自然语言处理(NLP)是研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,也是人工智能领域中一个最重要、最艰难的方向。说其重要,因为它的理论与实践与探索人类自身的思维、认知、意识等精神机制密切相关:说其艰难,因为每一项大的突 破都历经十年乃至几十年以上,要耗费几代人的心血。
近些年,NLP在中文分词、词性标注、词汇语义、句法解析方面均获得了很大的突破。大量的技术都应用于商业实践,并在商业领域获得了良好的市场和经济效益。文本方面主要有基于自然语言理解的智能搜索引擎和智能检索、智能机器翻译、自动摘要与文本综合、文本分类与文件整理、自动阅卷系统、信息过滤与垃圾邮件处理、文学研究与古文研究、语法校对、文本数据挖掘与智能决策、基于自然语言的计算机程序设计等。语音方面主要有机器同声传译、智能客户服务、聊天机器人、语音挖掘与多媒体挖掘、多媒体信息提取与文本转化等。
文章目录
- 文本分词
- 词干提取
- 词性还原
- 词袋模型
- 词频统计
- 情感分析
- jieba中文分词
- 对《我的大明新帝国》这本电子书进行词频统计
- snownlp库
安装NLTK库
pip install NLTK
安装语料库
NLTK语料库
这个链接有效期是永久的,你们直接下载nltk_data文件夹,我是直接放在D盘下的
下面这个链接是需要的两个txt文件。
后面代码要用的停止词和一本小说txt文件
文本分词
import nltk.tokenize as tk
doc = "Are you curious about tokenization? " \"Let's see how it works! " \"We need to analyze a couple of sentences " \"with punctuations to see it in action."
tokens = tk.sent_tokenize(doc) # 句子分词
for i, token in enumerate(tokens):print("%2d" % (i + 1), token)

import nltk.tokenize as tk
doc = "Are you curious about tokenization? " \"Let's see how it works! " \"We need to analyze a couple of sentences " \"with punctuations to see it in action."
tokens = tk.word_tokenize(doc) # 单词分词
for i, token in enumerate(tokens):print("%2d" % (i + 1), token)
1 Are2 you3 curious4 about5 tokenization6 ?7 Let8 's9 see
10 how
11 it
12 works
13 !
14 We
15 need
16 to
17 analyze
18 a
19 couple
20 of
21 sentences
22 with
23 punctuations
24 to
25 see
26 it
27 in
28 action
29 .
词干提取
import nltk.stem.porter as pt
import nltk.stem.lancaster as lc
import nltk.stem.snowball as sbwords = ['table', 'probably', 'wolves', 'playing', 'is','dog', 'the', 'beaches', 'grounded', 'dreamt', 'envision']
pt_stemmer = pt.PorterStemmer() # 波特词干提取器,偏宽松
lc_stemmer = lc.LancasterStemmer() # 朗卡斯特词干提取器,偏严格
sb_stemmer = sb.SnowballStemmer('english') # 思诺博词干提取器,偏中庸
for word in words:pt_stem = pt_stemmer.stem(word)lc_stem = lc_stemmer.stem(word)sb_stem = sb_stemmer.stem(word)print('%8s %8s %8s %8s' % (word, pt_stem, lc_stem, sb_stem))
table tabl tabl tabl
probably probabl prob probablwolves wolv wolv wolvplaying play play playis is is isdog dog dog dogthe the the thebeaches beach beach beach
grounded ground ground grounddreamt dreamt dreamt dreamt
envision envis envid envis
词性还原
import nltk.stem as ns
words = ['table', 'probably', 'wolves', 'playing','is', 'dog', 'the', 'beaches', 'grounded','dreamt', 'envision']
# 获取词性还原器对象
lemmatizer = ns.WordNetLemmatizer()
for word in words:n_lemma = lemmatizer.lemmatize(word, pos='n') # 名词 词性还原v_lemma = lemmatizer.lemmatize(word, pos='v') # 动词 词性还原print('%8s %8s %8s' % (word, n_lemma, v_lemma))
table table table
probably probably probablywolves wolf wolvesplaying playing playis is bedog dog dogthe the thebeaches beach beach
grounded grounded grounddreamt dreamt dream
envision envision envision
词袋模型
一句话的语义很大程度取决于某个单词出现的次数,词袋模型以每一个句子作为一个样本,用特征名和特证值构建的数学模型称为“词袋模型”
特证名:句子中所有可能出现的单词
特证值:单词在句子中出现的次数
import nltk.tokenize as tk
import sklearn.feature_extraction.text as ftdoc = 'The brown dog is running. ' \'The black dog is in the black room. ' \'Running in the room is forbidden.'# 对doc按照句子进行拆分
sents = tk.sent_tokenize(doc)cv = ft.CountVectorizer() # 构建词袋模型
bow = cv.fit_transform(sents) # 训练词袋模型
print(cv.get_feature_names()) # 获取所有特征名
# ['black', 'brown', 'dog', 'forbidden', 'in', 'is', 'room', 'running', 'the']
print(bow.toarray())
['black', 'brown', 'dog', 'forbidden', 'in', 'is', 'room', 'running', 'the']
[[0 1 1 0 0 1 0 1 1][2 0 1 0 1 1 1 0 2][0 0 0 1 1 1 1 1 1]]
词频统计
import nltk
doc = "who are you?where are you from?"
