1、ES调优手段
1.1、设计阶段调优
ES数据区分热、温、冷三个阶段
ES索引按月滚动生成
mapping设置合理的数据类型是否需要分词
使用别名管理索引???
1.2、数据写入优化
1> 单条写入改为多条数据写入
2> 自动生成ID
3> 索引刷盘时间,index.refresh_interval: 30s; 默认1s改为30s,减少刷盘频次
4> 设置副本数为0
5> 设置segment段大小,参数如下:
indices.memory.index_buffer_size: 20% (最大堆内存百分比)
indices.memory.min_index_buffer_size: 96mb (最小缓存大小)
6> 设置节点之间的故障检测配置,例如以下elasticsearch.yml配置:
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
1.3 查询优化
1、分片数合理评估
1>集群总分片数建议控制在5w以内,单个索引的规模控制在 1TB 以内,单个分片大小控制在30 ~ 50GB ,docs数控制在10亿内,如果超过建议滚动;
2>分片的数量通常建议小于或等于ES 的数据节点数量,最大不超过总节点数的2倍,通过增加分片数可以提升并发;
3>分片数越多长尾效应越明显,所以并不是越多越好,在搜索场景合理控制分片数也可以提升性能。
2、mapping设计
1> 合理设置index:false,store:false,doc_values:false
2> 长字段增加序列化和高亮开销,但字段长度不能高于65536(short?),超长配置: ignore_above 忽略超长的数据
3> 合理设置keyword类型,使用倒排索引
4> 合理使用fields属性,对于text字段设置子字段为keyword,支持text和keyword两种功能。
"city": {"type":"text","fields":{"raw":{"type":"keyword"}}}
"sort": {"city.raw": "asc"}
