大家好,我是Mr数据杨,设想我们正准备上演一出《三国演义》,需要设置工作环境。就像古代的诸侯需要配置自己的军队和物资。在数据的世界里需要准备数据和代码,这就如同筹备兵马和粮草。
跟踪文件并上传,就像各诸侯的斥候寻找并记录各地的情况。DVC(数据版本控制)工作流程就好比一个国家的军事行动流程,规划,行动,反馈,校正,如此往复。现在需要构建一个机器学习模型。这就像三国时期的诸侯制定战略计划。准备数据,训练模型,评估模型,再标记提交,就像诸侯准备兵力,训练士兵,评估战局,然后决定下一步行动。
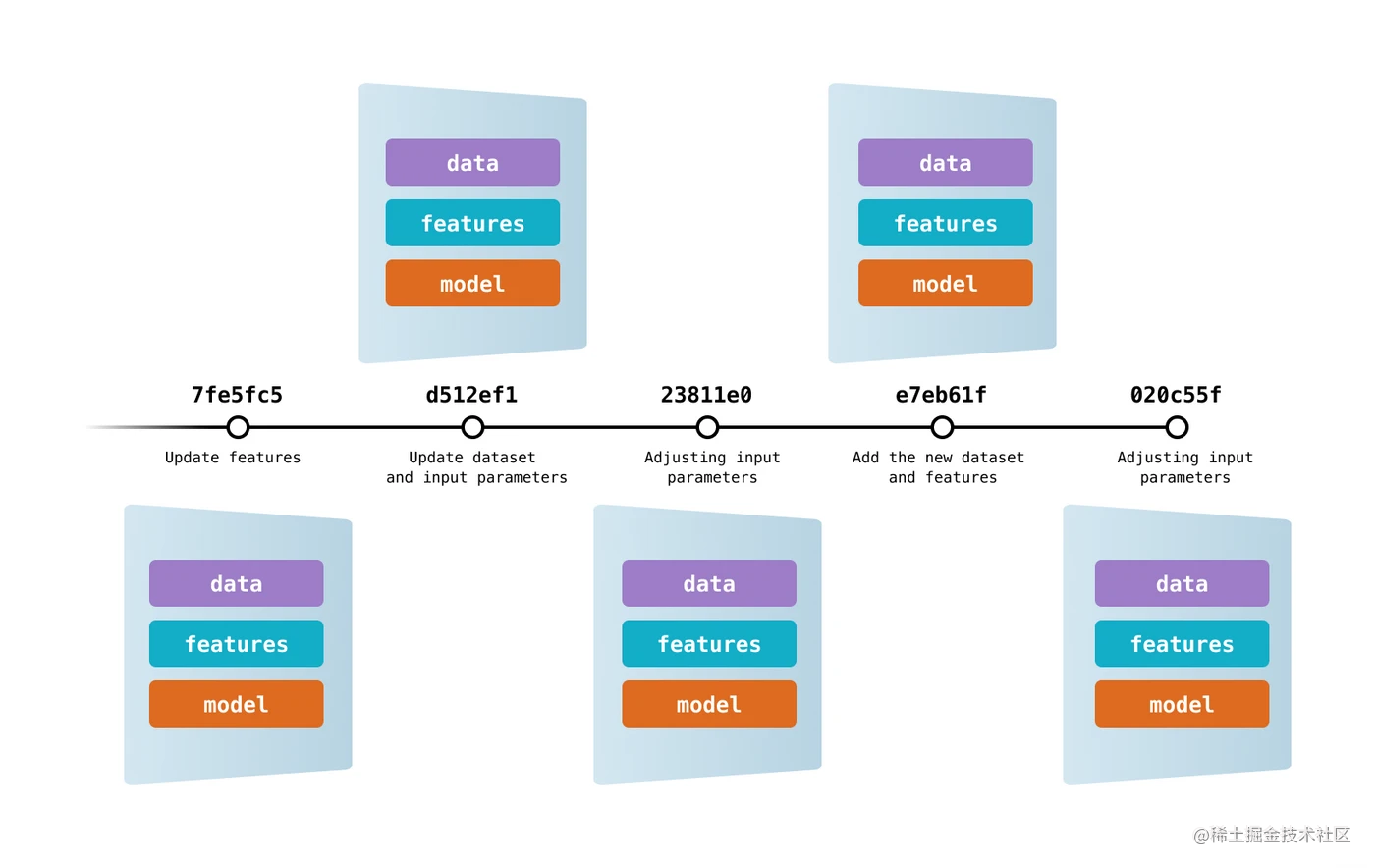
可以为每一个版本数据集和模型创建一个 Git 分支,如同在不同时期、不同战役下制定不同的战略。可以通过DVC文件查看不同版本的模型和数据,如同通过历史记录回顾过去的战役。共享程序开发如同各诸侯之间的联盟,通过共享资源和信息,达到共同的目标。通过创建可重现的Pipelines,将数据获取、数据预处理、训练模型、评估模型等步骤串联起来,如同一场完美的战役,每个环节都是环环相扣,无懈可击。
可以根据评估结果,调整或更换训练模型,如同诸侯根据战局变化,随时调整战术和策略。这就是Python和DVC的魅力,我们可以像《三国演义》的诸侯那样,通过策略和智谋,最终赢得这场数据之战!
