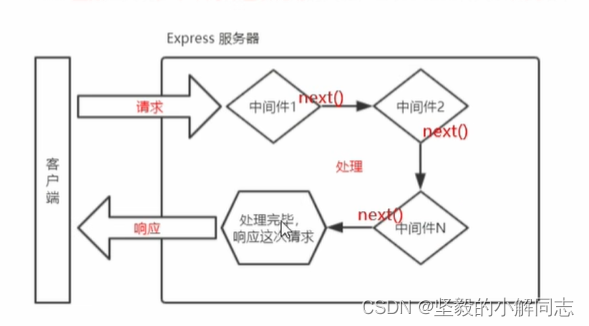
目录:
(1)k8s指南-概述
(2)k8s指南-架构
(3)k8s指南-工作负载(1)
(4)k8s指南-工作负载(2)
(5)k8s指南-工作负载(3)
(6)k8s指南-工作负载(4)
(7)k8s指南-Service
(8)k8s指南-Ingress
(9)k8s指南-DNS与服务发现
(10)K8S指南-平滑升级与自动扩缩容
首先给个结论:
- 系统升级发布时,先是Deployment的replicas生效,假设replicas为10,则先将旧的pod扩/缩容到10。
- 随后hpa的minReplicas和maxReplicas生效,假设hpa的范围是1~5,则会立即将旧的pod数量缩减到5。
- 其后Deployment的RollingUpdate生效,按照maxSurge设置扩展新的pod,并逐步缩减旧的pod,直到旧的pod全部替换为新pod并且数量为5。
- 最后hpa扩缩容策略生效,根据hpa的behavior来执行水平扩缩容。
Pod初始数量与滚动更新
在本系列前文中介绍Deployment的时候介绍过,pod的基本数量是由ReplicaSet控制的,参数字段为.spec.replicas。
如果未指定
.spec.replicas字段,则默认值为1。
当deployment更新时,在rs指定pod数量的基础上,根据更新策略来更新pod。也就是说,如果当前pod数不为1,而.spec.replicas参数为1时,rs控制器会将初始pod数量降为1。
Deployment支持两种更新策略,分别是滚动更新(RollingUpdate)和删除时更新(Recreate),后者也称为单批次更新。
- Recreate,先删除当前正在运行的pod,当所有pod销毁后,再创建新的rs并启动新pod。在整个更新过程中,会造成服务中断。一般不用。
- RollingUpdate,一次仅更新一批pod,分多次将全部pod更新完。该策略实现了服务平滑升级,但不同客户端得到的响应可能会因为来自新旧两个不同版本的服务端而有所不同。
HPA
RS可以控制pod的基本数量,但是需要手动去调整。
HPA(HorizontalPodAutoscaler)可以控制Deployment及其ReplicaSet的规模,从而可以实现自动控制pod的数量。
HPA自动扩缩不适用于无法扩缩的对象,例如DaemonSet。
HorizontalPodAutoscaler 被实现为 Kubernetes API 资源和控制器。
资源决定了控制器的行为。 在 Kubernetes 控制平面内运行的水平 Pod 自动扩缩控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标, 例如,平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标。间隔时间由kube-controller-manager的--horizontal-pod-autoscaler-sync-period参数设置,默认为15s。
对资源指标的支持
HPA的任何目标资源都可以基于其中的Pods的资源用量来实现扩缩。在定义Pod规约时,cpu和memory这类资源请求是必须被设定的。这些设定值被用来确定资源利用量并被HPA控制器用来对目标资源完成扩缩操作。下面是一个示例:
spec:minReplicas: 1maxReplicas: 5metrics:type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 60
基于这一配置,HPA控制器会根据全部pod的平均cpu利用率是否达到60%来决定要不要扩缩容。
注意,利用率是pod的当前资源用量与request请求值之间的比值。
对容器资源指标的支持
HPA除了支持pod级别的资源指标外,还支持容器级别的资源指标。这使得用户可以为pod中最重要的容器配置扩缩阈值。
比如说,当前pod中有一个web应用和一个执行日志操作的容器,你可以基于web容器的资源用量来执行扩缩,而不管日志操作容器的资源用量。下面是一个示例:
type: ContainerResource
containerResource:name: cpucontainer: application // 容器名target:type: UtilizationaverageUtilization: 60
