动态面板数据模型及估计方法
假说里面不要出现显著
文章目录
- (一)面板数据基础知识
- **一、面板数据的定义**
- **二、面板数据的分类**
- **三、面板数据的优缺点**
- **四、面板数据模型**
- **五、面板数据模型的估计**
- (二)**短面板数据分析的基本程序**
- **三大问题检验**
- (三)**长面板数据分析**
- (四)**机制识别方法**
- (五)平稳序列
- (六)内生性与工具变量法
- **内生性问题及解决方法**
- 两阶段最小二乘法
- (七)动态面板数据模型及估计方法
- 差分GMM和系统GMM
- (八)面板门限模型
- 一、门限回归
- 二、面板数据的门限回归
- 三、面板单门限模型的两大检验
- 双门限面板模型
- 四、面板门限模型操作xthreg命令介绍
- 五、面板单门限模型的实现与检验
- 六、面板多门限模型的实现与检验
- 实例分析中的代码
- (九)双重差分模型
- 一、双重差分模型的介绍
- 二、做DID需要注意的若干问题
- 三、双重差分模型的Stata操作
- (十)合成控制法
- 一、合成控制法的基本思想
- 合成控制法的具体方法
- 合成控制法的synth命令
- 合成控制法Stata操作
- 合成控制法的稳健性检验
- 使用合成控制法的注意事项
- (十一)断点回归
- 断点回归设计理论
- 断点回归设计的Stata命令
- 断点回归设计的案例操作
(一)面板数据基础知识
一、面板数据的定义
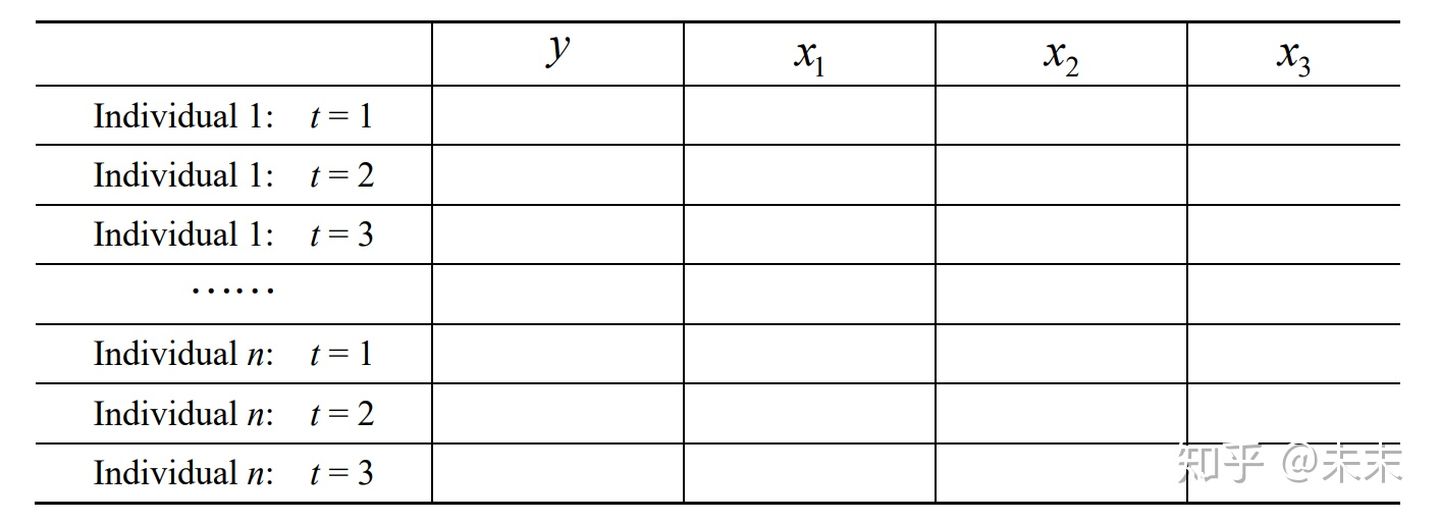
面板数据(panel data或long itudinaldata),指的是在一段时间内跟踪同一组个体(individual)的数据。它既有横截面的维度(n个个体),又有时间维度(T个时期)。是同时在时间和截面上取得的二维数据,又称时间序列与截面混合数据(polled timeseries and cross section data)。
一个T=3的面板数据结构如下所示
二、面板数据的分类
面板数据类型通常分为三类,分别为:
a.短面板数据与长面板数据
b.动态面板数据和静态面板数据
c.平衡面板和非平衡面板
(1)短面板数据与长面板数据
当截面数n大于T时,即为短面板数据;
当截面数n小于T时,即为长面板数据.
(2)动态面板数据和静态面板数据
如果解释变量包含别解释变量的滞后值,则为动态面板数据,反之则为静态面板.
(3)平衡面板和非平衡面板
当每个个体在相同的时间内都有观察值记录,即为平衡面板,反之则为非平衡面板。
三、面板数据的优缺点
1、面板数据的优点
(1)可以处理由不可观察的个体异质性所导致的内生性问题。
(2)提供更多个体动态行为的信息。
(3)样本量较大,可以提高估计的精确度。
2、面板数据的不足之处
(1)大多数面板数据分析技术都针对的是短面板。
(2)寻找面板数据结构工具变量不是很容易。
四、面板数据模型
面板数据模型分为非观测效应模型和混合回归模型两类。存在不可观测的个体效应模型即为非观测效应模型,反之则为混合回归模型。
(1)非观测效应模型
a.固定效应模型
b.随机效应模型
Y i t = β x i t + α i + ε i t i = 1 , ⋯ , n ; t = 1 , ⋯ , T \begin{aligned} &Y_{i t}=\beta x_{i t}+\alpha_{i}+\varepsilon_{i t} \\ &i=1, \cdots, n ; t=1, \cdots, T \end{aligned} Yit=βxit+αi+εiti=1,⋯,n;t=1,⋯,T
其中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wvrd4mDI-1640317583087)(https://www.zhihu.com/equation?tex={\alpha+_i})] 是不可观测的个体效应。
如果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KqgWnioB-1640317583088)(https://www.zhihu.com/equation?tex={\alpha+_i})] 与某个解释变量相关,就是固定效应模型
如果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tQ358z2f-1640317583088)(https://www.zhihu.com/equation?tex={\alpha+_i})] 与所有解释变量不相关,则为随机效应模型
**固定效应模型又分为:**单向固定效应模型与双向固定效应模型
**单向固定效应模型:**只考虑个体效应不考虑时间效应;
**双向固定效应模型:**同时考虑个体效应和时间效应,即
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fTr3IBgu-1640317583089)(https://www.zhihu.com/equation?tex={y_{it}}+%3D+\beta+{x_{it}}+%2B+{\lambda+_t}+%2B+{\alpha+i}+%2B+{\varepsilon+{it}})]
(2)混合回归模型
如果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UZNe60iD-1640317583090)(https://www.zhihu.com/equation?tex={\alpha+_i}%3D0)] ,即不存在个体效应,则为混合回归模型,即
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7RZ6ZKmC-1640317583091)(https://www.zhihu.com/equation?tex=\begin{array}{l}+{Y_{it}}+%3D+\beta+{x_{it}}+%2B+{\varepsilon+_{it}}\+i+%3D+1%2C+\cdots+%2Cn%3Bt+%3D+1%2C+\cdots+%2CT+\end{array})]
五、面板数据模型的估计
1、固定效应模型的估计
对固定效应模型的估计有两种方法:
固定效应变换(组内变换)与LSDV(最小二乘虚拟变量法)
a.固定效应变换(组内变换)
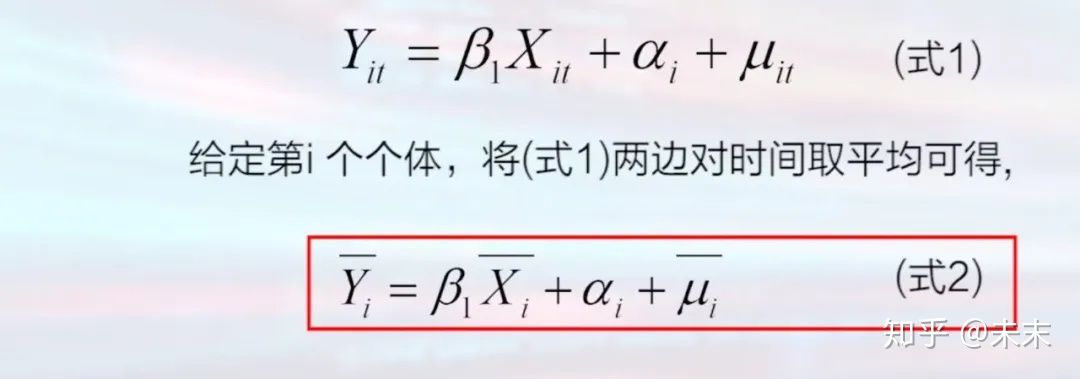

固定效应变换的优缺点
**优点:**即使个体效应与解释变量相关也可以得到一致估计;
**缺点:**无法估计不随时间而变的变量的影响。
#对固定效应变换无法估计不随时间而变的变量的影响的解决

固定效应模型的Stata的实现命令为:xtreg y x, fe
引入时间效应的双向固定效应的Stata的实现命令为:xi: xtreg y x i.year, fe
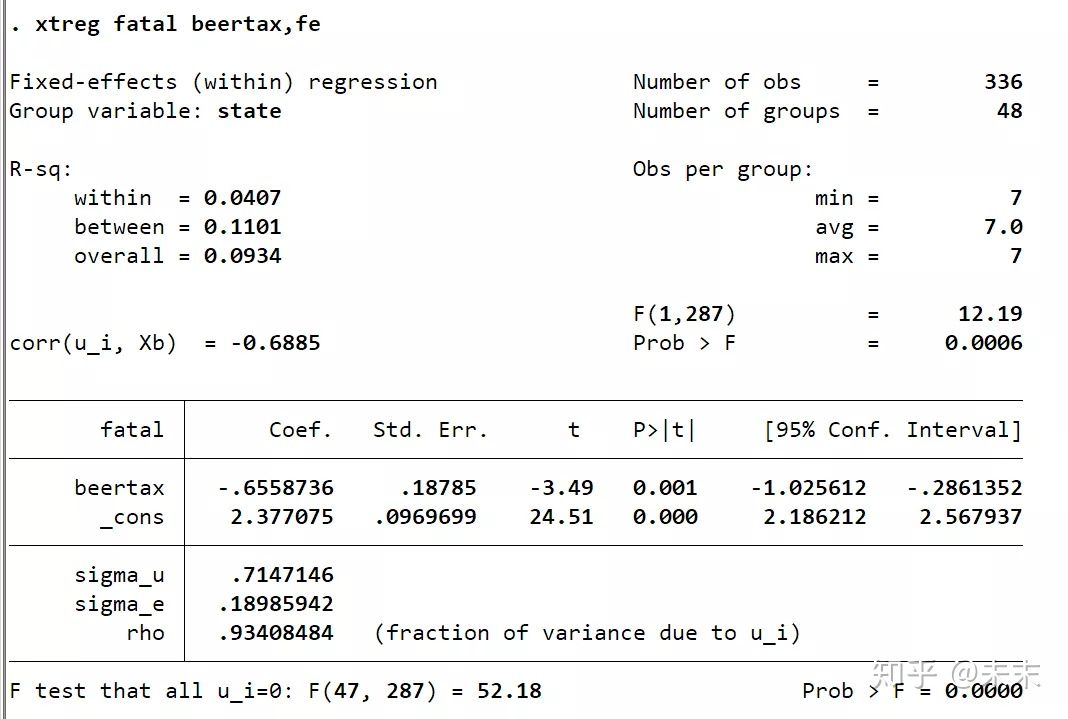 #数据来自慕课浙江大学方红生教授的面板数据分析与Stata应用课程(xtreg y x, fe)
#数据来自慕课浙江大学方红生教授的面板数据分析与Stata应用课程(xtreg y x, fe)
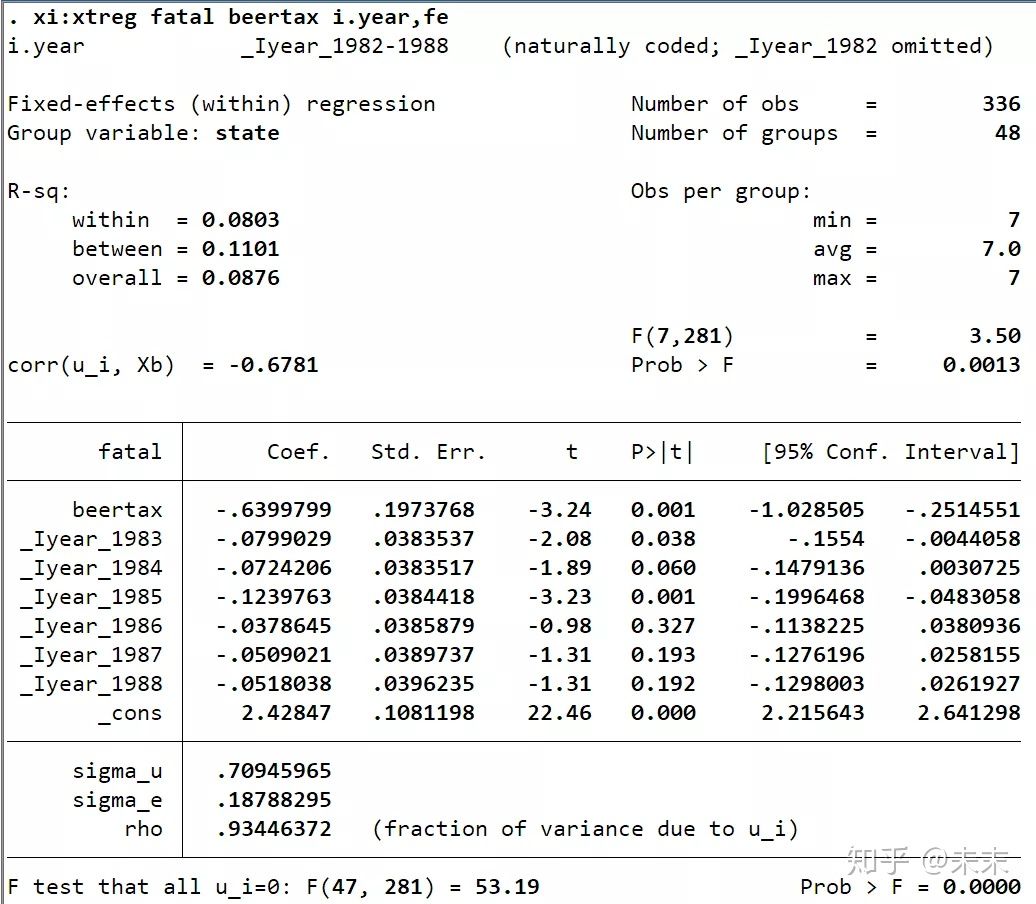 #数据来自慕课浙江大学方红生教授的面板数据分析与Stata应用课程(xi: xtreg y x i.year, fe)
#数据来自慕课浙江大学方红生教授的面板数据分析与Stata应用课程(xi: xtreg y x i.year, fe)
b.LSDV(最小二乘虚拟变量法)
#LSDV的基本思想

LSDV的Stata的实现命令为:
不存在时间效应:reg y x i.code
存在时间效应:xi: reg y x i.code i.year
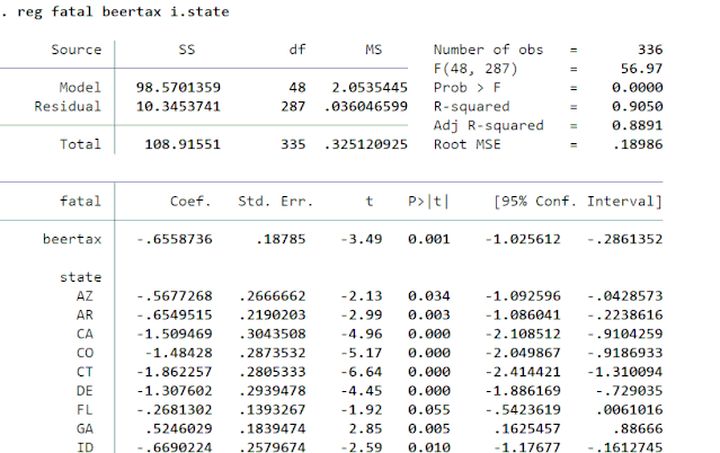
#数据来自慕课浙江大学方红生教授的面板数据分析与Stata应用课程(reg y x i.code)
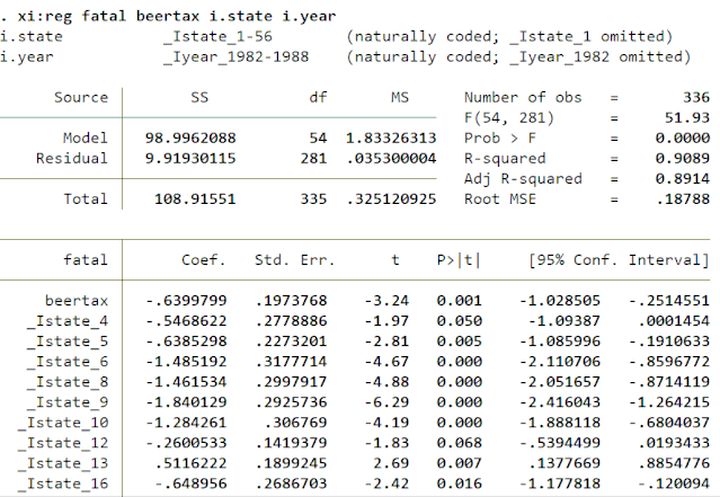
#数据来自慕课浙江大学方红生教授的面板数据分析与Stata应用课程(xi: reg y x i.code i.year)
2、随机效应模型
对随机效应模型的估计方法是广义最小二乘法

随机效应模型估计的Stata命令
不存在时间效应:xtreg y x ,re
存在时间效应:xi: reg y x i.year,re
短面板数据估计的同时,还需要考虑三大问题
即,误差项的异方差、误差项的自相关、截面相关问题