文章目录
- 数据版本控制
- 什么是 DVC
- 设置工作环境
- 数据和代码
- 基本 DVC 工作流程
- 基础准备
- 跟踪文件
- 上传文件
- 下载文件
- 构建机器学习模型
- 准备数据
- 训练模型
- 评估模型
- 版本数据集和模型
- 标记提交
- 创建每一个 Git 分支
- DVC 文件查看
- 共享程序开发
- 创建可重现的Pipelines
- 获取数据、数据预处理阶段
- 训练模型阶段
- 评估模型阶段
- 更换训练模型
数据版本控制
数据科学和机器学习不仅仅涉及算法的设计与实现,还需要管理代码、数据和模型版本的复杂性。这就引出了数据版本控制的需求。标准的软件工程依赖于版本控制系统,例如Git来管理在共享代码库上的多人并行工作,处理同一代码的不同版本。

在版本控制系统的指引下,每个项目都有一个代表其当前官方状态的中央代码库。开发人员可以复制该项目,进行一些修改,并提出申请,使自己的新版本成为官方版本。之后还会对这些代码进行审查和测试,确保其质量足以部署到生产环境。
但在商业数据科学和机器学习中,我们缺少类似的约定和标准。于是,数据版本控制成了答案,它是一组工具和流程,致力于将版本控制过程适配到数据领域。此举可以加快结果的交付速度,提高结果质量,并使数据管理更透明,实验进行得更有效以及协作更为便捷。
DVC(Data Version Control)是一个极佳的例子,它是一个数据版本控制工具,可以帮助研究人员管理数据和模型,并运行可重复的实验。
什么是 DVC
DVC:Python版的数据版本控制工具
DVC是一款以Python编写的命令行工具,模仿了Git的命令和工作流程,旨在便于快速融入常规的Git实践中。DVC的工作原理是与Git一同运行,命令经常以串联的方式使用。Git专门用于存储和版本控制代码,而DVC则执行相同的功能,但专注于数据和模型文件。
Git可以在本地存储代码,同时也支持在GitHub、Bitbucket或GitLab等托管服务上存储代码。类似地,DVC使用远程仓库来存储所有的数据和模型。远程仓库的本地副本可获取和修改,之后可以上传更改,以便与团队成员共享。在任何服务器上都可以设置DVC远程仓库,并将其连接到电脑,以防止数据在远程被成员破坏或删除。
在数据和模型被存储在远程仓库中时,会生成一个.dvc文件。这是一个轻量级的小文本文件,指向远程存储中的实际数据文件,并被设计为与代码一起存储在GitHub中。当下载一个Git仓库时,也会得到这些.dvc文件,然后可以使用这些文件来获取与该仓库关联的数据。
在DVC的体系中,大型的数据和模型文件存储在DVC远程仓库,而小型的.dvc文件,指向这些数据,会被存储在GitHub中。
设置工作环境
由于 DVC 是一个命令行工具,因此需要熟悉在操作系统的命令行中工作。
conda create --name dvc python=3.8.2 -y: 这条命令用于创建一个新的Conda环境,名为"dvc",并在该环境中安装Python版本3.8.2。-y参数表示命令执行时不需要确认。conda activate dvc: 这条命令用于激活名为"dvc"的Conda环境,这样就可以在这个环境中运行Python代码了。
$ conda create --name dvc python=3.8.2 -y$ conda activate dvc
-
$ conda config --add channels conda-forge这条命令用于将conda-forge添加到conda配置中的channels列表里。conda-forge是一个社区驱动的,提供最新版本软件包的conda频道。 -
$ conda install dvc scikit-learn scikit-image pandas numpy这条命令用于安装以下几个库:dvc:数据版本控制,用于管理和版本化数据和模型。scikit-learn:一个为Python提供大量机器学习算法的库。scikit-image:用于图像处理的Python库。pandas:用于数据处理和分析的Python库。numpy:Python科学计算库,提供多维数组对象、矩阵等高级数学函数功能。
$ conda config --add channels conda-forge$ conda install dvc scikit-learn scikit-image pandas numpy
数据和代码
- DVC 管理Fork源码: 这是一个GitHub仓库,其中包含DVC (数据版本控制)的源代码。DVC是一个开源工具,可以用于版本控制数据和数据科学管道,这对于机器学习和数据科学项目非常有用。
- ImageNet Data: 这是ImageNet数据集的下载页面。ImageNet是一个大规模的视觉数据库,主要用于计算机视觉研究,特别是在深度学习和卷积神经网络的发展中发挥了重要作用。
- Imagenette Data: 这是Imagenette数据集的GitHub仓库。Imagenette是ImageNet的一个子集,包含10个类别,目的是提供一个更快、更简单的数据集,以便研究和试验新的机器学习方法和技术。

data:存放数据的目录。prepared:经过预处理后的内部数据。raw:原始的、未经处理的外部数据。
metrics:存放模型评估指标的目录。model:保存训练好的模型的目录。src:包含源代码的目录。evaluate.py:用于评估模型的脚本。prepare.py:用于数据预处理的脚本。train.py:用于训练模型的脚本。
data-version-control/
|
├── data/ # 数据获取来源
│ ├── prepared/ # 内部修改数据
│ └── raw/ # 外部数据
|
├── metrics/ # 模型指标评估
├── model/ # 模型保存目录
└── src/ # 存储源代码├── evaluate.py # 评估模型├── prepare.py # 数据预处理└── train.py # 训练模型
Imagenette 是一种图像分类数据集。这意味着每张图片都有一种与之相关联的类别,用于描述图片内容。因此,处理数据的一项重要工作就是将图片文件移动到相应的类别文件夹中。
在Imagenette的十个类别中,可以选择两个类别来构建二元分类模型。这种模型只会判断输入图片是否属于这两个选定类别之一。这是一个很好的方式来简化问题并专注于如何训练模型以区分两种类型的图片。
data-version-control/
|
├── data/
│ ├── prepared/
│ └── raw/
│ ├── train/
│ │ ├── n01440764/
│ │ ├── n02102040/
│ │ ├── n02979186/
│ │ ├── n03000684/
│ │ ├── n03028079/
│ │ ├── n03394916/
│ │ ├── n03417042/
│ │ ├── n03425413/
│ │ ├── n03445777/
│ │ └── n03888257/
| |
│ └── val/
│ ├── n01440764/
│ ├── n02102040/
│ ├── n02979186/
│ ├── n03000684/
│ ├── n03028079/
│ ├── n03394916/
│ ├── n03417042/
│ ├── n03425413/
│ ├── n03445777/
│ └── n03888257/
