RabbitMQ
- 1. MQ介绍
- 1.1 什么是MQ?为什么要用MQ?
- 1.2 MQ的优缺点
- 1.3 几大MQ产品特点比较
- 2. Rabbitmq安装
- 2.1 实验环境
- 2.2 版本选择
- 2.3 安装Erlang语言包
- 2.4 安装RabbitMQ:
- 3. RabbitMQ集群搭建
- 3.1 搭建普通集群
- 3.2 搭建镜像集群
- 3.3 RabbitMQ基础使用
本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
课程内容:
1. MQ介绍
1.1 什么是MQ?为什么要用MQ?
MQ: MessageQueue,消息队列。队列,是一种FIFO先进先出的数据结构。消息由生产者发送到MQ进行排队,然后按原来的顺序交由消息的消费者进行处理。QQ和微信就是典型的MQ。
MQ的作用主要有以下三个方面:
- 异步
例子︰快递员发快递,直接到客户家效率会很低。引入菜鸟驿站后,快递员只需要把快递放到菜鸟驿站,就可以继续发其他快递去了。客户再按自己的时间安排去菜鸟驿站取快递。
作用:异步能提高系统的响应速度、吞吐量。 - 解耦
例子:《Thinking in JAVA》很经典,但是都是英文,我们看不懂,所以需要编辑社,将文章翻译成其他语言,这样就可以完成英语与其他语言的交流。
作用:
1、服务之间进行解耦,才可以减少服务之间的影响。提高系统整体的稳定性以及可扩展性。
2、另外,解耦后可以实现数据分发。生产者发送一个消息后,可以由一个或者多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
- 削峰
例子:长江每年都会涨水,但是下游出水口的速度是基本稳定的,所以会涨水。引入三峡大坝后,可以把水储存起来,下游慢慢排水。
作用:以稳定的系统资源应对突发的流量冲击。
1.2 MQ的优缺点
上面MQ的所用也就是使用MQ的优点。但是引入MQ也是有他的缺点的:
-
系统可用性降低
系统引入的外部依赖增多,系统的稳定性就会变差。一旦MQ宕机,对业务会产生影响。这就需要考虑如何保证MQ的高可用。 -
系统复杂度提高
引入MQ后系统的复杂度会大大提高。以前服务之间可以进行同步的服务调用,引入MQ后,会变为异步调用,数据的链路就会变得更复杂并且还会带来其他一些问题。比如:如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问题。 -
消息一致性问题
A系统处理完业务,通过MQ发送消息给B、C系统进行后续的业务处理。如果B系统处理成功,C系统处理失败怎么办?这就需要考虑如何保证消息数据处理的一致性。
1.3 几大MQ产品特点比较
常用的MQ产品包括Kafka、RabbitMQ和RocketMQ。我们对这三个产品做下简单的比较,重点需要理解他们的适用场景。