-
通过在命令中加入选项“robust”可以获得White稳健标准误,可以解决异方差的问题。
-
在命令中加入选项“cluster”可以获得Rogers标准误或聚类稳健的标准误,可以同时解决异方差和自相关两大问题。
-
使用命令xtscc可以同时解决三大问题,提供Driscoll-Kraay标准误。
(二)短面板数据分析的基本程序
1、模型设定与数据
2、描述性统计与作图
3、模型选择
4、报告计量结果
#以啤酒税将降低交通死亡率的假说为例,数据来自陈强教授的《高级计量经济学及Stata应用(第二版)》中的“traffic.dta”数据集。
第一步 模型设定与数据
为了检验假说,构造一个双向固定效应模型
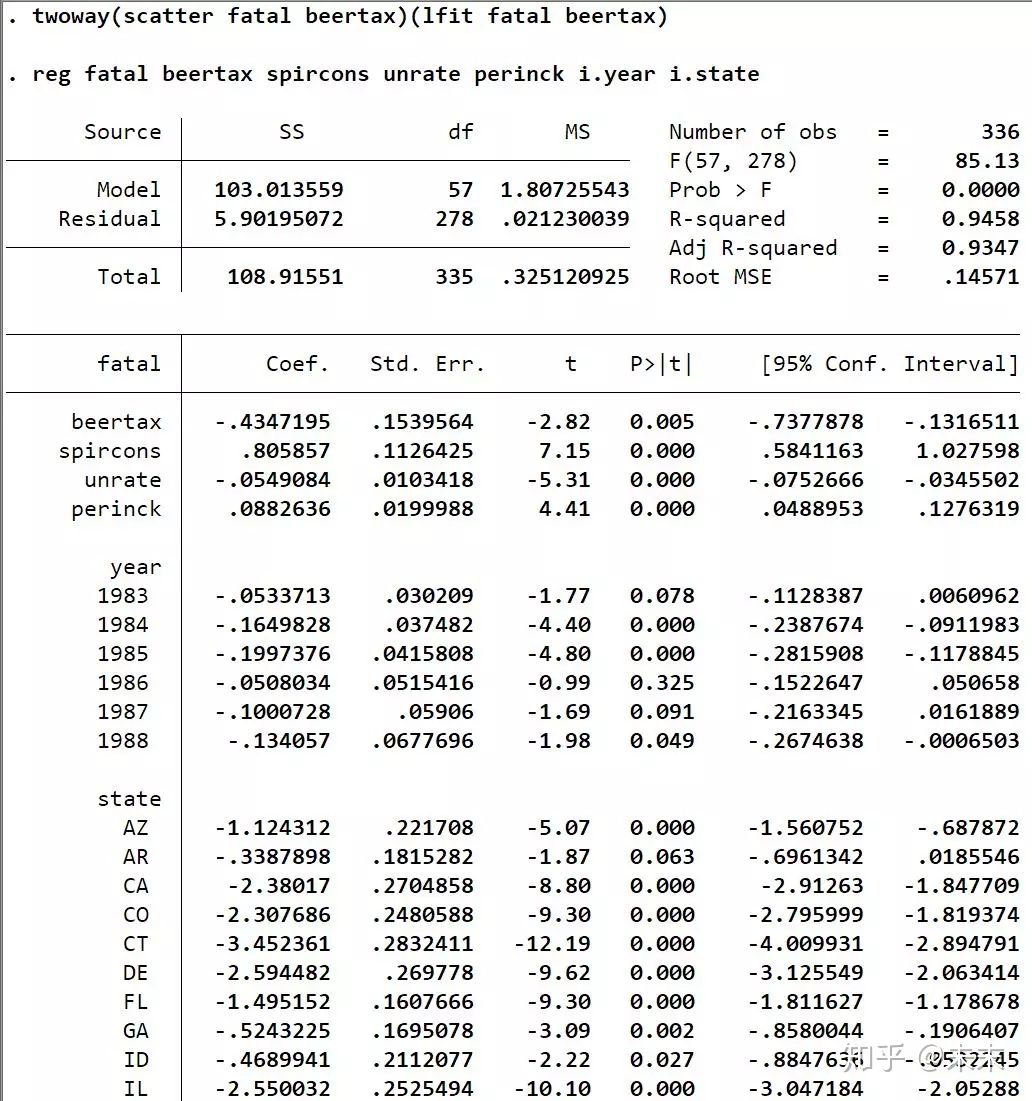
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e448qs0w-1640317583112)(https://www.zhihu.com/equation?tex=\begin{gathered}+++fata{l_{it}}+%3D+{\beta+_0}+%2B+{\beta+1}beerta{x{it}}+%2B+{\beta+2}spircon{s{it}}+%2B+{\beta+3}unrat{e{it}}+%2B+{\beta+4}perinc{k{it}}+\hfill%2B{\mu+_i}+%2B+{\gamma+t}+%2B+{\varepsilon+{it}}+\hfill\end{gathered})]
其中,被解释变量 f a t a l f a t a l fatal 为交通死亡率,核心解释变量 beertax 为啤酒税; 另外三个可观测 的控制变量: spircons、unrate、perinck 分别为酒精的消费量、税率和人均个人收入; μ i \mu_{i} μi 为不可观测的个体效应, γ t \gamma_{t} γt 为时间效应。
在Stata软件中对数据进行分析,执行如下步骤:
1、导入数据到Stata中
在Stata的“命令窗口”中输入
命令【use"数据集路径\traffic.dta"】将“traffic.dta”数据集导入到Stata中,
例如【use"C:\Users\traffic.dta"】。
将数据导入Stata后,即可在Stata的“变量窗口”中看到“traffic”数据集中的各个变量的名称及其标签。
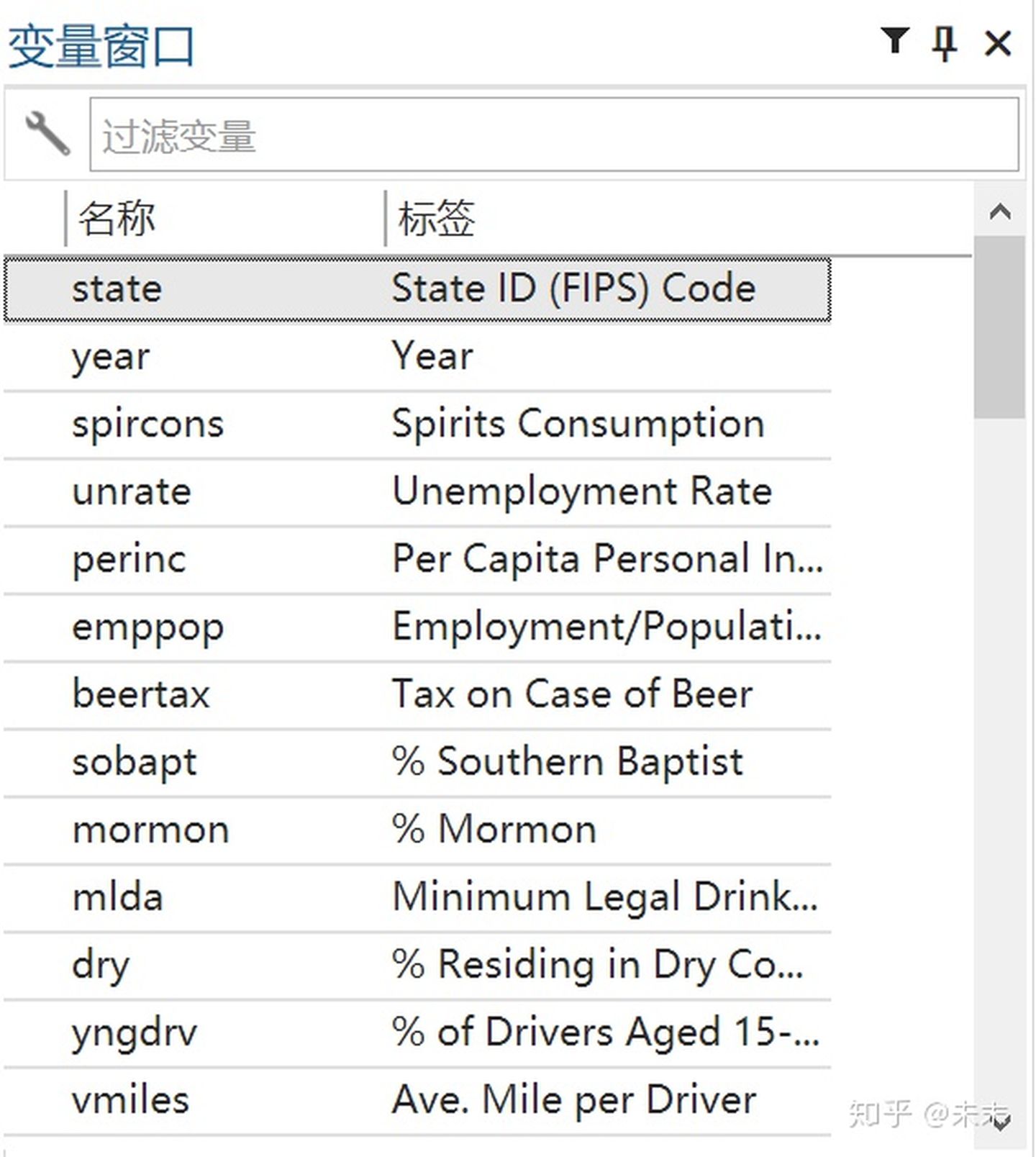 以啤酒税将降低交通死亡率的假说为例,数据来自陈强教授的《高级计量经济学及Stata应用(第二版)》中的“traffic.dta”数据集。
以啤酒税将降低交通死亡率的假说为例,数据来自陈强教授的《高级计量经济学及Stata应用(第二版)》中的“traffic.dta”数据集。
2、查看数据
在Stata的“命令窗口”输入命令【des】查看“traffic”数据集。
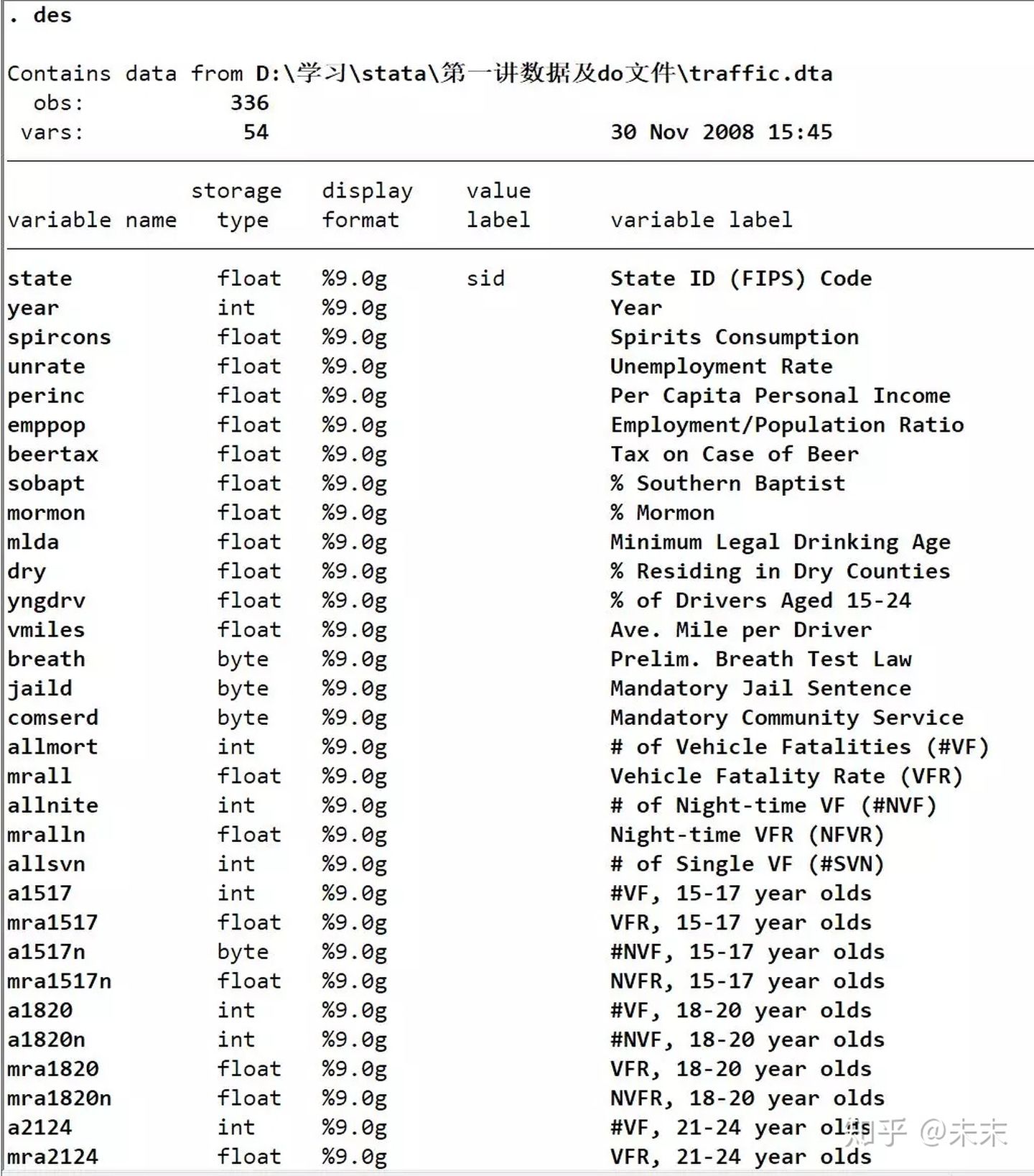
从输出结果我们可以看到:“traffic”数据集包含336个观测值,54个变量。此外,我们还可以看到数据集中的变量名称、数据类型以及相关的说明。
通过命令【xtdes】我们可以查看面板数据的特征。
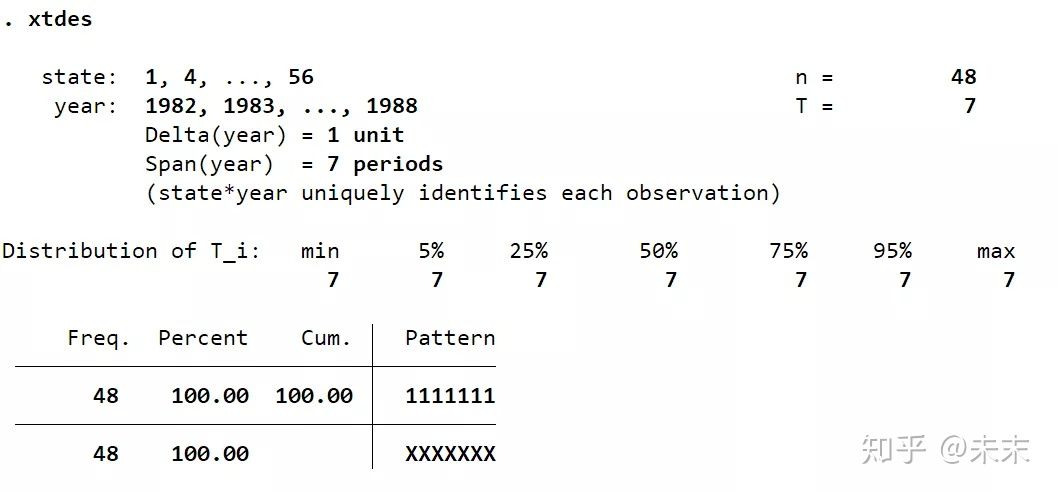
由结果可知:面板数据的截面数 ,时间数 , ,说明这是一个短面板数据集。
在使用面板数据分析前,我们需要输入命令【xtset state year】,来告诉Stata软件,这是一个以截面变量state为州,时间变量为year的面板数据。
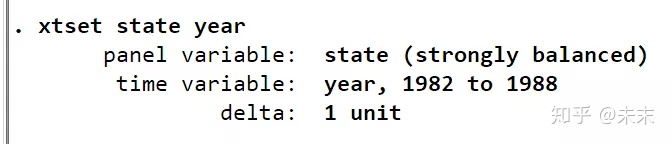
观察输出结果,由strongly balance可知,这是一个平衡面板数据。
至此,我们可以知道,“traffic”数据集是一个48个州,1982-1988年的平衡面板数据集。
第二步 描述性统计作图
1、描述性统计
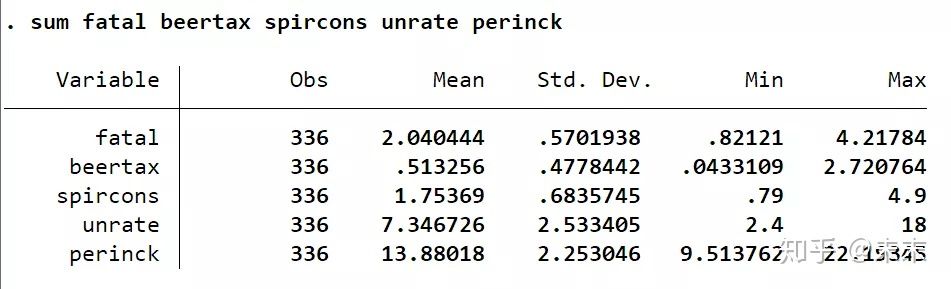
使用命令【sum 关键变量】可以得到关键变量的描述性统计表。
在Stata中输入命令【sum fatal beertax spircons unrate perinck】,我们可以得到解释变量与被解释变量的观测值、均值、标准差、最小值和最大值。
2、绘制散点图及回归直线
在回归之前,我们可以先画出核心变量与别解释变量的散点图及回归直线,来预先判定一下核心变量与被解释变量之间的关系。
使用命令【twoway(scatter fatal beertac)(lfit fatal beertax)】即可画出核心变量“fatal”与被解释变量“beertax”的散点图及回归直线。
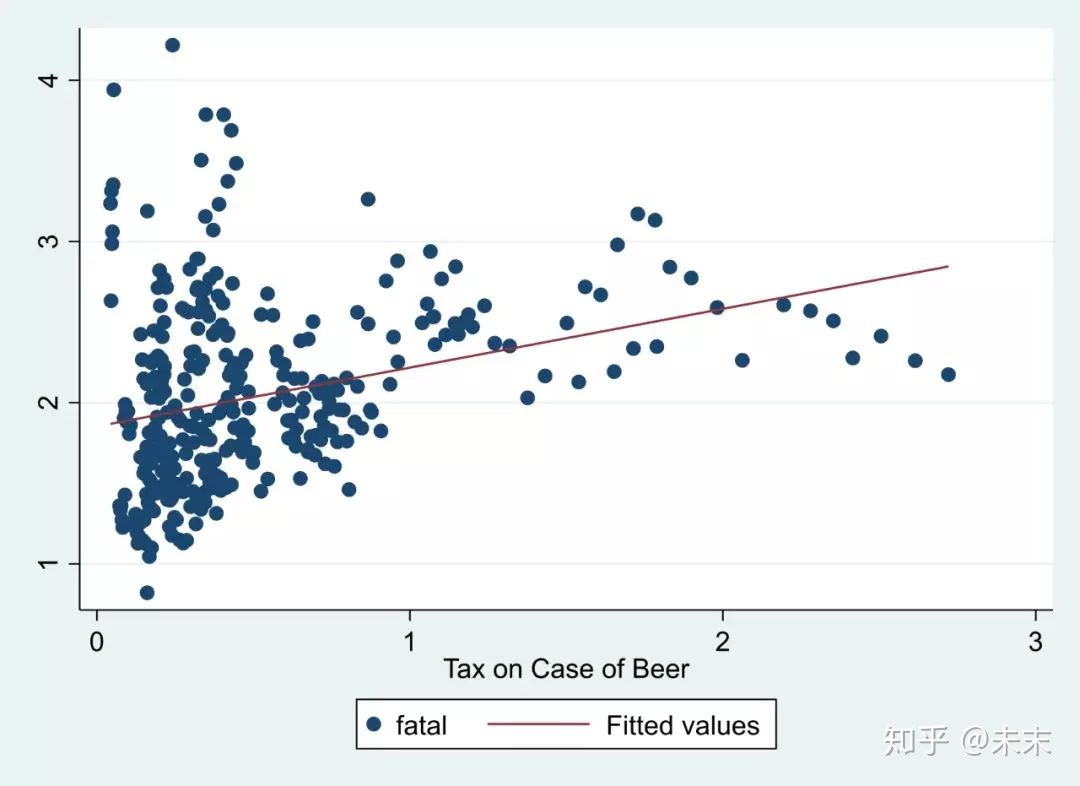
需要注意的是,严格意义上说,这样做并不是正确的,因为并没有控制核心变量之外的其他影响因素。
正确的做法应该是,在控制其他变量的基础上,展示核心变量与被解释变量的偏相关图。
首先,我们需要使用【reg】命令做出回归结果;
然后,使用命令【avplot 核心变量】即可得到核心变量与被解释变量的偏相关图。
#首次使用avplot的同学,要记得通过命令【search avplot】先安装avplot。
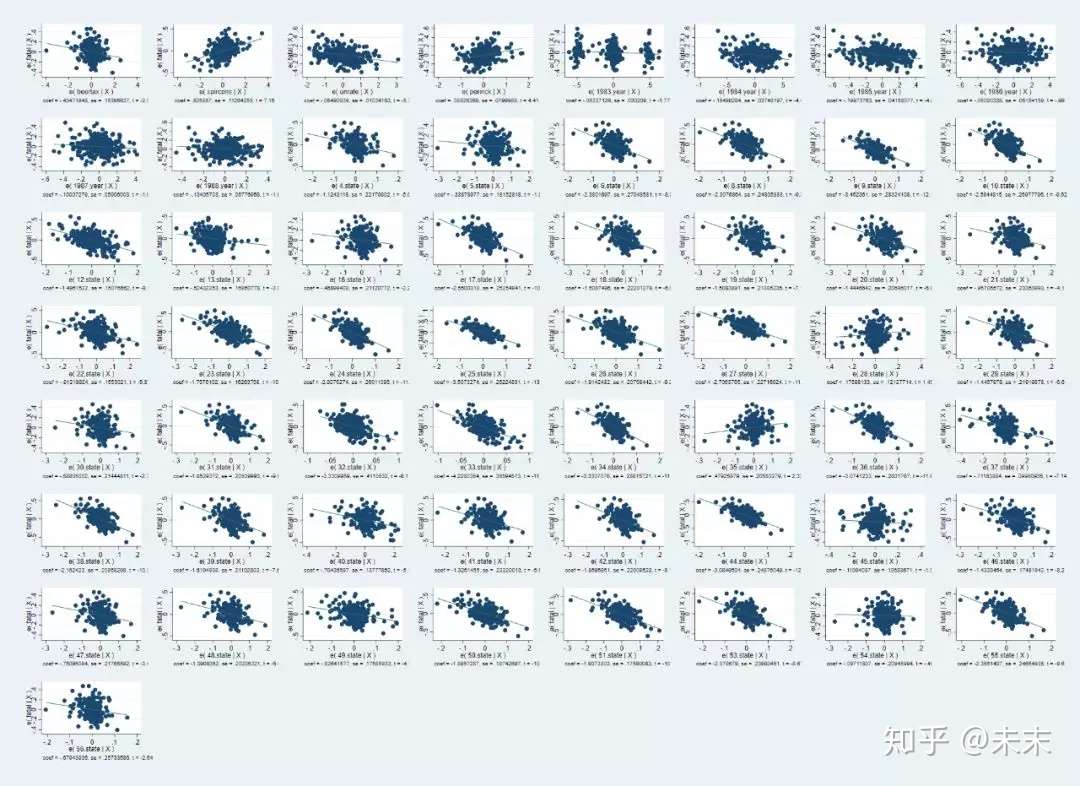
如果直接使用命令【avplots】则会得到所有的变量与被解释变量的偏相关图。
在Stata的“命令窗口”中先输入命令【reg fatal beertax spircons unrate perinck i.year i.state】进行LSDV估计。
然后,输入命令【avplot beertax】

输入命令【avplots】得到所有的变量与被解释变量的偏相关图。
3、绘制核心变量的时间序列图
使用命令【xtline 核心变量】可以做出核心变量在每个截面变量的时间序列图,以研究分析核心变量在每个截面变量中的变动趋势。
在Stata“命令窗口”中输入命令【xtline fatal】即可得到核心变量交通死亡率“fatal”在各个州的时间序列图。

第三步 模型选择
对于固定效应模型、随机效应模型和混合回归模型这三个模型,在实际应用中我们应该选择哪一个模型呢?
一般来说,在学术研究中我们选择双向固定效应模型就可以了。
但是,为了严谨,我们还是应该对三个模型进行比较选择,以判断哪一个模型是匹配数据集的最合适的模型。
1、比较混合回归模型和固定效应模型
首先,我们使用命令【tab year,gen(year)】生成年份虚拟变量;
然后,通过命令【xtreg fatal beertax spircons unrate perinck year2-year7 ,fe】估计双向固定效应模型。
使用命令“xtreg,fe”,在输出结果中我们会得到一个F检验的结果,其原假设为 H 0 : a l l μ i = 0 H_0:all~ \mu_i = 0 H0:all μi=0这意味着,如果接受原假设,就选择混合回归模型;如果拒绝原假设,则选择固定效应模型。
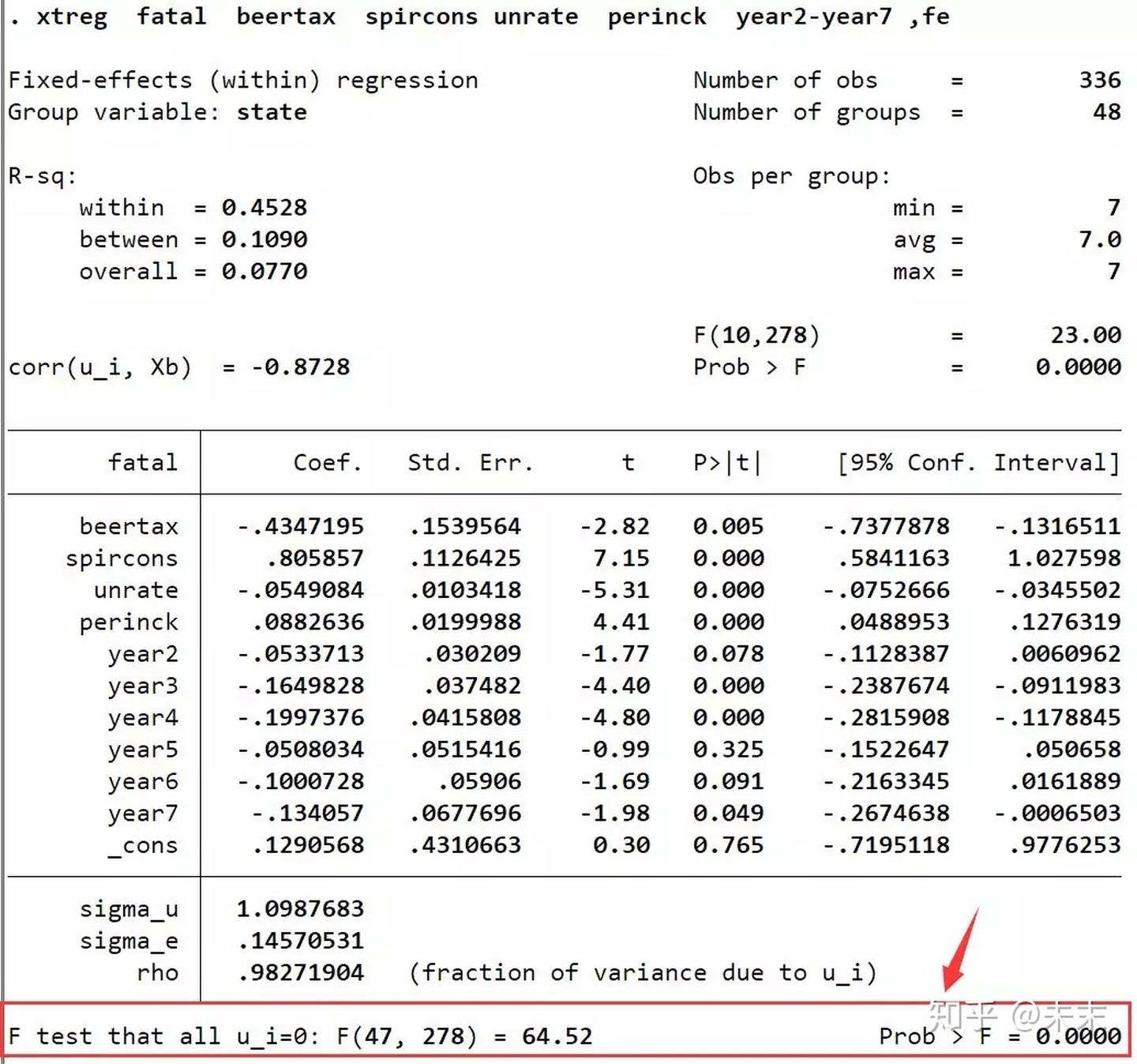
由输出结果可知,F检验对应的P值远小于0.01,那么,这是否就意味着我们可以拒绝原假设,选择固定效应模型呢?
答案是否定的,原因是误差项可能存在自相关、异方差和截面相关这三大问题,如果不对这三大问题进行处理,那么F检验的结果可能就不可靠。
三大问题检验
a.一般来说,先检验截面相关问题
我们可以使用命令【xtcsd】来检验截面相关问题。
#首次使用xtcsdt的同学,需要通过命令【ssc install xtcsd】来安装xtcsd。
“xtcsd”有三个选项,分别为:pes、fri、fre,每个选项都有其使用的前提
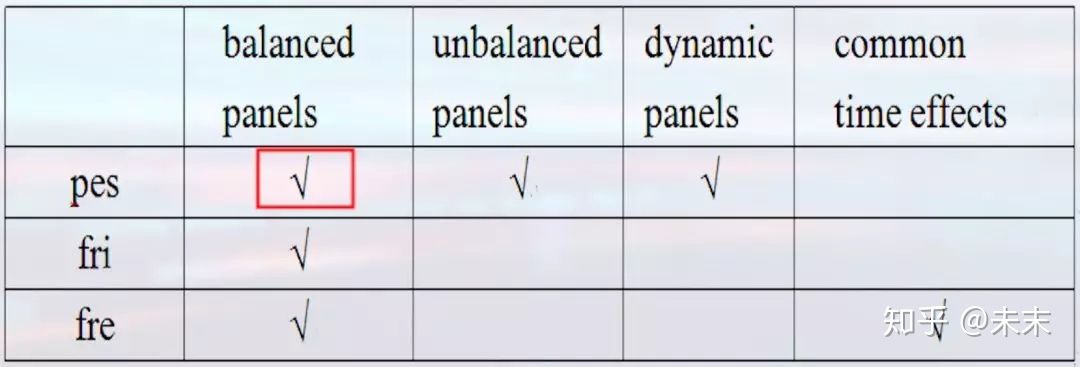
#“xtcsd”命令只可在固定效应模型或随机效应模型估计之后,才可运行
【xtcsd,pes】可以用于平衡面板、非平衡面板以及动态面板;
【xtcsd,fri】只可用于平衡面板;
【xtcsd,fre】可以用于平衡面板,但fre同时考虑了时间效应。
结合案例,我们使用的数据是平衡面板数据,而使用的模型控制了时间效应,所以我们选择命令【xtcsd,fre】

