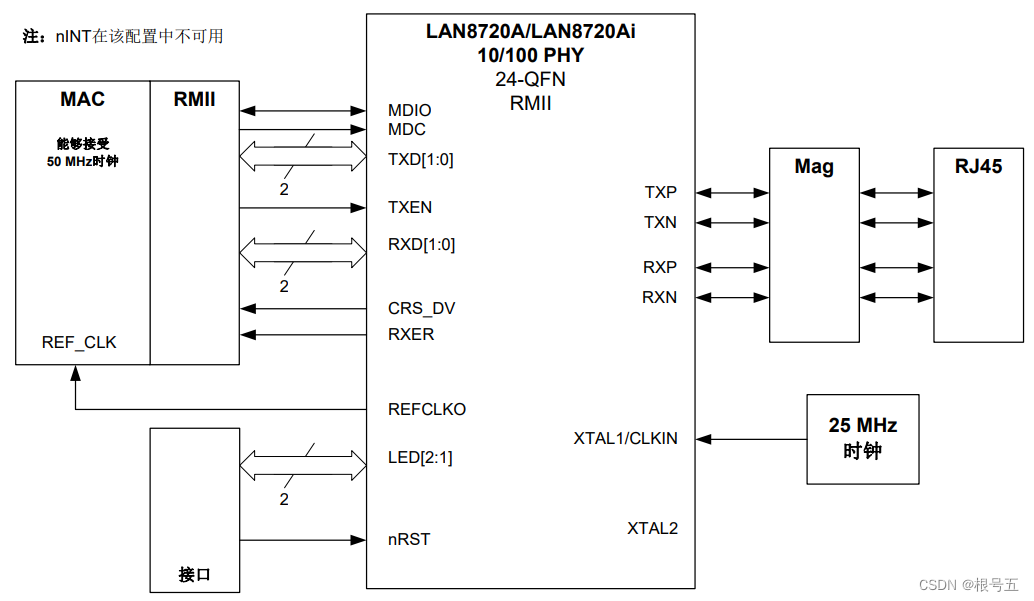
1、Unsupervised anomaly detection algorithms on real-world data: how many do we need?真实世界数据的无监督异常检测算法:我们需要多少?
Abstract:
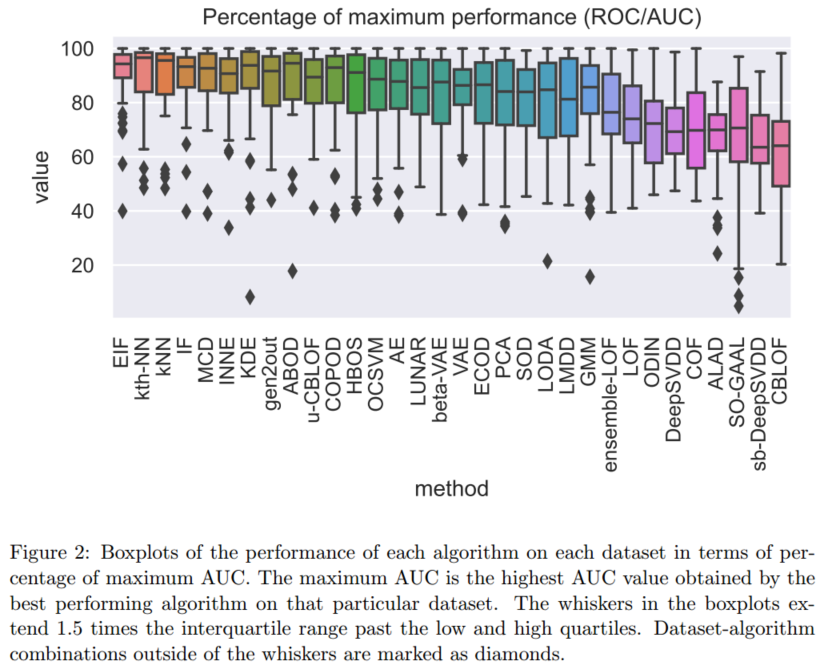
- 将所考虑的算法在所有数据集上的相对性能进行可视化和聚类,我们确定了两个明确的聚类:一个具有“局部”数据集,另一个具有“全局”数据集。
- 在局部数据集上,kNN算法名列前茅。在全局数据集上,EIF(扩展隔离林)算法的性能最好。
Introduction
所陈述的先前论文研究中发现表现较好的些算法:
- Isolation Forest 适用于检测全局异常
- ABOD (Angle-Based anomaly Detection) / LOF (Local anomaly Factor)(数据中存在多个聚类时)
- kNN 通常给出稳定的结果,推荐用于全局异常
- LOF适用于检测局部异常、依赖异常
- KDE(内核密度估计)表现还行,但一般不咋健壮,无法计算更大的数据集
- OCSVM (One-Class Support Vector Machine) 表现一般不怎么好,使用比其他算法大很多的验证集才能优化其性能
Background
- 全局异常:是可以从正常数据中分离出来的点
- 局部异常:位于密度较附近正常区域低的区域
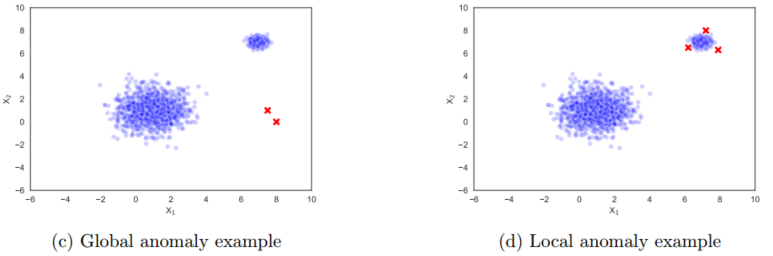
- 在许多实际情况下,异常并不是单一的,一小群异常形成集群,导致集群异常
Materials and Methods
- 为每种方法、数据集组合得出单个平均ROC-AUC分数
- 避免优化超参数

数据
- 实值、多元、表格数据
数据的处理步骤:
- 从每个数据集中删除所有重复的样本
- 所有数据集中的所有变量都被缩放和居中(中位数和四分位数范围受异常存在的影响都小于平均值和标准差。当已知存在异常时,该程序通常被认为比标准化更稳定)
- 通常评估异常分数比某些算法产生的二值标签更有用
- 异常检测评估中最常用的指标:根据ROC(接收者工作特征)曲线产生的AUC(曲线下面积)值计算每个算法-数据集组合的性能。
- 使用Iman-Davenport统计量(Iman and Davenport, 1980)来确定算法之间是否存在显著差异。(如果该统计量低于对应于p值0.05的期望临界值,我们应用Nemenyi事后检验(Nemenyi, 1963),然后评估哪些算法彼此显著不同。)
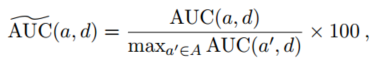 ,用a中的一个算法和d中的一个数据集
,用a中的一个算法和d中的一个数据集

Discussion
- 分类算法的数量大大超过了异常检测算法的数量
Conclusion