扩缩行为
在HPA中可以通过behavior参数来设置扩容和缩容行为,包括扩/缩容速率,扩/缩容之后的稳定窗口期。下面是一个示例:
behavior:scaleDown:stabilizationWindowSeconds: 600 # 等待10分钟再开始缩容policies:- type: Podsvalue: 4periodSeconds: 60 // 每分钟最多只允许缩容4- type: Percentvalue: 10periodSeconds: 60 // 每分钟最多只允许缩容10%
以上配置为缩容时的策略,第一个策略允许在一分钟内最多缩容4个pod,第二个表示在一分钟内最多缩容当前pod数量的10%。当存在多个策略时,取最大更改量的策略为默认策略。
稳定窗口
在上面扩缩行为示例代码中有一个参数为stabilizationWindowSeconds, 这个时间叫稳定窗口,目的是为了避免因为指标利用率的毛刺现象而出现频繁的扩缩容。
有了稳定窗口期之后,当HPA控制器判断需要扩缩容时,需要先保持窗口期的时间稳定不变。稳定期结束后,根据稳定期时间段的最终期望结果来进行扩缩容。
默认行为
要使用自定义扩缩容,不必指定所有字段。可以在基础配置中指定默认行为,并在自定义配置中覆写自定义参数。
下面是一个默认配置:
behavior:scaleDown:stabilizationWindowSeconds: 300 // 缩容稳定窗口期policies:- type: Percentvalue: 100periodSeconds: 15 //15s内最多缩容50%scaleUp:stabilizationWindowSeconds: 0 // 扩容稳定窗口期为0policies:- type: Percentvalue: 100periodSeconds: 15 // 15s内最多扩容100%- type: Podsvalue: 4periodSeconds: 15 // 15s内最多扩容4个podselectPolicy: Max // 更改值最大的策略生效,默认就是该策略
然后在自定义配置中覆写缩容策略:
behavior:scaleDown:policies:- type: Percentvalue: 10periodSeconds: 60
该配置会与默认配置合并,最终的缩容策略为:60s内最多缩容10%。
selectPolicy:Disable会关闭扩/缩容
副本数上下限
在HPA中可以指定副本数的上下限。比如minReplicas: 1 maxReplicas: 5表示pod数量下限为1,上限为5,换句话说,不管如何缩容,pod数都不能少于1,不管如何扩容,pod数不能大于5。
HPA中副本数的上下限也会对Deployment中的ReplicaSet有影响。
当Deployment上线或更新时,pod初始数量会被设置为Deployment中的rs数量,随后会受到HPA中的副本数限制。
举例说明,当前pod数量为20。Deployment更新时,其rs参数为1,因此rs控制器会将pod数量Scale down到1。
如果HPA中的minReplicas和maxReplica为15~25,则会将pod数量Scale up到15。随后Deployment中更新策略才会对pod执行更新。
这个就是本文开头给出的结论。
快速扩容为什么不快?
比如说有一个配置如下:
behavior:scaleUp:policies:- type: Percentvalue: 900periodSeconds: 10
表示允许每10秒最大扩容900%。
但在实际中发现,pod扩容没有达到预期效果。通常原因是计算周期与指标延迟。
在上文中说过HPA控制器是周期性计算期望副本数的,默认值为15秒。每次计算时获取到的监控指标也可能是有延迟的。
这两部分的时长之和为扩容的延迟时间。
通常都不需要HPA极度的灵敏,有一定的延时一般都是可接受的。
使用自定义指标进行伸缩
Kubernetes默认提供了CPU和内存作为HPA弹性伸缩的指标,如果有更复杂的场景需求,比如基于业务单副本QPS大小来进行自动扩缩容,可以考虑安装prometheus-adapter来实现基于自定义指标来进行弹性伸缩。
参考资料
[1]. https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-resource-metrics