使用Python3爬取沪深300指数列表
1. 思路分析
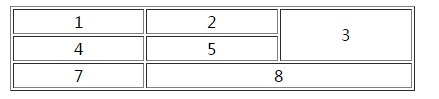
用chrome打开维基百科沪深300的页面,网址为:https://en.wikipedia.org/wiki/CSI_300_Index 。如下图一所示,可见沪深300指数股票列表。其中,包含了股票代号、公司名,交易所名称,权重和所属行业。这个列表所包含的信息就是我们所需要的。我们在向浏览器发送请求的时候,返回的是html代码,平时用浏览器浏览网页看到的这些图文并茂的规整的页面其实是html代码在经过浏览器渲染后的结果。所以,我们需要找到我们所需要抓取的信息在html代码中的位置,这个就是html解析了。解析的工具很多,作为资深小白,这里笔者选用正则表达式直接分析抓取信息。之所以没有使用成熟的Beautifulsoup4,Xpath等解析包,更多的是作为小白,从正则表达式入手更能体现抓取过程和抓取原理。这里,之后不妨大家试一试使用成熟解析包BS4之类的尝试一下。

图1 沪深300指数列表
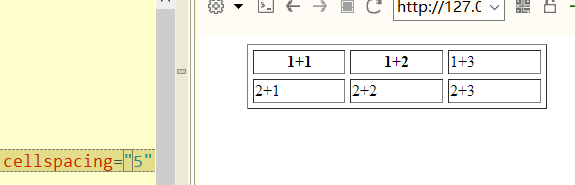
如何找到html中需要抓取的信息呢?可以在页面右键,打开网页源代码(Ctrl+U),可以查看到列表中的信息定位如下:

图2 列表信息定位
一个网页的html代码全部打开看上去会非常的繁多,其实html代码是一层一层结构化的,非常规整的。每一对尖括号包起来的是一个标签,比如这里的<tr>…</tr>表示一行,<td>…</td>表示一个空格。
2. 代码实现
(1)首先定义网址url,确定好要爬取的入口链接。
(2)然后获取浏览器信息,设置header信息等模拟浏览器进行访问(这一步可省略,此处没有屏蔽)。
(3)用urllib发送请求,爬取整个网页源代码。
(4)根据要爬取的信息构建正则表达式,如爬取股票代号列表,则采用'<td>(\d{6})'的正则表达式。
(5)采用构建的正则表达式提取相应的信息。
(6)存储爬取到的信息。
完整代码如下:
import pandas as pd
import re
import urllib.request
import tushare as ts
import osindex_list=[]
index_list1=[]
company_list=[]
stock_exchange_list=[]
weighting_list=[]
segment_list=[]url = "https://en.wikipedia.org/wiki/CSI_300_Index"headers = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]urllib.request.install_opener(opener)
file=urllib.request.urlopen(url)
data=str(file.read())pat='<table class="wikitable sortable">(.*)<h2><span class="mw-headline" id="Sub-Indicies">Sub-Indicies</span><span class="mw-editsection">'#<\/todday><\/table>'
data1= str(re.compile(pat).findall(data))
csi_1='<tbody><tr>(.*)<\/td><\/tr><\/tbody><\/table>'
csi = str(re.findall(csi_1,data1,re.S))hang = '<tr>(.*?)<\/td><\/tr>|<\/td><\/tr><\/tbody><\/table>'
zhenghang = re.findall(hang,csi)for i in range(len(zhenghang)):index_1='<td>(\d{6})'company_1='<td><a href="/.*?" title=".*?">((\w|\s|&|(|)|-){1,100})</a>'stock_exchange_1='<td>(Shanghai|Shenzhen)'weighting_1='<td>(\d,\d{1,2})'segment_1='<td>(Financials|Consumer Staples|Consumer Discretionary|Utilities|Industrials|Health Care|IT|Energy|Materials|Telecommunication Services)'index_list.extend(re.findall(index_1,zhenghang[i]))company_list.extend(re.findall(company_1,zhenghang[i]))stock_exchange_list.extend(re.findall(stock_exchange_1,zhenghang[i]))weighting_list.extend(re.findall(weighting_1,zhenghang[i]))segment_list.extend(re.findall(segment_1,zhenghang[i]))test =pd.DataFrame(columns=name,data=index_list)
#存储
test.to_csv('H:/day/index1.csv')
3.爬取结果


![[Java面试三]JavaWeb基础知识总结.](/images/no-images.jpg)