由检验结果可知,因为1.068大于百分之10所对应的临界值0.3583,所以拒绝不存在截面相关的原假设,即认为模型存在截面相关问题。
所以,我们使用之前之前介绍的“xtscc”命令来处理截面相关问题,然后再进行个体效应是否存在的检验。
#首次使用xtscc的同学,需要通过命令【ssc install xtscc】来安装xtscc。
在Stata中输入命令【xi:xtscc fatal beertax spircons unrate perinck year2-year7 i.state】
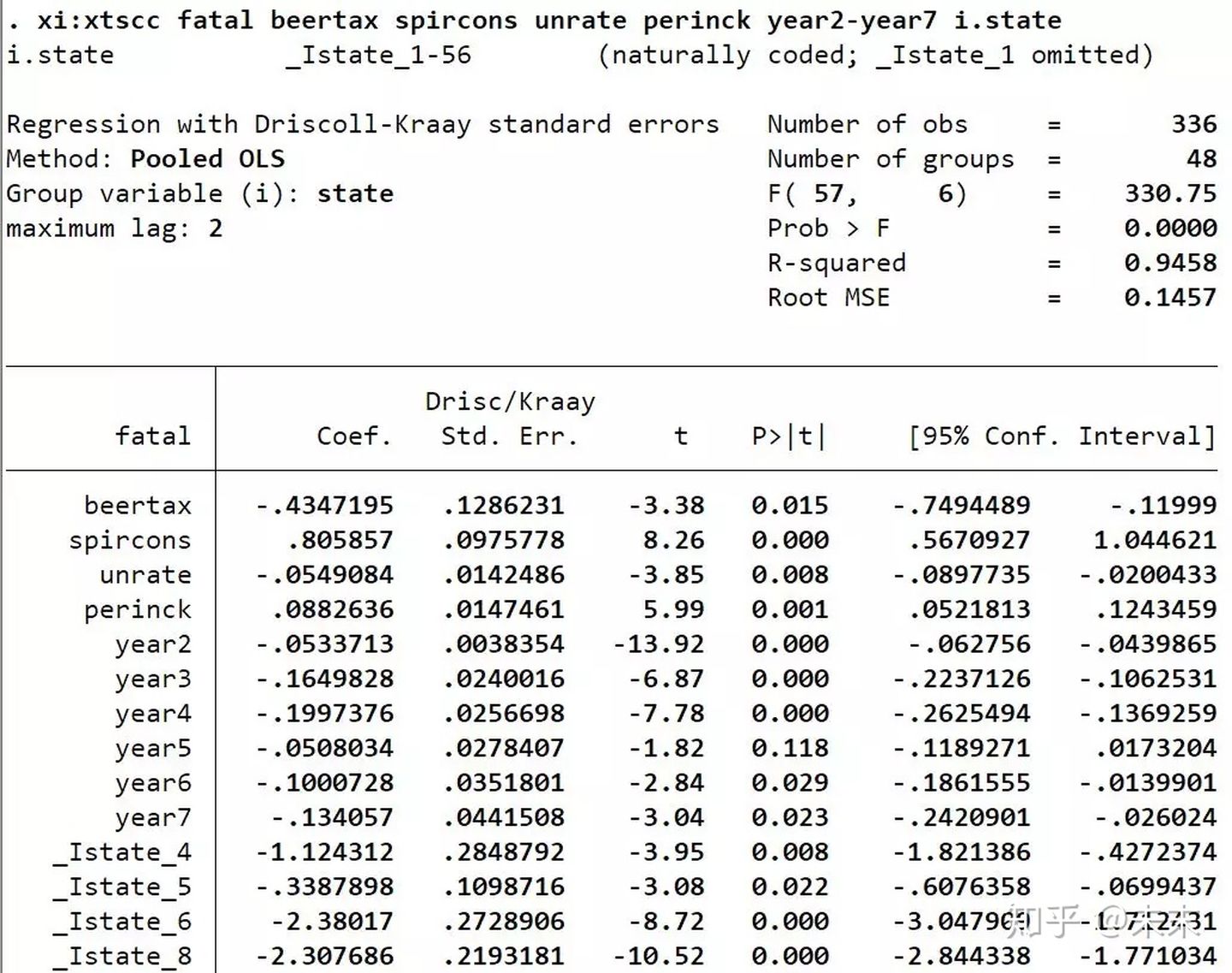
然后,使用命令【testparm _Istate*】对州虚拟变量做F检验
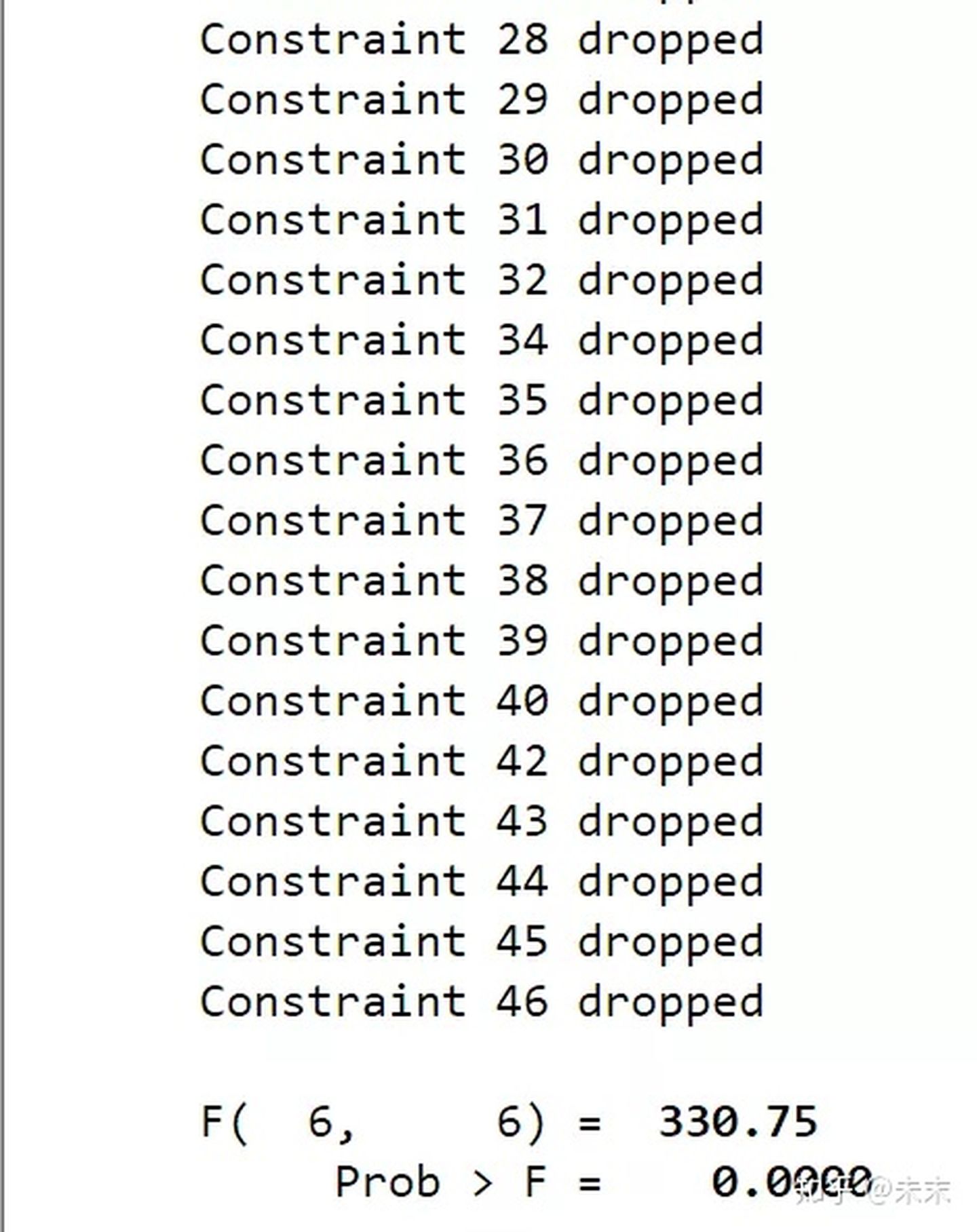
检验结果显示,P值远小于0.1,可以拒绝原假设,认为存在个体效应,所以选择固定效应模型。
b.如果不存在截面相关问题,假定存在异方差和自相关
如果不存在截面相关问题,假定存在异方差和自相关,则使用命令【xi:reg fatal beertax spircons unrate perinck year2-year7 i.state,cluster(state)】
这个命令使用聚类到州获得标准误来处理自相关和异方差问题。
然后,再使用命令【testparm _Istate*】对州虚拟变量进行F检验
2、比较混合回归模型和随机效应模型
Breusch 和Pagan在1980年提出了一个检验个体效应的LM检验。
其原假设为 H 0 : σ μ 2 = 0 H_{0}: \sigma_{\mu}^{2}=0 H0:σμ2=0 ,备择假设为 H 1 : σ μ 2 ≠ 0 H_{1}: \sigma_{\mu}^{2} \neq 0 H1:σμ2=0 。
如果拒绝原假设,就选择随机效应模型;如果接受原假设,则选择混合回归模型。
Stata的检验命令为【xttest0】或者【xttest1】
#首次使用xttest0/xttest1的同学,需要通过命令【findit xttest0/findit xttest1】来安装命令。
首先,使用随机效应模型进行估计。在Stata“命令窗口”中输入命令
【xtreg fatal beertax spircons unrate perinck year2-year7,re】
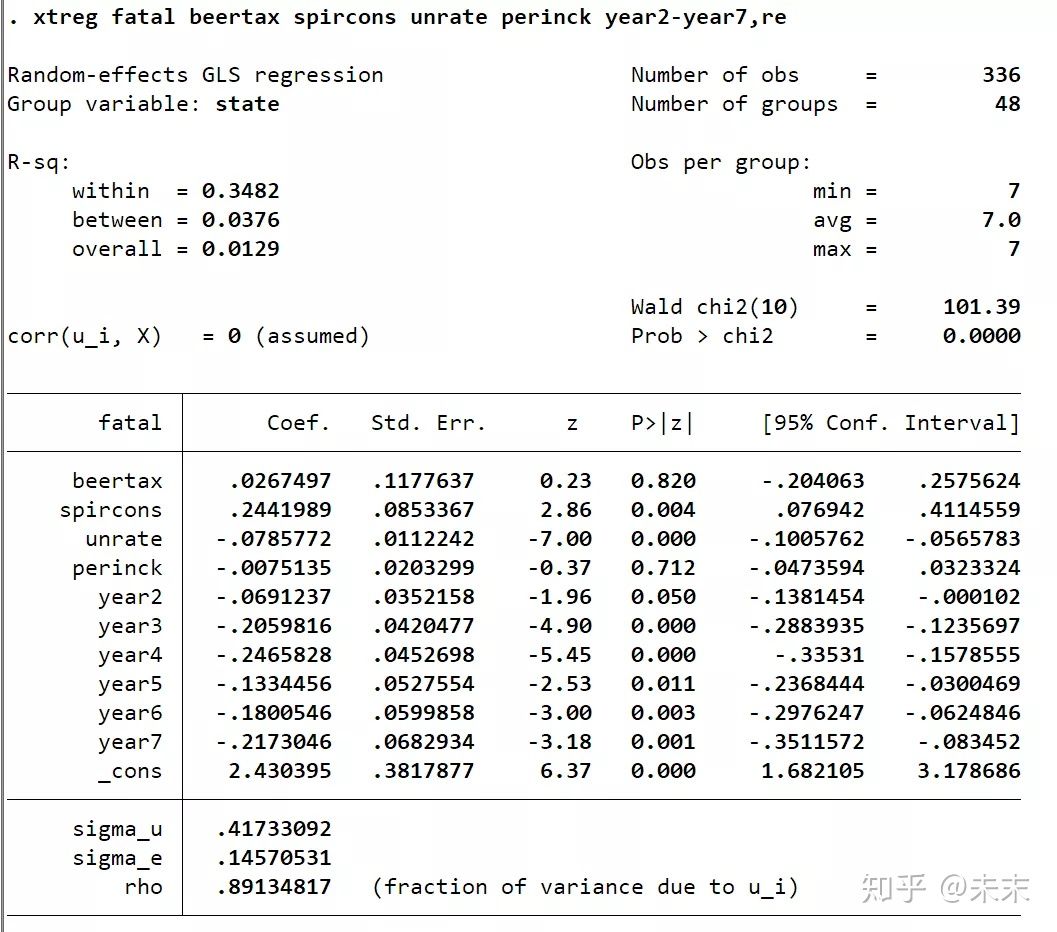
然后,输入命令【xtteat0】
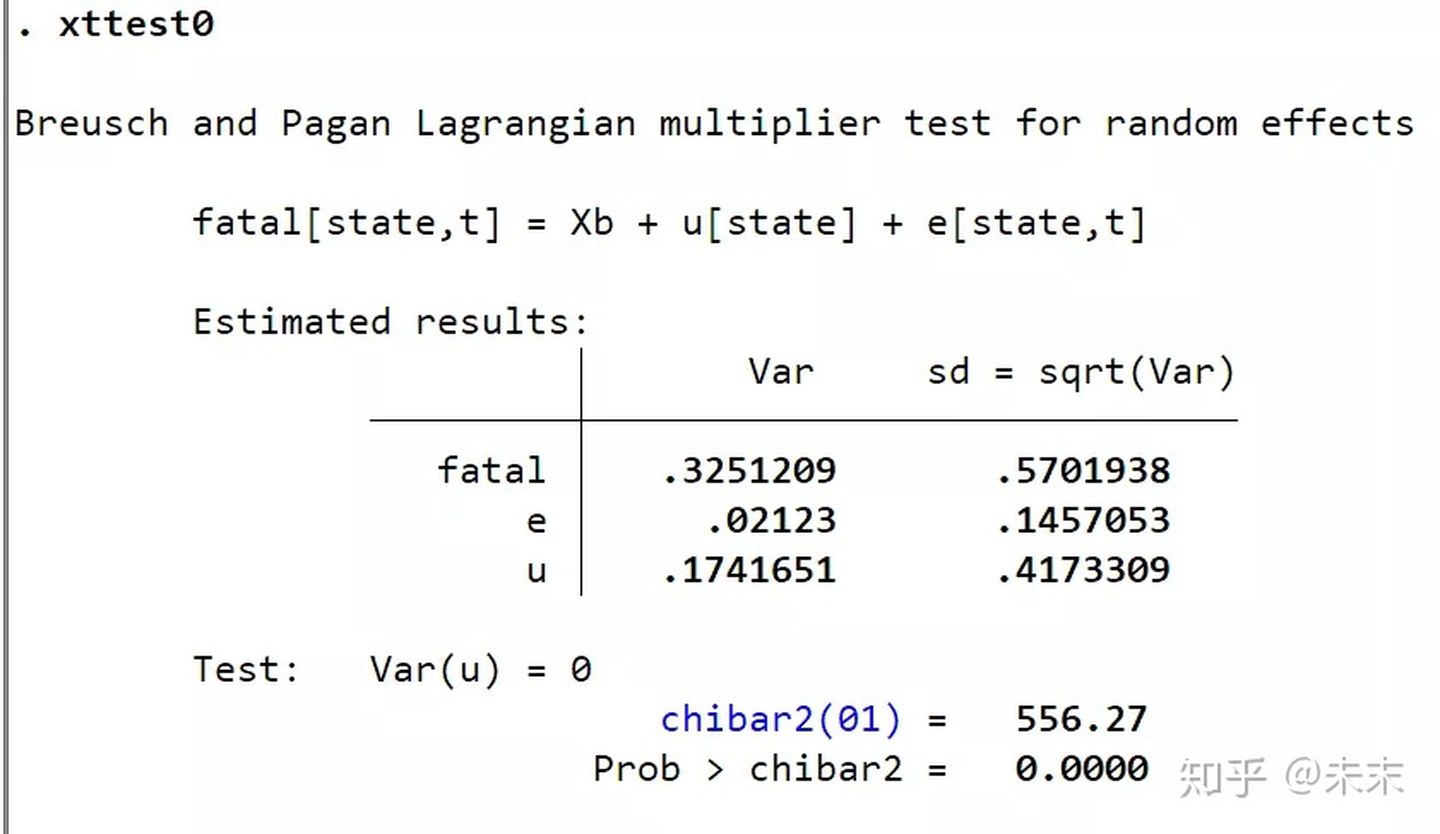
从检验结果,我们可以看到,P值为0,小于显著性水平0.01,所以在0.01的显著性水平下拒绝原假设,选择随机效应模型。
如果误差项存在自相关,使用命令【xttest1】检验随机效应更好。
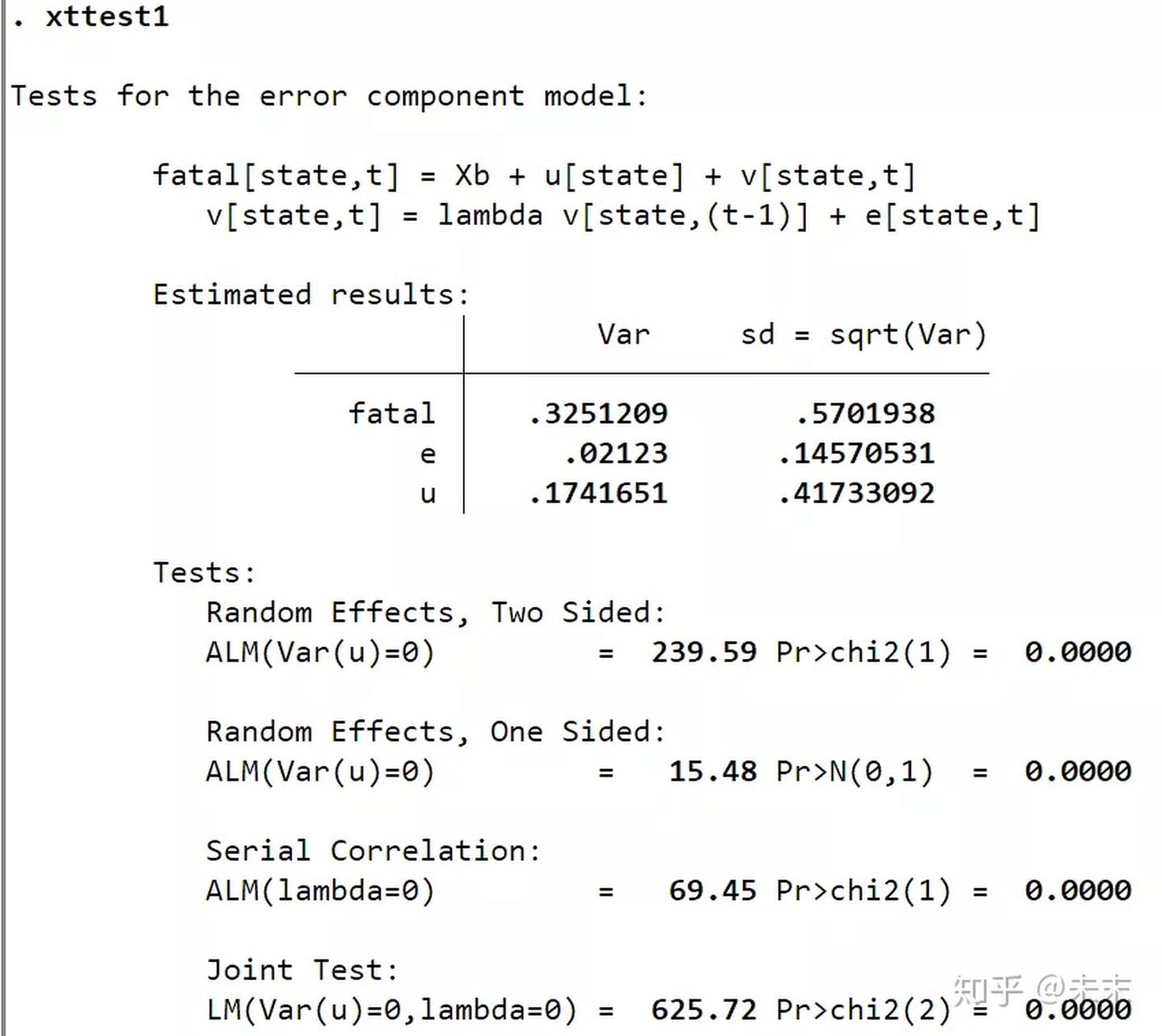
由输出结果可知:Random Effects给出了随机效应自相关的检验结果,由结果可知,随机效应存在一阶自相关问题;Serial Effects给出了误差项的自相关检验结果,检验结果的P值为0,小于0.01,所以在0.01的显著性水平下拒绝原假设,即误差项存在一阶自相关问题;LM检验结果显示应拒绝原假设,即选择随机效应模型。
3、比较固定效应模型和随机效应模型
通常使用Hausman检验进行比较。
Hausman检验的基本思想是:
如果 Cov ( α i , X i t ) = 0 \operatorname{Cov}\left(\alpha_{i}, X_{i t}\right)=0 Cov(αi,Xit)=0 ,那么固定效应模型和随机效应模型的估计都是一致的,但是随机效 应模型更加有效;
如果 Cov ( α i , X i t ) ≠ 0 \operatorname{Cov}\left(\alpha_{i}, X_{i t}\right) \neq 0 Cov(αi,Xit)=0 ,固定效应模型仍然一致,但随机效应模型是有偏的。
所以,如果原假设成立,则固定效应模型与随机效应模型将共同收敛于真实的参数值;反之,两者的差距过大,则倾向于拒绝原假设,选择固定效应模型。
Hausman检验有四行命令(不考虑异方差和截面相关)
称为:Hausman test1
#以“traffic”数据集为例
【xtreg fatal beertax spircons unrate perinck year2-year7,fe】#做固定效应估计
【est store FE】#存储固定效应估计的结果
【xtreg fatal beertax spircons unrate perinck year2-year7,re】#做随机效应估计
【hausman FE, constant sigmamore】/【hausman FE, constant sigmaless】#将两个估计结果进行比较;constant代表masi距离中常数项的估计量;sigmamore利用有效估计量方差,即re;sigmaless利用一致估计量方差,即fe。
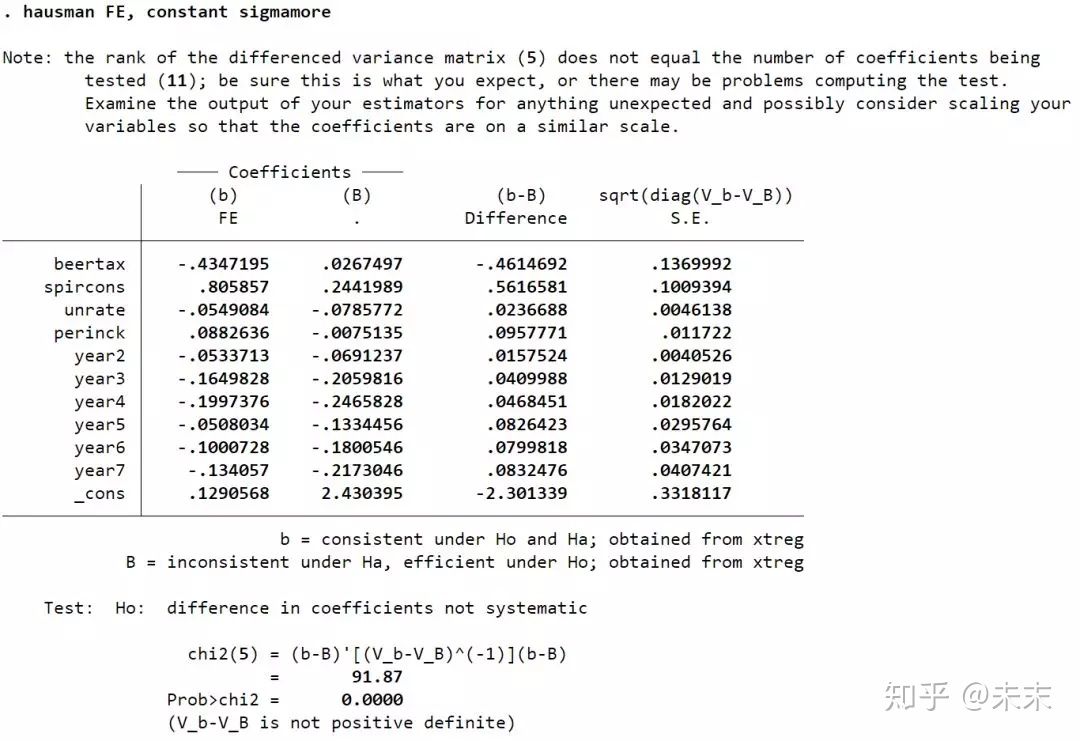
由结果可知,检验结果的P值为0,小于0.01,所以在0.01的显著性水平下拒绝原假设,选择固定效应模型。
需要注意的是:Hausman test1并不适合于异方差问题。
解决办法是:构造一个辅助回归。
y i t − θ ^ ⋅ y ˉ i = ( x i t − θ ^ ⋅ x ˉ i ) ′ β + ( 1 − θ ^ ) z ′ i δ + ( x i t − x ˉ i ) ′ γ + [ ( 1 − θ ^ ) μ i + ( ε i t − θ ^ ε ˉ i ) ] y_{i t}-\hat{\theta} \cdot \bar{y}_{i}=\left(x_{i t}-\hat{\theta} \cdot \bar{x}_{i}\right)^{\prime} \beta+(1-\hat{\theta}) z^{\prime}{ }_{i} \delta+\left(x_{i t}-\bar{x}_{i}\right)^{\prime} \gamma+\left[(1-\hat{\theta}) \mu_{i}+\left(\varepsilon_{i t}-\hat{\theta} \bar{\varepsilon}_{i}\right)\right] yit−θ^⋅yˉi=(xit−θ^⋅xˉi)′β+(1−θ^)z′iδ+(xit−xˉi)′γ+[(1−θ^)μi+(εit−θ^εˉi)]
这个辅助回归是在随机效应模型广义离差变换的基础上,加入一个解释变量的组内离差 ( x i t − x ˉ i ) \left(x_{i t}-\bar{x}_{i}\right) (xit−xˉi) 。
这个辅助回归的基本思想是:
(1) 如果 γ = 0 \gamma=0 γ=0 , 这和辅助回归方程就等价于随机效应的广义离差变换模型。如果随机效应模 型成立,则ols估计是一致的,所以 p lim n → ∞ γ ^ = γ = 0 p \lim _{n \rightarrow \infty} \hat{\gamma}=\gamma=0 plimn→∞γ^=γ=0 。
(2) 如果固定效应模型成立,由于扰动项 [ ( 1 − θ ^ ) μ i + ( ε i t − θ ^ ε ˉ i ) ] \left[(1-\hat{\theta}) \mu_{i}+\left(\varepsilon_{i t}-\hat{\theta} \bar{\varepsilon}_{i}\right)\right] [(1−θ^)μi+(εit−θ^εˉi)] 与 ( x i t − x ˉ i ) \left(x_{i t}-\bar{x}_{i}\right) (xit−xˉi) 相 关,所以,ols估计是不一致的,即 p lim n → ∞ γ ^ = γ ′ ≠ γ = 0 p \lim _{n \rightarrow \infty} \hat{\gamma}=\gamma^{\prime} \neq \gamma=0 plimn→∞γ^=γ′=γ=0 。
#因此,拒绝 H 0 : γ = 0 H_{0}: \gamma=0 H0:γ=0 ,意味着拒绝随机效应接受固定效应。
(3)使用聚类稳健标准误处理异方差问题后,再检验假设 H 0 : γ = 0 H_{0}: \gamma=0 H0:γ=0 。如果拒绝原假设,则 选择固定效应; 反之,则选择随机效应。
实现程序:Hausman test2
【quietly xtreg fatal beertax spircons unrate perinck year2-year7,re】
#做随机效应估计,"quietly"表示正常执行"xtreg"命令但不输出估计结果
【scalar theta=e(theta)】#得到广义离差中参数 的估计
【global yandxforhausman fatal beertax spircons unrate perinck year2 year3 year4 year5 year6 year7 】
#表示第一行命令中的所有变量,global是全局宏
【sort state】#依据state进行排序
【foreach x of varlist $yandxforhausman{
by state:egen meanx'=mean(x’)
gen mdx'=x’-mean`x’
gen redx'=x’-theta*mean`x’
}】
#"foreach"为循环语句,对变量名单上的所有 进行同样的操作。
【quietly reg redfatal redbeertax redspircons redunrate redperinck redyear2 redyear3 redyear4 redyear5 redyear6 redyear7 mdbeertax mdspircons mdunrate mdperinck mdyear2 mdyear3 mdyear4 mdyear5 mdyear6 mdyear7, vce(cluster state)】
#用"reg"命令做辅助回归,"vce(cluster state)"处理异方差
【test mdbeertax mdspircons mdunrate mdperinck mdyear2 mdyear3 mdyear4 mdyear5 mdyear6 mdyear7】
#使用"test"命令对所有的解释变量的组内离差进行联合显著性检验
在Stata中执行Hausman test2的命令
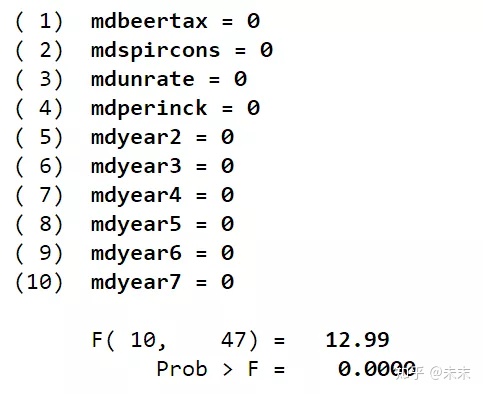
由检验结果可知,F检验的P值为0,小于0.01,所以在0.01的显著性水平下拒绝原假设,采用固定效应模型。
Hausman teat2解决了误差项存在异方差的问题,那么如果误差项存在截面相关,又该怎么办呢?
我们采用命令Hausman test3解决误差项截面相关的问题。
基于随机效应模型估计的截面相关检验
首先,因为我们构造的模型考虑了时间效应,所以通过命令【xtcsd,fre】检验误差项是否存在截面相关的问题。
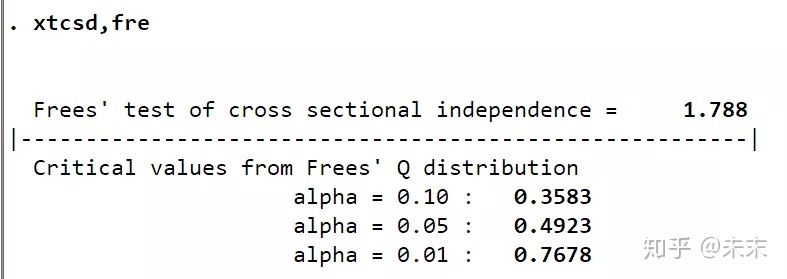
由检验结果可知,1.788大于0.01显著性水平所对应的值0.7678,所以在0.01的显著性水平下拒绝原假设,认为随机效应模型的误差项存在截面相关问题,需要进行处理。
实现程序:Hausman test3(适用于异方差和截面相关的情形)
Hausman test3只需将Hausman test2命令中的第六步进行辅助回归的代码中的"reg"命令改为"xtscc"命令即可。
【quietly xtscc redfatal redbeertax redspircons redunrate redperinck redyear2
redyear3 redyear4 redyear5 redyear6 redyear7 mdbeertax mdspircons
mdunrate mdperinck mdyear2 mdyear3 mdyear4 mdyear5 mdyear6 mdyear7】
使用"test"命令对所有的假设变量的组内离差进行联合显著性检验。
【test mdbeertax mdspircons mdunrate mdperinck mdyear2 mdyear3 mdyear4 mdyear5 mdyear6 mdyear7】
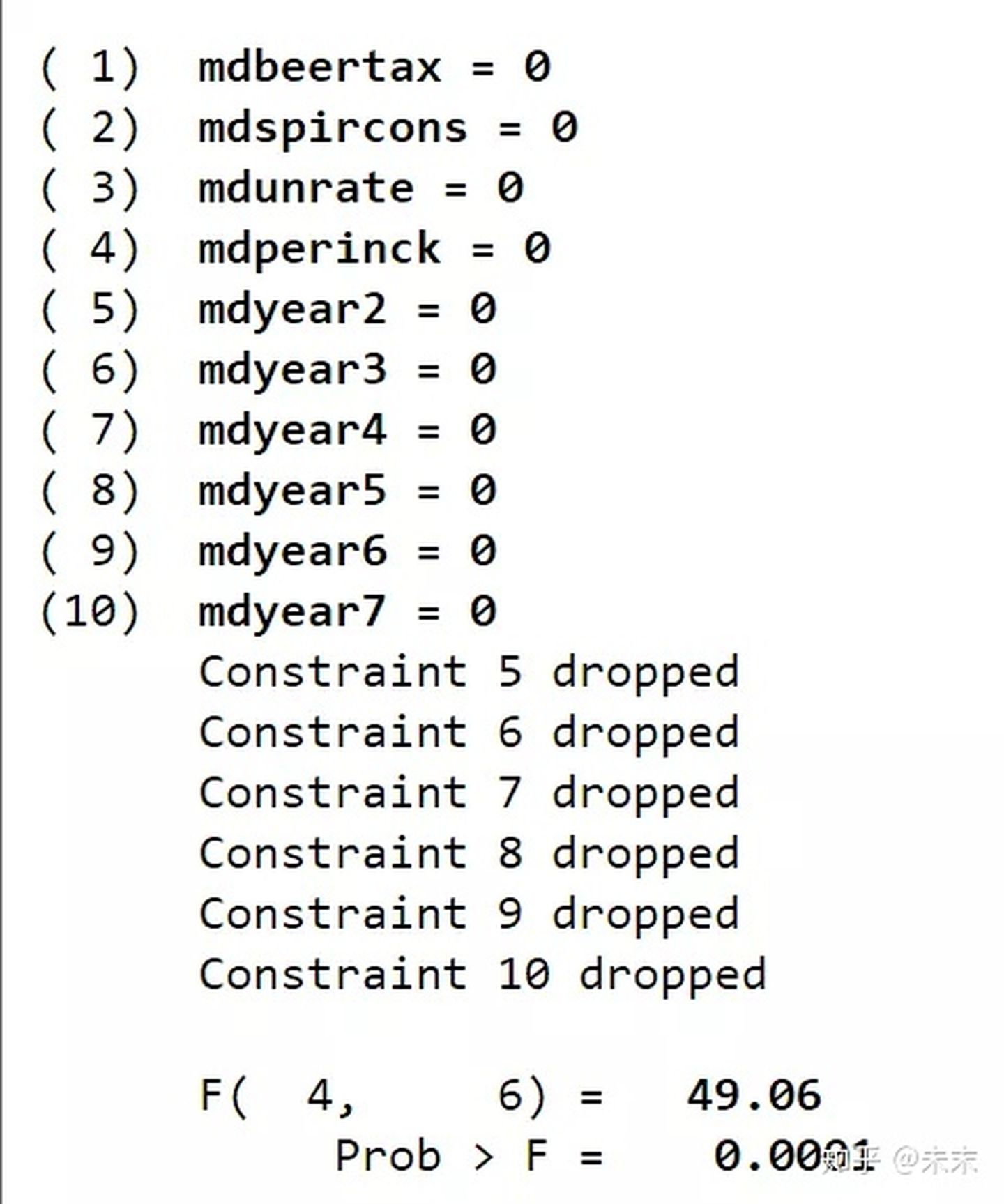
检验结果的P值为0.0001,同样拒绝原假设,所以选择固定效应模型。
第四步 报告计量结果
通过第三步模型的选择,我们最终确定了固定效应模型,所以报告固定效应模型的结果,同时我们要解决误差项可能存在的自相关、异方差和截面相关问题。
在第三步中,通过命令"xtcsd"我们识别到了误差项存在截面相关的问题;
接下来,我们检验模型异方差问题是否存在。
检验步骤为:
首先,我们做双向固定效应估计。
使用命令【xtreg fatal beertax spircons unrate perinck year2-year7,fe】
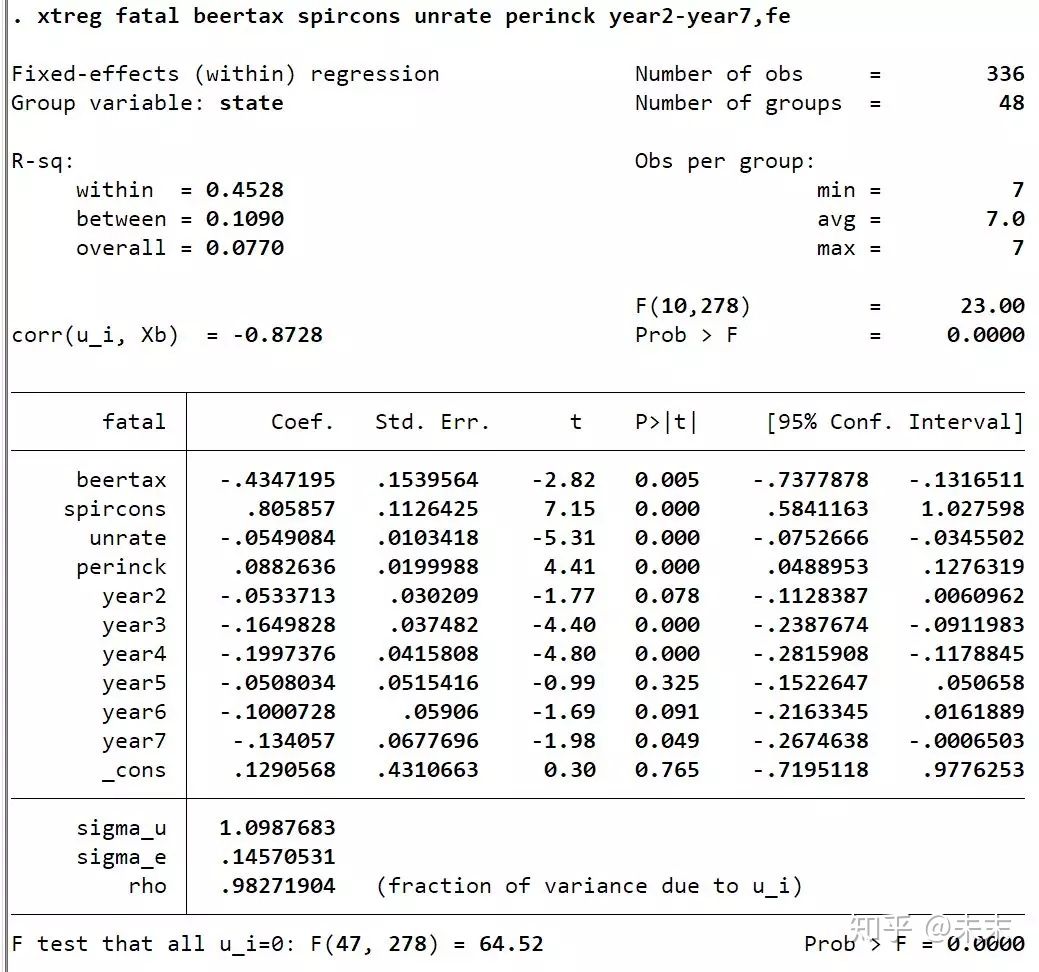
然后,我们运行【xttest3】命令
#【xttest3】只能在"xtreg,fe"或"xtgls"命令之后使用。首次使用【xttest3】的同学需要使用命令【ssc install xttest3】进行安装。