5> 字段爆炸:1) 父层级设置 enabled:false 防止子字段mapping,能被行存查出来2) dynamic=runtime 入新字段也会更新 mapping,但是新加入的字段不会被索引,dynamic=strict 不允许新增一个不在 mapping中的字段,dynamic=false (新字段不会被索引,不能作为查询条件,但是能被行存查询出来)
3、查询 Routing 路由优化?
4、查询裁剪
6、fetch性能优化1、字段设置40个,stored,docvalues,source 三种数据性能相同1) 当字段数很少时,低于 40 时,使用 doc_value Fields 拉取,性能最优。分析:如果我们只需要返回其中包含的一小部分字段时,读取并解压这个巨大的_source字段可能会开销很高。2) 当字段超较多时,达到 40 以上时,使用 _source 变为最优。分析:当我们需要非常多或者几乎全部字段时,此时使用 doc_value Fields 可能会有非常多的随机IO。这个时候,读取 _source 一个字段就能够处理全部业务字段。默认stored:false,docvalues:true,source:true设置示例:"properties" : {"_source":{"enabled":false//是否启用source}"field":{"type":"keyword","store":true,//是否存储原始值在storefields中"doc_values"true//是否存储原始值在docvalues中}"excludes":["meta.description","meta.other.*"]}2、内部结构Stored fields 在磁盘上以行的方式放置: 每个文档对应一个行,这个行包含该文档所有的stored fields。Doc values 以列的方式存储. 不同文档的相同字段被连续地存储在一起. 这种存储方式,可以直接访问一个特定的文档的特定字段。Source 与Stored fields方式差不多额外增加了_source字段存储全量json。