用户应该在什么时候应用哪种异常检测方法来解决他们的问题
- 用户对其数据集是否包含局部或全局异常没有先验知识时:k-thNN是最佳选择
- 已知数据集包含局部异常时:性能最好的方法是kNN
- 仅包含全局异常的数据集:IF(隔离森林) / EIF。此两种方法计算复杂度低、应用较好
2、Anomalous Instance Detection In Deep Learning: A Survey
根据异常对应的训练数据标签的可用性对这些技术进行分类,即监督、半监督和无监督技术。
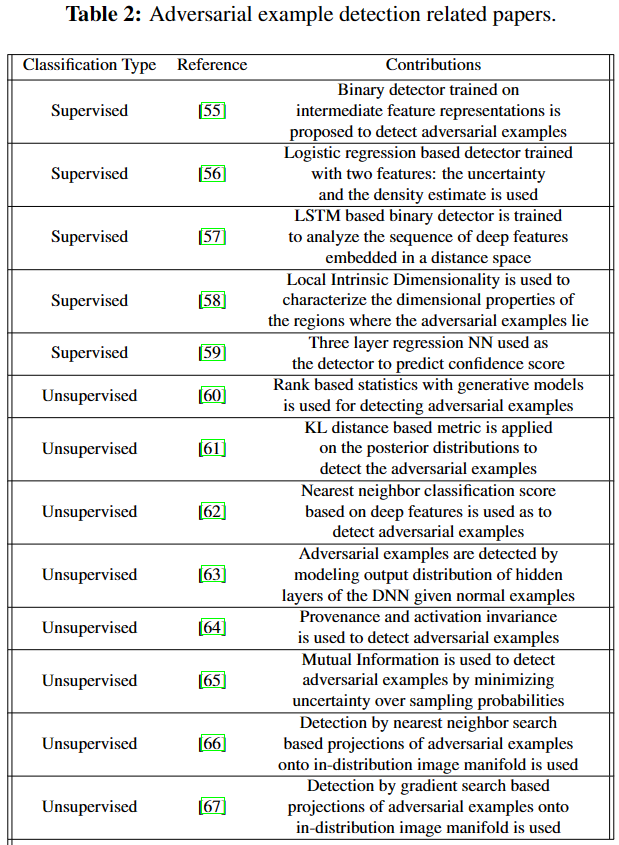
Unintentional Anomaly Detection 无意异常检测
无监督:基于GAN的架构用于比较生成图像与测试图像的瓶颈特征、
Inintentional Anomaly Detection 有意异常检测
DNN非常容易受到测试时间对抗样例的影响——人类难以察觉的扰动,当将其添加到任何图像时,都会导致其高概率被错误分类。
- 监督:从标记的训练样例中学习边界。可能会过拟合
- 无监督:灵活性、适用性。灵活性以鲁棒性未代价,对噪声和数据损坏非常敏感。不如监督、半监督准确。
- 半监督:利用标记的数据分布和未标记的数据提升无监督技术的性能,存在过拟合问题
启发式的方法是需要手动选择参数的,比如KNN。
一般来说,基于距离(KNN)和基于投影(GAN)的方法在测试阶段的计算成本很高。
Application Domains 应用领域
- Intrusion Detection 入侵检测。一个关键挑战是庞大的数据量和复杂的恶意模式,DL在此有广阔的应用前景
- Fraud Detection 欺诈检测。需准确地识别欺诈交易,实时检测。曾用到LSTM、CNN等。
- Healthcare and Industrial Domains 医疗保健和工业领域检测。要求准确性,易受到OOD和对抗性示例的影响。
- Malware Detection 恶意软件检测。监控计算机系统的活动来检测恶意软件。
- Time Series and Video Surveillance Anomaly Detection 时间序列和视频监控异常检测。基于RNN和LSTM的方法在多变量时间序列数据异常检测中表现良好。
Conclusion
- 根据异常示例标签的可用性和使用的度量类型对异常检测算法进行分类。对集成检测方法的探索可能是一个有价值的未来方向。集成方法将提供互补优势的多个检测器的输出组合成一个检测器,从而与使用单个检测器相比产生更好的性能。
- Going beyond image classification 超越图像分类,超越分类问题,探索基于深度学习的对象检测、控制和规划问题中的异常设计和检测可能是未来一个具有重要影响的研究方向。
- heoretical analysis and Fundamental Limits 理论分析和基本限制,在有种模式中,大多数基于启发式的防御(包括后检测和基于训练的)很容易被新的攻击打破。发展连贯的理论和方法来指导基于dl的系统异常检测的实际设计,以及对抗性示例存在的基本特征是至关重要的。