异方差检验结果显示:P值为0,所以拒绝原假设,认为存在异方差问题。
最后,我们检验误差项的自相关问题
通过命令【xtserial】对误差项的自相关问题进行检验。
#首次使用【xtserial】的同学需要使用命令【search xtserial】进行安装。
通过命令【tab state,gen(state)】生成州的虚拟变量
然后执行命令【xtserial fatal beertax spircons unrate perinck state2-state48 year2-year7】

由检验结果可知, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NF6b2moR-1640317583138)(https://gitee.com/zhang-yixin/markdown-drawing-bed/raw/master/img//202111091538948.svg+xml)] ,所以可以认为,在0.01的显著性水平下不拒绝原假设,即认为模型不存在自相关问题
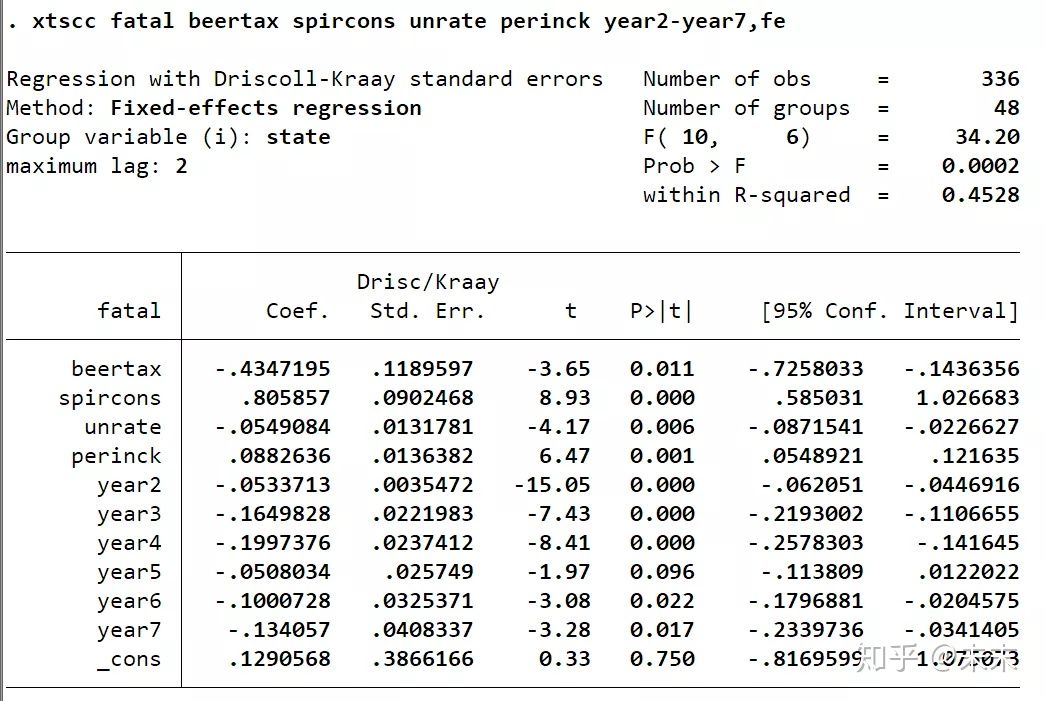
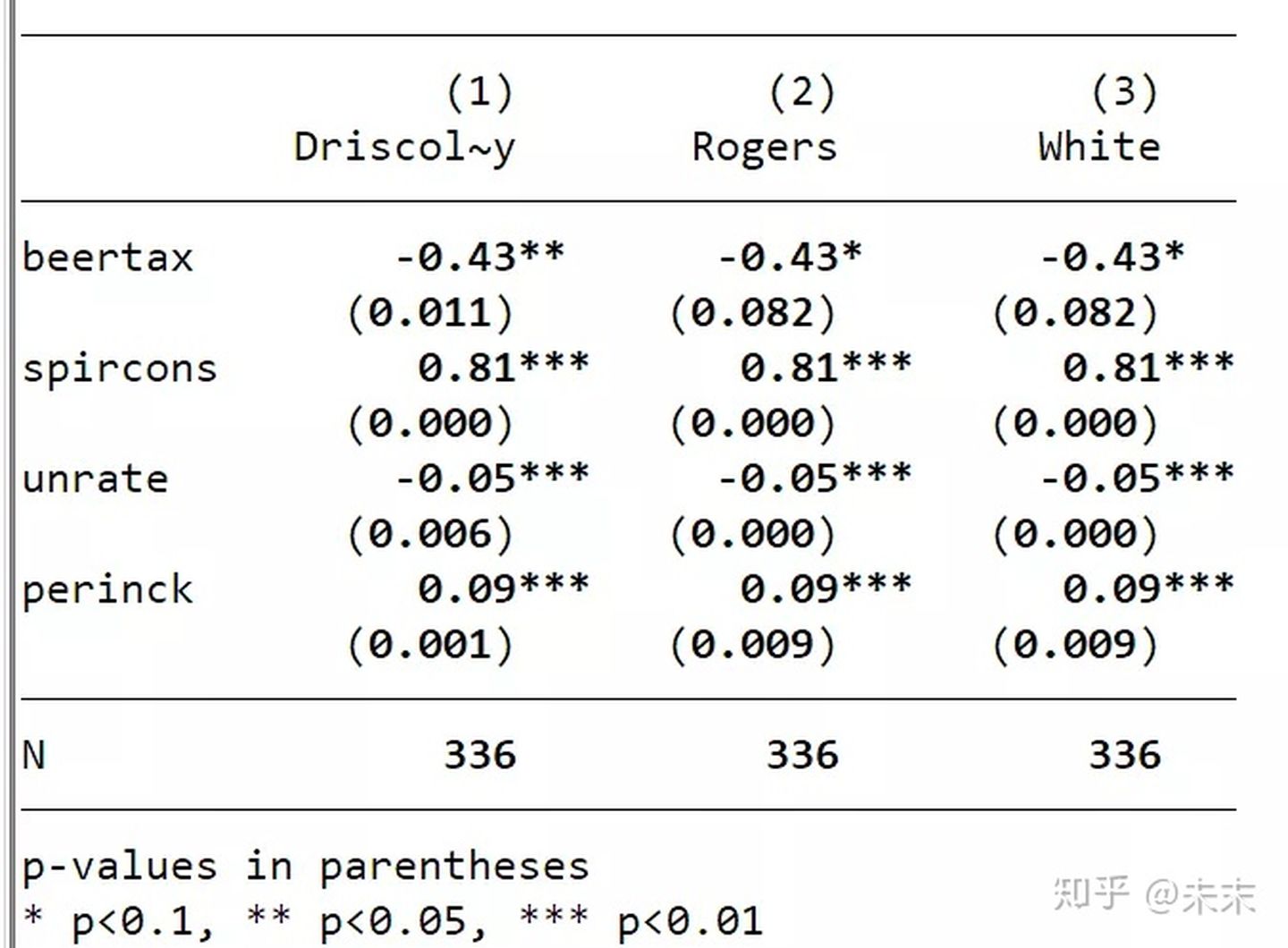
综上,由于存在截面相关和异方差问题,所以我们使用命令"xtscc"进行双向固定效应模型的估计。
使用命令:
【xtscc fatal beertax spircons unrate perinck year2-year7,fe】
【est store Driscoll-Kraay】
其中,标准误是Driscoll-Kraay,估计量是组内估计量。
此外,如果不存在截面相关,一般最终报告由如下命令估计的结果:
【xtreg fatal beertax spircons unrate perinck year2-year7,fe cluster(state)】
【est store Rogers】
其中,标准误是Rogers或聚类稳健标准误
用robust替换cluster(state)选项会得到相同的结果
【xtreg fatal beertax spircons unrate perinck year2-year7,fe robust】
【est store White】
其中,标准误是White标准误或稳健标准误
最后,我们可以通过"esttab"命令将所有的存储结果放在一起比较。
【esttab Driscoll-Kraay Rogers White,b(%9.2f)p mtitle(Driscoll-Kraay Rogers White)obslast star(* 0.1 ** 0.05 *** 0.01)compress nogap k(beertax spircons unrate perinck)】
#首次使用【esttab】的同学需要使用命令【ssc install estout】进行安装。
(三)长面板数据分析
上两篇笔记我们讲到了短面板数据分析。短面板数据分析主要关注对不可观测的个体效应的处理,而对于误差自相关、异方差和截面相关的问题只提供经过校正的标准误。
与短面板数据不同,长面板数据分析主要关注对误差项的处理(因为时间T大),而将个体效应用虚拟变量来控制(因为个体n小)。
所以,对于长面板数据分析,我们不需要在固定效应模型、随机效应模型和混合回归模型之间进行选择,长面板数据分析先验假定长面板数据模型就是固定效应模型。
此外,需要注意的是,短面板数据分析对于时间效应,用虚拟变量来控制,而长面板数据分析,由于时间T相对较长,为避免损失较多的自由度,所以一般则用时间趋势项来控制。
可以认为长面板数据模型是一个特殊的双向固定效应模型。在这个模型中,个体效应用虚拟变量控制,时间效应用时间趋势项控制,长面板数据模型的估计主要关注对误差项的处理。
一、长面板数据模型的估计方法
通常有三种方法对长面板数据模型进行估计。
**第一种:**使用OLS估计这个特殊的双向固定效应模型,并对误差项的自相关、异方差和截面相关的问题只提供面板校正的标准误(使用命令xtscc或xtpcse命令实现),这种估计方法最为稳健。
**第二种:**如果存在自相关、异方差和截面相关的问题,则使用FGLS估计这个特殊的双向固定效应模型,这种方法只是解决了误差项自相关的问题,而并未考虑异方差或截面相关的问题,对于误差项的异方差和截面相关的问题仍然只是提供面板校正的标准误(使用命令xtpcse实现),这种估计方法介于稳健和效率之间。
**第三种:**使用FGLS估计这个特殊的双向固定效应模型,对误差项的自相关、异方差和截面相关的问题一并加以处理(使用命令xtgls实现),这种估计方法最有效率。
二、长面板数据模型的Stata估计命令
常用的估计长面板数据模型的Stata命令有三个:【xtpcse】、【xtgls】和【xtscc】
对于【xtscc】命令,我们在前两篇短面板数据的笔记中已经讲过,【xtscc】也适用于长面板数据分析,它可以实现长面板数据模型的第一种估计方法,对误差项的自相关、异方差和截面相关问题提供面板校正的标准误。
下面,我们讲一下【xtpcse】和【xtgls】估计命令
1、【xtpcse】命令
基本命令格式:
xtpcse depvar indepvars,options
#命令的关键在于选项(options),不同的选项可以处理不同的问题。
对于误差项三大问题【xtpcse】命令选项(options)的使用
(1)自相关问题(一阶自相关)
a.使用选项:corr(ar1),使用的估计方法为FGLS
#误差项存在自相关时使用该选项;当T不比n大很多时使用该选项,因为此时T可能无法提供足够多的信息去估计每个个体的自相关系数,所以约束了每个个体的自相关系数都相等
b.使用选项:corr(psar1),使用的估计方法为FGLS。
#误差项存在自相关时使用该选项;当T比n大很多时使用该选择项,当T比n大很多时每个个体的自相关系数可以不同,就可以使用选项
c.使用选项:corr(independent)或corr(ind),使用的估计方法为OLS。
#误差项不存在自相关时,使用该选项
(2)异方差与截面相关问题
a.使用选项:independent
#误差项不存在异方差和截面相关问题,使用该选项
b.使用选项:hetonly(提供考虑异方差的面板校正标准误)
#误差项存在异方差但不存在截面相关问题,则使用该选项
c.使用选项:不加选项即可(提供既考虑异方差又考虑截面相关的面板校正标准误)
#误差项存在异方差和截面相关问题时,不加任何选项
选项:corr(ind)+independent等价于LSDV
2、【xtgls】命令
基本命令格式:
xtgls depvar indepvars,options
#如果对误差项的处理正确,那么【xtgls】比x【tpcse】估计效果更好
对于误差项三大问题【xtgls】命令选项(options)的使用
(1)自相关问题(一阶自相关)
【xtgls】与【xtpcse】命令的选项对自相关问题的处理是相同的
a.使用选项:corr(ar1),使用的估计方法为FGLS
#误差项存在自相关时使用该选项;当T不比n大很多时使用该选项,因为此时T可能无法提供足够多的信息去估计每个个体的自相关系数,所以约束了每个个体的自相关系数都相等
b.使用选项:corr(psar1),使用的估计方法为FGLS。
#误差项存在自相关时使用该选项;当T比n大很多时使用该选择项,当T比n大很多时每个个体的自相关系数可以不同,就可以使用选项
c.使用选项:corr(independent)或corr(ind),使用的估计方法为OLS。
#误差项不存在自相关时,使用该选项
(2)异方差与截面相关问题
a.使用选项:panels(iid)
#误差项不存在异方差和截面相关,使用该选项
b.使用选项:panles(heteroskedastic)
#误差项存在异方差但不存在截面相关问题时,使用该选项
c.使用选项:panels(correlated)#只适用于长面板数据
#误差项存在异方差和截面相关问题时,使用该选项
选项:corr(ind)+panels(iid)等价于LSDV
三、长面板数据分析的实例操作
#以数据集“mus08cigar.dta”为例估计香烟需求函数,数据来源于慕课上浙江大学方红生教授的面板数据分析与Stata应用课程中。
“mus08cigar.dta”数据集包括了美国10个州1963-1992年有关香烟消费量的相关变量。
参考上一篇文章短面板数据分析的基本程序,我们对长面板数据进行分析。
第一步 模型设定与数据
长面板数据不需要进行模型的选择,我们构造一个双向固定效应模型
ln c i t = β 0 + β 1 ln p i t + β 2 ln p min i t + β 3 ln y i t + μ i + γ t + ε i t \ln c_{i t}=\beta_{0}+\beta_{1} \ln p_{i t}+\beta_{2} \ln p \min _{i t}+\beta_{3} \ln y_{i t}+\mu_{i}+\gamma_{t}+\varepsilon_{i t} lncit=β0+β1lnpit+β2lnpitmin+β3lnyit+μi+γt+εit
其中,被解释变量lnc为人均香烟消费量的对数,解释变量:lnp为实际香烟价格的对数,lnpmin为相邻州最低香烟价格的对数,lny为人均可支配收入的对数。
在Stata软件中对数据进行分析,执行如下步骤:
1、导入数据到Stata中
在Stata的“命令窗口”中输入命令
use"数据集路径\mus08cigar.dta"
将“traffic.dta”数据集导入到Stata中,
例如
use"C:\Users\mus08cigar.dta"
将数据导入Stata后,即可在Stata的“变量窗口”中看到“mus08cigar”数据集中的各个变量的名称及其标签。
2、查看数据
在Stata的“命令窗口”输入命令
des
和命令
xtdes
查看“mus08cigar”数据集。


从输出结果我们可以看到:“mus08cigar”数据集包含300个观测值,6个变量。
面板数据的截面数 ,时间数 , ,说明这是一个长面板数据集。
输入命令
xtset state year
告诉Stata软件,这是一个以截面变量state为州,时间变量为year的面板数据。
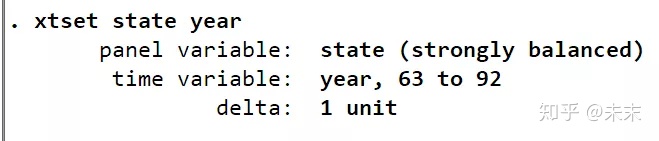
由“strongly balance”可知,这是一个平衡面板数据。
至此,我们可以知道,“mus08cigar”数据集是一个10个州,1963-1992年的长面板数据集且为平衡面板数据集。
第二步 描述性统计作图
1、描述性统计
使用命令【sum 关键变量】可以得到关键变量的描述性统计表。
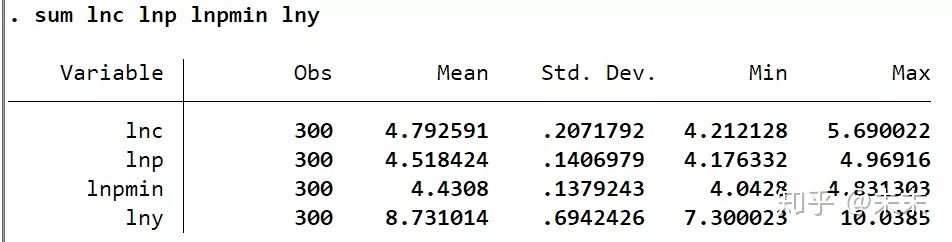
在Stata中输入命令
sum lnc lnp lnpmin lny
得到解释变量与被解释变量的观测值、均值、标准差、最小值和最大值。
2、绘制散点图及回归直线
在回归之前,我们先画出核心变量lnp与被解释变量lnc的散点图及回归直线,来预先观测一下核心变量与被解释变量之间是否存在理论上预期的负相关系。
使用命令
twoway(scatter lnc lnp)(lfit lnc lnp)
画出核心变量“lnp”与被解释变量“lnc”的散点图及回归直线。
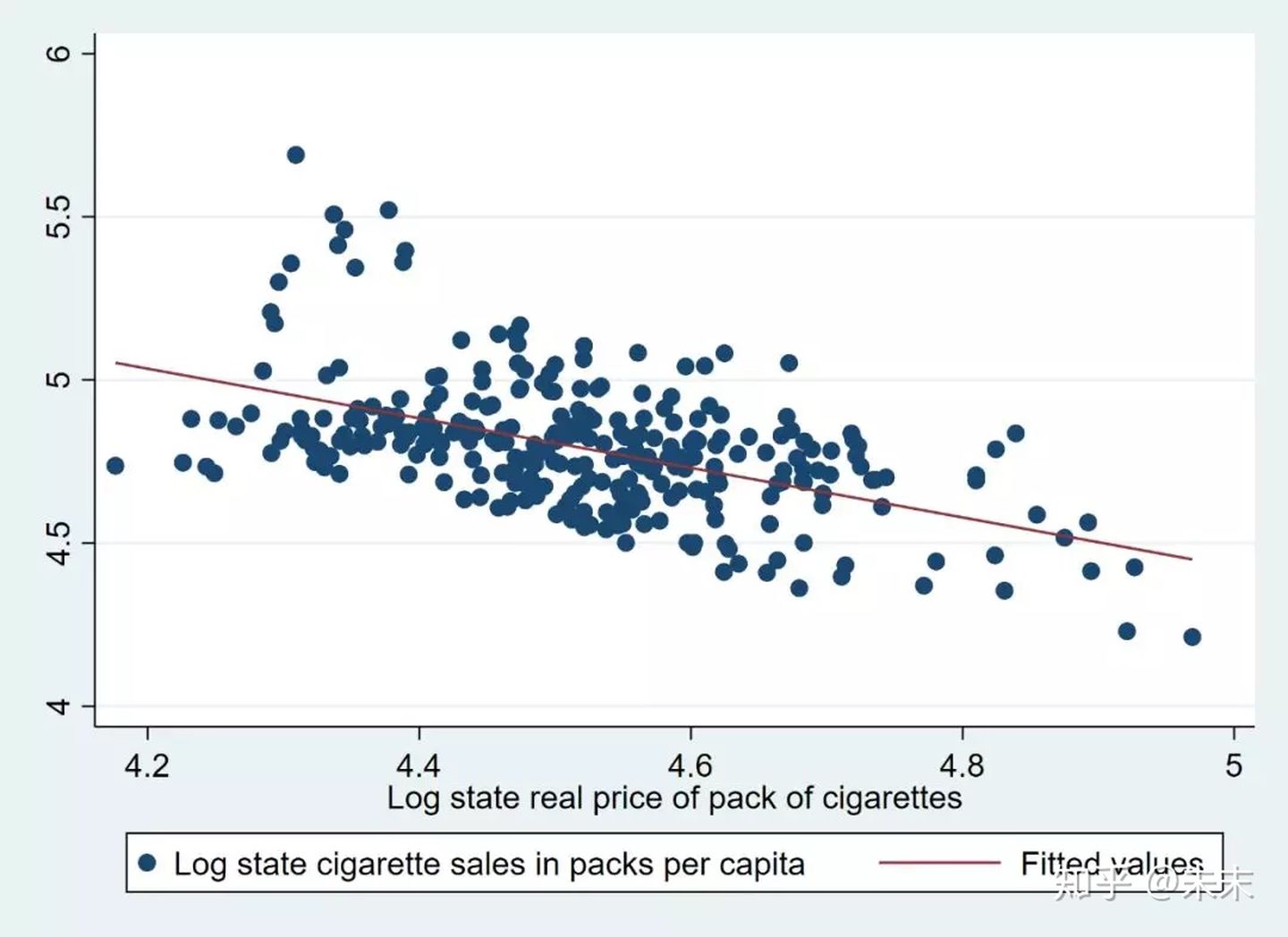
由结果可知,lnp与lnc之间是负相关系的,与理论预期一致。
接下来,我们做出相邻州的香烟价格的对数与被解释变量的散点图及回归直线,看一下核心变量lnpmin与被解释变量lnc之间是否存在理论上预期的正相关系。使用命令
twoway(scatter lnc lnpmin)(lfit lnc lnpmin)
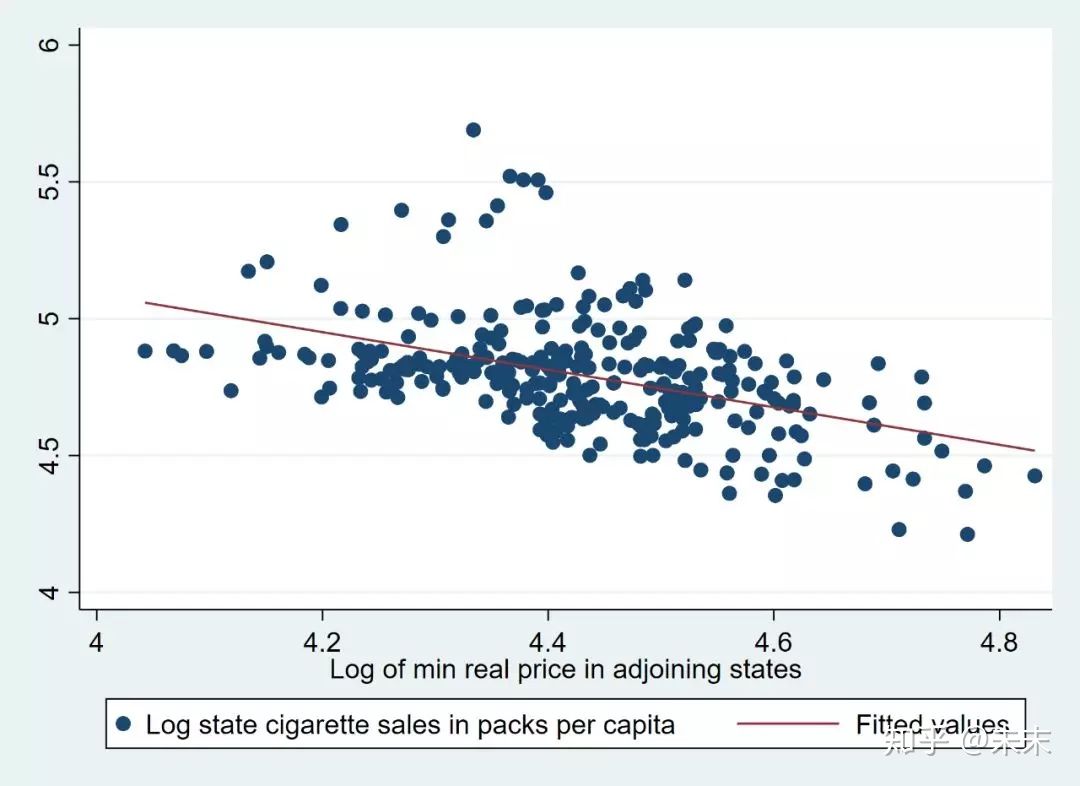
由结果可知,相邻州的香烟价格的对数lnpmin与被解释变量lnc之间是正相关系的,这与我们的理论预期并不符合。
不过,因为我们并没有控制其他的影响因素,所以这个结果并不是完全正确的,在之后的操作中,我们可以使用命令【avplot】绘制变量之间的偏相关图。
3、绘制核心变量的时间序列图
使用命令
xtline lnc
做出核心变量人均香烟消费的对数lnc在各个州的时间序列图,以研究分析人均香烟消费的对数lnc在每个州中的变动趋势。
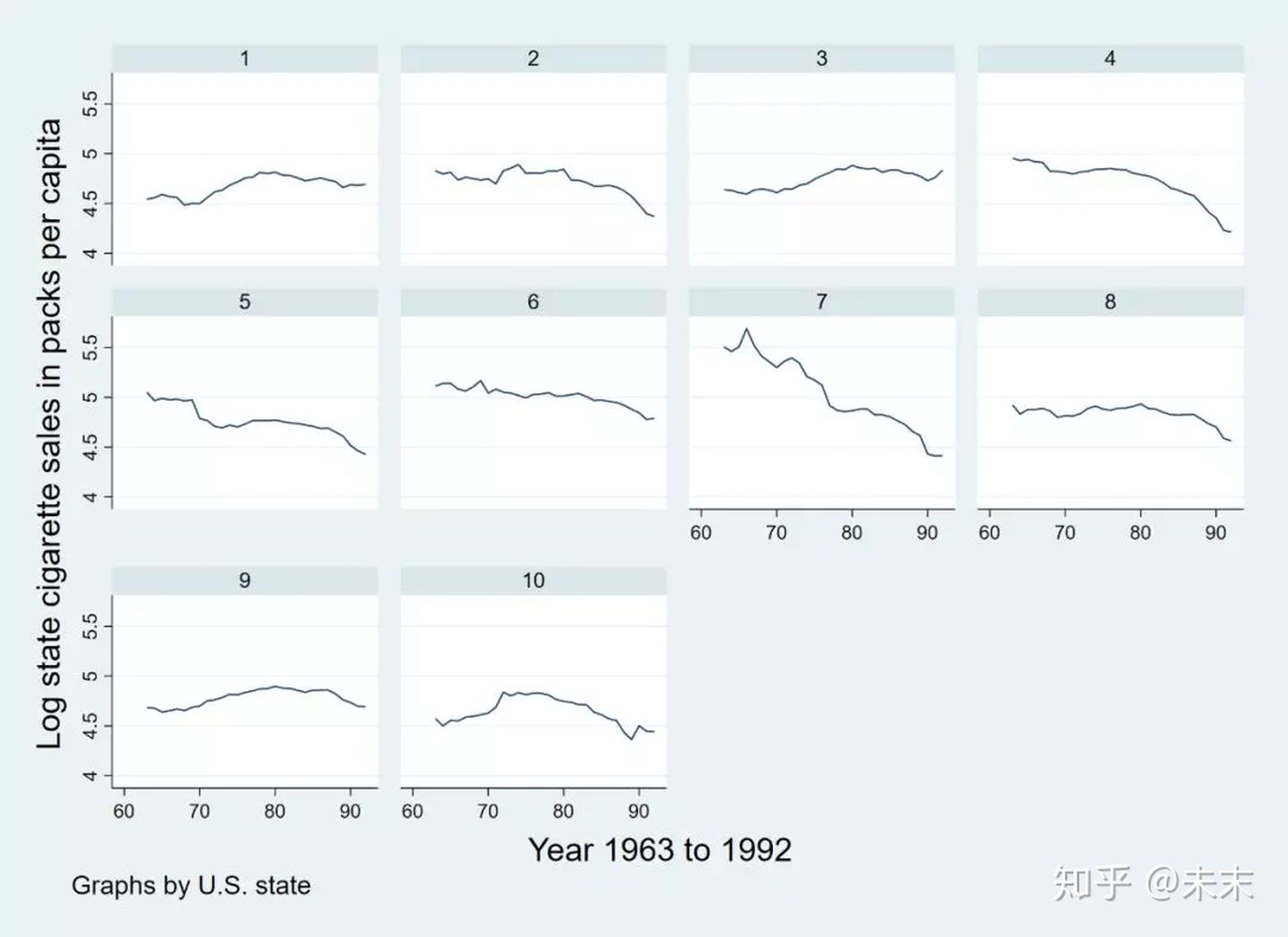
观察lnc在各个州的时序图,我们可以发现,1980年之后,所有州的人均香烟消费率基本都呈现出下降趋势。
使用命令
xtline lnp
做出美国10个州1963-1992年实际香烟价格对数的时间序列图。
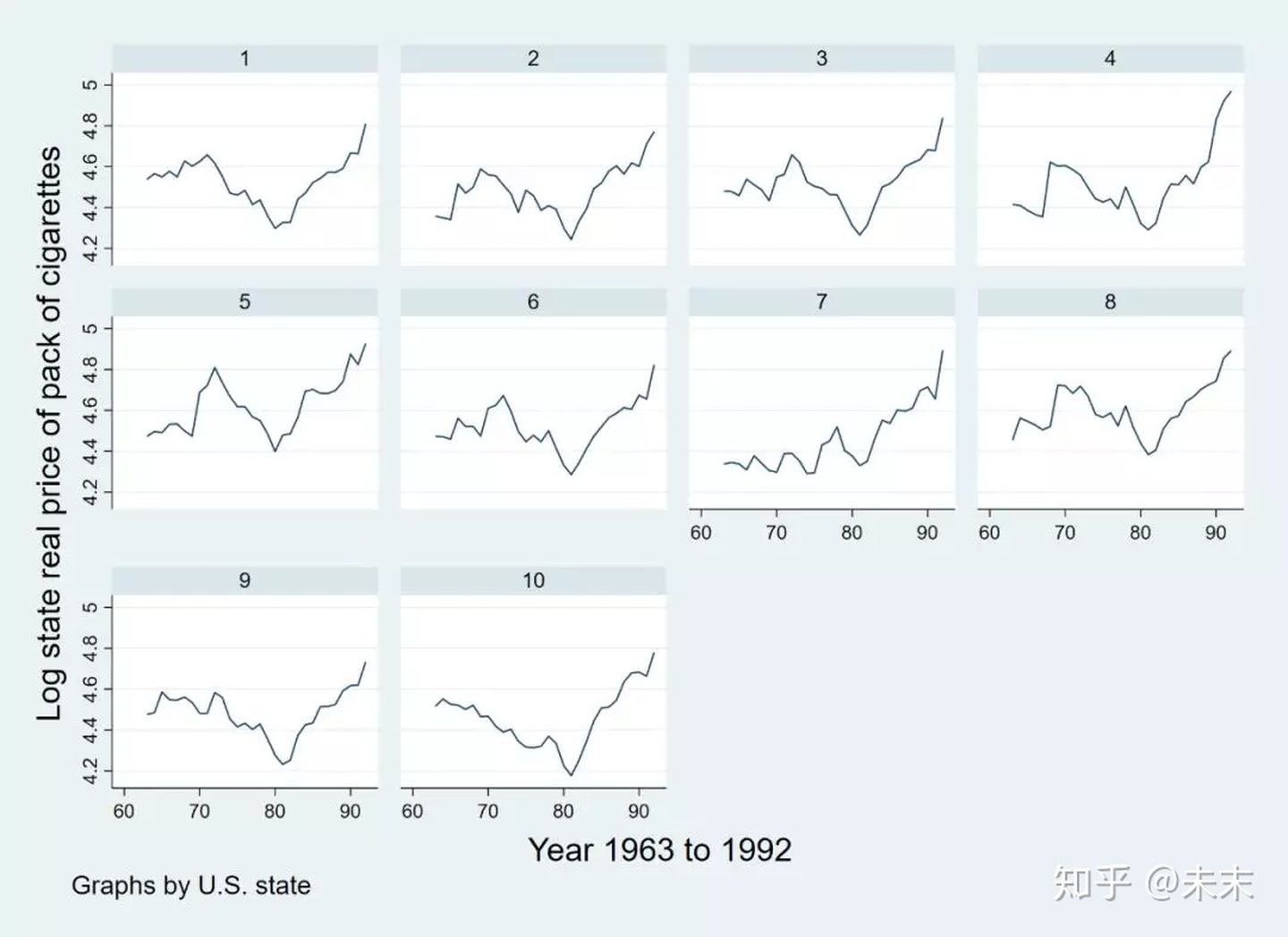
观察发现:1980年之后,所有州的香烟价格基本都呈现了上升的趋势。
第三步 模型估计
首先,我们先假定不存在自相关、异方差和截面相关这三大问题,使用LSDV估计双向固定效应模型。
依次进行如下操作:
使用命令
tab state,gen(state)
生成州虚拟变量;
使用命令
gen t=year-62
生成时间趋势变量;
输入命令
reg lnc lnp lnpmin lny state2-state10 t
进行LSDV估计;
输入命令
est store ols
保存结果。
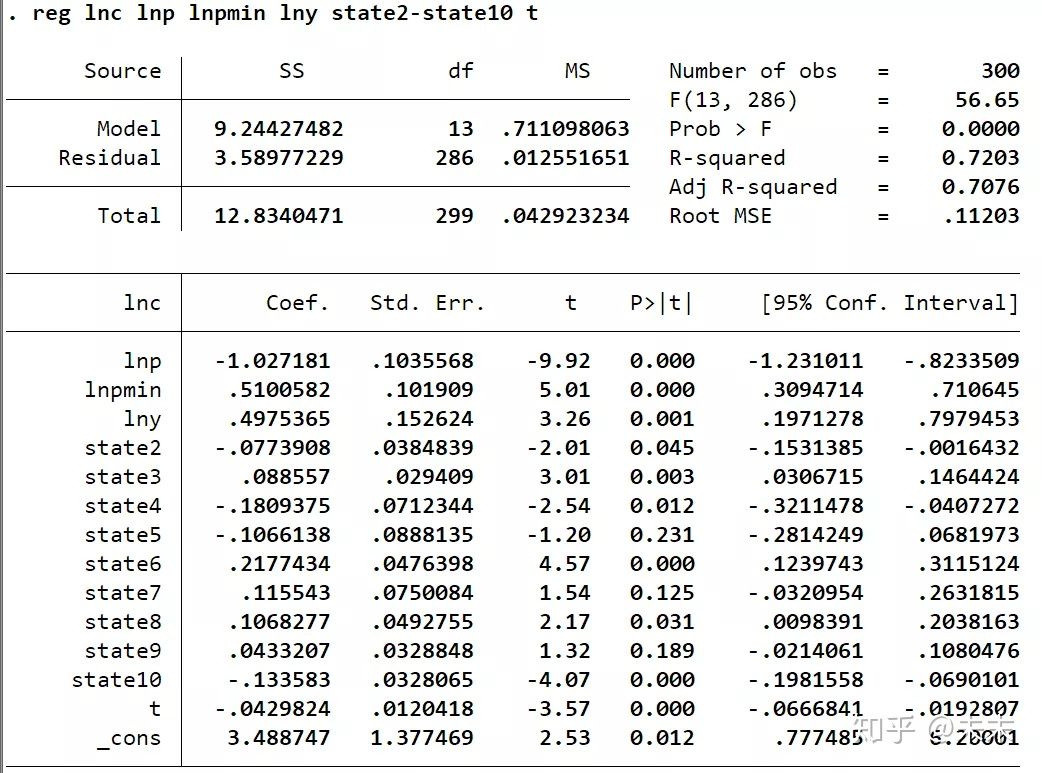
然后,我们输入命令
avplot lnp
查看核心解释变量lnp与被解释变量lnc的偏相关图。
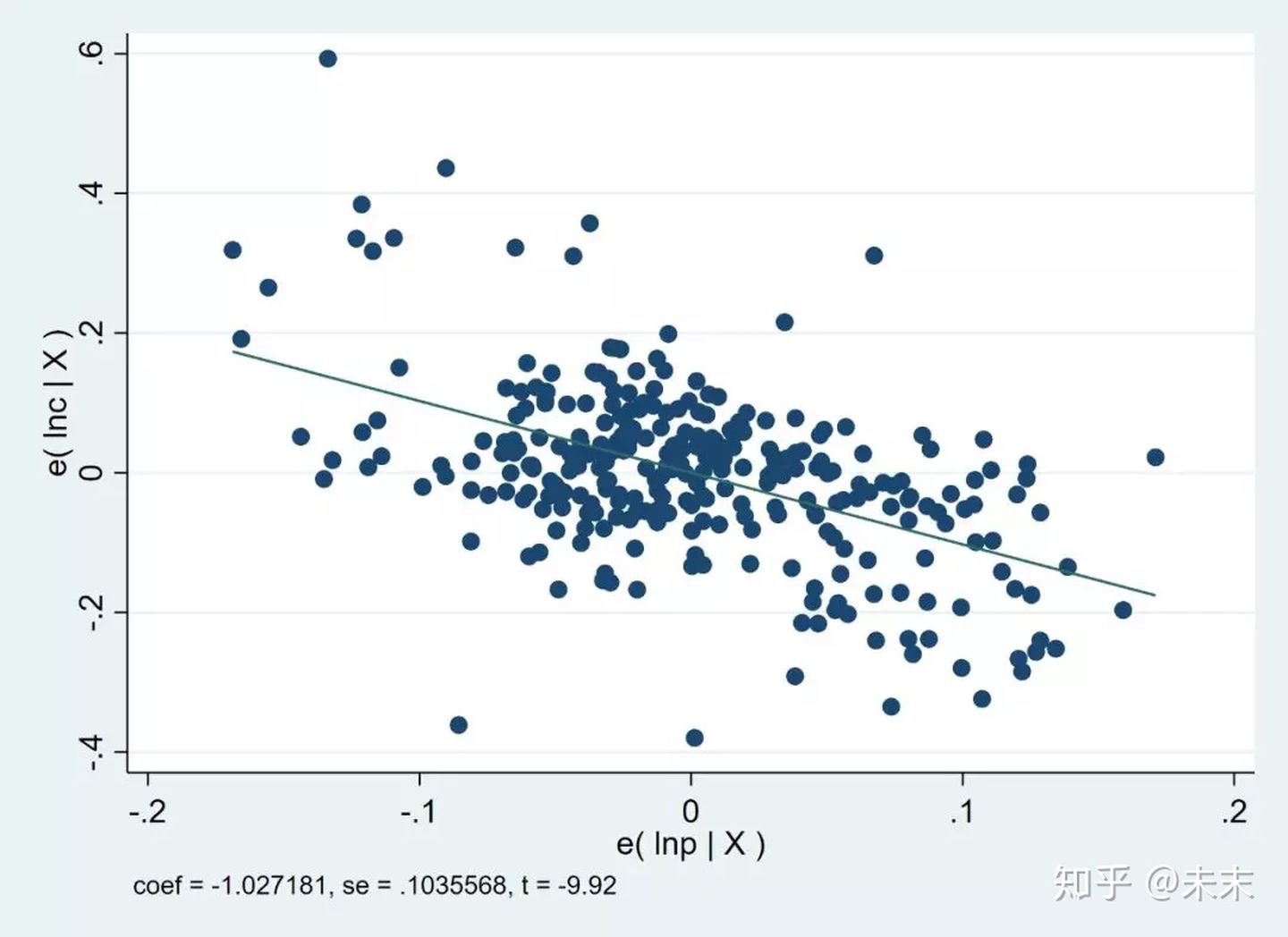
可以发现,两者之间明显呈现负相关关系。
接下来,我们检验误差项是否存在自相关、异方差和截面相关的问题。
1、自相关的检验
使用命令
xtserial lnc lnp lnpmin lny state2-state10 t
检验误差项的自相关问题。