word_list = nltk.word_tokenize(doc)#英文分词
freq_list=nltk.FreqDist(doc)#统计词频
print(word_list)
for k,v in freq_list.items():print(k,v)
['who', 'are', 'you', '?', 'where', 'are', 'you', 'from', '?']
w 2
h 2
o 45
a 2
r 4
e 4
y 2
u 2
? 2
f 1
m 1
from nltk.corpus import brown#导入brown语料库
from collections import Counter
print(brown.words())
# [u'The', u'Fulton', u'County', u'Grand', u'Jury', ...]
wordcounts = Counter(brown.words())#计数(区分大小写)
print(wordcounts['the'])
# 62713
print(wordcounts['The'])
# 7258
wordcounts_lower = Counter(i.lower() for i in brown.words())
#全部转换为小写
print(wordcounts_lower['The'])
# 0
print(wordcounts_lower['the'])
# 69971=62713+7258
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
62713
7258
0
69971
情感分析
import nltk.corpus as nc
import nltk.classify as cf
import nltk.classify.util as cu# 存储所有的正向样本
# pdata: [({单词:true}, 'pos'),(),()...]
pdata = []
# pos文件夹中的每个文件的路径
fileids = nc.movie_reviews.fileids('pos')
# print(len(fileids))
# 整理所有正面评论单词,存入pdata列表
for fileid in fileids:sample = {}# words: 把当前文档分词处理words = nc.movie_reviews.words(fileid)for word in words:sample[word] = Truepdata.append((sample, 'POSITIVE'))
# 整理所有反向样本,存入ndata列表
ndata = []
fileids = nc.movie_reviews.fileids('neg')
for fileid in fileids:sample = {}words = nc.movie_reviews.words(fileid)for word in words:sample[word] = Truendata.append((sample, 'NEGATIVE'))# 拆分测试集与训练集数量(80%作为训练集)
pnumb, nnumb = int(0.8 * len(pdata)), int(0.8 * len(ndata))
train_data = pdata[:pnumb] + ndata[:nnumb]
test_data = pdata[pnumb:] + ndata[nnumb:]
# 基于朴素贝叶斯分类器训练测试数据
model = cf.NaiveBayesClassifier.train(train_data)
ac = cu.accuracy(model, test_data)
print(ac)
#
# 模拟业务场景
reviews = ['It is an amazing movie.','This is a dull movie. I would never recommend it to anyone.','The cinematography is pretty great in this movie.','The direction was terrible and the story was all over the place.']
for review in reviews:sample = {}words = review.split()for word in words:sample[word] = Truepcls = model.classify(sample)print(review, '->', pcls)
0.735
It is an amazing movie. -> POSITIVE
This is a dull movie. I would never recommend it to anyone. -> NEGATIVE
The cinematography is pretty great in this movie. -> POSITIVE
The direction was terrible and the story was all over the place. -> NEGATIVE
jieba中文分词
pip install jieba
import jieba
doc="我喜欢静谧的环境,它能让人置身思考之中," \"同繁华城市的夜景一样能启发人,在不喧哗的时候看城市也别有一番韵味" \",但寻常人是受不了那份寂寞的。月光下," \"忙碌一天的人们享受起生活,有人掀开扉页," \"有人悠扬起曼妙的乐曲,有人漫步在白天忙碌奔走的街道上;" \"但同时,有人没有放松紧绷的发条,他们有为了生活卖大力气的," \"有为了光辉的未来埋头苦读的,还有掩着头哭泣的," \"在他们的眼中,月光是不一样的颜色。"
words_list=jieba.lcut(doc)
print(words_list)
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\dell\AppData\Local\Temp\jieba.cache
Loading model cost 0.604 seconds.
