式的FFmpeg。UVG数据集和HEVC数据集的GOP大小分别为12和10。有关H.264/H.265设置的更多详细信息,请参阅补充资料。
图5显示了在UVG数据集、HEVC B类和E类数据集上的实验结果。补充材料中提供了HEVC C级和D级的结果。显然,本文方法在很大程度上优于最新的视频压缩[40]。在UVG数据集上,该方法在相同的Bpp水平下获得了约0.6dB的增益。值得一提的是,本文方法仅使用一个之前的参考帧,而Wu等人的工作却没有。[40]利用双向帧预测,并且需要两个相邻帧。因此,利用多个参考帧中的时间信息可以进一步提高框架的压缩性能。
在大多数数据集上,当通过PSNR和MS-SSIM来衡量,本文提出的框架优于H.264标准。此外,与H.265相比,该方法在MS-SSIM指标上具有类似或更好的压缩性能。如前所述,损失函数中的失真项由MSE度量。尽管如此,根据MS-SSIM,本文方法仍可以提供合理的视觉质量。
4.3. Ablation Study and Model Analysis
Motion Estimation.
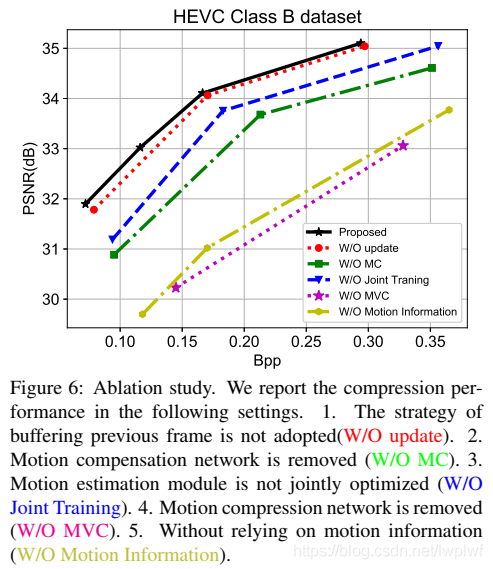
在本文提出的方法中,利用了端到端训练策略的优势,在整个网络中对运动估计模块进行优化。 因此,基于率-失真优化,系统中的光流有望得到进一步压缩,从而得到更精确的变换帧(warped frames)。为了验证其有效性,作者在整个训练阶段对初始化的运动估计模块的参数进行了固定,在这种情况下,对运动估计模块进行预训练只是为了更准确地估计光流,而不是为了获得最佳的率-失真。图6中的实验结果表明,与采用固定运动估计的方法相比,采用联合训练进行运动估计的方法可以显著提高运动估计的性能,在图6中由W/O联合训练表示(见蓝色曲线) 。
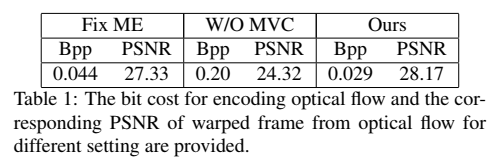
在表1中报告了用于编码光流的平均比特成本和相应的转换帧(warped frame)的峰值信噪比PSNR。具体地说,当运动估计模块在训练阶段固定时,对产生的光流进行编码需要0.044bpp,相应的转换帧的PSNR为27.33db。相比之下,在本文提出的方法中,需要0.029bpp来编码光流,并且转换帧的PSNR更高(28.17dB)。因此,联合学习策略不仅节省了编码操作所需的比特数,而且具有更好的转换图像质量。这些实验结果清楚地表明,将运动估计应用于率-失真优化可提高压缩性能。
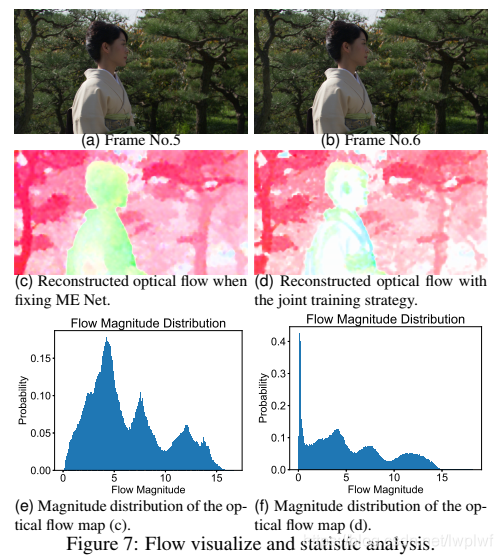
在图7中,提供了进一步的视觉比较。图7(a)和(b)表示序列的帧5和帧6。图7(c)表示在训练过程中光流网络被固定时的重建光流图。图7(d)表示使用联合训练策略后的重建光流图。图7(e)和(f)是光流量值的相应概率分布。可以看出,使用本文方法重建的光流包含了更多的像素,这些像素的流大小为零(例如,在人体区域)。尽管在这些区域中零值不是真正的光流值,但本文方法仍可以在均匀区域中生成精确的运动补偿结果。更重要的是,具有更多零值的光流图需要更少的比特来进行编码。例如,在图7(c)中对光流图进行编码需要0.045bpp,而对图7(d)中的光流图进行编码仅需要0.038bpp。
应该提到的是,在H.264[39]或H.265[31]中,为了获得更好的压缩性能,许多运动矢量被分配为零。令人惊讶的是,本文提出的框架可以学习相似的运动分布,而无需像[39,31]中那样依赖任何复杂的手工制作的运动估计策略。
Motion Compensation.