由检验结果可知,P值为0,所以拒绝一阶自相关不存在的原假设,表明存在自相关问题。
2、异方差的检验
使用命令【xttest3】对误差项的异方差问题进行检验。
#【xttest3】只能在【xtreg,fe】和【xtgls】命令之后使用;
#第一次使用【xttest3】的同学,需要使用命令【ssc install xttest3】进行安装
在Stata中输入命令
quietly xtreg lnc lnp lnpmin lny t,fe
然后输入命令
xttest3
(也可以输入命令【quietly xtgls lnc lnp lnpmin lny state2-state10 t】和【xttest3】)

由检验结果可知,P值为0,所以拒绝原假设,认为误差项存在异方差问题。
3、截面相关的检验
使用命令【xttest2】对误差项的截面相关问题进行检验。
#【xttest2】只能在【xtreg,fe】、【xtgls】或【ivreg2】之后使用,只适用于长面板数据;
#第一次使用【xttest2】的同学,需要使用命令【ssc install xttest2】进行安装
在Stata中输入命令
quietly xtreg lnc lnp lnpmin lny t,fe
然后输入命令
xttest2
(也可以输入命令【quietly xtgls lnc lnp lnpmin lny state2-state10 t】和【xttest2】)
当然,因为我们上一步进行了误差项异方差问题的检验,所以这一步我们可以直接输入命令
xttest2