Prefix dict has been built successfully.
['我', '喜欢', '静谧', '的', '环境', ',', '它', '能', '让', '人', '置身', '思考', '之中', ',', '同', '繁华', '城市', '的', '夜景', '一样', '能', '启发', '人', ',', '在', '不', '喧哗', '的', '时候', '看', '城市', '也', '别', '有', '一番', '韵味', ',', '但', '寻常', '人', '是', '受不了', '那', '份', '寂寞', '的', '。', '月光', '下', ',', '忙碌', '一天', '的', '人们', '享受', '起', '生活', ',', '有人', '掀开', '扉页', ',', '有人', '悠扬', '起', '曼妙', '的', '乐曲', ',', '有人', '漫步', '在', '白天', '忙碌', '奔走', '的', '街道', '上', ';', '但', '同时', ',', '有人', '没有', '放松', '紧绷', '的', '发条', ',', '他们', '有', '为了', '生活', '卖大', '力气', '的', ',', '有', '为了', '光辉', '的', '未来', '埋头', '苦读', '的', ',', '还有', '掩着', '头', '哭泣', '的', ',', '在', '他们', '的', '眼中', ',', '月光', '是', '不', '一样', '的', '颜色', '。']
import jieba
str="东汉末年分三国当时有三个国家"
print(jieba.lcut(str))
print(jieba.lcut(str,cut_all=True))
print(jieba.lcut_for_search(str))
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\dell\AppData\Local\Temp\jieba.cache
Loading model cost 0.790 seconds.
Prefix dict has been built successfully.
['东汉', '末年', '分', '三国', '当时', '有', '三个', '国家']
['东汉', '汉末', '末年', '分', '三国', '当时', '有', '三个', '国家']
['东汉', '末年', '分', '三国', '当时', '有', '三个', '国家']
import jieba
doc="这是南宫峻熙的博客"
print(jieba.lcut(doc))
jieba.add_word("南宫峻熙")
# 将指定词语加入到分词库
print(jieba.lcut(doc))
['这是', '南宫', '峻熙', '的', '博客']
['这是', '南宫峻熙', '的', '博客']
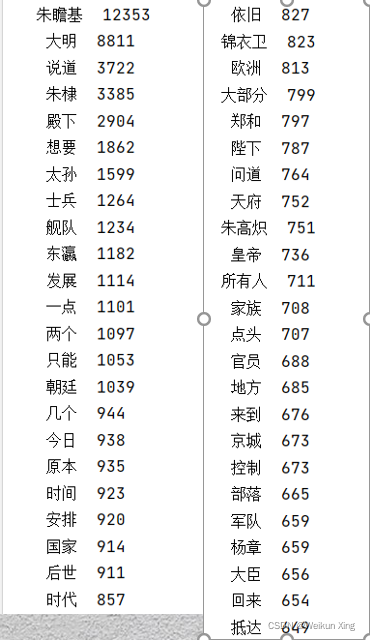
对《我的大明新帝国》这本电子书进行词频统计
import jieba
from collections import Counter
def stopwordslist(filepath):# 创建停用词liststopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwords
def seg_sentence(sentence):# 对句子进行分词sentence_seged = jieba.cut(sentence.strip())stopwords = stopwordslist('stoplist.txt') # 这里加载停用词的路径outstr = []for word in sentence_seged:if word not in stopwords:if word != '\t':outstr.append(word)return outstr
def word_frequency(line_seg):# 对分词进行词频展示c = Counter()for x in line_seg:if len(x) > 1 and x != '\r\n':c[x] += 1for (k, v) in c.most_common():print('%s%s %d' % (' ' * (5 - len(k)), k, v))
inputs = open('我的大明新帝国.txt', 'r', encoding='utf-8')
lines = ""
for line in inputs:lines += line.replace("\n", "")
inputs.close()
line_seg = seg_sentence(lines) # 这里的返回值是列表
print(word_frequency(line_seg)) # 取词频
运行可能需要几分钟,耐心等待
snownlp库
pip install snownlp
from snownlp import SnowNLP
doc="我喜欢静谧的环境,它能让人置身思考之中," \"同繁华城市的夜景一样能启发人,在不喧哗的时候看城市也别有一番韵味" \",但寻常人是受不了那份寂寞的。月光下," \"忙碌一天的人们享受起生活,有人掀开扉页," \"有人悠扬起曼妙的乐曲,有人漫步在白天忙碌奔走的街道上;" \"但同时,有人没有放松紧绷的发条,他们有为了生活卖大力气的," \"有为了光辉的未来埋头苦读的,还有掩着头哭泣的," \"在他们的眼中,月光是不一样的颜色。"