|
├── metrics/
├── model/
└── src/├── evaluate.py├── prepare.py└── train.py
基本 DVC 工作流程
DVC 如何与 Git 协同工作来管理的代码和数据。

基础准备
准备工作,为实验创建一个分支。
git是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。checkout是git的一个命令,用于切换到指定的分支或者提交。-b是checkout的一个选项,表示如果分支不存在,就新建一个分支。"first_experiment"是要切换(或创建)的分支的名称。
$ git checkout -b "first_experiment"
初始化 DVC,在项目中初始化Data Version Control(DVC)。
dvc init会在当前目录中创建一个新的DVC仓库。- DVC是一种开源的数据版本控制工具,主要用于数据科学和机器学习项目中管理数据和模型文件的版本。
- 这个命令会在当前目录下生成一个
.dvc的隐藏目录,用于存储DVC配置、缓存以及其他必要的文件。
$ dvc init
在DVC中添加了一个新的远程存储库,并设置它为默认的远程存储库。
dvc:这是执行DVC命令行工具的命令。remote add:这个子命令用于添加一个新的远程存储库。-d:这是一个选项,表示设置添加的远程存储库为默认的远程存储库。remote_storage:这是为远程存储库设定的名字,可以随后用这个名字来引用这个远程存储库。path/to/your/dvc_remote:这是远程存储库的路径,可以是本地的一个文件夹,也可以是一个云存储的地址,比如Amazon S3,Google Cloud Storage,或者其他DVC支持的存储服务的地址。
$ dvc remote add -d remote_storage path/to/your/dvc_remote
此期间会生成一个 config 基于文本的配置文件。
[core]定义了一组核心设置。analytics = false表明此设置禁用了分析或数据收集。remote = remote_storage设置了默认的远程存储位置为 “remote_storage”。
['remote "remote_storage"']定义了一个名为 “remote_storage” 的远程存储设置。url = /path/xxxxxx/remote_storage设置了远程存储的 URL 或路径,这里的路径是/path/xxxxxx/remote_storage。
[core]analytics = falseremote = remote_storage
['remote "remote_storage"']url = /path/xxxxxx/remote_storage
跟踪文件
将 train 和 val 目录添加到 DVC 控件。
dvc add data/raw/train:这个命令将会让DVC开始跟踪data/raw/train目录。DVC会为这个目录创建一个.dvc文件,这个文件描述了数据文件的版本信息。
$ dvc add data/raw/train
$ dvc add d:这个命令看起来并不完整。如果它是dvc add [some_file_or_directory]的形式,那它的功能是让DVC开始跟踪指定的文件或目录,并创建一个对应的.dvc文件来保存版本信息。
$ dvc add data/raw/val
执行过程涉及以下三个步骤:
- 添加
train/和val/文件夹到.gitignore。 - 生成两个.dvc扩展名的文件,即
train.dvc和val.dvc。 - 将
train/和val/复制到暂存区。
执行dvc add train/命令后,大文件的文件夹由DVC进行管理,而小文件如.dvc和.gitignore由Git控制。此外,train/文件夹也被添加到了暂存区或缓存中。

$ git add --all:这是一个Git命令。git:这是版本控制系统Git的命令行工具,用于执行各种Git操作。add:这是Git的一个子命令,用于将新的或已修改的文件添加到Git的暂存区域。--all:这是add命令的一个选项,表示将所有Git可见的文件添加到所有代码和小文件添加到 Git 控制 git add 中。
$ git add --all # --all开关将 Git 可见的所有文件添加到暂存区域。

上传文件
使用 git 创建快照 commit 提交上传。
git commit -m "First commit with setup and DVC files":这行代码在Git中创建了一个新的提交。提交是项目历史的一个快照,它包含了当前所有被跟踪文件的版本信息。-m标志表示对这次提交的描述,这次描述为"First commit with setup and DVC files"。dvc push:这行代码将Data Version Control(DVC)跟踪的数据和模型推送到默认的远程存储。DVC是一个开源的版本控制系统,用于处理大型文件,数据集,机器学习模型。dvc push命令类似于git push,但它专门用于处理DVC跟踪的文件和目录。
$ git commit -m "First commit with setup and DVC files"$ dvc push
DVC(Data Version Control)以智能方式进行数据备份。在进行此操作时,它首先会检查整个存储库目录,寻找所有的 .dvc 文件。.dvc 文件在这里起着重要的角色,它们标记了哪些数据需要被备份。在识别这些文件后,DVC 会进行下一步操作。
DVC 执行复制操作,将所有需要备份的数据从本地缓存复制到远程存储中。这就确保了数据的安全性,使得在需要时数据可以轻松恢复。

将 Git 控制下的文件推送到 GitHub。
git push: Git命令用于将本地仓库的更改上传到远程仓库。--set-upstream: 选项用于设置默认的远程仓库和分支,将来推送(push)或者拉取(pull)时可以不需要指定具体的远程仓库或者分支。origin: 这是推送到的远程仓库的名称,通常情况下origin是默认的远程仓库名称。first_experiment: 这是想要推送的本地分支的名称。此命令的含义是把first_experiment分支推送到origin远程仓库,并且设置origin为默认的远程仓库,first_experiment为默认的分支。
$ git push --set-upstream origin first_experiment

下载文件
先尝试这删除一些文件。可以删除整个 val/文件夹,确保该.dvc文件不会被删除。
$ rm -rf data/raw/val
被删除的内容在缓存中取回数据。
checkout是 DVC 的一个命令,这个命令的作用是根据 DVC 文件检出特定的数据版本。data/raw/val.dvc是一个 DVC 文件的路径,该文件包含了特定数据版本的元信息。- 整行代码的意思就是根据 “data/raw/val.dvc” 文件中记录的元信息检出相应的数据版本。
$ dvc checkout data/raw/val.dvc
首次在全新设备上克隆GitHub存储库时,本地缓存将为空。此时,理解如何填充这个空缓存成为关键步骤。