3 Outlier Detection with Autoencoder Ensembles
Abstract
- 引入了用于无监督异常值检测的自编码器集成。
- 基本思想是随机改变自编码器的连接架构,以获得更好的性能。与自适应采样方法(为了加快神经网络的训练过程)相结合,使方法更加高效。
- 在几个基准数据集上,将所提出的方法与目前最先进的检测器进行了比较,结果表明了方法的准确性。
Introduction
- 使用各种具有不同结构和连接密度的随机连接的自编码器代替全连接的自编码器作为基本集成组件,降低了计算复杂度
- 在集成框架内利用精心设计的自适应样本大小方法来实现提高多样性和训练时间的双重目标。
- 将自适应采样与随机模型构建相结合,以获得高质量的结果。我们将这个模型称为RandNet,即用于离群点检测的随机神经网络。
- 关于这种方法的一个显著观察是:训练过程可以很容易地并行化。
可以把神经网络看作是一个利用非线性降维对异常值进行评分的模型。
RandNet模型
- 自动编码器的目标:训练输出以尽可能接近地重建输入
- 对数据进行分层和非线性降维,体系结构是分层和对称的
- 中间层的节点数量较少,因此重建输入的唯一方法是学习权重
- 有一组完全独立(不同)的神经网络,并将结果组合在一起。
- 允许在单个网络中进行过拟合,但只在多个网络的组合中减少方差。
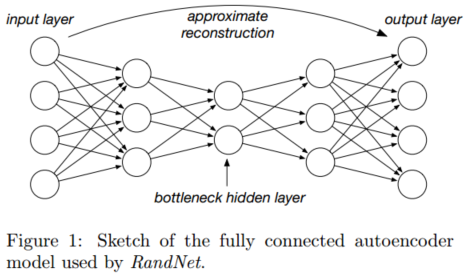
- 输入层的节点数与训练数据的维数完全相同,记为d
- 对于所有层,节点数量的最小限制是3(为了避免中间层的过度压缩,从而无法正确地重构数据)
集成学习方法 Ensemble learning methods
- 是将来自不同基础检测器的预测结合起来以产生更稳健结果的算法
- 基本思想是:根据数据的选择或基本模型的设计,预测算法通常在分数上有一个自然的方差。
- 使集成学习方法起作用:单个集成组件必须充分多样化(通过创建预测模型来实现,让每个集成组件都能够捕获底层模式的不同部分)
本文所提方法
将集成学习方法与自编码器结合使用,以获得更高的精度。
Cites:
- Bouman, Roel et al. “Unsupervised anomaly detection algorithms on real-world data: how many do we need?” (2023).
- Bulusu, Saikiran et al. “Anomalous Instance Detection in Deep Learning: A Survey.” ArXiv abs/2003.06979 (2020): n. pag.
- Chen, Jinghui et al. “Outlier Detection with Autoencoder Ensembles.” SDM (2017).