| 优点 | 缺点 | 使用场景 | |
|---|---|---|---|
| kafka | 吞吐量非常大,性能非常好,集群高可用。 | 会丢数据功能比较单 | 日志分析,大数据采集 |
| Rabbit | 消息可靠性高,功能全面。 | 吞吐量比较低,消息积累会影响性能,erlang语言不好定制。 | 小规模场景 |
| Rocket MQ | 高吞吐,高性能,高可用,功能全面。 | 开源版功能不如云上版,官方文档比较简单,客户端只支持java。 | 几乎全场景 |
另外,关于这三大产品更详细的比较,可以参见《kafka vs rabbitmq vs rocketmq.pdf》
关于RabbitMQ的功能特性,可以在官网( https://www.rabbitmq.com/)上看到,包含Asynchronous Message(异步消息)、DeveloperExperience(开发体验)、Distributed Deployment(分布式部署)、Enterprise & Cloud Ready(企业云部署)、Tools & Plugins(工具和插件)、Management & Monitoring(管理和监控)六大部分。所以其中的功能是相当丰富的,而我们肯定只能关注重点的部分内容,所以还是要经常到官网上去看看的。
2. Rabbitmq安装
2.1 实验环境
准备了三台虚拟机192.168.232.128~130,预备搭建三台机器的集群。
三台机器均预装CentOS7操作系统。分别配置机器名worker1,worker2,worker3。然后需要关闭防火墙(或者找到RabbitMQ的业务端口全部打开。5672(amqp端口);15672(http Api口);25672(集群通信端口))。
2.2 版本选择
RabbitMQ版本,通常与他的大的功能是有关系的。3.8.x版本主要是围绕Quorum Queue功能,而3.9.x版本主要是围绕Streams功能。目前还有3.10.x版本,还在rc阶段。我们这次选择3.9.15版本。
RabbitMQ是基于Erlang语言开发,所以安装前需要安装Erlang语言环境。需要注意下的是RabbitMQ与ErLang是有版本对应关系的3.9.15版本的RabbitMQ只支持23.2以上到24.3版本的Erlang。
Docker hub上也已经有官方上传的镜像
2.3 安装Erlang语言包
这个语言包,在windows下的安装比较简单,是一个可执行程序,直接图形化安装就行了。
Linux上的安装稍微复杂,需要有非常多的依赖包。简单起见,可以下载rabbitmq提供的zero dependency版本。下载地址https://github.com/rabbitmq/erlang-rpm/releases/tag/v23.2.7下载完成后,可以尝试使用下面的指令安装