fetch是DVC的一个命令,用于从远程存储库中下载数据到本地DVC缓存。它不会将数据直接检出到工作区。这使得用户可以在需要时获取数据,而不会立即占用本地存储空间。data/raw/val.dvc是指定的DVC文件的路径。这个文件包含了版本控制的数据的元数据。DVC通过读取这个文件中的元数据,来知道如何从远程存储库获取相应的数据。
$ dvc fetch data/raw/val.dvc
dvc pull 执行 dvc fetch,然后执行 dvc checkout。 在一次扫描中将数据从远程复制到缓存并复制到存储库中。 这些命令大致模仿了 Git 的功能,因为 Git 也有 fetch、checkout 和 pull 命令。

构建机器学习模型
准备数据
为了方便使用,将创建一个CSV文件,其中列出所有用于训练的图像及其对应标签。CSV文件将有两列,一列是图像文件的完整路径(filename),一列是标签字符串(label)。
filename, label
full/path/to/data-version-control/raw/n03445777/n03445777_5768.JPEG,golf ball
full/path/to/data-version-control/raw/n03445777/n03445777_5768,golf ball
full/path/to/data-version-control/raw/n03445777/n03445777_11967.JPEG,golf ball
- train.csv:包含用于训练的图像列表。
- test.csv:包含用于测试的图像列表。
数据处理 prepare.py。
- 导入依赖库:
pathlib:Python 3.4 版本开始提供的一种面向对象的文件系统路径操作库。pandas:一个强大的数据处理库。
- 定义一个字典
FOLDERS_TO_LABELS,将图像所在的文件夹名称映射到具体的标签。 - 定义函数
get_files_and_labels(source_path),用于从给定的路径(及其子文件夹)中收集所有图像的绝对路径和对应的标签。 - 定义函数
save_as_csv(filenames, labels, destination),它接收文件名和标签列表,然后使用 pandas 创建一个 DataFrame,并将其保存为 CSV 文件。 - 定义函数
main(repo_path),这是主函数,负责设置输入和输出路径,并调用之前定义的函数,从给定路径中提取图像文件名和标签,然后保存为 CSV 文件。 if __name__ == "__main__":这一部分是Python程序的入口点,当直接运行此文件时,以下的代码会被执行。这部分代码首先获取当前文件的父文件夹路径,然后调用 main 函数开始执行程序的主要任务。
from pathlib import Pathimport pandas as pd# 映射文件夹名称
FOLDERS_TO_LABELS = {"n03445777": "golf ball","n03888257": "parachute"}# 获取标签的文件列表
def get_files_and_labels(source_path):images = []labels = []for image_path in source_path.rglob("*/*.JPEG"):filename = image_path.absolute()folder = image_path.parent.nameif folder in FOLDERS_TO_LABELS:images.append(filename)label = FOLDERS_TO_LABELS[folder]labels.append(label)return images, labels# 保存label为 CSV 文件
def save_as_csv(filenames, labels, destination):data_dictionary = {"filename": filenames, "label": labels}data_frame = pd.DataFrame(data_dictionary)data_frame.to_csv(destination)def main(repo_path):data_path = repo_path / "data"train_path = data_path / "raw/train"test_path = data_path / "raw/val"train_files, train_labels = get_files_and_labels(train_path)test_files, test_labels = get_files_and_labels(test_path)prepared = data_path / "prepared"save_as_csv(train_files, train_labels, prepared / "train.csv")save_as_csv(test_files, test_labels, prepared / "test.csv")if __name__ == "__main__":repo_path = Path(__file__).parent.parentmain(repo_path)
完成脚本后,data/prepared/文件夹中会生成两个重要的文件:train.csv和test.csv。这两个文件是训练和测试模型的基石。要跟踪这些文件的版本并存储它们,可以利用数据版本控制工具DVC。
dvc add data/prepared/train.csv data/prepared/test.csv:这个命令是用于版本控制的工具DVC (Data Version Control) 中的一个命令,它将data/prepared/train.csv和data/prepared/test.csv文件加入到DVC的版本管理中。git add --all:这是Git命令,用于将所有未追踪的文件添加到Git的暂存区。git commit -m "Created train and test CSV files":这也是Git命令,用于将暂存区的文件提交到Git仓库,并附带一个提交信息 “Created train and test CSV files”,说明这次提交的内容或目的。
$ dvc add data/prepared/train.csv data/prepared/test.csv
$ git add --all
$ git commit -m "Created train and test CSV files"
训练模型
模型训练采用的是一种被誉为“监督学习”的策略。具体步骤如下:
- 提供图像:首先,模型被展示一张图像,任务是尝试预测图像所展示的内容。
- 猜测与校验:模型对所展示图像做出预测后,会接受一个“真实”的标签作为反馈。
- 自我修正:如果预测不准确,模型会根据误差进行自我修正,以提高未来的预测准确性。
这一流程在整个数据集中的每个图像和其相应的标签上重复多次,以此实现模型的学习与进步。
模型训练 train.py
- 从
joblib导入dump函数,用于保存模型 - 从
pathlib导入Path,方便进行路径操作 - 导入
numpy和pandas,用于数据处理 - 从
skimage.io导入imread_collection,用于读取图片数据 - 从