7、Force merge优化减少小的segment
8、ES缓存设计
9、聚合优化Metric 聚合 - 计算字段值的求和平均值,Geo-hash,采样等Bucket 聚合 - 将字段值、范围、或者其它条件分组到Bucket中Pipeline 聚合 - 从已聚合数据中进行聚合查询
10、分页查询1、from + size2、滚动翻页(Search Scroll)3、流式翻页(Search After)ES 查询优化
news/2024/12/2 14:41:05/
相关文章
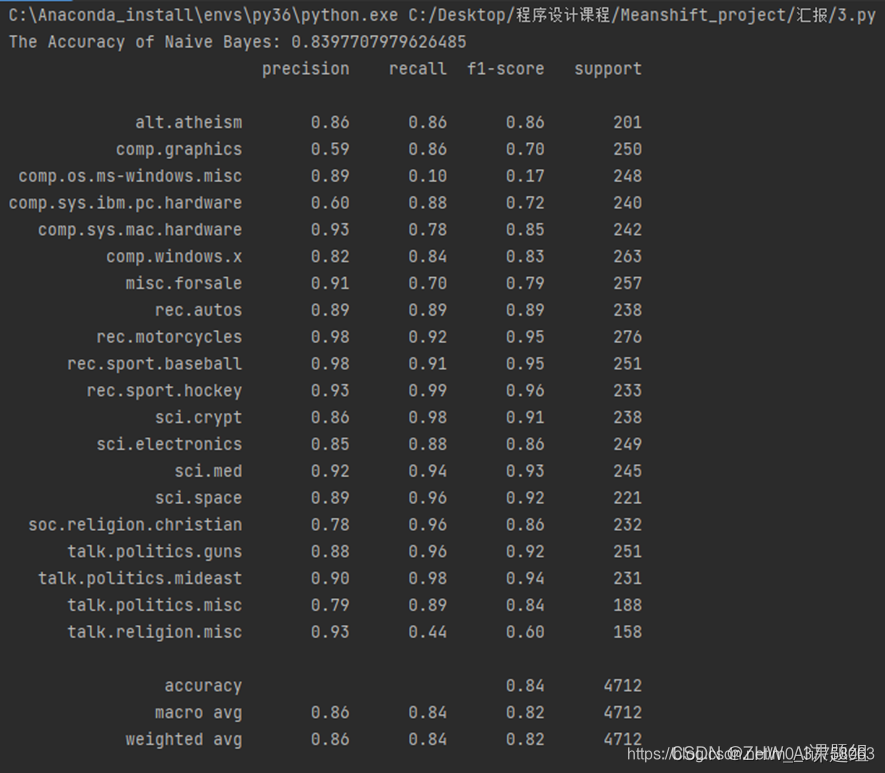
朴素贝叶斯算法实现英文文本分类
目录 1. 作者介绍2. 朴素贝叶斯算法简介及案例2.1朴素贝叶斯算法简介2.2文本分类器2.3对新闻文本进行文本分类 3. Python 代码实现3.1文本分类器3.2 新闻文本分类 参考(可供参考的链接和引用文献) 1. 作者介绍
梁有成,男,西安工程…
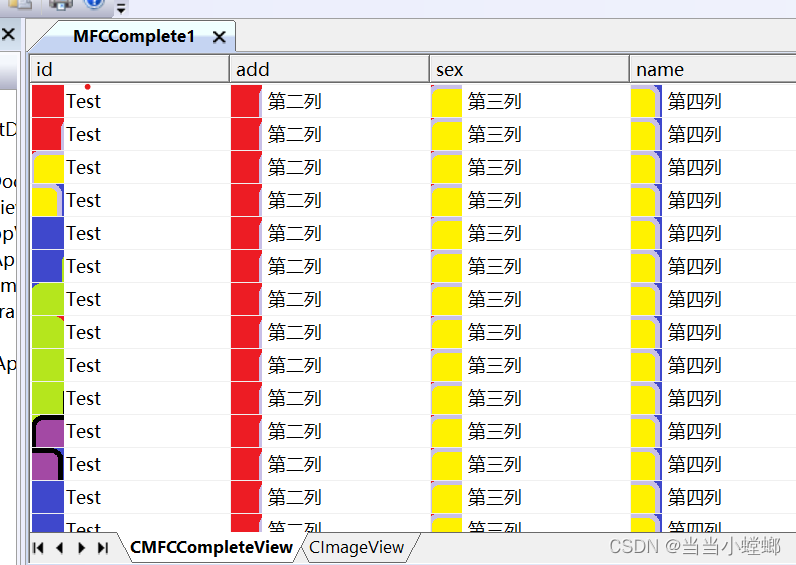
MFC CListCtrl 显示图片
MFC CListCtrl 显示图片 MFC CListCtrl 显示图片PreCreateWindow中设置风格没有起作用在OnCreate中设置CListCtrl的风格最合适在OnInitialUpdate中添加数据最合适需要设置CImageList,资源是我自己搞的一个图片资源ps:参考链接 MFC CListCtrl 显示图片
在使用MFC的C…
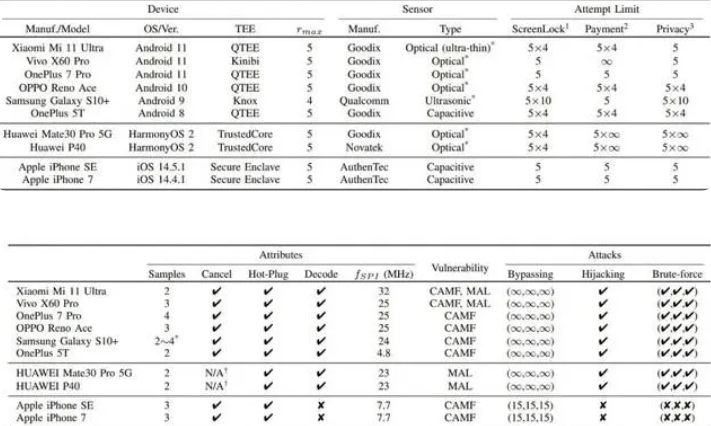
安卓、鸿蒙系统通通中招,手机指纹可被轻松破解
正文开始前问下大家,你的手机都采用了哪些解锁方式?
经过这么些年发展,目前手机的解锁方式可谓是五花八门。
从最开始的数字密码到图案密码,再到后来的面部解锁、虹膜解锁、指纹解锁等。 数字密码虽然最早出现,但放到…

揭秘数据传输中常用的加密算法及其优缺点
本文介绍了常见的数据加密算法,包括AES、RSA、DES、3DES和Blowfish。对每种算法的原理、应用场景、优点和缺点进行了详细的介绍。读者可以根据实际需求选择合适的加密算法以提高数据的安全性。