可以看到,检验结果的P值为0,所以拒绝原假设,认为误差项存在截面相关的问题。
综上,通过检验,我们发现模型误差项存在自相关、异方差和截面相关的问题。
第四步 报告计量结果
通过第三步对模型误差项的检验,我们知道模型的误差项存在自相关、异方差和截面相关的问题,所以,我们需要对误差项的自相关、异方差和截面相关问题进行处理并报告计量结果。
对【xtpcse】、【xtgls】和【xtscc】三个命令的结果分别进行报告。
依次输入命令:
xtpcse lnc lnp lnpmin lny state2-state10 t,corr(psar1)
est store xtpcse
xtgls lnc lnp lnpmin lny state2-state10 t,corr(psar1) panels(correlated)
est store xtgls
xtscc lnc lnp lnpmin lny state2-state10 t
est store xtscc
最后通过【esttab】命令将所有的存储结果放在一起进行比较。
输入命令
esttab ols xtpcse xtgls xtscc,b(%9.2f)p mtitle(ols xtpcse xtgls xtscc)obslast star(* 0.1 ** 0.05 *** 0.01)compress nogap k(lnp lnpmin lny t)
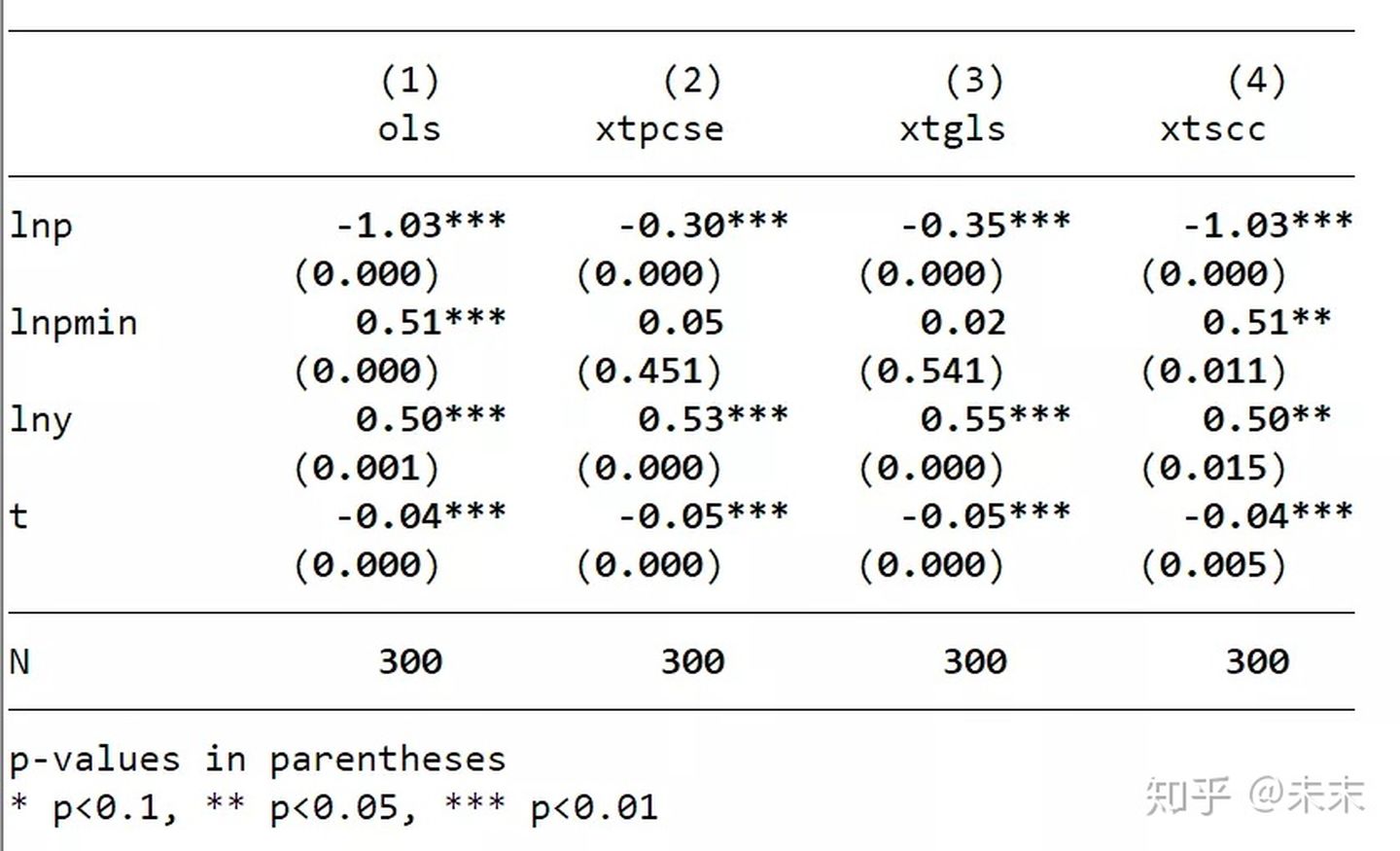
输出的表格中,(1)的结果是不对误差项做任何处理的结果,(2)、(3)、(4)是分别使用三种命令并对误差项的三大问题进行处理的结果。
(四)机制识别方法
一篇高质量的经验研究论文必须回答核心变量以什么样的方式影响了被解释变量,要揭示核心解释变量影响被解释变量背后的机制。所以,机制识别方法在论文研究中是十分重要的。
一、联立方程法
联立方程法是一种重要的机制识别方法。
**联立方程模型:**经济理论常常推导出一组相互联系的方程,其中一个方程的解释变量是另一方程的被解释变量,这就是联立方程组。
方红生教授以印发在国际顶级期刊经济与统计学评论上的论文:《民主、波动和经济发展》为例介绍联立方程法。
Ahmed Mushfiq Mobarak,2005."Democracy,Volatility, and Economic Development,"The Review of Economics and Statistics, MIT Press,vol.87(2),pages 348-361,May
论文《民主、波动和经济发展》构造了一个联立方程来试图解释民主是否通过影响了波动来影响经济发展。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IiZPPAkX-1640317583154)(https://www.zhihu.com/equation?tex=\begin{gathered}+\begin{split}+%26Growt{h_{it}}+%3D+{\alpha+0}Volatilit{y{it}}+%2B+{\alpha+1}Democrac{y{it}}+%2B+{\alpha+2}{X{it}}+%2B+{\mu+i}+%2B+{\varepsilon+{it}}\+%26Volatilit{y_{it}}+%3D+{\beta+0}Democrac{y{it}}+%2B+{\beta+1}{X{it}}+%2B+{\mu+i}+%2B+{\varepsilon+{it}}+\end{split}+\end{gathered})]
在第一个方程中,民主对经济发展的直接效应是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g04OoFRa-1640317583155)(https://www.zhihu.com/equation?tex=\alpha_1)] ,而民主通过影响波动来影响经济发展的间接效应是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pM9stLDC-1640317583156)(https://www.zhihu.com/equation?tex=\alpha_0·\beta_0)] 。
二、联立方程的估计方法
在使用单一方程估计法时,由于忽略了各方程之间的联系(包括各方程扰动项之间的联系),所以不如将所有方程作为一个整体进行估计(即系统估计法)更有效率。
**系统估计法的缺点:**如果其中的某个方程估计的不准确,则可能会影响系统中其它方程的估计。
三阶段最小二乘法
三阶段最小二乘法是最常见的系统估计法。
**(1)**对于一个多方程系统,如果各方程中都不包含内生解释变量,则对每个方程进行OLS估计是一致的,但却不是最有效的,因为单一方程OLS忽略了不同方程的扰动项之间可能存在相关性。
此时,利用SUR(Seemingly Unrelated Regression Estimation)对整个方程系统进行估计是有效率的。
SUR的Stata实现命令为:
xi:reg3(第一个方程的被解释变量 第一个方程的解释变量 i.code i.year)(第二个方程的被解释变量 第二个方程的解释变量 i.code i.year),sure
**(2)**对于一个多方程系统,如果方程中包含内生解释变量,则对每个方程进行2SLS估计是一致的,但却不是最有效的,因为单一方程2SLS忽略了不同方程的扰动项之间可能存在的相关性。
此时,利用3SLS对整个联立方程系统同时进行估计是最有效率的。
3SLS的Stata实现命令为:
xi:reg3(第一个方程的被解释变量 第一个方程的解释变量 i.code i.year)(第二个方程的被解释变量 第二个方程的解释变量 i.code i.year),endog(varlist) exog(varlist)
其中,endog()选项代表系统内除了被解释变量外的内生变量,exog()选项代表从系统外寻找的工具变量。
**#需要注意的是:**论文《民主、波动和经济发展》中,虽然波动在第一个方程中是内生变量,但是不要放入endog()选项中,因为波动在第二个方程中是作为被解释变量的。此外,如果系统内没有除了被解释变量外的内生变量,那么我们就可以删除endog()选项和exog()选项。
#内生变量与外生变量:
对联立方程模型系统而言,已经不能用被解释变量与解释变量来划分变量,而将变量分为内生变量与外生变量两大类。
**内生变量:**内生变量是具有某种概率分布的随机变量,它的参数是是联立方程系统估计的元素。内生变量是由模型系统决定的,同时也对模型系统产生影响。(内生变量一般都是经济变量,通常情况下,模型中内生变量与随机变量相关)
**外生变量:**外生变量一般是确定性变量,或者是具有临界概率分布的随机变量,其参数不是模型系统研究的元素。外生变量影响系统,但本身不受系统的影响。(外生变量一般是经济变量、条件变量、政策变量、虚变量,通常情况下,模型中外生变量与随机项不相关)
三、机制识别方法
Acemoglu et al.(2003)方法
Acemoglu等人2003年发表在国际顶级期刊《货币经济学》杂志上的文章:《制度原因,宏观经济症状:波动,危机与增长》中所使用的的机制识别方法被后来的许多文章引用。
Acemoglu, D.J.A.Robinson, Y.Y.Thaicharoen, andS.Johnson,2003, “Institutional causes, macroeconomic symptoms:volatility,crises and growth”,Journal of Monetary Economics, 50,49-123.
由于文章比较长,为了理解Acemoglu等人的方法,方红生教授以文章《攫取之手、援助之手与中国税收超GDP增长》为例进行讲解。
《攫取之手、援助之手与中国税收超GDP增长》(方红生、张军),《经济研究》2013年第3期
其中,“攫取之手”是指中央税收占总税收的比重;“援助之手”是指中央转移支付占地方政府财政支出的比重。
文章构建了三个方程,分别如下:
Tshare i t = α 1 Tshare i t − 1 + α 2 R g h i t + α 3 R h h i t + α 4 R g h i t ∗ R h h i t + β X i t + μ i + μ t + ε i t \begin{aligned} \text { Tshare }_{i t}=& \alpha_{1} \text { Tshare }_{i t-1}+\alpha_{2} R g h_{i t}+\alpha_{3} R h h_{i t}+\alpha_{4} R g h_{i t} * R h h_{i t} \\ &+\beta X_{i t}+\mu_{i}+\mu_{t}+\varepsilon_{i t} \end{aligned} Tshare it=α1 Tshare it−1+α2Rghit+α3Rhhit+α4Rghit∗Rhhit+βXit+μi+μt+εit
其中,被解释变量Tshare为税收占GDP的比重,解释变量由被解释变量滞后一期 ( Tshare i t − 1 _{i} t-1 it−1 ) 、攖取之手 ( R g h ) (\mathrm{Rgh}) (Rgh) 、援助之手 ( R h h ) (\mathrm{Rhh}) (Rhh) 、两只手的交互项 ( R g h ⋆ R h h ) \left(\mathrm{Rgh}^{\star} \mathrm{Rhh}\right) (Rgh⋆Rhh) 以及 其他控制变量组成。核心解释变量为挸取之手、援助之手和两只手的交互项。
预期,攫取之手与援助之手对GDP占税收的比重具有正向效应,而交互项具有负向效应。
文章试图对税收征管效率和高税行业的发展这两个渠道的重要性进行识别考虑到税收征管效率面临着严重的度量问题,所以只为高税行业的发展这一渠道寻找一个相对合适的代理变量,即,使用非农产业化,所以构造第二个方程。
(2)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nDUY9uys-1640317583157)(https://www.zhihu.com/equation?tex=\begin{align*}+Pnonagr{i_{it}}+%3D+%26{\alpha+1}Pnonagr{i{it±+1}}+%2B+{\alpha+2}Rg{h{it}}+%2B+{\alpha+3}Rh{h{it}}+%2B+{\alpha+4}Rg{h{it}}Rh{h_{it}}\+%26%2B+\beta+{X_{it}}+%2B+{\mu+_i}+%2B+{\mu+t}+%2B+{\varepsilon+{it}}+\end{align*})]
其中,非农产业化(Pnonagri)为被解释变量;解释变量由被解释变量滞后一期(Tshare_it-1)、攫取之手(Rgh)、援助之手(Rhh)、两只手的交互项(Rgh*Rhh)以及其他控制变量组成。核心解释变量为攫取之手、援助之手和两只手的交互项。
预期,攫取之手与援助之手对非农产业化具有正向效应,而交互项具有负向效应。
第三个方程为:将非农产业化引入第一个方程构建起来。
Tshare i t = γ Pnonagri i t + α 1 Tshare i t − 1 + α 2 R g h i t + α 3 R h h i t + α 4 R g h i t ∗ R h h i t + β X i t + μ i + μ t + ε i t \begin{aligned} \text { Tshare }_{i t}=& \gamma \text { Pnonagri }_{i t}+\alpha_{1} \text { Tshare }_{i t-1}+\alpha_{2} R g h_{i t}+\alpha_{3} R h h_{i t}+\alpha_{4} R g h_{i t} * R h h_{i t} \\ &+\beta X_{i t}+\mu_{i}+\mu_{t}+\varepsilon_{i t} \end{aligned} Tshare it=γ Pnonagri it+α1 Tshare it−1+α2Rghit+α3Rhhit+α4Rghit∗Rhhit+βXit+μi+μt+εit
其中,核心解释变量依然是攫取之手、援助之手和两只手的交互项。
接下来,我们通过Acemoglu等人的判别规则判断“非农产业化”这个机制的重要性。
- 如果与第一个方程进行对比,第三个方程中的核心变量由显著变为不显著,或其显著性和(或)系数有明显的下降,而Pnonagri显著,那么Pnonagri是其作用于税收占GDP比重的一个主要渠道。
- 如果核心变量显著而Pnonagri不显著,那么Pnonagri不是其作用于税收占GDP比重的一个渠道。在此情形下,核心变量只能通过其他渠道(如提高税收征管效率)起作用。
- 如果核心变量和Pnonagri都显著,且前者的显著性和系数并没有明显的下降,那么核心变量作用于税收占GDP比重的主要渠道是税收征管效率的提高而非Pnonagri。
渠道检验的结果如下
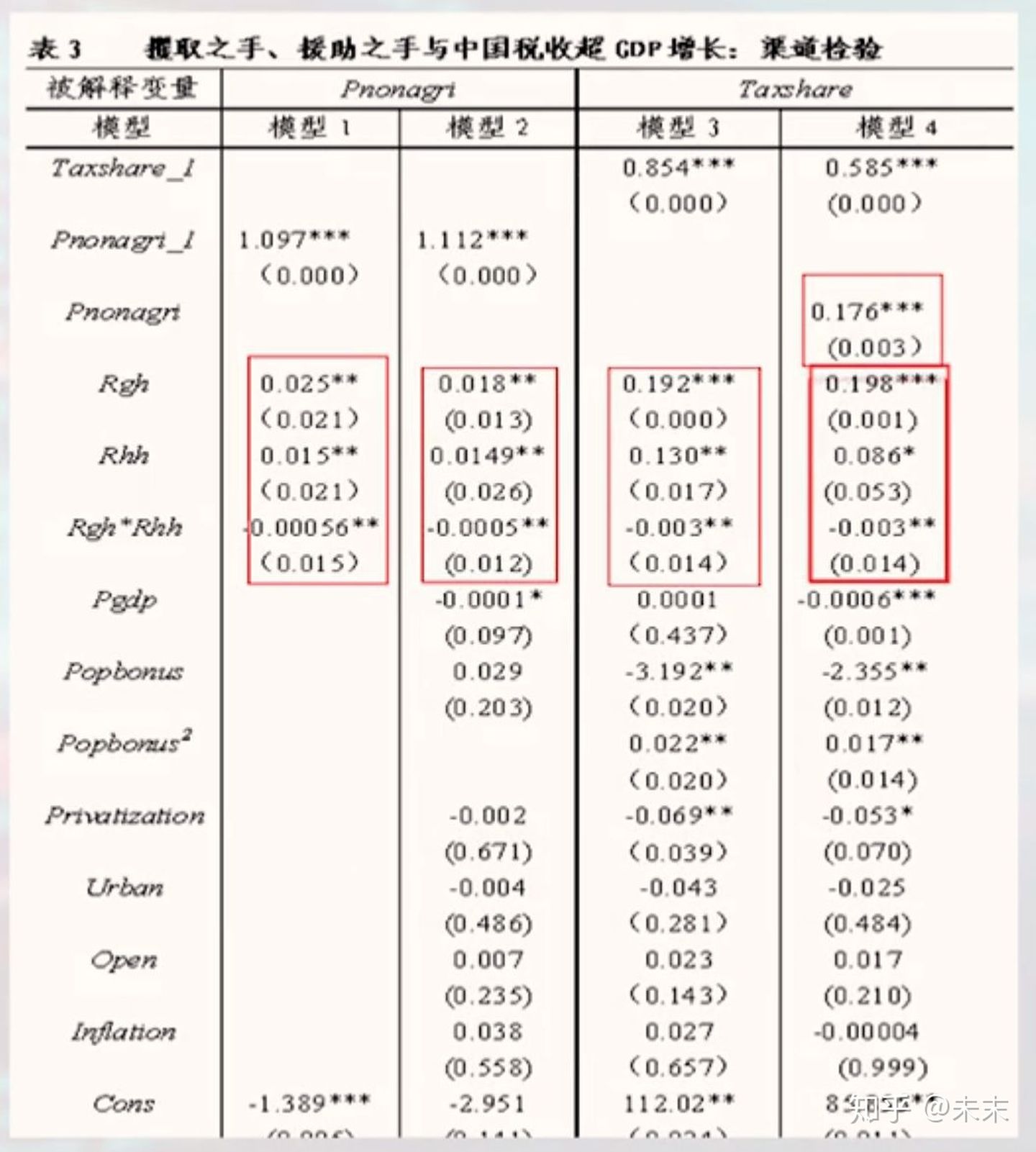 图片来自慕课上浙江大学方红生教授的面板数据分析与Stata应用课程截图
图片来自慕课上浙江大学方红生教授的面板数据分析与Stata应用课程截图
其中,模型2为上文中的第二个方程,可以看到,攫取之手、援助之手和两只手的交互项对Pnonagri产生了预期的影响;模型3为上文中的第一个方程,同样,攫取之手、援助之手和两只手的交互项对税收占GDP的比重产生了预期的影响;模型4即为上文中的第三个方程,可以看到,Pnonagri显著为正,在核心解释变量方面,与模型3相比,只有援助之手的系数和显著性有显著下降,攫取之手和两只手的交互项并未发生显著性的变换。
根据Acemoglu等人的判别规则我们可以得出结论:
(1)中央政府援助之手是将非农产业化作为其推高税收占GDP比重的一个主要渠道,税收征管效率仅是次要渠道。
(2)攫取之手及其与援助之手的交互项是将税收征管效率作为其推高税收占GDP比重的一个主要渠道,非农产业化仅是次要渠道。
(五)平稳序列
在我们使用面板数据做计量分析的时候,我们在拟合模型之前,首先需要对数据的平稳性进行检验,检验数据平稳性最常用的办法是单位根检验。
知识回顾
如果一个时间序列不是平稳过程,则称为“非平稳序列”(non-stalionary time series)。在以下三种情况下,都有可能出现非平稳序列:
- 确定性趋势
- 结构变动
- 随机趋势
我们称平稳的时间序列为“零阶单整”(Integrated of order zero),记为I(0)。如果时间序列的一阶差分为平稳过程,则称为“一阶单整" (Integrated of order one),记为I(1),也称为“单位根过程”(unit root process)。更一般地,如果时间序列的d阶差分为平稳过程,则称为"d阶单整"( Integrated of order d),记为I(d)。
对于I(0)序列,由于它是平稳的,所以长期而言有回到其期望值的趋势,这种性质被称为"均值回复”(mean-reverting)。而非平稳的I(1)序列则会“到处乱跑” (wander widely),没有上述性质。此外,I(0)序列对于其过去的行为只有有限的记忆,即发生在过去的扰动项对未来的影响随时间而衰减;而I(1)序列则对过去的行为具有无限长的记忆,即任何过去的冲击都将永久性地改变未来的整个序列。
非平稳序列会造成以下问题:
- 自回归系数向左偏向于0;
- 传统的t检验失效;
- 两个相互独立的单位根变量可能出现伪回归(spurious regression)或伪相关。
面板数据单位根检验
陈强教授在《高级计量经济学与STATA应用(第二版)》中给出了六种对面板数据的单位根进行检验的方法。分别是:LLC、HT、Breintung、IPS、费雪式和Hadri LM 6种方法进行面板单位根检验。
有些面板单位根检验(LLC检验、HT检验与Breitung检验),假设各面板单位的自回归系数均相同,也称为“共同根”( common root) ,其他检验则允许各面板单位的自回归系数不同。
除此之外,为了导出检验统计量的大样本分布,这些检验对于横截面维度n或时间维度T是否固定,或趋于无穷的速度所作的渐近假定也不尽相同。因此,对于具体数据,究竟适用何种面板单位根检验,主要取决于样本容量。比如,基于 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JscwAWyb-1640317583159)(https://www.zhihu.com/equation?tex=n%2FT\to0)] 的检验,要求时间维度T增长速度快于横截面维度n,故适用于长面板。而基于T固定而n ->∞的检验则适用于短面板。Stata手册将这些检验分类总结如下表。
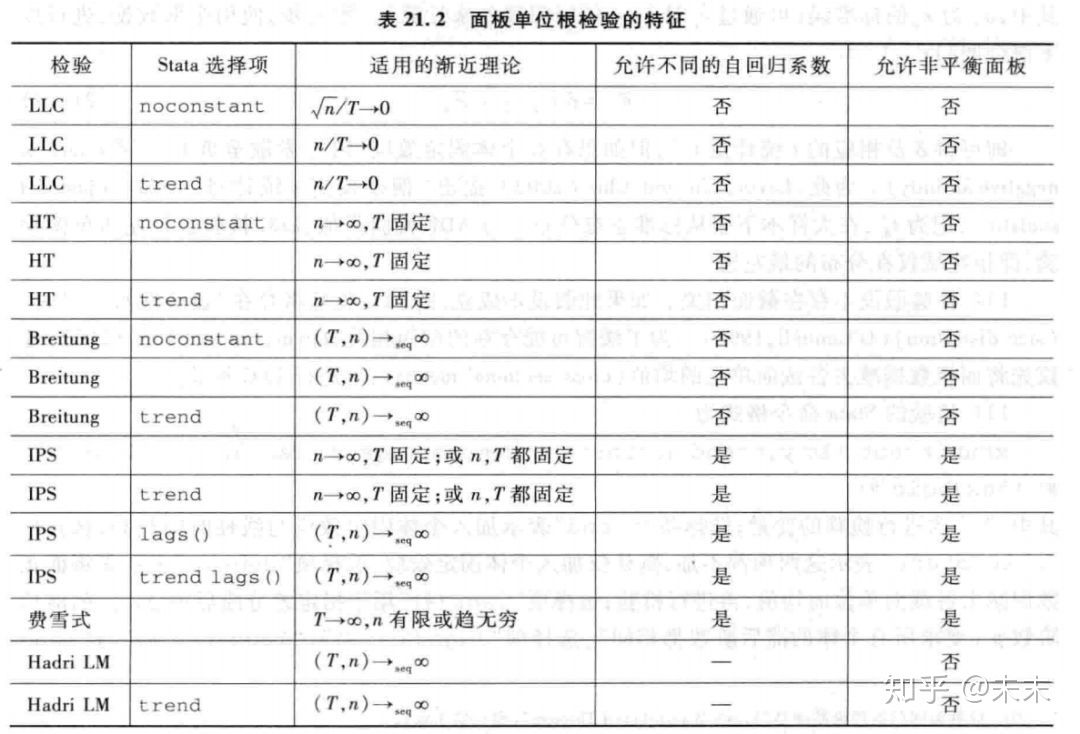 图片来自陈强教授《高级计量经济学及Stata应用(第二版)》中的截图
图片来自陈强教授《高级计量经济学及Stata应用(第二版)》中的截图
表中, ( T , n ) → s e q ∞ (T, n) \rightarrow_{s e q} \infty (T,n)→seq∞ 表示 “序贯极限” (sequential limit),即首先给定n,让 T → ∞ T \rightarrow \infty T→∞ , 然后再让 n → ∞ n \rightarrow \infty n→∞ 。在实践中,这要求T较大,而且n也不能太小。
此外,因为Hadri LM检验为面板平稳性检验(原假设为平稳过程),所以不存在是否“允许不同的自回归系数”的问题。
1、LLC检验
LLC检验适用于长面板数据(T>n),且为平衡面板数据。
LLC检验假设不存在截面相关,如果这个假设不成立,则LLC检验将存在“显著性水平扭曲”,为了缓解可能存在的界面相关,我们可以先将面板数据减去各截面单位的均值,然后再进行LLC检验。
#LLC检验是左边单侧检验,即拒绝域仅在分布的最左边。
LLC检验的Stata命令格式为:
xtunitroot llc y,trend noconstant demean lags(#) lags(aic #) lags(bic #) lags(hqic #)
其中,"y"表示需要进行检验的变量;选择项“trend”表示加入个体固定效应与线性时间趋势,选择项“noconstant”表示这两项都不加,默认仅加入个体固定效应;选择项“demean”表示先将面板数据减去各截面单位的均值,再进行检验;选择项“lags(#)”用于指定差分滞后项 Δ y t , t − j \Delta y_{t,t-j} Δyt,t−j的滞后阶数p(要求所有个体滞后阶数都相同);选择项“lags(aic #)”、“lags(bic #)”、与“lags(hqic #)”分别表示使用AIC、BIC或HQIC信息准则来选择 p i p_i pi 并指定其最大值#,且不同个体的滞后阶数 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bTaZWsW7-1640317583161)(https://www.zhihu.com/equation?tex=p_i)] 可以不同。
******下面,我们以Stata提供的数据集pennxrate. dta为例进行LLC检验。
pennxrate平衡面板来自Penn World Table 6.2,包含151个国家,1970—2003年的实际汇率数据。目标是检验“购买力平价”(Purchasing Power Parity,简记PPP)是否成立。购买力平价假说认为,两国之间的名义汇率反映两国之间的物价水平,经物价调整后的实际汇率在长期内趋于均衡值,故应为平稳过程。因此,检验lnrxrate (实际汇率的对数)是否为单位根过程;如果是,则拒绝PPP假说。该数据集还包括两个虚拟变量g7与oecd,分别表示G7与OECD国家。另外,由于选择美国作为参照国来考察世界各国的汇率,故美国不在此数据集中。
 pennxrate.dta数据集
pennxrate.dta数据集
在理论上,因为没有理由认为lnrxrate有时间趋势,所以在检验中我们不使用选择项“trend”,而使用默认设置, 即仅加入个体固定效应。又因为LLC检验仅适用于长面板数据,即要求横截面维度小于时间维度,因此,为了检验的目的,我们仅使用G7中的六个国家(不含美国)进行检验。考虑到G7国家经济发展水平相近且联系密切,所以每个国家的扰动项可能存在截面相关,为此,我们在检验中使用选择项“demean”来缓解截面相关问题。
LLC检验命令为
xtunitroot llc lnrxrate if g7,lags(aic 10) demean
 LLC检验结果
LLC检验结果
LLC检验结果显示,根据AIC信息准则选择的平均滞后阶数为1.5,偏差校正统计量为-2.08,其对应的P值为0.0187,小于0.05,所以在5%的显著性水平下拒绝原假设,认为面板数据为平稳过程。检验结果支持PPP。
2、HT检验
HT检验要求面板数据为平衡面板数据。
由于LLC检验仅适用于长面板,而许多微观面板数据的时间维度T较小。为此,Harris and Tzavalis(1999)(简记HT)提出了基于T固定,而 n → ∞ n \to \infty n→∞ 的检验统计量。
HT检验的Stata命令格式为:
xtunitroot ht y,trend noconstant demean
其中,"y"表示需要进行检验的变量;选择项“trend”表示加入个体固定效应与线性时间趋势,选择项“noconstant”表示这两项都不加,默认仅加入个体固定效应;选择项“demean”表示先将面板数据减去各截面单位的均值,再进行检验。
#HT检验是左边单侧检验
******继续以数据集pennxrate.dta为例进行检验演示。
因为HT检验的前提为T固定而 n → ∞ n \to \infty n→∞ ,所以我们使用全部151个国家进行HT检验,同样,为了缓解截面相关问题,我们在命令中依然使用选择项“demean”。
HT检验命令为
xtunitroot ht lnrxrate,demean
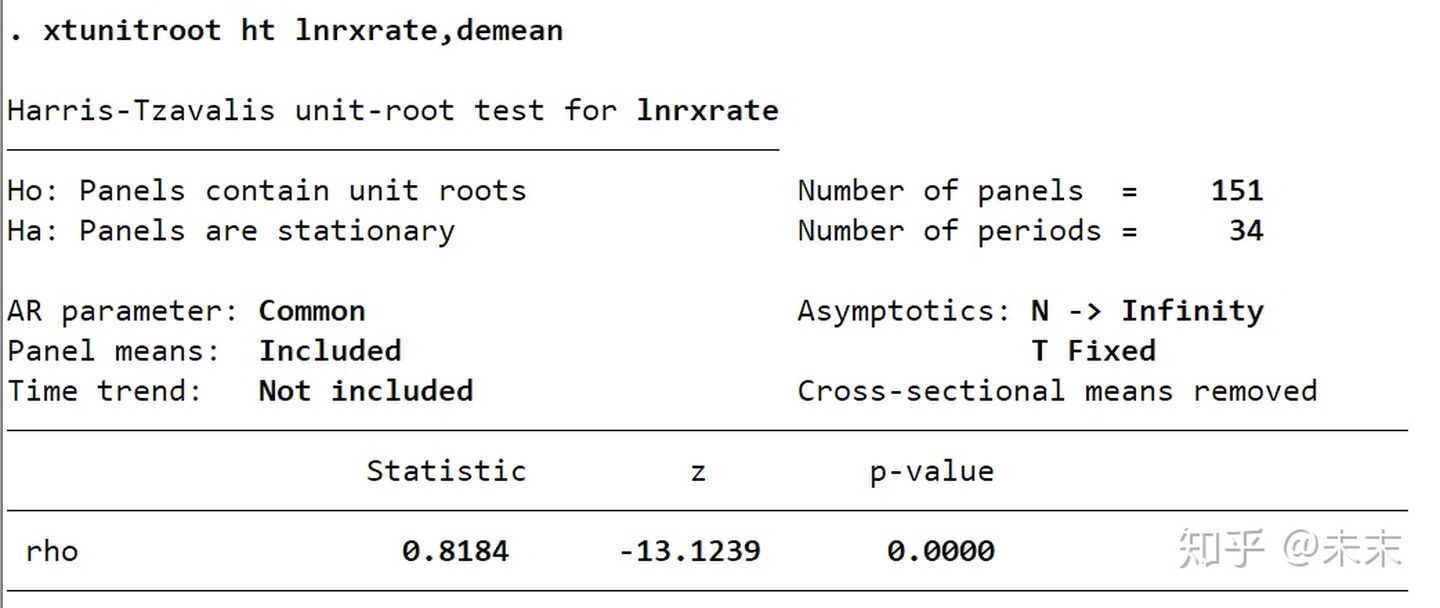 HT检验结果
HT检验结果
由HT检验结果可知, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PFF9xE28-1640317583164)(https://www.zhihu.com/equation?tex=\hat+p+%3D+0.82)] ,而 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qyeN24h3-1640317583164)(https://www.zhihu.com/equation?tex=z%3D-13.12)] ,相应的P值为0.0000,所以强烈拒绝面板单位根的原假设,依然支持PPP。
3、Breitung检验
Breitung检验要求面板数据为平衡面板数据。
LLC检验与HT检验的共同特点是直接用OLS估计回归方程,然后再对自回归系数或t 统计量进行校正,以消除动态面板偏差。
Breitung检验(Breitung 2000)的基本思路与LLC检验类似。主要区别在于,Breitung首先对数据进行“向前正交变换” (forward orthogonalization),即减去未来各期的平均值,然后再进行回归,使得回归后不再需要偏差校正。具体步骤参见Stala手册。所得检验统计量记为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8hDmrXGH-1640317583165)(https://www.zhihu.com/equation?tex=\lambda)] ,服从渐近标准正态分布,然后进行左边单侧检验。
Breitung检验假设数据生成过程为AR(1)。如果存在更高阶的自回归项,则应先进行“预白噪声化”( prewhitening),以消除原序列的自相关。
#Breitung检验是左边单侧检验
Breitung检验的Stata命令格式为:
xtunitroot breitung y,trend noconstant demean robust lags(#)
其中,"y"表示需要进行检验的变量;选择项“trend”表示加入个体固定效应与线性时间趋势,选择项“noconstant”表示这两项都不加,默认仅加入个体固定效应;选择项“demean”表示先将面板数据减去各截面单位的均值,再进行检验;选择项“robust”表示使用截面相关稳健的统计量;选择项“lags(#)”用于指定进行预白噪声化的滞后阶数,默认不进行预白噪声化。
******继续以数据集pennxrate.dta为例进行检验演示。
由于Breitung检验的渐进理论假设为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aQrN7XrX-1640317583166)(https://www.zhihu.com/equation?tex=(T%2Cn)]{+\to+_{seq}}\infty) ,所以选择OECD国家作为样本数据。我们在命令中使用选择项“robust”控制截面相关,所以不再使用选择项“demean”。
因为,在LLC检验中,平均滞后期为1,所以假设数据生成过程为AR(1),不进行预白噪声化处理。
Breitung检验命令为
xtunitroot breitung lnrxrate if oecd,robust
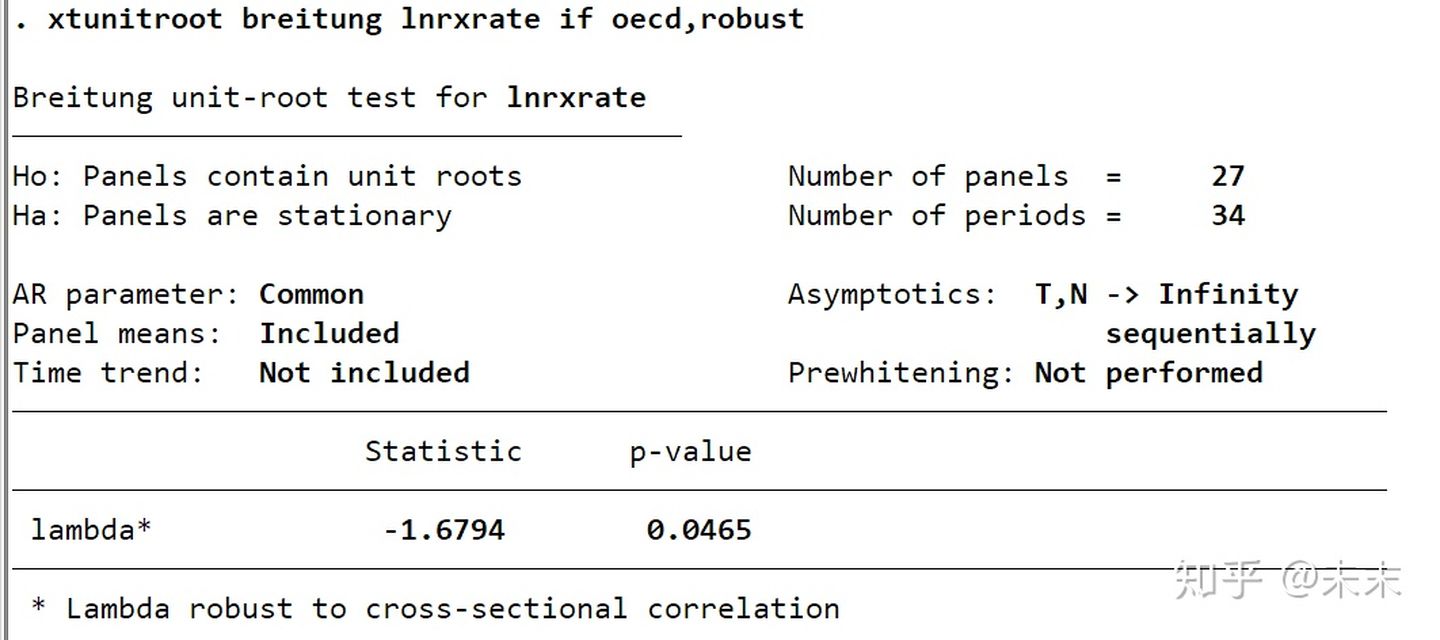 Breitung检验结果
Breitung检验结果
Breitung检验结果显示,检验统计量 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vmow3GZf-1640317583167)(https://www.zhihu.com/equation?tex=\lambda)] =-1.68,相应的P值为0.0465,小于0.05,所以在5%的显著性水平上拒绝原假设,即认为面板数据是平稳过程。
4、IPS检验
LLC检验、HT检验与Breitung检验的共同局限在于,它们都要求每位个体的自回归系数 δ \delta δ都相等,此共同根假设在实践中可能过强。比如,不同国家由于制度与文化的原因,经济规律可能不同。为了克服此缺点,Im, Pesaran and Shin(2003)(简记IPS)提出了IPS面板单位根检验。
#IPS检验是左边单侧检验
IPS检验的Stata命令格式为:
xtunitroot ips y,trend demean lags(#) lags(aic #) lags(bic #) lags(hqic #)
其中,"y"表示需要进行检验的变量;选择项“trend”表示加入个体固定效应与线性时间趋势,默认仅加入个体固定效应;选择项“demean”表示先将面板数据减去各截面单位的均值,再进行检验;选择项“lags(#)”用于指定差分滞后项 Δ y t , t − j \Delta y_{t,t-j} Δyt,t−j的滞后阶数p(要求所有个体滞后阶数都相同);选择项“lags(aic #)”、“lags(bic #)”、与“lags(hqic #)”分别表示使用AIC、BIC或HQIC信息准则来选择 [外链图片转存中…(img-tAvWAHMG-1640317583168)] 并指定其最大值#,且不同个体的滞后阶数 [外链图片转存中…(img-4RZFa5Nw-1640317583169)] 可以不同。
******继续以数据集pennxrate.dta为例检验OECD国家是否符合PPP假说。
首先,我们假定扰动项没有自相关,但使用选择项“demean”来缓解可能存在的自相关。
IPS检验命令为
xtunitroot ips lnrxrate if oecd,demean
[外链图片转存中…(img-nMkULKl7-1640317583169)]IPS检验结果(假定扰动项没有自相关)
由检验结果可知,t-bar统计量为-3.13,小于1%显著性水平的临界值-1.81,所以拒绝面板单位根的原假设。此外,统计量Z-t-tilder-bar对应的P值为0.000,同样拒绝原假设。
下面,我们考虑扰动项存在自相关的情形,并引入差分滞后项。
IPS检验命令为
xtunitroot ips lnrxrate if oecd,lags(aic 8) demean
[外链图片转存中…(img-q7Vsl2HS-1640317583170)]IPS检验结果(假定扰动项存在自相关)
结果显示:根据AIC准则选择的平均滞后期为1.48,而统计量W-t-bar的值为-7.31,对应的P值为0.000,所以依然拒绝原假设。
5、费雪式检验
费雪式检验的基本思路类似于IPS检验,即对每位个体分别进行检验,然后再将这些信息综合起来。具体来说,就是对面板数据中的每位个体分别进行单位根检验(ADF检验或PPP检验),得到n个检验统计量及相应的p值 { p 1 , p 2 , … , p n } \left\{p_{1}, p_{2}, \ldots, p_{n}\right\} {p1,p2,…,pn}。
Choi(2001)提出了四种方法将这些P值综合成“费雪式”统计量。
方法一:逆卡方变换(单边右侧检验),允许非平衡面板数据。
方法二:逆正太变换(单边左侧检验)
方法三:逆逻辑变换(单边左侧检验)
方法四:修正逆卡方变换(如果面板中个体数n很大,可以使用“修正逆卡方变换”)
费雪式检验的Stata命令格式为:
xtunitroot fisher y,dfuller pperron demean lags(#)
其中,选择项“dfuller”表示根据ADF检验获得P值,选择项“pperron”表示根据PP检验获得P值。选择项“lags(#)”如果与选择项“dfuller”同时使用,表示ADF检验的滞后阶数,如果与选择项“pperron”同时使用,表示用于计算标准误的滞后阶数。进一步,如果使用选择项“dfuller”,则命令dfuller的所有选择项也都适用于此命令;类似的,如果使用选择项“pperron”,则命令pperron的所有选择项也都适用于此命令。
******继续以数据集pennxrate.dta为例,使用滞后两期的ADF回归检验所有151个国家的实际汇率。
由于许多国家的实际汇率对数的平均值都不为零,所以假设真实模型可能存在漂移项,所以加入命令dfuller的选择项“drift”。此外,使用选择项“demean”来缓解可能存在的界面相关。
费雪式检验命令为
xtunitroot fisher lnrxrate,dfuller drift lags(2) demean
[外链图片转存中…(img-1RZTaA2o-1640317583171)]费雪式检验结果
费雪式检验结果显示,所有的四个统计量均强烈拒绝面板单位根的原假设,其相应的p值均为0.0000。
6、Hadri LM检验
Hadri (2000)把KPSS平稳性检验推广到面板数据,提出了检验面板平稳性的LM检验(原假设为平稳过程)。
Hadri LM的Stata命令格式为:
xtunitroot hadri y,trend demean robust kernel (bartlett #) kernek (parzen #) kernel(quadraticspectral #)
其中,选择项“robust”表示允许不同个体的 ε i t \varepsilon_{it} εit存在异方差(不再是iid,但仍为正态);选择项“kernel(bartlett #) kernel(parzen #) kernel(quadraticspectral #)”分别指定使用bartlett,parzen或quadraticspectral核函数以及滞后阶数#,来估计扰动项的长期方差,即渐进方差。使用选择项“kernek()”可以使得检验结果在存在异方差和自相关的情况下也成立。
******仍以数据集pennxrate.dta为例,对OECD国家进行检验。
为了控制自相关,使用滞后5阶的bartlett核函数。
Hadri LM检验命令为
xtunitroot hadri lnrxrate if oecd,kernel(bartlett 5) demean
[外链图片转存中…(img-Yh3BnqjK-1640317583171)]Hadri LM检验结果
Hadri LM检验结果显示:可以拒绝“所有面板单位均为平稳过程”的原假设,这与上面五种检验方法的结果有所不同。
Banerjee et al(2005)探讨了面板单位根检验对于PPP假说的适用性,并指出由于不同国家之间汇率可能存在协整或长期关系,面板单位根检验经常在原假设正确的情况下也拒绝原假设。
*******如果我们进行面板单位根检验结果显示所有变量均为单位根过程,我们就需要进行下一步的面板协整检验了。
(六)内生性与工具变量法
面板数据分析与Stata应用笔记整理自慕课上浙江大学方红生教授的面板数据分析与Stata应用课程,笔记中部分图片来自课程截图。
笔记内容还参考了陈强教授的《高级计量经济学及Stata应用(第二版)》
一篇高质量的经验研究论文需要高度重视内生性问题的处理
内生性问题及解决方法
短面板和长面板数据的分析技术都只考虑了一种内生性问题,即不可观测的个体效应与解释变量相关,对于这一问题,我们只需要对个体效应进行控制即可解决。
而一种普遍的内生性问题——解释变量与误差项存在相关性普遍存在于计量方程中,如果这个问题不加以重视和处理那么回归结果就变的不可相信。
内生性问题的来源
内生性问题主要来自于三个方面,分别为:遗漏变量、联立性以及度量误差
1、遗漏变量
遗漏变量是指可能与解释变量相关的变量,本来应该加以控制,但却没有控制的变量。这些变量最后进入了误差项,从而导致误差项与解释变量相关,进而导致了内生性问题。
2、联立性
联立性是指一个计量方程中的核心解释变量A对被解释变量B产生影响,反过来,被解释变量B又对A产生影响。
[外链图片转存中…(img-FixkjFmV-1640317583172)]
如果B对A有正向的影响,正向冲击就会导致A增加,从而导致核心解释变量A与误差项正相关。
如果B对A有负向的影响,正向冲击就会导致A降低,从而导致核心解释变量A与误差项负相关。
3、度量误差
度量误差可以分为解释变量的度量误差和被解释变量的度量误差。
(1)解释变量存在度量误差
假设真实的模型为:
y = α + β x ∗ + ε y=\alpha+\beta x^{*}+\varepsilon y=α+βx∗+ε
其中, Cov ( x ∗ , ε ) = 0 \operatorname{Cov}\left(x^{*}, \varepsilon\right)=0 Cov(x∗,ε)=0,而 x ∗ x^* x∗无法精确观测,我们只能观测到x,二者之间的关系是:
x = x ∗ + μ x=x^{*}+\mu x=x∗+μ
且满足 Cov ( x ∗ , μ ) = 0 , Cov ( μ , ε ) = 0 \operatorname{Cov}\left(x^{*}, \mu\right)=0, \quad \operatorname{Cov}(\mu, \varepsilon)=0 Cov(x∗,μ)=0,Cov(μ,ε)=0 。
将上述(1)(2)两式合并可以得到:
[外链图片转存中…(img-6uEdUasQ-1640317583173)]+(3))
此时,因为 与x相关,所以能够观测到的解释变量x与新的误差项 [外链图片转存中…(img-AZC8GZRL-1640317583191)]) 存在相关关系,从而产生内生性,在这种情况下,估计得到的系数绝对值会偏小。
(2)被解释变量存在度量误差
假设真实的模型为:
[外链图片转存中…(img-iH6TjKTz-1640317583193)]
其中, [外链图片转存中…(img-ZbpU4r7j-1640317583194)]+%3D+0) ,而 [外链图片转存中…(img-dLm9U38K-1640317583195)] 无法精确观测,只能观测到y,二者之间的关系是:
[外链图片转存中…(img-PhTjzUn9-1640317583196)]
其中, [外链图片转存中…(img-9NRDhRw6-1640317583197)] 为测量误差,两式合并可以得到:
[外链图片转存中…(img-ZJqs5faM-1640317583198)]+(6))
此时,如果 Cov ( x , v ) = 0 \operatorname{Cov}(x, v)=0 Cov(x,v)=0 ,则OLS估计量仍是一致的,但估计结果可能会增大扰动项的方差,若 [外链图片转存中…(img-oQHKB8g9-1640317583199)]\ne0) ,就会产生内生性问题。
内生性会带来的问题
#在存在内生性解释变量的情况下,OLS估计量有偏且不一致。