skimage.transform导入resize,用于调整图片大小 - 从
sklearn.linear_model导入SGDClassifier,一个随机梯度下降的线性分类器 load_images:从给定的data_frame加载图像数据load_labels:从给定的data_frame加载标签数据preprocess:对输入的图像进行预处理,将其大小调整为 (100, 100, 3) 并将其重塑为 (1, 30000) 的数组load_data:从指定的路径加载数据,对图像数据进行预处理,并返回处理后的图像数据和对应的标签main:读取训练数据,训练 SGD 分类器,并将训练好的模型保存到指定的路径
程序运行时,会获取当前文件的父目录作为仓库路径,并以此路径作为参数调用主函数 main。
from joblib import dump
from pathlib import Pathimport numpy as np
import pandas as pd
from skimage.io import imread_collection
from skimage.transform import resize
from sklearn.linear_model import SGDClassifier# 加载图像数据
def load_images(data_frame, column_name):filelist = data_frame[column_name].to_list()image_list = imread_collection(filelist)return image_list# 加载标签数据
def load_labels(data_frame, column_name):label_list = data_frame[column_name].to_list()return label_list# 数据处理
def preprocess(image):resized = resize(image, (100, 100, 3))reshaped = resized.reshape((1, 30000))return reshape# 模型加载数据
def load_data(data_path):df = pd.read_csv(data_path)labels = load_labels(data_frame=df, column_name="label")raw_images = load_images(data_frame=df, column_name="filename")processed_images = [preprocess(image) for image in raw_images]data = np.concatenate(processed_images, axis=0)return data, labels# 模型训练主程序
def main(repo_path):train_csv_path = repo_path / "data/prepared/train.csv"train_data, labels = load_data(train_csv_path)sgd = SGDClassifier(max_iter=10)trained_model = sgd.fit(train_data, labels)dump(trained_model, repo_path / "model/model.joblib")if __name__ == "__main__":repo_path = Path(__file__).parent.parentmain(repo_path)
在脚本执行完毕后,会在model/目录下生成一个名为model.joblib的经过训练的机器学习模型文件。这个文件在整个实验过程中扮演着至关重要的角色。需要将该文件纳入DVC(数据版本控制)的管理,并将相应的.dvc文件提交到GitHub。
dvc add model/model.joblib: 这条命令将 “model.joblib” 文件添加到 DVC,DVC 会为该文件生成一个 “.dvc” 文件以跟踪文件版本。DVC 通常用于数据科学项目中对大型数据文件、模型、指标文件等进行版本控制。git add --all: 这是 Git 的一个命令,用于将项目中的所有未跟踪或已修改的文件添加到 Git 的暂存区,准备进行下一次的提交。git commit -m "Trained an SGD classifier": 这条命令将前一步添加到暂存区的所有文件进行提交,创建一个新的版本,并附带一条提交信息 “Trained an SGD classifier”,这条信息是对这次提交的描述。
$ dvc add model/model.joblib
$ git add --all
$ git commit -m "Trained an SGD classifier"
评估模型
利用数字来表示模型的表现情况。
模型训练 evaluate.py
- 导入了
joblib模块的load方法,它用于加载序列化的Python对象。 - 导入
json模块,用于处理JSON数据。 - 导入
pathlib模块的Path类,用于处理文件和目录路径。 - 导入
sklearn.metrics的accuracy_score函数,用于计算模型的精确度。 - 从
train模块中导入load_data函数,用于加载数据。 - 定义了一个
repo_path的路径,这是你的项目的根目录。 - 设置了
test_csv_path路径,该路径是预处理过的测试数据的位置。 - 调用
load_data函数加载测试数据和对应的标签。 - 加载了训练过的模型。
- 使用加载的模型对测试数据进行预测。
- 计算预测结果的精确度。
- 将精确度结果存入字典
metrics。 - 定义了精确度结果的存储路径
accuracy_path。 - 将精确度结果写入到
accuracy.json文件。
from joblib import load
import json
from pathlib import Pathfrom sklearn.metrics import accuracy_scorefrom train import load_datadef main(repo_path):test_csv_path = repo_path / "data/prepared/test.csv"test_data, labels = load_data(test_csv_path)model = load(repo_path / "model/model.joblib")predictions = model.predict(test_data)accuracy = accuracy_score(labels, predictions)metrics = {"accuracy": accuracy}accuracy_path = repo_path / "metrics/accuracy.json"accuracy_path.write_text(json.dumps(metrics))if __name__ == "__main__":repo_path = Path(__file__).parent.parentmain(repo_path)
执行脚本可以获得一个准确率。
{ "accuracy": 0.7781238791545 }
