目录
一、Flink简介
二、为什么选择Flink
三、与传统数据处理架构相比
四、Flinik批处理数据基础代码
五、Flink流处理基础代码
一、Flink简介
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数 据流进行状态计算。
二、为什么选择Flink
流数据更真实地反映了我们的生活方式
传统的数据架构是基于有限数据集的
低延迟 ➢ 高吞吐 ➢ 结果的准确性和良好的容错性
三、与传统数据处理架构相比
传统分析处理中,将数据从业务数据库复制到数仓,再进行分析和查询

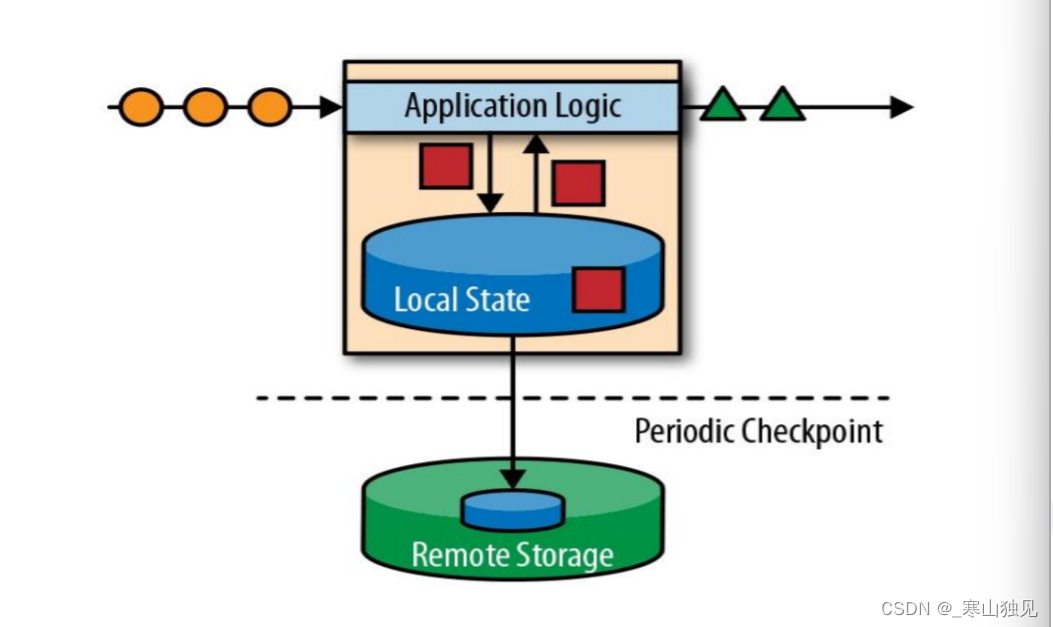
而有状态的流式处理
四、Flinik批处理数据基础代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;//批处理word count
public class WordCount {public static void main(String[] args) throws Exception{//创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//从文件里读取数据String inputPath = "D:\\java\\Flink\\src\\main\\webapp\\resource\\hello.txt";DataSource<String> inputDataSet = env.readTextFile(inputPath);//对数据集进行处理,按空格分词展开,转换成(word,1)二元组进行统计DataSet<Tuple2<String,Integer>> resultSet = inputDataSet.flatMap(new MyflatMapper()).groupBy(0) //按照第一个位置的word分组.sum(1); //将第二个位置上的数据求和resultSet.print();}//自定义类,实现FlatMapFunction接口public static class MyflatMapper implements FlatMapFunction<String, Tuple2<String,Integer>>{@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {//按空格分词String[] words = s.split(" ");//遍历所有的word,包成二元组输出for (String word: words){collector.collect(new Tuple2<>(word,1));}}}}
五、Flink流处理基础代码
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;//流处理(数据边来边处理)
public class StreamWordCount {public static void main(String[] args) throws Exception{//创建流处理执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为8env.setParallelism(8);//从文件中读取数据
// String inputPath = "D:\\java\\Flink\\src\\main\\webapp\\resource\\hello.txt";
// DataStream<String> inputDataStream = env.readTextFile(inputPath);//从KAFKA中读取流数据(监听端口号,边输入边处理)//用parameter tool工具从程序启动参数中提取配置项ParameterTool parameterTool = ParameterTool.fromArgs(args);String host = parameterTool.get("host");int port = parameterTool.getInt("port");DataStream<String> inputDataStream = env.socketTextStream(host,port);//基于数据流进行转换计算SingleOutputStreamOperator<Tuple2<String,Integer>> resultStream =inputDataStream.flatMap( new WordCount.MyflatMapper()).keyBy(0).sum(1);resultStream.print();//执行任务env.execute();}
}