rpm -ivh erlang-23.2.7-1.el7.x86_64.rpm

这样Erlang语言包就安装完成了。安装完后可以使用erl -version指令检测下erlang是否安装成功。
erl -version

2.4 安装RabbitMQ:
RabbitMQ的安装方式有很多,我们采用RPM安装包的方式。安装包可以到github仓库中下载发布包。下载地址: https://github.com/rabbitmq/rabbitmq-server/releases/tag/v3.9.15
然后使用rpm -Uvh 指令安装RabbitMQ的rpm断包时,会报错,需要安装一个socat。
而这个socat我也在网上下载到了rpm安装包。
socat-1.7.3.2-1.1.el7.x86_64.rpm,但是安装时,却提示需要tcp_wrappers依赖。
rpm -ivh socat-1.7.3.2-1.1.el7.x86_64.rpm
这时,当然可以按他的提示去安装依赖包。但是我就没有这么做了。直接用yum安装这个socat依赖。在使用yum时,可以做一个小配置,将yum源配置成阿里的yum源,这样速度会比较快。
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum makecache
然后安装socat
yum install socat
socat安装完成后,就可以安装RabbitMQ了。
rpm -Uvh rabbitmq-server-3.9.15-1.el7.noarch.rpm

安装完成后,可以查看下他的安装情况
whereis rabbitmqctl

启动RabbitMQ服务
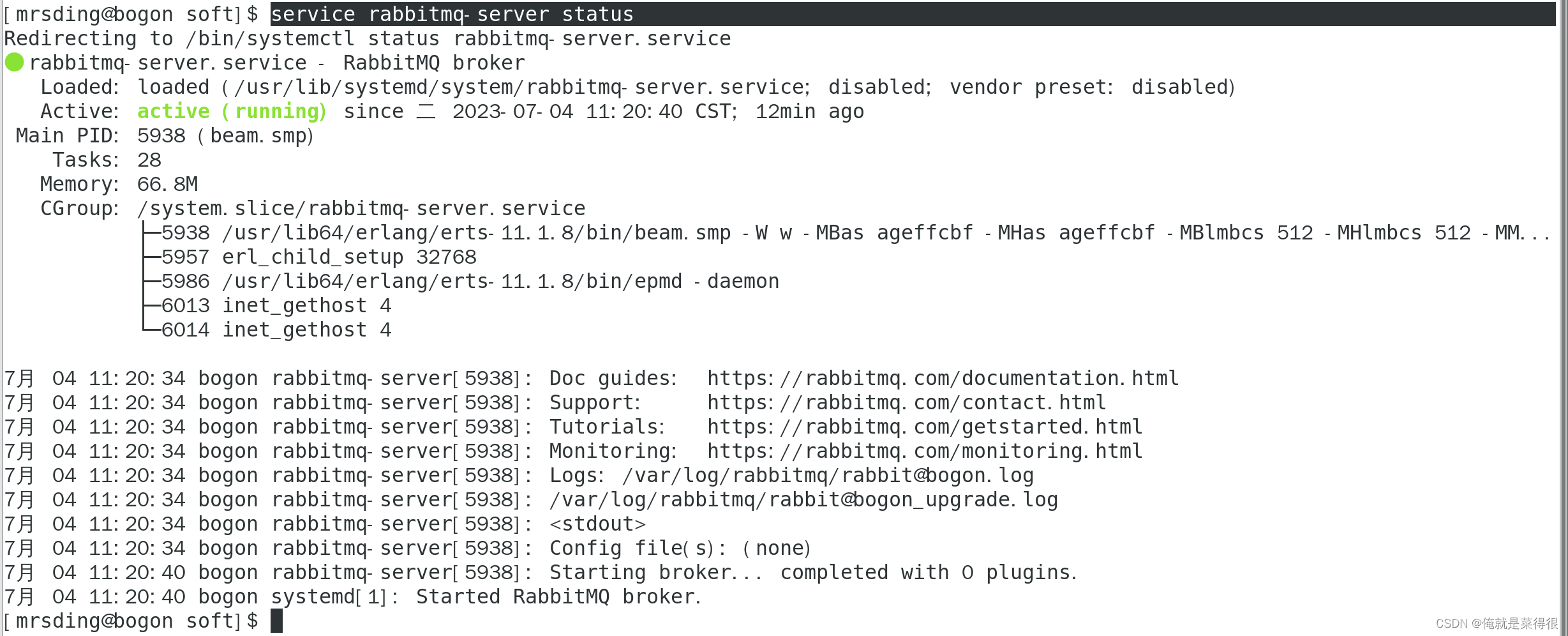
service rabbitmq-server start

查看服务启动状态
service rabbitmq-server status
其他常用的启停操作:
rabbitmq-server -deched --后台启动服务
rabbitmqctl start_app --启动服务
rabbitmqctl stop_app --关闭服务
这样RabbitMQ服务就启动完成了。之后可以配置下打开他的Web管理页面:
rabbitmq-plugins enable rabbitmq_management
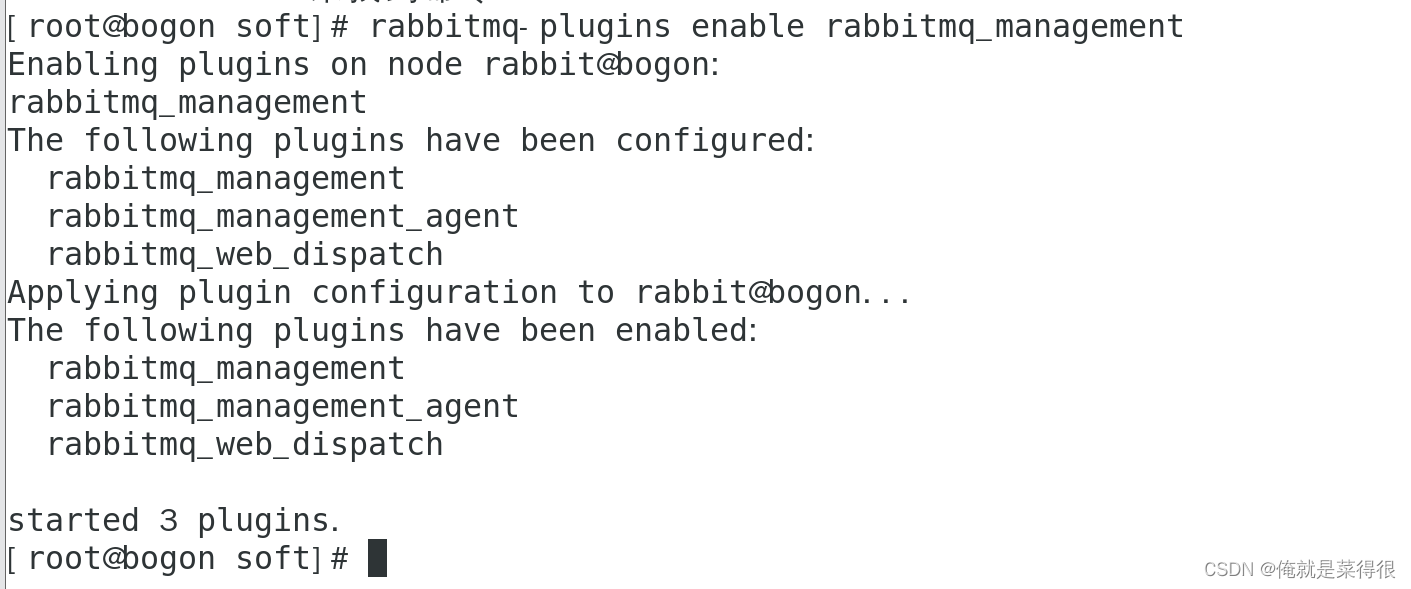
可以看到,这时需要重启RabbitMQ服务才能生效。重启后,就可以访问Web控制台了。访问端口http://localhost:15672。
这时,可以使用默认的guest/guest用户登录。但是注意下,默认情况下,只允许在localhost本地登录,远程访问是无法登录的。这时,可以创建一个管理员账户来登录。