准确率 JSON 文件非常小,将其保存在 GitHub 中很有用,这样可以快速检查每个实验的执行情况。
$ git add --all
$ git commit -m "Evaluate the SGD model accuracy"
版本数据集和模型
首先对 first_experiment 分支所做的所有更改推送到 GitHub 和 DVC 远程存储。
$ git push
$ dvc push
标记提交
在Git版本控制系统中创建一个新的标签。
git tag:这是Git命令,用于创建、列出、删除或验证使用GPG签名的标签对象。-a:这是一个选项,表示创建一个带注解的标签。与轻量级标签(不带-a、-s或-m的标签)相比,带注解的标签可以存储更多信息,例如创建人、创建日期和标签信息。sgd-classifier:这是你要创建的标签的名称。-m:这是一个选项,允许你为标签添加一条消息,这条消息会被存储在标签信息中。"SGDClassifier with accuracy 77.81%":这是你为标签添加的消息,描述了这个标签的内容或含义。在这个例子中,消息是 “SGDClassifier with accuracy 77.81%”,表示这个代码版本实现的SGD分类器的准确率为77.81%。
$ git tag -a sgd-classifier -m "SGDClassifier with accuracy 77.81%"
Git 标签不会通过常规提交推送,因此必须单独推送到 GitHub 上的存储库源或使用的任何平台。 使用 --tags 开关将所有标签从本地存储库推送到远程服务器。
$ git push origin --tags
可以随时查看当前存储库中的所有标签。
$ git tag
创建每一个 Git 分支
将模型的最大迭代次数设置为100。可以尝试将该数字设置得更高来观察结果是否改善,创建一个新分支并调用 sgd-100-iterations 。
$ git checkout -b "sgd-100-iterations"
train.py 中修改代码
- 这个函数名为
main,它接受一个参数repo_path,代表的是存储库路径。 train_csv_path是准备好的训练数据CSV文件的路径,这个文件在存储库路径的"data/prepared"目录下。load_data(train_csv_path)是一个函数,用于从CSV文件中加载训练数据和对应的标签。这个函数的输出是一个包含两个元素的元组,第一个元素是训练数据,第二个元素是对应的标签。SGDClassifier(max_iter=100)创建了一个随机梯度下降分类器实例,其中max_iter参数指定了优化算法的最大迭代次数。sgd.fit(train_data, labels)使用训练数据和对应的标签来训练随机梯度下降分类器,得到训练后的模型trained_model。dump(trained_model, repo_path / "model/model.joblib")将训练后的模型保存到存储库路径的"model"目录下,文件名为"model.joblib"。
def main(repo_path):train_csv_path = repo_path / "data/prepared/train.csv"train_data, labels = load_data(train_csv_path)sgd = SGDClassifier(max_iter=100) # 修改这里trained_model = sgd.fit(train_data, labels)dump(trained_model, repo_path / "model/model.joblib")
然后进行模型的训练和评估,并且回生成新的模型文件和结果json文件。
$ python src/train.py
$ python src/evaluate.py
将提交结果到 DVC 缓存中。
$ dvc commit
添加并提交 Git 中。
$ git add --all:这条命令将会把所有的修改(包括新文件、修改的文件和删除的文件)添加到暂存区。--all选项意味着所有改变的文件,不论是追踪的还是未追踪的文件都会被添加。$ git commit -m "Change SGD max_iter to 100":这条命令将会创建一个新的提交(commit),记录当前项目的一个版本。-m选项后面的文本是对这次提交的描述信息,它帮助其他开发者了解这次提交做了什么改动。在这个例子中,描述信息是 “Change SGD max_iter to 100”,表示这次提交修改了SGD的最大迭代次数为100。
$ git add --all
$ git commit -m "Change SGD max_iter to 100"
标记新的实验。
git tag -a sgd-100-iter -m "Trained an SGD Classifier for 100 iterations": 这行命令在本地Git仓库中创建了一个名为 “sgd-100-iter” 的注释标签,并为这个标签添加了一条描述信息 “Trained an SGD Classifier for 100 iterations”。-a选项表示创建一个带有注解的标签,-m选项后跟的是标签的描述信息。git push origin --tags: 这行命令将所有未推送的本地标签推送到远程仓库 “origin”。--tags选项告诉 Git 将所有标签推送到远程仓库。
$ git tag -a sgd-100-iter -m "Trained an SGD Classifier for 100 iterations"
$ git push origin --tags
将代码更改推送到 GitHub 并将 DVC 更改推送到您的远程存储。
git push --set-upstream origin sgd-100-iter:这个命令的功能是将本地的sgd-100-iter分支推送到远程仓库(origin)。--set-upstream参数将origin设为默认远程仓库,之后使用git push就可以直接推送到这个远程仓库。dvc push:DVC(Data Version Control)是一个用于数据科学和机器学习项目的版本控制工具。dvc push命令的功能是将数据集(已被DVC管理)上传到远程存储。这使得其他人能够通过dvc pull下载并使用相同的数据集。
$ git push --set-upstream origin sgd-100-iter
$ dvc push
从 GitHub 签出代码然后从 DVC 签出数据和模型来在分支之间跳转,也可以查看 first_example 分支并获取关联的数据和模型。
$ git checkout first_experiment: 这条命令是在Git中切换到名为first_experiment的分支。Git是一个版本控制系统,允许开发者保存项目的不同版本,分支是对源代码不同版本的引用。$ dvc checkout: 这是Data Version Control(DVC)的一个命令,用于恢复文件和目录。DVC是一个版本控制系统,用于数据科学和机器学习项目,可以追踪大文件、目录或ML实验,而不会将它们添加到Git中。这条命令将会恢复DVC追踪的文件和目录到当前Git分支下的最新版本。
$ git checkout first_experiment
$ dvc checkout