s=SnowNLP(doc)
print('词语:',s.words)
print('分句:',s.sentences)
print('情感偏向:',s.sentiments)
print('拼音:',s.pinyin)
print('关键字:',s.keywords(5))
print('摘要:',s.summary(5))
print('词频:',s.tf)
print('逆向文件频率:',s.idf)
词语: ['我', '喜欢', '静谧', '的', '环境', ',', '它', '能', '让', '人', '置身', '思考', '之中', ',', '同', '繁华', '城市', '的', '夜景', '一样', '能', '启发', '人', ',', '在', '不', '喧', '哗', '的', '时候', '看', '城市', '也', '别', '有', '一番', '韵味', ',', '但', '寻常', '人', '是', '受', '不', '了', '那', '份', '寂寞', '的', '。', '月光', '下', ',', '忙碌', '一', '天', '的', '人们', '享受', '起', '生活', ',', '有人', '掀开', '扉页', ',', '有人', '悠扬', '起曼', '妙', '的', '乐曲', ',', '有人', '漫步', '在', '白天', '忙碌', '奔走', '的', '街道', '上', ';', '但', '同时', ',', '有人', '没', '有', '放松', '紧', '绷', '的', '发', '条', ',', '他们', '有', '为了', '生活', '卖', '大', '力气', '的', ',', '有为', '了', '光辉', '的', '未来', '埋头苦', '读', '的', ',', '还有', '掩', '着头', '哭泣', '的', ',', '在', '他们', '的', '眼中', ',', '月光', '是', '不', '一样', '的', '颜色', '。']
分句: ['我喜欢静谧的环境', '它能让人置身思考之中', '同繁华城市的夜景一样能启发人', '在不喧哗的时候看城市也别有一番韵味', '但寻常人是受不了那份寂寞的', '月光下', '忙碌一天的人们享受起生活', '有人掀开扉页', '有人悠扬起曼妙的乐曲', '有人漫步在白天忙碌奔走的街道上', '但同时', '有人没有放松紧绷的发条', '他们有为了生活卖大力气的', '有为了光辉的未来埋头苦读的', '还有掩着头哭泣的', '在他们的眼中', '月光是不一样的颜色']
情感偏向: 0.9999999999999998
拼音: ['wo', 'xi', 'huan', 'jing', 'mi', 'de', 'huan', 'jing', ',', 'ta', 'neng', 'rang', 'ren', 'zhi', 'shen', 'si', 'kao', 'zhi', 'zhong', ',', 'tong', 'fan', 'hua', 'cheng', 'shi', 'de', 'ye', 'jing', 'yi', 'yang', 'neng', 'qi', 'fa', 'ren', ',', 'zai', 'bu', 'xuan', 'hua', 'de', 'shi', 'hou', 'kan', 'cheng', 'shi', 'ye', 'bie', 'you', 'yi', 'fan', 'yun', 'wei', ',', 'dan', 'xun', 'chang', 'ren', 'shi', 'shou', 'bu', 'liao', 'na', 'fen', 'ji', 'mo', 'de', '。', 'yue', 'guang', 'xia', ',', 'mang', 'lu', 'yi', 'tian', 'de', 'ren', 'men', 'xiang', 'shou', 'qi', 'sheng', 'huo', ',', 'you', 'ren', 'xian', 'kai', 'fei', 'ye', ',', 'you', 'ren', 'you', 'yang', 'qi', 'man', 'miao', 'de', 'yue', 'qu', ',', 'you', 'ren', 'man', 'bu', 'zai', 'bai', 'tian', 'mang', 'lu', 'ben', 'zou', 'de', 'jie', 'dao', 'shang', ';', 'dan', 'tong', 'shi', ',', 'you', 'ren', 'mei', 'you', 'fang', 'song', 'jin', 'beng', 'de', 'fa', 'tiao', ',', 'ta', 'men', 'you', 'wei', 'liao', 'sheng', 'huo', 'mai', 'da', 'li', 'qi', 'de', ',', 'you', 'wei', 'liao', 'guang', 'hui', 'de', 'wei', 'lai', 'mai', 'tou', 'ku', 'du', 'de', ',', 'hai', 'you', 'yan', 'zhe', 'tou', 'ku', 'qi', 'de', ',', 'zai', 'ta', 'men', 'de', 'yan', 'zhong', ',', 'yue', 'guang', 'shi', 'bu', 'yi', 'yang', 'de', 'yan', 'shai', '。']