rabbitmqctl add_user admin admin
rabbitmqctl set_permissions -p / admin "." "." "."
rabbitmqctl set_user_tags admin administrator

这样就可以用admin/admin用户登录Web控制台了。
3. RabbitMQ集群搭建
在RabbitMQ中,一个节点的服务其实也是作为一个集群来处理的,在web控制台的admin-> cluster中可以看到集群的名字,并且可以在页面上修改。而多节点的集群有两种方式
- 默认的普通集群模式:
这种模式使用Erlang语言天生具备的集群方式搭建。这种集群模式下,集群的各个节点之间只会有相同的元数据,即队列结构,而消息不会进行冗余,只存在一个节点中。消费时,如果消费的不是存有数据的节点,RabbitMQ会临时在节点之间进行数据传输,将消息从存有数据的节点传输到消费的节点。
很显然,这种集群模式的消息可靠性不是很高。因为如果其中有个节点服务宕机了,那这个节点上的数据就无法消费了,需要等到这个节点服务恢复后才能消费,而这时,消费者端已经消费过的消息就有可能给不了服务端正确应答,服务起来后,就会再次消费这些消息,造成这部分消息重复消费。另外,如果消息没有做持久化,重启就消息就会丢失。
并且,这种集群模式也不支持高可用,即当某一个节点服务挂了后,需要手动重启服务,才能保证这一部分消息能正常消费。所以这种集群模式只适合一些对消息安全性不是很高的场景。而在使用这种模式时,消费者应该尽量的连接上每一个节点,减少消息在集群中的传输。
需要数据的时候还要临时去别的节点拉取数据 - 镜像模式:
这种模式是在普通集群模式基础上的一种增强方案,这也就是RabbitMQ的官方HA高可用方案。需要在搭建了普通集群之后再补充搭建。其本质区别在于,这种模式会在镜像节点中间主动进行消息同步,而不是在客户端拉取消息时临时同步。
并且在集群内部有一个算法会选举产生master和slave,当一个master挂了后,也会自动选出一个来。从而给整个集群提供高可用能力。
这种模式的消息可靠性更高,因为每个节点上都存着全量的消息。而他的弊端也是明显的,集群内部的网络带宽会被这种同步通讯大量的消耗,进而降低整个集群的性能。这种模式下,队列数量最好不要过多。
3.1 搭建普通集群
1∶需要同步集群节点中的cookie。
默认会在/ar/lib/rabbitmq/目录下生成一个.erlang.cookiq。里面有一个字符串。我们要做的就是保证集群中三个节点的这个cookie字符串一致。
我们实验中将worker1和worker3加入到worker2的RabbitMQ集群中,所以将worker2的.erlang.cookie文件分发到worker1和worker3。