会使用多种数据增强提高模型的泛化性。在输入分辨率大的task(如医疗诊断辅助)上,消耗的时间更大。为了提高augment的效率,故使用Kornia进行数据增强。
效果
效果还是比较好的,下面是其他人做的对比实验:
https://blog.csdn.net/OTZ_2333/article/details/118655925
我使用数据集测试了一下提速前后遍历数据集的耗时。测试方法就是将正常训练model的代码去掉前向传播、计算loss、反向传播等操作,只保留数据的加载、预处理、转移到GPU的操作。是用的数据集中总共有1万张图片。
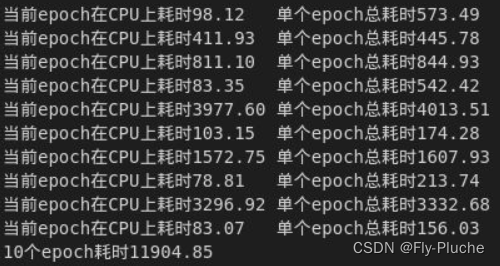
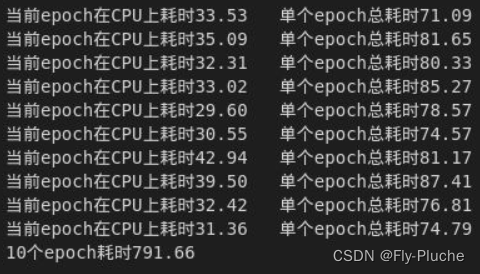
原始的dataload在10epoch下总耗时11904s(下图一),加速后的dataload在10epoch下耗时791s(下图二)。此外,可以看到原始的dataload各个epcoh的耗时很不稳定,短的能有150s,长的能有4000s;而加速后的dataload耗时基本上都在80s左右。
图一:
图二:
Code
先定义一个transformer类
import torch
import kornia.augmentation as K
class DataAugmentation(torch.nn.Module):def __init__(self,):super().__init__()self.flip = torch.nn.Sequential(K.RandomHorizontalFlip(p=0.5),K.RandomVerticalFlip(p=0.5),)p=0.8self.transform_geometry = K.ImageSequential(K.RandomAffine(degrees=20, translate=0.1, scale=[0.8,1.2], shear=20, p=p),K.RandomThinPlateSpline(scale=0.25, p=p),random_apply=1, #choose 1)p=0.5self.transform_intensity = K.ImageSequential(K.RandomGamma(gamma=(0.5, 1.5), gain=(0.5, 1.2), p=p),K.RandomContrast(contrast=(0.8,1.2), p=p),K.RandomBrightness(brightness=(0.8,1.2), p=p),random_apply=1, #choose 1)# p=0.5# self.transform_other = K.ImageSequential(# K.MyRoll(p=0.1), #Mosaic Augmentation using only one image, implemented by using pytorch roll , i.e. cyclic shift# K.MyCutOut(num_block=5, block_size=[0.1, 0.2], fill='constant', p=0.1),# random_apply=1, #choose 1# )@torch.no_grad() # disable gradients for effiencydef forward(self, x):x = self.flip(x) # BxCxHxWx = self.transform_geometry(x)x = self.transform_intensity(x)# x = self.transform_other(x)return xif __name__=="__main__":input = torch.rand(4,3,255,255)dataaugmentation = DataAugmentation()input = dataaugmentation(input)print(input.shape)
在训练的时候调用
if config.KORNIA:kornia_aug = DataAugmentation()
for batch_idx, data in enumerate(train_progress):X, y_cancer = data[0].to(DEVICE),data[1]optim.zero_grad()# Using mixed precision trainingwith autocast():if config.KORNIA:X = kornia_aug(X)y_cancer_pred, aux_loss = model.forward(X)loss.backward()optim.step()scheduler.step()
注意点
- @torch.no_grad()
用于在数据增强时禁用梯度以提高效率 - 加速失败,使用kornia之后反而变慢了
要先将输入加载到cuda上,再进行数据增强 - tensor.cuda的精度冲突
先用with autocast(),再进行数据增强 - 注意要归一化!!!
- 可以自己写一些相关数据增强的方式,如我注释掉的K.MyRoll,K.MyCutOut,但是我还不是很懂要咋写,求大佬教
- 因为kornia的这种方式输入是B,C,H,W四维的tensor,所以放在__getitem__多半是不行的
- 显存开销比较大,有点难蚌┭┮﹏┭┮