关键字: ['有人', '人', '不', '忙碌', '城市']
摘要: ['月光是不一样的颜色', '有人漫步在白天忙碌奔走的街道上', '但寻常人是受不了那份寂寞的', '忙碌一天的人们享受起生活', '有人掀开扉页']
词频: [{'我': 1}, {'喜': 1}, {'欢': 1}, {'静': 1}, {'谧': 1}, {'的': 1}, {'环': 1}, {'境': 1}, {',': 1}, {'它': 1}, {'能': 1}, {'让': 1}, {'人': 1}, {'置': 1}, {'身': 1}, {'思': 1}, {'考': 1}, {'之': 1}, {'中': 1}, {',': 1}, {'同': 1}, {'繁': 1}, {'华': 1}, {'城': 1}, {'市': 1}, {'的': 1}, {'夜': 1}, {'景': 1}, {'一': 1}, {'样': 1}, {'能': 1}, {'启': 1}, {'发': 1}, {'人': 1}, {',': 1}, {'在': 1}, {'不': 1}, {'喧': 1}, {'哗': 1}, {'的': 1}, {'时': 1}, {'候': 1}, {'看': 1}, {'城': 1}, {'市': 1}, {'也': 1}, {'别': 1}, {'有': 1}, {'一': 1}, {'番': 1}, {'韵': 1}, {'味': 1}, {',': 1}, {'但': 1}, {'寻': 1}, {'常': 1}, {'人': 1}, {'是': 1}, {'受': 1}, {'不': 1}, {'了': 1}, {'那': 1}, {'份': 1}, {'寂': 1}, {'寞': 1}, {'的': 1}, {'。': 1}, {'月': 1}, {'光': 1}, {'下': 1}, {',': 1}, {'忙': 1}, {'碌': 1}, {'一': 1}, {'天': 1}, {'的': 1}, {'人': 1}, {'们': 1}, {'享': 1}, {'受': 1}, {'起': 1}, {'生': 1}, {'活': 1}, {',': 1}, {'有': 1}, {'人': 1}, {'掀': 1}, {'开': 1}, {'扉': 1}, {'页': 1}, {',': 1}, {'有': 1}, {'人': 1}, {'悠': 1}, {'扬': 1}, {'起': 1}, {'曼': 1}, {'妙': 1}, {'的': 1}, {'乐': 1}, {'曲': 1}, {',': 1}, {'有': 1}, {'人': 1}, {'漫': 1}, {'步': 1}, {'在': 1}, {'白': 1}, {'天': 1}, {'忙': 1}, {'碌': 1}, {'奔': 1}, {'走': 1}, {'的': 1}, {'街': 1}, {'道': 1}, {'上': 1}, {';': 1}, {'但': 1}, {'同': 1}, {'时': 1}, {',': 1}, {'有': 1}, {'人': 1}, {'没': 1}, {'有': 1}, {'放': 1}, {'松': 1}, {'紧': 1}, {'绷': 1}, {'的': 1}, {'发': 1}, {'条': 1}, {',': 1}, {'他': 1}, {'们': 1}, {'有': 1}, {'为': 1}, {'了': 1}, {'生': 1}, {'活': 1}, {'卖': 1}, {'大': 1}, {'力': 1}, {'气': 1}, {'的': 1}, {',': 1}, {'有': 1}, {'为': 1}, {'了': 1}, {'光': 1}, {'辉': 1}, {'的': 1}, {'未': 1}, {'来': 1}, {'埋': 1}, {'头': 1}, {'苦': 1}, {'读': 1}, {'的': 1}, {',': 1}, {'还': 1}, {'有': 1}, {'掩': 1}, {'着': 1}, {'头': 1}, {'哭': 1}, {'泣': 1}, {'的': 1}, {',': 1}, {'在': 1}, {'他': 1}, {'们': 1}, {'的': 1}, {'眼': 1}, {'中': 1}, {',': 1}, {'月': 1}, {'光': 1}, {'是': 1}, {'不': 1}, {'一': 1}, {'样': 1}, {'的': 1}, {'颜': 1}, {'色': 1}, {'。': 1}]