DVC 文件查看
打开 data-version-control/model/model.joblib.dvc。
md5: 这是文件的 MD5 哈希值,用于验证文件的完整性。62bdac455a6574ed68a1744da1505745是特定文件的哈希值。outs: 这是一个列表,包含了项目的输出文件的信息。md5: 这是特定输出文件的 MD5 哈希值,96652bd680f9b8bd7c223488ac97f151是这个输出文件的哈希值。path: 这是输出文件的路径或文件名,model.joblib是一个输出文件的名称。cache: 表示是否需要对该输出文件进行缓存,这里的true表示需要。metric: 表示该文件是否为度量文件,这里的false表示不是。persist: 表示是否要持久化这个文件,这里的false表示不需要。
md5: 62bdac455a6574ed68a1744da1505745
outs:- md5: 96652bd680f9b8bd7c223488ac97f151path: model.joblibcache: truemetric: falsepersist: false
共享程序开发
在计算机的某个位置创建一个新文件夹。调用shared_cache 作为 DVC 为该文件夹用作缓存。现在每次运行 dvc add 或 dvc commit 时,数据都会备份到该文件夹中。
$ dvc cache dir path/to/shared_cache
那么所有文件都将位于存储库的 .dvc/cache 文件夹中。数据从默认缓存移动到新的共享缓存中,将 .dvc/cache 目录下的所有文件和目录移动到 path/to/shared_cache 目录下。
$ mv .dvc/cache/* path/to/shared_cache
机器上的所有用户现在可以将他们的存储库缓存指向共享缓存。

现在拥有了一个共享缓存,所有其他用户都可以为他们的存储库共享该缓存。如果操作系统 (OS) 不允许所有人使用共享缓存,请确保系统上的所有权限均已正确设置。
数据缓存备份,检查存储库的.dvc/config文件。
[cache]dir = /path/to/shared_cache
创建可重现的Pipelines
获取数据、数据预处理阶段
创建一个新分支并调用 sgd-pipeline。整个命令的含义是在当前Git仓库中创建一个名为sgd-pipeline的新分支,并立即切换到这个新分支上。
$ git checkout -b sgd-pipeline
运行prepare.py作为DVC Pipelines阶段。 执行此操作的命令是dvc run,需要知道依赖项、输出和命令。

prepare.py 使用以下命令作为DVC管道阶段执行dvc run。
dvc run -n prepare: 使用DVC (Data Version Control) 运行一个名为 “prepare” 的pipeline阶段。Pipeline阶段是一种用来组织和执行数据科学项目中的任务的工具。-d src/prepare.py -d data/raw: 指定该pipeline阶段依赖于 “src/prepare.py” 文件和 “data/raw” 文件夹。任何这些依赖项的更改都可能需要重新运行阶段。-o data/prepared/train.csv -o data/prepared/test.csv: 这个pipeline阶段的输出是 “data/prepared/train.csv” 和 “data/prepared/test.csv”。如果这些文件不存在或已更改,那么阶段可能需要重新运行以生成它们。python src/prepare.py: 这是运行阶段时需要执行的实际命令,也就是执行 “prepare.py” 文件中的Python代码。
$ dvc run -n prepare \ # 要运行 pipeline 阶段并将其称为准备-d src/prepare.py -d data/raw \ # pipeline 需要 prepare.py 文件和 data/raw 文件夹-o data/prepared/train.csv -o data/prepared/test.csv \ # pipeline 将生成 train.csv 和 test.csv 文件python src/prepare.py # 执行的命令是 python src/prepare.py
DVC 将创建两个文件,dvc.yaml 和 dvc.lock。
dvc.yaml
stages: 这部分定义了在这个项目中的所有阶段。在这个例子中,我们只有一个阶段,叫做prepare。prepare: 这是一个阶段的名称,它可以是任意的,但在这里我们把它命名为prepare。cmd: 这是在prepare阶段中要执行的命令。在这个例子中,我们运行python src/prepare.py。这个命令将使用 Python 执行位于src目录下的prepare.py脚本。deps: 这是prepare阶段的依赖项,也就是说,如果这些文件发生了改变,那么prepare阶段就需要重新运行。在这个例子中,依赖项有data/raw和src/prepare.py。outs: 这是prepare阶段的输出,也就是该阶段运行之后应该产生的文件。在这个例子中,输出文件有data/prepared/test.csv和data/prepared/train.csv。如果这些文件不存在或者有任何改变,那么prepare阶段就需要重新运行。
stages:prepare:cmd: python src/prepare.pydeps:- data/raw- src/prepare.pyouts:- data/prepared/test.csv- data/prepared/train.csv
dvc.lock
prepare::定义一个新的阶段,这个阶段的名字是"prepare"。cmd: python src/prepare.py:这是在"prepare"阶段要执行的命令,即运行名为prepare.py的Python脚本,该脚本位于src文件夹中。deps::定义了"prepare"阶段的依赖项。依赖项包括:data/raw:原始数据的文件夹,其MD5哈希值用于检查数据是否有变动。src/prepare.py:Python脚本的文件,其MD5哈希值用于检查代码是否有变动。
outs::定义了"prepare"阶段的输出项。输出项包括:data/prepared/test.csv:测试数据集的CSV文件。data/prepared/train.csv:训练数据集的CSV文件。
prepare:cmd: python src/prepare.pydeps:- path: data/rawmd5: a8a5252d9b14ab2c1be283822a86981a.dir- path: src/prepare.pymd5: 0e29f075d51efc6d280851d66f8943feouts:- path: data/prepared/test.csvmd5: d4a8cdf527c2c58d8cc4464c48f2b5c5- path: data/prepared/train.csvmd5: 50cbdb38dbf0121a6314c4ad9ff786fe
流程图
训练模型阶段
使用dvc (Data Version Control) 工具运行一个命名为 train 的阶段。
