这篇文章笼统地介绍一下失焦模糊、运动模糊、低照图像恢复、hdr、超级夜景等提高图像质量的技术。
图像拍摄的2个重要参数:光圈大小及曝光时间
光圈大小:控制光线穿过孔的大小
曝光时间(又称快门速度):控制光线投射到传感器上的时间
对某个场景进行拍摄,外部光线是固定的,要得到合适的曝光,需要将两个参数调节结合。光圈控制了景深,太近太远都会模糊,大光圈会导致景深变浅,远处(景深外)模糊,即失焦模糊(可以这么理解,但不一定正确,人看远处会眯眼看,睁大眼睛看不清)。长的曝光时间内,手抖或者物体移动会引入运动模糊。

对上图牛顿摆进行拍摄,根据能量守恒定律,右侧球撞击,最左侧球弹出,循环往复。左图小光圈(f/22)大曝光时间(0.33sec),导致运动模糊 。右图大光圈小曝光时间,导致背景失焦模糊。ISO 代表感光度,此场景固定。
两种模糊
失焦模糊 defocus blur
运动模糊 motion blur
失焦模糊检测
Rethinking the Defocus Blur Detection Problem and A Real-Time Deep DBD Model
上海交通大学

通过swap操作实现了数据放大及自监督(自监督损失见Lself),在训练过程中可避免语义的干扰。
并将模糊检测与显著性检测任务相结合,有2种模糊是较难检测的:'salient but out-of-focus', 'in-focus but not salient'。对这些区域分配更大的权重,做难样本挖掘。

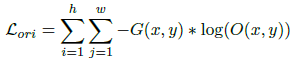
加权后: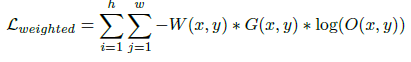
------
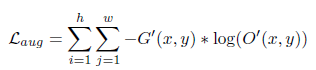
加权后:
---------
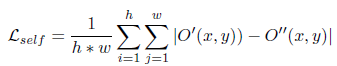
损失实质有3个,见上上图。对其中2个损失加了权重做难样本挖掘。
去失焦模糊
Defocus Deblurring Using Dual-Pixel Data
Dp相机的初衷是为了利用左右像素的差异自动对焦。输入图像I显示空间变化的离焦模糊。成像时采集与I相对应的两幅双像素(DP)图像L和R。从L和R DP图像斑块的互相关可以看出,在焦点内和焦点外的斑块表现出不同的像素视差量。这些信息有助于DNN了解图像不同区域的模糊程度。
不在整幅图像上训练,而是在patch上训练。The size of input and output layers is set to 512×512×6 and 512 × 512 × 3, respectively. This is because we train not on the full-size images but on the extracted image patches.
双像素相机提供了500个场景共2000张图像的成对数据集,每个场景包括:
(i) 失焦图像(ii) 2个DP 子图(iii)聚焦图像



Deblurring by Realistic Blurring——腾讯

learning-to-Blur GAN (BGAN)
learning-to-DeBlur GAN (DBGAN)
noise map的获取方式:用4维的正态分布的噪声重复128*128次模拟
To obtain the noise map, we sample a noise vector of length 4 from a normal distribution and duplicate it 128 × 128 times in the spatial dimension to obtain a 4 × 128 × 128 noise map as in [46]. In this way, we can generate various blurry images based on one sharp image.
Relativistic Blur Loss (RBL):为了充分训练BGAN-G,使得G生成的图真假难辨
Real and synthesized images are labeled as 1 and 0, respectively. (a) A traditional loss function is used to update the generator to create blurry images (label=0) which are similar to real ones (label=1). (b) The RBL not only increases the probability that generated images look real (0 ! 0.5, which is labeled as “Push”), but also simultaneously decreases the output probability that real images are real (1 ! 0.5, which is labeled as “Pull”).