逆向文件频率: {'我': 4.822966130975706, '喜': 4.822966130975706, '欢': 4.822966130975706, '静': 4.822966130975706, '谧': 4.822966130975706, '的': 2.482028949960385, '环': 4.822966130975706, '境': 4.822966130975706, ',': 2.482028949960385, '它': 4.822966130975706, '能': 4.3067641501733345, '让': 4.822966130975706, '人': 3.0501090444320624, '置': 4.822966130975706, '身': 4.822966130975706, '思': 4.822966130975706, '考': 4.822966130975706, '之': 4.822966130975706, '中': 4.3067641501733345, '同': 4.3067641501733345, '繁': 4.822966130975706, '华': 4.822966130975706, '城': 4.3067641501733345, '市': 4.3067641501733345, '夜': 4.822966130975706, '景': 4.822966130975706, '一': 3.708137270718351, '样': 4.3067641501733345, '启': 4.822966130975706, '发': 4.3067641501733345, '在': 3.9648864949852136, '不': 3.9648864949852136, '喧': 4.822966130975706, '哗': 4.822966130975706, '时': 4.3067641501733345, '候': 4.822966130975706, '看': 4.822966130975706, '也': 4.822966130975706, '别': 4.822966130975706, '有': 2.933296802613198, '番': 4.822966130975706, '韵': 4.822966130975706, '味': 4.822966130975706, '但': 4.3067641501733345, '寻': 4.822966130975706, '常': 4.822966130975706, '是': 4.3067641501733345, '受': 4.3067641501733345, '了': 3.9648864949852136, '那': 4.822966130975706, '份': 4.822966130975706, '寂': 4.822966130975706, '寞': 4.822966130975706, '。': 4.3067641501733345, '月': 4.3067641501733345, '光': 3.9648864949852136, '下': 4.822966130975706, '忙': 4.3067641501733345, '碌': 4.3067641501733345, '天': 4.3067641501733345, '们': 3.9648864949852136, '享': 4.822966130975706, '起': 4.3067641501733345, '生': 4.3067641501733345, '活': 4.3067641501733345, '掀': 4.822966130975706, '开': 4.822966130975706, '扉': 4.822966130975706, '页': 4.822966130975706, '悠': 4.822966130975706, '扬': 4.822966130975706, '曼': 4.822966130975706, '妙': 4.822966130975706, '乐': 4.822966130975706, '曲': 4.822966130975706, '漫': 4.822966130975706, '步': 4.822966130975706, '白': 4.822966130975706, '奔': 4.822966130975706, '走': 4.822966130975706, '街': 4.822966130975706, '道': 4.822966130975706, '上': 4.822966130975706, ';': 4.822966130975706, '没': 4.822966130975706, '放': 4.822966130975706, '松': 4.822966130975706, '紧': 4.822966130975706, '绷': 4.822966130975706, '条': 4.822966130975706, '他': 4.3067641501733345, '为': 4.3067641501733345, '卖': 4.822966130975706, '大': 4.822966130975706, '力': 4.822966130975706, '气': 4.822966130975706, '辉': 4.822966130975706, '未': 4.822966130975706, '来': 4.822966130975706, '埋': 4.822966130975706, '头': 4.3067641501733345, '苦': 4.822966130975706, '读': 4.822966130975706, '还': 4.822966130975706, '掩': 4.822966130975706, '着': 4.822966130975706, '哭': 4.822966130975706, '泣': 4.822966130975706, '眼': 4.822966130975706, '颜': 4.822966130975706, '色': 4.822966130975706}