#只要任何一个解释变量与随机扰动项相关,全部解释变量的系数都会有偏、不一致。
解决内生性问题的方法
通常有两种方法解决内生性问题即使用内生变量的滞后一期和工具变量法。
1、使用内生变量的滞后一期
一般来说,内生变量的上一期与当期误差项并不存在相关关系,所以可以考虑使用内生变量的滞后一期替代当期的内生变量。这种方法较为简单,并且在直觉上可行,但这种方法的缺点是:不能够回答当期的内生变量对当期的被解释变量的影响程度;而且,上一期的内生变量也可能因为遗漏变量而具有内生性。
2、工具变量法
工具变量是指某一个变量与模型中解释变量高度相关,但却不与误差项相关,估计过程中被作为工具使用,以替代模型中与误差项相关的解释变量的变量。
工具变量法则是使用工具变量进行估计的方法。
工具变量法最常用的估计方法为:两阶段最小二乘法(TSLS)。
两阶段最小二乘法
两阶段最小二乘法,顾名思义,是指分两阶段进行最小二乘估计。
第一阶段:将内生性变量作为被解释变量,工具变量和方程中的外生变量作为解释变量,来进行最小二乘估计;
第二阶段:用第一阶段估计得到的内生变量的预测值替换内生变量,再进行最小二乘估计。
两阶段最小二乘法的原理
第一阶段:消除了潜在内生解释变量的内生性,通过外生变量的预测回归,得到这些变量的外生性部分。
第二阶段:利用第一阶段得到外生的预测回归的拟合值进行回归,进而消除偏误。
需要注意的是:
-
工具变量法估计的标准误始终大于OLS估计的标准误,工具变量与内生性解释变量的相关性越强,工具变量法估计的标准误就越低,估计精度就越高。
-
工具变量法对工具变量的选择有着非常高的要求,好的工具变量会使得结果更加精确,而不当的工具变量会使得工具变量法的估计结果比最小二乘法的估计结果更加糟糕。如果实在难以找到一个好的工具变量,那么选择OLS估计也是一个不错的结果,但是需要在文章解释OLS估计是高估还是低估了结果,这有利于对问题的分析。如果内生变量与误差项是正相关则是高估了结果,如果是负相关,则是低估了结果。
工具变量法的检验
使用工具变量法进行估计时,我们需要对工具变量进行三项检验,分别为:内生性检验、相关性检验、外生性检验。
1、内生性检验
内生性检验即检验核心变量是否具有内生性。如果我们关心的核心解释变量不具有内生性,我们就没有必要使用工具变量法进行估计,而如果我们使用了工具变量法虽然得到了一致估计量,但并不是有效估计量。
2、相关性检验
相关性检验是检验工具变量是否与内生变量之间存在强相关关系。如果使用的工具变量是弱工具变量,则会导致内生变量估计的标准系数偏大。
3、外生性检验
外生性检验是检验工具变量是否与误差项不相关。如果工具变量与误差项相关,则不满足外生性条件,那么使用工具变量法估计很可能会比OLS估计的结果更糟糕。
工具变量法的检验方法
对工具变量的三大检验,一般来说,我们应该先做相关性检验,因为,如果存在弱工具变量,则两阶段最小二乘法的估计结果会比OLS的估计结果更加糟糕。此外,弱工具变量会使内生性检验的Hausman test和外生性检验的Hansen’s J的结果产生偏差。
1、相关性检验方法
相关性检验是通过构造辅助回归来对工具变量与内生变量之间的相关性进行检验。构造的辅助回归即为两阶段最小二乘法的第一阶段,用所有的外生解释变量(包括工具变量)对潜在的内生解释变量做OLS回归。
对辅助回归的结果,我们首先观察工具变量的系数符号是否符合理论预期,其次观察F值是否大于10,如果大于10则表明工具变量与内生解释变量存在强相关
以Acemoglu等人2001年的论文举例说明,文章中的变量如下所示。
[外链图片转存中…(img-hchT7gF8-1640317583200)]
由于制度与人均GDP之间存在着双向因果关系,所以制度是内生变量。为了解决制度变量的内生性问题,Acemoglu等人选择的工具变量是殖民地的死亡率。这是因为,殖民地的死亡率越高,殖民者就越不倾向于移植好的制度,而更倾向于采取掠夺性的制度安排,而那时的制度对现在仍然有影响。
使用Acemoglu等人的截面数据做第一阶段OLS回归,结果如下所示。
reg avexpr logem4 lat_abst
[外链图片转存中…(img-n1c8sR0y-1640317583201)]
由检验结果可知,F值等于12.82,大于10,表明工具变量与内生性变量之间存在着强相关关系。此外,工具变量logem4对内生性变量avexpr产生了显著的负向影响,这符合工具变量背后的逻辑。
** 我们也可以使用如下命令进行相关性检验。
ivreg logpgp95 last_abst(avexpr=logem4),first
### ivreg命令是在括号中"=“的左边放入内生性解释变量”="的右边放入工具变量,选项[first]表示既报告第一阶段的回归结果也报告第二阶段的回归结果。
上面的两种检验工具变量与内生变量相关性的方法适合于方程中存在一个内生性解释变量。那么,如果方程中有多个内生性解释变量,我们又该如何做先关性检验呢。
Stock/Yogo给出了检验规则:
如果弱识别检验的最小特征值统计量大于Stock/Yogo的15% maximal IV size所对应的临界值,我们就可以认为工具变量不存在弱相关问题。
对多个内生性变量进行相关性检验的命令为[ivreg2]或者[xtivreg2]
仍以上文的例子为例,对内生性解释变量使用命令[ivreg2]进行检验,结果如下所示。
ivreg2 logpgp95 last_abst(avexpr=logem4)
[外链图片转存中…(img-4yvCOahn-1640317583202)]
由检验结果可知,弱识别检验的最下特征值统计量为13.09,大于所对应的临界值8.96,所以,我们可以认为工具变量不存在弱相关。
###如果检验结果显示为弱工具变量,我们又该如何解决呢?
一般有三种办法来解决弱工具变量问题。
- 选择更好的工具变量
- 做冗余检验将弱相关的工具变量剔除掉,冗余检验的原假设是指定的工具变量是多余的,ivreg/xtivreg2提供了选项redundant(varlist)
- 利用有限信息最大似然法(LIML)对弱工具变量不敏感。在大样本下,LIML与两阶段最小二乘估计是渐进等价的,当存在弱工具变量时,LIML的小样本性质可能优于两阶段最小二乘法。具体实现命令为:(ivreg …,liml)或(ivreg2 …,liml)
2、内生性检验方法
内生性检验首先假定模型中存在内生性解释变量进行两阶段最小二乘回归;然后再假定不存在内生性变量进行普通回归;最后使用Hausman检验对内生性问题进行检验。
如果检验结果的P值小于0.1,表明两个回归系数存在显著的系统性差异,意味着关注的核心变量具有内生性。如果P值大于0.1,表明两个回归系数不存在系统性差异,意味着关注的核心变量不存在内生性问题。
继续以Acemoglu等人的数据为例进行内生性检验,Hausman检验程序为:
ivreg logpgp95 lat_abst(avexpr=logem4)
est store iv
reg logpgp95 lat_abst avexpr
hausman iv
[外链图片转存中…(img-wB2f0yFz-1640317583203)]
检验结果显示,P值为0.0453,小于0.1,拒绝原假设,表明两个模型的回归系数在10%的显著性水平下存在显著性的差异,认为检验的变量是内生性变量。
### 内生性检验有一个非常便捷的命令,即[ivreg2,endog]或[xtivreg,endog()],我们只要在上述命令中将内生变量放入endog选项中即可。我们也可以直接输入命令
ivreg2 logpgp95 lat_abst(avexpr=logem4),endog(avexpr)
[外链图片转存中…(img-SZoZlCHR-1640317583204)]
由检验结果我们可以看到,P值为0.0001,同样表明制度变量是内生性变量。
3、外生性检验
如果我们选择的工具变量的个数恰好等于内生变量的个数,这时是恰好识别的,这种情况公认是无法进行外生性检验的即检验所选择的工具变量是否和误差项不相关,我们只能定性讨论或依赖于专家的意见。
如果是过度识别的情况即工具变量的个数大于内生变量的个数,我们就可以检验所选择的工具变量是否与误差项不相关。对工具变量外生性的检验我们可以使用命令ivreg2或者xtivreg2。检验的原假设是工具变量与误差项不相关。当P值小于0.1时拒绝原假设,说明工具变量与误差项相关,工具变量不具有外生性;当P值大于0.1时,接受原假设,说明工具变量与误差项不相关,工具变量具有外生性。
### 值得注意的是,ivreg2 和 xtivreg2可以同时做上述三大检验。
此外,在上述的分析中,我们没有考虑模型误差项的异方差和自相关问题,如果误差项存在异方差或自相关时,两阶段最小二乘虽然是一致估计量但却并不是有效估计量,而更为有效的方法是“广义矩估计(GMM)”,GMM方法使用的前提条件是工具变量数大于内生变量数,两阶段最小二乘估计存在异方差或自相关。
GMM的实现命令为:直接在ivreg2或xtivreg2命令之后添加gmm选项即可。
(七)动态面板数据模型及估计方法
面板数据分析与Stata应用笔记整理自慕课上浙江大学方红生教授的面板数据分析与Stata应用课程,笔记中部分图片来自课程截图。
笔记内容还参考了陈强教授的《高级计量经济学及Stata应用(第二版)》
在笔记(六)中我们写到了内生性问题的处理以及工具变量法,然而在实际操作中工具变量却并不是很容易寻找到,但是动态面板数据模型可以解决内生性问题。
一、理论知识
面板数据的一个优点是可以对个体的动态行为进行建模。有些经济理论认为,由于惯性或部分调整,个体的当前行为取决于过去的行为,比如企业今年招聘雇员会受到上一年招聘雇员的影响,企业今年的投资决策也会受到去年投资的影响。
动态面板数据(Dynamic Panel Data,简记DPD):是指在面板模型中,解释变量包含了被假释变量的滞后值。在动态面板数据模型中,被解释变量和上一期变量之间存在关系,即 y i , t y_{i,t} yi,t和 y i , t − 1 y_{i,t-1} yi,t−1 之间是有关系的,上一期的值决定着下一期的值。
动态面板数据模型的设定是在原有的静态面板数据模型的基础上引入被解释变量的滞后期,而其他的都相同。
[外链图片转存中…(img-0dTR1EnL-1640317583205)]
其中, [外链图片转存中…(img-AXTo7cUs-1640317583206)] 为复合误差项, u i t = u i + v i t u_{it}=u_i+v_{it} uit=ui+vit , [外链图片转存中…(img-AJ6MdH43-1640317583207)] 为随机扰动项; [外链图片转存中…(img-cFJnXr70-1640317583208)] 为不可观测的个体效应。
可以很容易的看出,模型中 [外链图片转存中…(img-0TzUGyEg-1640317583210)] 是一个内生变量,模型存在内生性问题,所以使用传统的最小二乘进行估计,估计结果是有偏且不一致的。
对上述的动态面板数据模型进行拟合估计:首先进行一阶差分将原始模型中的不可观测的个体效应 去除,得到差分后的模型为:
[外链图片转存中…(img-QyPGSQUD-1640317583210)]
由于 [外链图片转存中…(img-k3qJ1t6a-1640317583211)] 与 [外链图片转存中…(img-PKRSQj93-1640317583212)] 相关,所以 [外链图片转存中…(img-edshOlHy-1640317583213)] 与 $\Delta \varepsilon_{i, t-1} $是相关的,所以一阶差分后的动态面板数据模型仍存在内生性问题。Anderson等人在1982年提出了一种为差分变量 y t , i − 1 y_{t,i-1} yt,i−1 寻找工具变量的方法。这个工具变量为 [外链图片转存中…(img-z6c2TzDl-1640317583214)] 。由于差分变量本身包含着 [外链图片转存中…(img-XJgKdDvv-1640317583214)] ,所以工具变量和内生变量存在高度的相关性,在误差项 ε i t \varepsilon_{it} εit不存在自相关的前提下,工具变量 y i t − 2 y_{it-2} yit−2与误差项的差分 ε i , t − ε i , t − 1 \varepsilon_{i, t}-\varepsilon_{i, t-1} εi,t−εi,t−1 不相关,因此, [外链图片转存中…(img-TC314wWC-1640317583215)] 满足工具变量的条件。
Anderson,T.W.,and C.Hsiao(1982)."Formulation and Estimation of Dynamic Models Using Panel Data,"Journal of Econometrics,18,47-82.
[外链图片转存中…(img-DZAJXShv-1640317583216)]
需要注意的是, [外链图片转存中…(img-J54EEcJe-1640317583217)] 并不是唯一可使用的工具变量,被解释变量滞后三期、四期的变量都满足工具变量的条件,Arellano等人1991年曾提到这些。
Arellano,M.,and S.Bond(1991).“Some Tests of Specification for Panel Data:Monte Carlo Evidence and an Application to Employment Equations,” Review of Economic Studies,58,277-297.
同时,他们认为这种相当于两阶段最小二乘估计的结果虽然是一致的,但却并不是有效的,因为他们没有充分利用样本里的所有信息,于是他们提出了**使用更多工具变量的广义矩估计方法(GMM)**来进行动态面板数据模型的估计,工具变量来自更多的滞后期。
差分GMM和系统GMM
动态面板数据模型的GMM估计方法又可以分为两种,即差分GMM(DIF-GMM)和系统GMM(SYS-GMM)估计方法。
需要注意的是,差分GMM和系统GMM方法主要适用于短动态面板数据。这是因为,虽然基于IV或GMM的估计方法是一致估计量(即当 [外链图片转存中…(img-amHwVMat-1640317583218)] 时,没有偏差),但对于n较小而T较大的长面板则可能存在较严重的偏差。对于长动态面板数据模型的估计可以使用“偏差校正LSDV法”进行估计。
差分GMM估计方法和系统GMM估计方法都可以对动态面板数据进行估计。早前,差分GMM估计方法被使用的较多,在学术界被广泛用来处理动态面板数据模型中的严重内生性问题。
**差分GMM的基本思路是:**对基本模型进行一阶差分以去除固定效应的影响,然后,用一组滞后的解释变量作为差分方程中相应变量的工具变量。
Blundell和Bond两位作者认为,差分GMM的估计量较易受弱工具变量的影响而产生向下的大的有限样本偏差。为了克服这一问题,Blundell和Bond提出了系统广义矩估计即系统GMM估计方法。
系统GMM估计方法是基于差分GMM之上形成的,结合了差分方程和水平方程,此外,还增加了一组滞后的差分变量作为水平方程相应的工具变量,更具有系统性。
相对来说,系统GMM估计量具有更好的有限样本性质。
**系统GMM估计方法的前提假定是:**工具变量的一阶差分与固定效应项不相关。然而,到目前为止,并没有方法能够对这一个假定进行检验。
此外,使用系统GMM估计方法的条件是:
(1)大N小T,即短面板数据;
(2)线性函数关系,构造的计量模型要求是线性的;
(3)方程等号左边的变量作为动态变量;
(4)方程等号右边的变量并不是严格外生的;
(5)控制个体固定效应;
(6)默认不存在截面相关问题,并且建议采用双向固定效应。
时间虚拟变量的引入可以使误差项的截面相关变得不相关,所以在模型设定中尽可能地引入时间虚拟变量以减少截面相关的可能。
在理论层面,GMM估计量(差分GMM、系统GMM)的一致性关键取决于各项假设条件是否满足,这需要进行两个假设检验。
(1)通过Hansen(Sargan)过度识别约束检验对所使用的工具变量的有效性进行检验,此检验的原假设是所使用的工具变量与误差项是不相关的。
(2)通过Arellano-Bond的自相关检验方法对差分方程的随机误差项的二阶序列相关进行检验,其原假设是一阶差分方程的随机误差项中不存在二阶序列相关。如果不拒绝原假设则意味着工具变量有效和模型设定正确。
在自相关的检验中,误差项的一阶差分存在一阶自相关而不存在二阶自相关,所以AR(1)的P值应该小于0.1,AR(2)的P值应该大于0.1,两者需要同时成立。
此外,过多的工具变量会使得估计结果失去效率,xtabond2命令提供了选项“collapse”可以通过限定滞后期数来控制工具变量的个数。
最后,在操作层面,如何证明GMM的估计结果是有效可行的呢?
对于GMM估计结果是否有效可行,Bond等人(2002)给出了一种简单的检验方法:如果GMM估计值**介于固定效应估计值和混合OLS估计值之间**,则GMM估计是可靠有效的。
这是因为:被解释变量滞后一期 与复合误差项存在正向关系,使用OLS估计通常会导致滞后项系数产生向上的偏误。而动态面板数据模型采用固定效应估计时,进行的是组内离差变换,由于 与 存在正相关性,所以进行离差变换后, 的组内离差与误差项的组内离差之间存在着负相关,这会使滞后项系数产生一个严重向下的偏误。
工具变量数不要超过截面数
Roodman(2006)指出太多的工具变量可能会过度拟合内生变量而不能去掉内生部分。此外,过度的工具变量还可能弱化Hansen过度识别约束检验,使得Hansen检验的p值等于1.00,所以在对面板数据进行估计时,应尽可能地满足拇指规则,即工具变量数不超过截面数,在Hansen检验接近1时,需要使用lag(# #)选项与“collapse”选项将工具变量压缩,使得p值小于1.00,而不是很接近于1。
二、动态面板数据模型Stata命令及实例
使用英国140家企业1976-1984年的数据来研究就业问题,数据集是一个非平衡面板数据。其中,被解释变量为n,是就业的对数,存在着两期滞后;重要的解释变量有当期和滞后一期的工资水平w,当期、滞后一期和滞后两期的资本存量k,以及当期、滞后一期和滞后两期的公司产出ys,所有的变量都取对数形式,对所有的时间虚拟变量都加以控制来捕捉经济周期的影响。
使用【des】命令查看数据集信息,结果如下所示
[外链图片转存中…(img-adH45h4W-1640317583219)]
输出结果中,因为数据集是非平衡面板数据,所以时间虚拟变量只有五个。
使用【sum】命令对关键变量进行描述统计,结果如下所示:
[外链图片转存中…(img-8DTZhwGW-1640317583219)]
(一)常规方法的估计与分析
首先,我们对动态面板数据模型进项OLS估计(估计结果是有偏且不一致的),结果如下所示。
reg n nL1 nL2 w wL1 k kL1kL2 ys ysL1 ysL2 yr*
也可以直接使用滞后一期
reg n L.n L2.n w L.W k L.K L2.k ys L.ys L.ys L2.ys yr*
注意使用* 需要先生成年份的虚拟变量
xi: reg n L.n L2.n w L.W k L.K L2.k ys L.ys L.ys L2.ys i.year
[外链图片转存中…(img-YPD1SO9x-1640317583220)]
由拟合结果我们可以看到,被解释变量滞后一期的系数为1.045,因为OLS的估计结果会偏大,所以真实的估计系数应该小于1.045。
我们只关心被解释变量滞后一期的系数大小,而不关心其显著性。
接下来,我们使用LSDV方法进行双向固定效应估计,结果如下所示。
xtreg n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.id i.year
[外链图片转存中…(img-o2KfwUpw-1640317583221)]
由拟合结果可知,被解释变量滞后一期系数的估计结果为0.733。由上文的分析可知,由于被解释变量滞后一期 的组内离差与误差项的组内离差存在负相关系,固定效应的估计结果会产生一个严重向下的偏误系数,从而低估了被解释变量滞后一期真实系数大小,所以真实值应该大于0.733。综述,结合普通最小二乘法的估计结果,我们可以初步确定被解释变量滞后一期的真实系数应该介于0.733与1.045之间。
Anderson的方法,使用一个工具变量,发现不ok
ivregress 2sls D.n (D.nL1=nL2) D.(nL2 w Wl1 k kL1 kL2 ys ysL1 ysL2 yr1979 yr1981 yr1982 yr1983)
难以解决动态面板的内生性问题
ivreg D.n (D.L.n= L2.n) D.( L2.n w L.w k L.k L2.k ys L.ys
L2.ys yr1980 yr1981 yr1982 yr1983 yr1984)
(二)GMM估计方法的Stata命令
对差分GMM与系统GMM的估计,Stata提供了官方的和非官网的两种命令。两者的区别在于官方的命令xtabond与xtdpdsys均不提供异方差稳健的Hansen统计量而是仅仅提供基于iid假设的Sargan统计量,而非官方的命令xtabond2则提供Hansen统计量。Sargan检验不稳健但不受弱工具变量的影响;Hansen检验稳健但容易受到弱工具变量的影响。当工具变量数非常的多,接近或超过截面数时便会出现弱工具变量问题。
1、差分GMM的Stata官方命令:xtabond
差分GMM的Stata官方命令格式如下所示
[外链图片转存中…(img-a7tOMvfU-1640317583222)]
xtabond depvar indepvars,lags(p) maxldep(q) twostep vce(robust) pre(varlist) endogenous(varlist) inst(varlist)
其中,“depvar”为被解释变量,“indepvars”为满足严格外生性的解释变量。
选项“lags§”表示使用被解释变量的p阶滞后值作为解释变量,默认值为p=1;
“maxldep(q)”表示最多使用q阶被解释变量的滞后值作为工具变量,默认值为使用所有可能的滞后值。
选项“twostep”表示使用GMM,默认方法为2SLS即一步GMM;
选项“pre(varlist)”,“endogenous(varlist)”,“inst(varlist)”分别用来指定前定变量、内生变量和额外的工具变量。
选项“vce(robust)”表示使用稳健标准误,该稳健标准误允许 存在异方差,而且针对两步GMM的估计进行了调整,在Stata中称为“WC-Robust Standard Error”(Windmeijer,2005;其中WC表示“Windmeijer bias-corrected”)。
nolevel 使用差分GMM
small 纠正小样本的结果
nomata 让数据跑出结果来
==**前定变量:**如果 x i , t x_{i,t} xi,t 是前定变量,则 [外链图片转存中…(img-1spyPTg6-1640317583223)] 与当期误差项 ε i , t \varepsilon_{i,t} εi,t不相关,但与上一期误差项 [外链图片转存中…(img-NPtVxNB4-1640317583224)] 相关。==例如,模型中被解释变量的滞后一期即为前定变量。为前定变量 [外链图片转存中…(img-HC9orEcG-1640317583225)] 的一阶差分寻求的工具变量可以是 x i , t − 1 , x i , t − 2 x_{i,t-1},x_{i,t-2} xi,t−1,xi,t−2 等等。
此外,如果 [外链图片转存中…(img-3m1FFLEW-1640317583225)] 是前定变量,那么 [外链图片转存中…(img-TN3bm7fz-1640317583226)] 是外生变量。所以前定变量的滞后一期即为外生变量,同样,滞后两期、三期也为外生变量。如果一个变量 [外链图片转存中…(img-wF9L85Yu-1640317583227)] 是内生变量,那么滞后一期 [外链图片转存中…(img-BTCiAoTi-1640317583227)] 是前定变量,滞后两期开始为外生变量。
xi: xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year, gmm(L.n) iv(L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year) nolevel robust small nomata
sagen检验不稳健,但是不受到weak iv的影响。
hassen检验结果稳健,但是受到weak iv 的影响。
2、系统GMM的Stata官方命令:xtdpdsys
系统GMM的Stata官方命令格式如下所示
xtdpdsys depvar [indepvars],lags(p) maxldep(q) twostep vce(robust) pre(varlist) endogenous(varlist) inst(varlist)
其中各参数的含义与差分GMM的相同。
xi: xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year, gmm(L.n, lag(2 5)) iv(L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year) nolevel robust small nomata
lag( )滞后期为2-5
然后看p值和hassen值
3、非官方xtabond2命令
首次使用xtabond2需要通过命令【ssc install xtabond2】进行安装。
xtabond2命令较为复杂,我们可以在Stata中通过命令【help xtabond2】来查看xtabond2的具体使用方法。
[外链图片转存中…(img-ODb659e6-1640317583228)]
xtabond2常用的格式为:
xtabond2 depvar varlist ,gmm(varlist,lag(# #) collapse) iv(varlist) nolevel twostep robust noconstant small or
其中,“depvar”为被解释变量,“varlist”为全部的解释变量。
选项“gmm(varlist)”表示放入模型中所有的前定变量与内生变量,以**“变量”+“,”+“lag(# #)”**的方式限定变量的滞后期作为其工具变量,
必要时我们可以加上“collapse”,这个选项可以极大的压缩工具变量数;
选项“iv(varlist)”表示放入模型中所有的外生解释变量;
选项“nolevel”表示进行差分GMM估计,默认为系统GMM估计;
选项“twostep”为两步GMM估计,默认为一步GMM估计;
选项“robust”表示提供稳健的标准误;
选项“noconstant”表示不要常数项;
选项“small”在样本量特别小的时候使用,用以纠正小样本估计量;
选项“or”表示采用正交变换。
简略写法:
xtabond2 n L.n L2.n w L1.w L(0.2).(k ys) yr*, gmm(L.(n w k)) iv L(0.2).ys yr*) nolevel robust small
详细写法
[外链图片转存中…(img-5ikoxcLC-1640317583229)]
stata呈现结果相同
(三)差分GMM方法估计与分析
官方的命令xtabond与xtdpdsys的实例操作可以参考陈强教授《高级计量经济学及Stata应用(第二版)》书中的案例。
使用非官方命令xtabond2进行差分GMM估计:
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L2.ys i.year,gmm(L.n) iv(L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year) nolevel robust small
上述Stata命令中n为被解释变量;L.n、L2.n、w、L.w、k、L.k、L2.k、ys、L2.ys为解释变量;i.year为控制年份虚拟变量。命令只考虑L.n为前定变量,其余解释变量均为外生变量;“robust”表示使用稳健标准误来处理异方差和自相关问题;“small”用于修正小样本估计量。
[外链图片转存中…(img-hugdYaZx-1640317583230)]
由拟合结果可知,工具变量数(Number of instruments)为41个,截面数(Number of groups)是140。被解释变量滞后一期的系数为0.686。
对估计的Arellano-Bond的自相关与Hansen过度识别进行检验,结果如下:
[外链图片转存中…(img-rY7HF87j-1640317583230)]
由检验结果可以知道,AR(1)的p值为0.000,AR(2)的p值为0.606,这表明存在一阶自相关而不存咋二阶自相关,通过了自相关检验;Hansen检验结果显示所对应的p值为0.114,大于0.1,所以工具变量的有效性通过了检验。
在常规方法的估计中我们知道,被解释变量滞后一期的真实系数应该介于0.733与1.045之间。而上述差分GMM的结果为0.686,被解释变量滞后一期的系数值并不处于常规方法的区间范围之内。
所以,我们对上诉估计命令进行进一步的修正。
首先,改变工具变量的滞后期数。考虑使用被解释变量滞后2-5期与2-4期作为被解释变量滞后一期(前定变量)的工具变量。只需在**gmm()**中加入相应的滞后期数即可。
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n,lag(2 5)) iv(L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year) nolevel robust smallxi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n,lag(2 4)) iv(L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year) nolevel robust small
[外链图片转存中…(img-tyJPWvG3-1640317583231)]
表格中的第一列为我们进行差分GMM估计最初得到的结果,允许使用前定变量L.n的所有滞后期作为工具变量来进行估计;第二列则是使用前定变量的滞后2-5期作为工具变量进行估计;第三列为使用前定变量的2-4期作为工具变量进行估计。
通过表中的结果我们可以看到,第二列的结果即使用前定变量的滞后2-5期作为工具变量进行估计,结果处于0.733-1.045之内,而使用滞后2-4期则是操作了区间范围。
由此可见,控制滞后期数可能是解决系数估计值未处于给定范围之内的方法之一。
此外,将w和k作为内生变量进行拟合,改变估计命令。
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n,lag(1 .)) gmm(w,lag(2 .)) gmm(L.w) gmm(L.k) gmm(k,lag(2 .)) iv(L2.n L2.k ys L.ys L2.ys i.year) nolevel robust small
上述命令也可以写作,三个命令是等价的:
命令一:
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n) gmm(w k,lag(2 .)) gmm(L.w L.k) iv(L2.n L2.k ys L.ys L2.ys i.year) nolevel robust small
或命令二:
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n L.w L.k) iv(ys L.ys L2.ys i.year) nolevel robust small
如果变量x是内生变量,它的工具变量是它的滞后两期L2.x。
当模型中仅出现x时,Stata命令中既可以使用gmm(L.x)处理,也可以使用gmm(x,lag(2 .)),两者是等价的。
当x和L.x同时出现在模型中时,为了避免重复,只需要写gmm(L.x)即可。
[外链图片转存中…(img-6Dm2pTXE-1640317583232)]
[外链图片转存中…(img-iAAYokvJ-1640317583232)]
由上述结果可知,被解释变量滞后一期系数的估计值为0.818,处于0.733-1.045之内,且Arellano-Bond自相关检验与Hansen检验均通过。
Arelano与Bover两位作者在1995年提出了采用正交变换的方法。他们认为当数据集是非平衡面板数据集时,进行一阶差分时会损失一些数据,使用向前正交变换即用当期值减去前面期数所有观测值的平均值可以减少数据量的损失。在Stata中我们只需要在命令的最后加入选项“or”即可实现这一操作。
(四)系统GMM方法估计与分析
在理论部分我们知道Blundell和Bond两位作者认为,差分GMM的估计量较易受弱工具变量的影响,从而产生向下的大的有限样本偏差。为了克服这一问题,Blundell和Bond提出了系统广义矩估计即系统GMM估计方法。
使用xtabond2命令进行系统GMM估计。
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n L.w L.k) iv(ys L.ys L2.ys i.year) robust small
[外链图片转存中…(img-1rqSny68-1640317583235)]
由拟合结果可知,系统GMM估计的被解释变量滞后一期的系数为1.06,在0.733-1.045之外。这个结果与我们所期待的结果并不一致。
工具变量较多时
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n L.w L.k,collapse) iv(ys L.ys L2.ys i.year) robust small
[外链图片转存中…(img-6Tgx34E1-1640317583236)]
[外链图片转存中…(img-wlS5QksE-1640317583236)]
两步GMM
[外链图片转存中…(img-resLnPFn-1640317583237)]
如果想对两种gmm进行对比,两种变量保持一致
[外链图片转存中…(img-h4HwHAyF-1640317583238)]
为什么系统GMM这种相对更好的估计方法却得到了不理想的结果呢?
再次观察估计结果可以发现,工具变量数为112,非常的多,解决截面数140,所以我们需要处理过多的工具变量,使用上文提到的==“collapse”==选项修改Stata命令,结果如下:
xi:xtabond2 n L.n L2.n w L.w k L.k L2.k ys L.ys L2.ys i.year,gmm(L.n L.w L.k,collapse) iv(ys L.ys L2.ys i.year) robust small
[外链图片转存中…(img-btR0WRFG-1640317583238)]
观察拟合结果可以发现,调整后的工具变量数为34,相比于之前的112大大减少,而被解释变量滞后一期的系数为0.948,处于0.733-1.045之间。
对估计的Arellano-Bond的自相关与Hansen过度识别进行检验,结果如下:
[外链图片转存中…(img-QL7eeesW-1640317583240)]
由检验结果可知,两大检验均通过了显著性检验。
[外链图片转存中…(img-uPKMkC5N-1640317583241)]
时间虚拟变量的引入可以使误差项的截面相关变得不相关,所以在模型设定中尽可能地引入时间虚拟变量以减少截面相关的可能。
最后,对于截面相关的问题,在动态面板数据中也可能是存在的。现在最新的研究已经有了处理动态面板数据截面相关问题的方法,即xtbcfe命令。
[外链图片转存中…(img-U64QaUf5-1640317583242)]
BCFE估计的优点
第一,BCFE估计适用于小样本高阶滞后项动态面板数据模型,并且无论是平衡面板数据还是非平衡面板数据,BCFE估计都能解决一般化异方差和当期截面自相关问题;
第二,使用Monte Carlo模拟可以发现,当数据样本为具有很小或者相对较小的T时,BCFE估计可以修正标准FE的小样本估计偏误,回归结果要优于差分GMM和系统GMM估计结果。
第三,在面对小样本数据结构时,BCFE估计也不会受到条件异方差的影响。这意味着,BCFE不适用于较大样本或T没有过度小于N的数据样本的动态面板数据模型的估计。而BCFE不适用的领域系统GMM则做的相对较好。
xtbcfe命令的具体使用以及各个参数的含义可以在Stata中通过命令【help xtbcfe】进行查看。
[外链图片转存中…(img-ey9NLPt3-1640317583242)]
[外链图片转存中…(img-G2cvip67-1640317583243)]