-n train: 创建一个名为 “train” 的新阶段。-d src/train.py: 将src/train.py设置为阶段依赖。如果文件改变,DVC 会认为阶段需要重新运行。-d data/prepared/train.csv: 将data/prepared/train.csv设置为另一个阶段依赖。这通常是输入数据文件。-o model/model.joblib: 将model/model.joblib设置为阶段输出。DVC 会跟踪这个文件的变化。python src/train.py: 是你实际要运行的命令,这里是运行 Python 脚本来训练模型。

当 src/train.py 或 data/prepared/train.csv 有任何更改时,重新运行 python src/train.py 并生成新的 model.joblib。
$ dvc run -n train \-d src/train.py -d data/prepared/train.csv \-o model/model.joblib \python src/train.py
创建 Pipeline 的第二阶段并将其记录在 dvc.yml 和 dvc.lock 文件中。
评估模型阶段
使用dvc (Data Version Control) 工具运行一个命名为 evaluate 的阶段。
dvc run: DVC(Data Version Control)的命令,用于运行数据科学或机器学习工作流的步骤并记录其结果。-n evaluate: 命名该步骤为"evaluate"。-d src/evaluate.py -d model/model.joblib: 定义步骤的依赖,即运行此步骤需要的文件。在这个例子中,依赖的文件是src/evaluate.py和model/model.joblib。-M metrics/accuracy.json: 定义要生成的指标文件,这些文件会被DVC追踪,以检查步骤的效果。在这个例子中,metrics/accuracy.json就是一个指标文件。python src/evaluate.py: 运行src/evaluate.py脚本的命令,这个脚本通常用来评估模型的表现。

$ dvc run -n evaluate \-d src/evaluate.py -d model/model.joblib \-M metrics/accuracy.json \python src/evaluate.py
dvc metrics show是 Data Version Control (DVC) 工具的一个命令,用于显示项目中定义的指标。metrics/accuracy.json:这部分表示 DVC 正在从accuracy.json这个文件中提取指标。accuracy: 0.6996197718631179这部分显示了在accuracy.json文件中定义的accuracy指标的值,值为0.6996197718631179。
$ dvc metrics showmetrics/accuracy.json:accuracy: 0.6996197718631179
更换训练模型
还可以使用随机森林分类器(random forest classifier)进行预测业务,可能会产生更好的效果。
git:这是一个分布式版本控制系统,可以让开发者对他们的项目进行有效地管理和跟踪。checkout:这是一个git命令,它的主要作用是切换到不同的分支或者版本。-b:这是checkout命令的一个参数,表示创建一个新的分支并立即切换到那个分支。"random_forest":这是新创建的分支的名字。
$ git checkout -b "random_forest"
train.py 修改,读取一份训练数据,训练一个随机森林分类器,并将训练好的模型保存下来。以下是关于每一行代码的详细解释:
from joblib import dump:导入了joblib库中的dump函数,用于序列化(保存)Python对象到硬盘。from pathlib import Path:导入了pathlib库中的Path类,用于处理文件和目录路径。import numpy as np:导入了numpy库,并用np作为别名。numpy是一个处理大型多维数组和矩阵的科学计算库。import pandas as pd:导入了pandas库,并用pd作为别名。pandas用于数据处理和分析。from skimage.io import imread_collection:导入了skimage.io库中的imread_collection函数,用于读取图片集合。from skimage.transform import resize:导入了skimage.transform库中的resize函数,用于调整图片的尺寸。from sklearn.ensemble import RandomForestClassifier:导入了sklearn.ensemble库中的RandomForestClassifier类,这是一个随机森林分类器。train_csv_path = repo_path / "data/prepared/train.csv":定义了训练数据的路径,该路径在给定的库路径下的"data/prepared/"目录。train_data, labels = load_data(train_csv_path):调用了一个名为load_data的函数(该函数在这段代码中并未定义),它加载并返回训练数据和对应的标签。rf = RandomForestClassifier():创建了一个随机森林分类器实例。trained_model = rf.fit(train_data, labels):使用训练数据和对应的标签来训练随机森林分类器。dump(trained_model, repo_path / "model/model.joblib"):使用joblib.dump函数将训练好的模型保存到指定路径的"model/model.joblib"文件中。
from joblib import dump
from pathlib import Pathimport numpy as np
import pandas as pd
from skimage.io import imread_collection
from skimage.transform import resize
from sklearn.ensemble import RandomForestClassifierdef main(path_to_repo):train_csv_path = repo_path / "data/prepared/train.csv"train_data, labels = load_data(train_csv_path)rf = RandomForestClassifier()trained_model = rf.fit(train_data, labels)dump(trained_model, repo_path / "model/model.joblib")
最后直接看一下结果吧。
$ dvc metrics show -T
sgd-pipeline:metrics/accuracy.json:accuracy: 0.7781238791545
forest:metrics/accuracy.json:accuracy: 0.8313875589354