本文利用运动补偿网络,在估计光流的基础上,对转换帧进行改善(refine the warped frame)。为了评估该模块的有效性,作者进行了另一个实验,移除了系统中的运动补偿网络。用W/O MC表示的另一种方法的实验结果(见图6中的绿色曲线)表明,在相同的bpp水平下,没有运动补偿网络的PSNR将下降约1.0db。
Updating Strategy.(更新策略)
如第3.6节所述,在对当前帧xt进行编码时,我们使用在线缓冲区在训练阶段存储先前重建的帧x ^ t-1。我们还报告了在训练阶段将先前重建的帧x ^ t-1直接替换为先前的原始帧xt-1时的压缩性能。由W / O更新表示的替代方法的结果(参见红色曲线)如图6所示。它表明,在相同的bpp电平下,缓冲策略可以提供约0.2dB的增益。
如第3.6节所述,在对当前帧 x t \ x_t xt进行编码时,使用在线缓冲区在训练阶段存储前一重构帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1。还报告了在训练阶段,当前一重构帧 x ^ t − 1 \ \hat{x}_{t-1} x^t−1被先前的原始帧 x t − 1 \ x_{t−1} xt−1直接替换时的压缩性能。图6显示了由W/O update表示的替代方法的结果(见红色曲线)。结果表明,在相同的bpp水平下,缓冲策略可以提供约0.2dB的增益。
MV Encoder and Decoder Network.(MV编码器和解码器网络)
在本文提出的框架中,作者设计了一个CNN模型来压缩光流并编码相应的运动表示。在不使用CNN的情况下,直接对原始光流值进行量化编码也是可行的。作者进行了一个新的实验,去掉了MV编解码器网络。图6中的实验结果表明,去除运动压缩网络后,用W/O MVC表示的替代方法的PSNR(见红色曲线)将下降超过2db。此外,表1还提供了在该设置下对光流进行编码的比特成本和相应的转换帧的PSNR(用W/O MVC表示)。很明显,直接编码原始光流值需要更多的比特(0.20Bpp),对应的PSNR(24.43dB)比本文方法(28.17dB)要差得多。因此,当光流用于运动估计时,运动压缩是至关重要的。
Motion Information.(运动信息)
在图2(b)中,还研究了仅保留残差编码器和解码器网络的设置。与本文方法相比,在不使用任何运动估计方法的情况下单独处理每个帧(见由W/O运动信息表示的黄色曲线)导会致PSNR下降超过2dB。
Running Time and Model Complexity. (运行时间和模型复杂性)
本文提出的端到端视频压缩框架的参数总数约为11M,为了测试不同编解码器的速度,使用装有Intel Xeon E5-2640 v4 CPU和单个Titan 1080Ti GPU的计算机进行了实验。对于分辨率为352x288的视频,Wu等人[40]的每次迭代的编码(解码)速度为29fps(38fps),而本文的整体速度是24.5fps(41fps)。基于官方软件JM[2]和HM[3]的H.264和H.265的编码速度分别为2.4fps和0.35fps。商业软件x264[6]和x265[7]的编码速度分别为250fps和42fps。虽然商用编解码器x264[6]和x265[7]可以提供比本文更快的编码速度,但它们仍需要大量代码优化。
Bit Rate Analysis.(比特率分析)
本文利用文献[12]中的概率估计网络估计运动信息和残差信息的比特率。为了验证可靠性,使用图8(a)中的算术编码来比较估计的比特率和实际的比特率。很明显,估计的比特率与实际比特率很接近。此外,还进一步研究了比特率的组成。在图8(b)中,提供每个点的 λ \ λ λ值和运动信息的百分比。当目标函数 λ ∗ D + R \ {λ*D+R} λ∗D+R中的 λ \ λ λ变大时,整个Bpp也变大,而相应的运动信息百分比下降。
5. Conclusion
本文提出了一个完整的端到端深度学习视频压缩框架。该框架继承了传统视频压缩标准中经典预测编码方案的优点以及DNNs强大的非线性表示能力。实验结果表明,该方法优于目前广泛采用的H.264视频压缩标准和最新的基于学习的视频压缩系统。该工作为深度神经网络在视频压缩中的应用提供了一个很有前景的框架。基于所提出的框架,其他新的光流技术、图像压缩技术、双向预测技术和速率控制技术都可以很容易地嵌入到该框架中。