1. 高级加密标准(Advanced Encryption Standard, AES)
原理:AES是一种对称加…
ML之XGBoost:基于泰坦尼克号数据集(填充/标签编码/推理数据再处理)利用XGBoost算法(json文件的模型导出和载入推理)实现二分类预测应用案例
ML之XGBoost:基于泰坦尼克号数据集(填充/标签编码/推理数据再处理)利用XGBoost算法(json文件的模型导出和载入推理)实现二分类预测应用案例 目录
基于泰坦尼克号数据集(独热编码/标签编码)利用XGBoost算法(json文件的模型导出和载入推理)实现二分类预测应用案例
#…

数据可视化是什么?怎么做?看这篇文章就够了
数据可视化是什么
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。也就是说可视化的存在是为了帮助我们更好的去传递信息。
我们需要对我们现有的数据进行分析,得出自己的结论,明确要表达的信息和主题(即你通过…
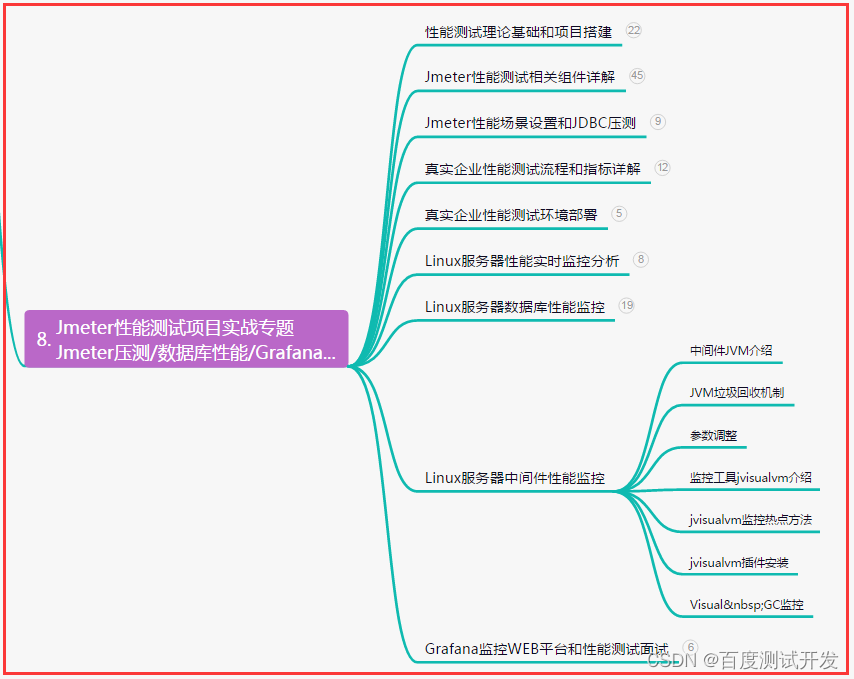
【软件测试】5年测试老鸟总结,自动化测试成功实施,你应该知道的...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言
自动化测试 Pytho…
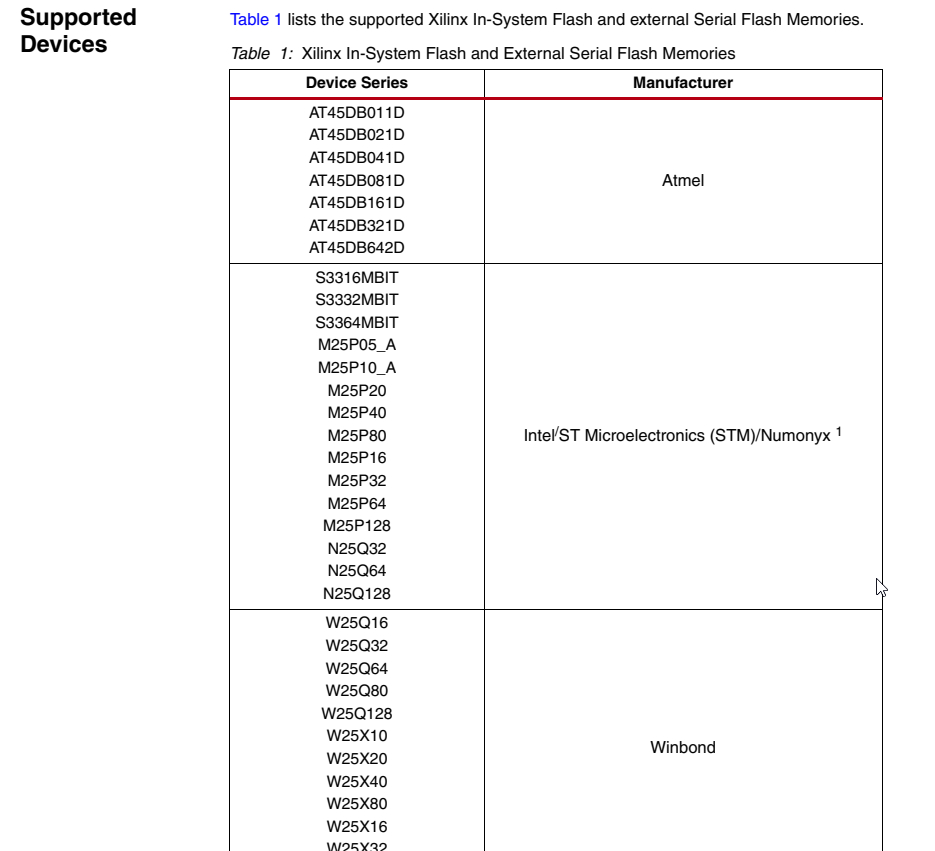
MicroBlaze系列教程(9):xilisf串行Flash驱动库的使用
文章目录 1. xilisf库简介2. xilisf库函数3. xilisf配置4. xilisf应用示例工程下载本文是Xilinx MicroBlaze系列教程的第9篇文章。 1. xilisf库简介
xilisf库(Xilinx In-system and Serial Flash Library) 是Xilinx 提供的一款串行Flash驱动库,支持常用的 Atmel 、Intel、S…