CycleGAN With a Blur Kernel for Deconvolution Microscopy:Optimal Transport Geometry
研究特定场景下的deblur问题:当前应用场景为显微镜成像,模糊核h是已知的,也就是blur-gan是已知的。

去运动模糊
DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks
https://blog.csdn.net/PPLLO_o/article/details/91403642
随机生成轨迹,轨迹的下一个点的位置是基于先前的点速度和位置,模拟更逼真和复杂的模糊内核,生成成对数据集。比如一个五维的对角矩阵,可以模拟45度角的运动模糊。
提出了一种基于随机轨迹的方法,用于从一组清晰图像以自动方式生成用于运动去模糊训练的数据集。它可以模拟更逼真和复杂的模糊内核。我们遵循Boracchi和Foi [4]描述的随机轨迹生成的想法。然后通过将子像素内插应用于轨迹矢量来生成内核。每个轨迹矢量是复值矢量,其对应于在连续域中跟随2D随机运动的对象的离散位置。轨迹生成是通过马尔可夫过程完成的,总结在算法1中。轨迹的下一个点的位置是基于先前的点速度和位置,高斯扰动,脉冲扰动和确定性惯性分量随机生成的。
用于运动去模糊的条件GAN。生成器网络将模糊图像作为输入并产生清晰图像的估计。在训练期间,判别网络将恢复的和清晰的图像作为输入并估计它们之间的距离。根据清晰和恢复图像的特征图之间VGG-19 [30]的激活差异,总损失包括来判别器的WGAN损失和感知损失[15]。在测试时,只保留生成器。

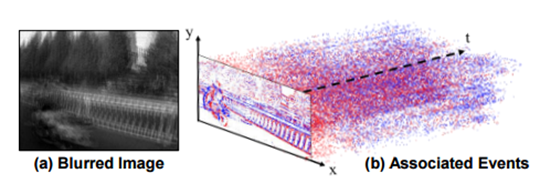
Learning Event-Based Motion Deblurring——商汤
通过一张图片和对应的事件相机数据,对图像中的场景进行光流估计。
event相机:能够敏感捕捉运动的物体,当某个像素所处位置的亮度值发生变化时,回传一个信息(也称为事件)

低照图像恢复
Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement
——天津大学、香港城市大学、南洋理工、北京交通
对每个像素点进行高阶映射,这个高阶映射需要满足以下3个要求:
1、增强图像的像素值归一化为[0,1],值域也为[0,1],避免了由于溢出截断而导致的信息丢失;
2、曲线单调,保留相邻像素间的大小关系;
3、曲线简单,在反向传播过程中可导。
根据以上三个要求,作者提出了以下方程式:
![]()
为提高曲线的表达能力,将以上公式迭代八次(式中n值为1~8)。
![]()
利用 CNN 估计图像中每个像素的高阶映射方程,进行像素点变换。作者设计了几个和颜色对比度等有关的loss,无需成对数据集。
https://blog.csdn.net/qq_36560894/article/details/108024748

hdr
高动态范围图像(high dynamic range,HDR)
动态范围指的是相机拍摄的照片从最暗到最亮的这个范围,动态范围大,就能够展示更丰富的层次,包含更广的色彩空间,能够记录下更多的亮部和暗部细节。
HDR技术拍摄的时候分别拍摄多张不同曝光的照片,然后将多张照片合成在一起,各自提取表现效果出色的部分来合成,将多张不同曝光值的帧融合,输出一张动态范围更大,细节更丰富的图像,能够更好的反应真实环境中的视觉效果。

超级夜景
可以理解为时间更长的hdr,超级夜景模式难点在于长时间曝光中补偿矫正抖动。
通过软件算法,可以挑选不同张片中拍的最好的细节,让照片无论亮部还是暗部的细节都处理的恰到好处。

华为默认拍照、HDR、超级夜景对比
超级夜景出片慢,手特别陡或运动物体很容易糊片。高光压制比HDR 好一些(见灯牌),超级夜景适用静态夜景,动态夜景不行。
HDR出片快,不容易糊片,整体亮度更高,很适合拍摄动态夜景,高光压制逊于超级夜景,好于默认拍照。

图像增强的其他方向
去摩尔纹
Image Demoireing with Learnable Bandpass Filters——华为

摩尔纹:感光元件出现的高频干扰,使图片出现彩色的高频率不规则的条纹。在拍摄屏幕、高密度条纹布料时会出现。
对于纹理恢复子问题,提出了一个可学习的带通滤波器(LBF),以了解去除摩尔纹之前的频率。对于颜色恢复子问题,提出了两步色调映射策略,该策略首先应用全局色调映射来校正全局色彩shift,然后对每个像素执行颜色的局部微调。
去云、去雨、去雾
视频去模糊
去噪点
人脸图像恢复
图像增强的常见思路
基于设备——利用深度摄像头、事件相机、dp相机、hdr等提供的额外信息
基于数据——建立成对数据集,训练cnn网络
基于GAN——无需成对数据集,设计特殊的损失函数
基于理解——根据场景,建立数学模型