[外链图片转存中…(img-lJFu5Vme-1640317583245)]

前置变量的工具变量就是前置变量的滞后一期 内生变量的工具变量就是滞后两期
两步估计才是标准的GMM估计
太多的工具变量会使得Hansen检验的p值等于 1.00 1.00 1.00, 所以在Hansen检 验接近1时, 要采用lag ( ) 选项与 collapse选项将工具变量压缩, 使得p 值小于 1.00 1.00 1.00, 而不是很接近于 1 。

最后的计量结果报告
ols + lsdv + 系统gmm +差分gmm +bcfe抽样的结果
报告一下sagen 和hansen 检验的结果 AR1,AR2
lag的滞后期
工具变量的个数(不要超过截面数,避免出现若工具变量问题)
两阶段最小二乘和gmm的关系:两阶段最小二乘 虽然是一致的,但不是有效的估计量,因为没有充分利用所有的样本信息。
(八)面板门限模型
面板数据分析与Stata应用笔记整理自慕课上浙江大学方红生教授的面板数据分析与Stata应用课程,笔记中部分图片来自课程截图。
笔记内容还参考了陈强教授的《高级计量经济学及Stata应用(第二版)》
我们在做经验研究的时候通常遵循这样的几个步骤:
- 首先,是分析研究我们关注的核心变量对被解释变量产生的影响(这个影响是一个平均效应);
- 其次,是进行对估计的模型进行稳健性检验,从不同的角度来探讨这个平均效应的结果是否稳健;
- 然后,是机制分析,探讨研究我们所关注的核心解释变量是如何影响被解释变量的;
- 最后,是异质性分析,探讨关键的解释变量在不同的条件下可能会对被解释变量产生什么样的影响。
本篇笔记的内容面板门限模型实际上就是做异质性分析。
寻找异质性的典型的处理方法有:
- 在模型中加入解释变量的二次项,以查看解释变量和被解释变量之间是否存在“U”型或倒“U”型的关系。
- 将交互项引入模型。
- 对数据进行分组回归。
需要注意的是,上述的对异质性处理的方法可能会存在高度共线性的问题,从而使得变量不再显著。此外,在对数据的分组上也存在一定的困难。于是,面板门限模型便成为了一种较好的异质性分析的方法。
一、门限回归
在回归分析中,我们常常关心模型系数的估计值是否稳定,即如果将整个样本分成若干个子样本(subsample)分别进行回归,是否还能够得到大致相同的估计系数。对于时间序列数据,这意味着经济结构是否随着时间的推移而改变;对于横截面数据,比如,样本中有男性与女性,则可以根据性别将样本一分为二,分别估计男性样本与女性样本。
如果用来划分样本的变量不是离散型变量而是连续变量,比如,企业规模、人均国民收入,则需要给出一个划分的标准,即“门限(门槛)值”(threshold level)。
在应用研究中,门限变量的应用是非常的广泛。经济规律可能是非线性的,其函数形式可能会依赖于某个变量(称为“门限变量”)而改变。
- 比如,人们常常怀疑大企业与小企业的投资行为不同,那么如何区分大企业与小企业呢?
- 另外,受到流动性约束(liquidity constraint)的企业与没有流动性约束企业的投资行为也可能不同,如何通过债务股本比(debt to equity ratio)或其他指标来区分这两类企业?
- 再比如,发达国家与发展中国家的经济增长规律可能不同,如何通过人均国民收入这一指标来区分一个国家发达与否?
对门限模型的拟合,传统的做法是,由研究者主观(随意)地确定一个门限值,然后根据此门限值把样本一分为二(或分成更多子样本)。这种方法既不对门限值进行参数估计,也不对其显著性进行统计检验。
显然,这样得到的结果并不可靠。为此,Hansen(2000)提出“门限(门槛)回归”(threshold regression),以严格的统计推断方法对门限值进行参数估计与假设检验。
假设样本数据为 [外链图片转存中…(img-gJgNeL9Y-1640317583247)] ,其中 [外链图片转存中…(img-4BPkAIJm-1640317583248)] 为用来划分样本的==“门限变量”==(threshold variable), [外链图片转存中…(img-hAdo3ewu-1640317583249)] 可以是解释变量的一部分。考虑以下门限回归模型:
关心的核心变量本身也可以当做门限变量。
[外链图片转存中…(img-0Uy2gEHN-1640317583249)] (1)
其中, [外链图片转存中…(img-h9AM3DKn-1640317583250)] 为待估计的门限值, [外链图片转存中…(img-5845MHU3-1640317583250)] 为外生解释变量,与扰动项 [外链图片转存中…(img-44gWZr6U-1640317583251)] 不相关。上面的分段函数可以合并写为:
[外链图片转存中…(img-Qv8xCJnH-1640317583252)]%2B{{\beta+’}_2}{x_i}·1({{q_i}>\gamma+})+%2B+{\varepsilon+_i}}) (2)
其中, [外链图片转存中…(img-H5FWjCX1-1640317583252)]) 为示性函数,即如果括号中的表达式为真,则取值为1;反之,取值为0。显然,这是一个非线性回归,因为它无法写成参数 [外链图片转存中…(img-9rBK5qkZ-1640317583253)]) 的线性函数。可以用非线性最小二乘法(NLS)来估计,即最小化残差平方和。
事实上,如果 [外链图片转存中…(img-v043x9w7-1640317583254)] 的取值已知,则可以通过定义 [外链图片转存中…(img-G5iObUSv-1640317583254)]) 与 [外链图片转存中…(img-Jbkw8OeU-1640317583256)]) ,将上述方程转换为参数为 [外链图片转存中…(img-JrJlkfnF-1640317583256)]) 的线性回归模型:
[外链图片转存中…(img-5XP52HFU-1640317583257)] (3)
因此,在实际计算中,通常分两步来最小化残差平方和从而确定门限值 [外链图片转存中…(img-oaKE70Av-1640317583258)] 的取值,即首先给定 [外链图片转存中…(img-Ew9wmaSJ-1640317583258)] 的取值,对方程(3)进行OLS估计得到残差平方和关于 [外链图片转存中…(img-UzohHfsO-1640317583259)] 的函数 [外链图片转存中…(img-3REaqvaY-1640317583260)]) ;其次,选择 [外链图片转存中…(img-UN3pZQO5-1640317583260)] 使得 [外链图片转存中…(img-8LYwTBTm-1640317583261)] 最小化。
二、面板数据的门限回归
对于面板数据 [外链图片转存中…(img-ICqVpEYL-1640317583261)] ,其中 [外链图片转存中…(img-0tXjR6Yj-1640317583262)] 表示个体, [外链图片转存中…(img-lqqP6GGV-1640317583263)] 表示时间,Hansen(1999)考虑了如下的固定效应(fix effects)门限回归模型:
[外链图片转存中…(img-u6qaAEWB-1640317583263)] (4)
其中, [外链图片转存中…(img-ihdRcKKq-1640317583264)] 为门限变量(可以是解释变量 [外链图片转存中…(img-4CjX7RfB-1640317583265)] 的一部分), [外链图片转存中…(img-X0o9hD6m-1640317583265)] 为待估计的门限值,扰动项 [外链图片转存中…(img-IsvBhiJx-1640317583266)] 为独立同分布的。
假设解释变量 [外链图片转存中…(img-aNoZSQJh-1640317583267)] 为外生变量,与扰动项 [外链图片转存中…(img-JU7RuLRD-1640317583267)] 不相关。因此, [外链图片转存中…(img-BzYIhuuJ-1640317583268)] 不包含被解释变量 y i t y_{it} yit 的滞后值,不是动态面板。个体截距项 [外链图片转存中…(img-4oJXRHSo-1640317583269)] 的存在表明,这是固定效应模型。使用示性函数 [外链图片转存中…(img-OqTfJ2qY-1640317583270)]) ,可以将模型更简洁地表示为
[外链图片转存中…(img-fLN9MLRw-1640317583270)]%2B{{\beta+’}2}{x{it}}·I({{q_{it}}>\gamma+})+%2B+{\varepsilon+_i}}) (5)
关于门限值 [外链图片转存中…(img-Zux54YHI-1640317583271)] 的确定,在实际研究中,我们首先将样本按照门限变量 [外链图片转存中…(img-5XePL3LZ-1640317583272)] 的大小进行升序排列,需要注意的是,为了使得到的门限值有意义,排列时忽略 [外链图片转存中…(img-nDyRZVW1-1640317583273)] 最大的 [外链图片转存中…(img-WbzZK1Ld-1640317583273)] 个样本和最小的 [外链图片转存中…(img-p7SZlkso-1640317583275)] 个样本,仅以中间的样本作为门限值的候选范围。
为了提高门限值估计的精确度,Hansen在门限回归中使用了“格栅搜索法”(Grid Search)来连续给出门限回归中的候选门限值 [外链图片转存中…(img-bh4IaY9B-1640317583276)] 。首先,以0.0025作为格栅化水平将候选门限值范围进行格栅化处理;然后,用格栅化得到的全部格栅点作为候选门限值 [外链图片转存中…(img-F9jwFye7-1640317583277)] ,并分别进行回归计算出相对应的模型的残差平方和,选择使模型残差平方和最小的候选门限值作为回归估计的真实门限值。
类似的,可以考虑多门限的面板回归模型。以两个门限值为例:
[外链图片转存中…(img-stjWLYf4-1640317583278)]+%2B+{{\beta+’}2}{x{it}}+\cdot+I({\gamma+1}+<+{q{it}}+\leqslant+{\gamma+2})+\+++++%2B+{{\beta+’}3}{x{it}}+\cdot+I({q{it}}+>{\gamma+_2})+%2B+{\varepsilon+_i}+\++\end{gathered}) (6)
其中,门限值 [外链图片转存中…(img-7yQPVtBj-1640317583279)] ,同样地,可以将这个模型转换为离差形式,并仍用两步法进行估计。首先,给定 ( γ 1 , γ 2 ) \left(\gamma_{1}, \gamma_{2}\right) (γ1,γ2) ,使用OLS估计离差模型,得到残差平方和 [外链图片转存中…(img-Vy3hyWNz-1640317583280)]) 。其次,选择 [外链图片转存中…(img-Me3so9Gl-1640317583281)] 使得 [外链图片转存中…(img-WArAQ1l1-1640317583281)] 最小化。
固定效应变换和LSDV
三、面板单门限模型的两大检验
在找出门限值 [外链图片转存中…(img-aDApIieW-1640317583282)] 之后,我们还需要进行两大检验来查看这个门限效应是否真实存在。
1、门限效应的显著性检验
门限效应显著性检验的原假设与备择假设分别为:
[外链图片转存中…(img-lNy4q8QT-1640317583283)]
[外链图片转存中…(img-QT78ldru-1640317583283)]
如果面板单门限模型估计的两个分组系数是相同的,那就没有必要分组进行面板门限模型的估计。
对门限效应显著性的检验,可以构造似然比统计量 [外链图片转存中…(img-p1jUCpNE-1640317583284)]
通过自助法获得 [外链图片转存中…(img-ZRQmYkyh-1640317583285)] 对应的P值,如果P值小于0.1,则拒绝原假设,认为存在门限效应。

计算 γ \gamma γ的值

2、门限估计值的真实性(一致性)检验
对门限估计值的真实性进行检验,即检验 H 0 : γ = γ 0 H_{0}: \gamma=\gamma_{0} H0:γ=γ0
Hansen(1996)使用极大似然法检验门限值,构造似然比检验统计量为 L R ( γ ) L R(\gamma) LR(γ) 。
Hansen(2000)计算了置信区间,即在显著性水平为时 [外链图片转存中…(img-wwhOIWGL-1640317583285)] ,当 [外链图片转存中…(img-mZUTF8xg-1640317583287)]+\leqslant±2ln(1-\sqrt+{1{\text{±+}}\alpha+})) ,不能拒绝原假设,认为门限估计值的真实性是显著的。
这一步,我们可以通过画出 L R ( γ ) L R(\gamma) LR(γ) 与水平线 c ( α ) = − 2 log ( 1 − 1 − α ) c(\alpha)=-2 \log (1-\sqrt{1-\alpha}) c(α)=−2log(1−1−α)的图像,来更加形象化的看到 [外链图片转存中…(img-Xexfgs3V-1640317583287)] 值在什么水平范围之内。
当 [外链图片转存中…(img-1I6jQ18R-1640317583288)] 取值分别为10%、5%与1%时,对应的值分别为:6.53、7.35和10.59。
双门限面板模型
y i t = μ i + β 1 ′ x i t I ( q i t ⩽ γ 1 ) + β 2 ′ x i t I ( γ 1 < q i t ⩽ γ 2 ) + β 3 ′ x i t I ( γ 2 < q i t ) + e i t y_{i t}=\mu_{i}+\beta_{1}^{\prime} x_{i t} I\left(q_{i t} \leqslant \gamma_{1}\right)+\beta_{2}^{\prime} x_{i t} I\left(\gamma_{1}<q_{i t} \leqslant \gamma_{2}\right)+\beta_{3}^{\prime} x_{i t} I\left(\gamma_{2}<q_{i t}\right)+e_{i t} yit=μi+β1′xitI(qit⩽γ1)+β2′xitI(γ1<qit⩽γ2)+β3′xitI(γ2<qit)+eit
Step 1: Estimate single threshold model: γ ^ 1 , S 1 ( γ ^ 1 ) \hat{\gamma}_{1}, S_{1}\left(\hat{\gamma}_{1}\right) γ^1,S1(γ^1)
Step 2 : Given γ ^ 1 \hat{\gamma}_{1} γ^1, Estimate second threshold:
S 2 r ( γ 2 ) = { S ( γ ^ 1 , γ 2 ) , γ ^ 1 < γ 2 S ( γ 2 , γ ^ 1 ) , γ ^ 1 > γ 2 , γ ^ 2 r = arg min γ 2 S 2 r ( γ 2 ) S_{2}^{r}\left(\gamma_{2}\right)=\left\{\begin{array}{ll} S\left(\hat{\gamma}_{1}, \gamma_{2}\right), & \hat{\gamma}_{1}<\gamma_{2} \\ S\left(\gamma_{2}, \hat{\gamma}_{1}\right), & \hat{\gamma}_{1}>\gamma_{2} \end{array}, \hat{\gamma}_{2}^{r}=\underset{\gamma_{2}}{\arg \min } S_{2}^{r}\left(\gamma_{2}\right)\right. S2r(γ2)={S(γ^1,γ2),S(γ2,γ^1),γ^1<γ2γ^1>γ2,γ^2r=γ2argminS2r(γ2)
Step 3 : γ ^ 2 3: \hat{\gamma}_{2} 3:γ^2 is effecient, but γ ^ 1 \hat{\gamma}_{1} γ^1 isn’t.
S 1 r ( γ 1 ) = { S ( γ 1 , γ ^ 2 r ) , γ 1 < γ ^ 2 r S ( γ ^ 2 r , γ 1 ) , γ 1 > γ ^ 2 r , γ ^ 1 r = arg min γ 1 S 1 r ( γ 1 ) S_{1}^{r}\left(\gamma_{1}\right)=\left\{\begin{array}{l} S\left(\gamma_{1}, \hat{\gamma}_{2}^{r}\right), \gamma_{1}<\hat{\gamma}_{2}^{r} \\ S\left(\hat{\gamma}_{2}^{r}, \gamma_{1}\right), \gamma_{1}>\hat{\gamma}_{2}^{r}, \hat{\gamma}_{1}^{r}=\underset{\gamma_{1}}{\arg \min } S_{1}^{r}\left(\gamma_{1}\right) \end{array}\right. S1r(γ1)={S(γ1,γ^2r),γ1<γ^2rS(γ^2r,γ1),γ1>γ^2r,γ^1r=γ1argminS1r(γ1)
决定门限的个数
H0: no threshold; H1: one threshold
F 1 = ( S 0 − S 1 ( γ ^ ) ) / σ ^ 2 F_{1}=\left(S_{0}-S_{1}(\hat{\gamma})\right) / \hat{\sigma}^{2} F1=(S0−S1(γ^))/σ^2
H0: one threshold; H1: two thresholds
F 2 = S 1 ( γ ^ 1 ) − S 2 r ( γ ^ 2 r ) σ ^ 2 F_{2}=\frac{S_{1}\left(\hat{\gamma}_{1}\right)-S_{2}^{\mathrm{r}}\left(\hat{\gamma}_{2}^{\mathrm{r}}\right)}{\hat{\sigma}^{2}} F2=σ^2S1(γ^1)−S2r(γ^2r)
L R 2 r ( γ 2 ) = ( S 2 r ( γ 2 ) − S 2 r ( γ ^ 2 r ) ) / σ ^ 2 L R 1 r ( γ 1 ) = ( S 1 r ( γ 1 ) − S 1 r ( γ ^ 1 r ) ) / σ ^ 2 \begin{aligned} &L R_{2}^{r}\left(\gamma_{2}\right)=\left(S_{2}^{r}\left(\gamma_{2}\right)-S_{2}^{r}\left(\hat{\gamma}_{2}^{r}\right)\right) / \hat{\sigma}^{2} \\ &L R_{1}^{r}\left(\gamma_{1}\right)=\left(S_{1}^{r}\left(\gamma_{1}\right)-S_{1}^{r}\left(\hat{\gamma}_{1}^{r}\right)\right) / \hat{\sigma}^{2} \end{aligned} LR2r(γ2)=(S2r(γ2)−S2r(γ^2r))/σ^2LR1r(γ1)=(S1r(γ1)−S1r(γ^1r))/σ^2
( 1 − α ) % (1-\alpha) \% (1−α)% confidence intervals for γ 2 \gamma_{2} γ2 and γ 1 \gamma_{1} γ1 are the set of values of γ \gamma γ such that L R 2 r ( γ ) ⩽ c ( α ) L R_{2}^{\mathrm{r}}(\gamma) \leqslant c(\alpha) LR2r(γ)⩽c(α) and L R 1 r ( γ ) ⩽ c ( α ) L R_{1}^{\mathrm{r}}(\gamma) \leqslant c(\alpha) LR1r(γ)⩽c(α), respectively.
四、面板门限模型操作xthreg命令介绍
xthreg命令需要在Stata 13.0及以上版本才能安装使用,且xthreg只能估计基于平衡面板数据的固定效应面板门限模型。
首次使用xthreg命令需要使用命令【findit xthreg】进行安装。
sysdir set PLUS ".\ado\plus"
sysdir set PERSONAL ".\ado\personal"
通过【help xthhreg】我们可以查看命令xthreg的详细使用信息。
[外链图片转存中…(img-ReLAYtJ6-1640317583289)]
xthreg命令的格式为:
【xthreg depvar [indepvars] [if] [in], rx(varlist) qx(varname) [thnum(#) grid(#) trim(numlist) bs(numlist) thlevel(#) gen(newvarname) noreg nobslog thgiven options]】
其中,“depvar”为被解释变量、“[indepvars]”为除去体制依赖变量外的解释变量;
选项“rx(varlist)”中放入体制依赖变量,即依赖于门限变量的核心解释变量;
选项“qx(varname)”中放入门限变量;
选项“thnum(#)”中放入门限数,xthreg最多可以估计三个门限值;
选项“grid(#)”中放入格栅点数目,默认为300;
选项“trim(numlist)”为上下删去观测值的比例,选取剩下比例的值作为搜索门限值的范围,
“trim”中填写的内容需要与门限数对应,假设我们删去头尾1%的样本观测值,如果门限数为1,则填写为“trim(0.01)”,如果门限数为2,则填写“trim(0.01 0.01)”,如果门限数为3,则填写“trim(0.01 0.01 0.01)”;
选项“bs(numlist)”是自助抽样的次数,用于门限效应的检验,一般设为300;
选项“thlevel(#)”为设定置信水平,一般为95%;
选项“gen(newvarname)”是为面板门限模型中的门限变量所在的区间生成虚拟变量;
选项“thgive”表示如果加上“thgive”选项则第二个门限值或第三个门限值的估计可以根据之前的结果进行拟合。
此外,运行xthreg命令可以存储的结果如下:
[外链图片转存中…(img-3pB5HxiQ-1640317583289)]
五、面板单门限模型的实现与检验
以Hansen(1999)研究的投资对现金流的敏感性是否受到融资约束的影响为例对面板单门限模型进行拟合与检验。数据集是一个包含美国565家企业、15年数据的微观企业数据集。
参照Hansen(1999)构造的面板数据双门限模型,我们构造面板数据单门限模型如下:
[外链图片转存中…(img-0abkCQYE-1640317583290)]+%2B+{\beta+7}{c{it±+1}}I({d_{it±+1}}+>\lambda+){\text{+%2B+}}{\mu+i}+%2B+{\varepsilon+{it}}+\++\end{gathered})
其中,被解释变量 [外链图片转存中…(img-7ymbOSTP-1640317583290)] 为投资资本比; [外链图片转存中…(img-ZGH9xDFB-1640317583291)] 为总市值价值与资产的比值; d i t d_{it} dit 为长期负债率,是对融资约束的衡量; c i t c_{it} cit是现金流与总资产的比值,是我们应该关注的核心解释变量。模型中的异质性因素为融资约束(长期负债率) [外链图片转存中…(img-UosFpUb0-1640317583292)] ,Hansen使用 [外链图片转存中…(img-ixVws4To-1640317583292)] 的滞后一期作为门限变量。通过命令【use hansen1999.dta】将数据集导入Stata中。
我们使用命令【des】查看数据集的信息。
[外链图片转存中…(img-6q4QdVRG-1640317583293)]
此外,我们还可以使用tabstat命令进行描述性统计,tabstat可以报告变量在不同分位数的取值。
使用命令【tabstat i q1 c1 d1,s(min p25 p50 p75 max) format(%6.3f) c(s)】
[外链图片转存中…(img-Xb7UEWT2-1640317583294)]
接下来,我们对面板数据单门限模型进行估计。
使用命令
【xthreg i q1 q2 q3 d1 qd1,rx(c1) qx(d1) thnum(1) grid(400) trim(0.01) bs(300)】
其中,被解释变量为i,除体制依赖变量外的解释变量q1 q2 q3 d1 qd1,体制依赖变量c1,门限变量d1(这里异质性因素在模型中既作为控制变量又作为门限变量,一般情况下是不这么做的)。命令中,我们设置格点数为400,将升序后的门限变量上下各删去1%,进行自助抽样300次。
[外链图片转存中…(img-bBlPjjbK-1640317583295)]
由估计结果我们可以看到,上图中第一个表格显示了门限值为0.0154。第二个表格是对门限效应的检验,表格上方显示自助抽样数bootstrap为300,检验结果显示通过自助法获得的p值为0,远小于0.1,所以拒绝线性模型的原假设,认为存在门限效应。
[外链图片转存中…(img-RF1chKbS-1640317583295)]
在估计结果中,虚拟变量取值为0时表示融资约束小于门限值0.0154的情形,这时所对应的系数为融资约束较低时现金流对投资的影响;取值为1时表示融资约束大于门限值0.0154的情形,所对应的系数为融资约束较高时现金流对投资的影响。
观察系数估计的结果,可以看到系数的估计结果和我们预期的结果相符合,融资约束较高时现金流对投资的影响更大,这是因为融资约束较高时,企业就很难从外面获得投资所需要的自己,所以企业投资时就更多的依赖于内部的现金流。
接下来 我们使用命令【_matplot】画出似然比函数LR与水平线 [外链图片转存中…(img-4gyLE0kh-1640317583296)]) 的图像,对门限估计值的真实性进行检验。
_matplot e(LR),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Threshold") recast(line) name(LR)
[外链图片转存中…(img-iAGTWH96-1640317583297)]
通过上述图像我们可以直观的看到,似然比统计量LR是门限变量的函数, 的值为 为5%时的取值为7.35,当LR小于7.35时我们便确定了门限值的置信区间,令LR=0,即可确定所对应的门限值为0.0154。
六、面板多门限模型的实现与检验
xthreg命令最多可以估计三个门限模型。我们首先估计三门限模型。
xthreg i q1 q2 q3 d1 qd1,rx(c1) qx(d1) thnum(3) grid(400) trim(0.01 0.01 0.05) bs(0 300 300) thgive
因为我们已经知到存在第一个门限,所以对第一个门限其自助数可以设为0,即选项“bs(#)”设置为bs(0 300 300),这样可以节省模型拟合时间;选项“thgive”表示在第一个门限值给定的情况下,寻找第二、第三个门限值,不加“xtgive”即重头开始估计。
[外链图片转存中…(img-xSQRckbN-1640317583297)]
由运行结果的第一部分我们可以看到三个门限值的取值以及相应的显著性检验。可以看到,第一个门限值为0.0154,第二个门限值为0.5418,第三个门限值为0.4778。观察门限效应的检验结果可以看到,第一个和第二个门限效应检验所对应的p值均小于0.1而第三个门限效应检验的p值为0.57大于0.1,所以,可以认为存在双门限效应而不存在三门限效应。
[外链图片转存中…(img-Qf6QDL0P-1640317583298)]
上述的结果是三门限模型系数估计的结果,按融资约束的三个门限值将样本分为了四个组,从而得到不同的影响程度。
绘制LR统计量的图像对三个门限估计值的真实性进行检验。
_matplot e(LR21),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("First Threshold") recast(line) name(LR21) nodraw
_matplot e(LR22),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Second Threshold") recast(line) name(LR22) nodraw
_matplot e(LR3),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Third Threshold") recast(line) name(LR3) nodraw
graph combine LR21 LR22 LR3,cols(1)
[外链图片转存中…(img-mTqYTAso-1640317583299)]
可以看到,第一个门限与第二个门限的LR图像均与水平线有交点,分别确定了两个门限值的置信区间,所以通过了显著性的检验,而第三个门限的LR图像并没有与水平线出现交点,所以第三门限未能通过显著性的检验。
综上,我们最终应当拟合一个双门限模型。
所以,我们运行命令【xthreg i q1 q2 q3 d1 qd1,rx(c1) qx(d1) thnum(2) grid(400) trim(0.01 0.01) bs(300 300)】对面板数据双门限模型进行估计拟合。
[外链图片转存中…(img-XU6wcR6Y-1640317583299)]
[外链图片转存中…(img-wl5jJW6j-1640317583300)]
实例分析中的代码
use hansen1999.dta
des
help tabstat
tabstat i q1 c1 d1,s(min p25 p50 p75 max) format(%6.3f) c(s)
xthreg i q1 q2 q3 d1 qd1,rx(c1) qx(d1) thnum(1) grid(400) trim(0.01) bs(300)
_matplot e(LR),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Threshold") recast(line) name(LR)
xthreg i q1 q2 q3 d1 qd1,rx(c1) qx(d1) thnum(3) grid(400) trim(0.01 0.01 0.05) bs(0 300 300) thgive
_matplot e(LR21),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("First Threshold") recast(line) name(LR21) nodraw
_matplot e(LR22),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Second Threshold") recast(line) name(LR22) nodraw
_matplot e(LR3),columns(1 2) yline(7.35,lpattern(dash)) connect(direct) msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Third Threshold") recast(line) name(LR3) nodraw
graph combine LR21 LR22 LR3,cols(1)
xthreg i q1 q2 q3 d1 qd1,rx(c1) qx(d1) thnum(2) grid(400) trim(0.01 0.01) bs(300 300)
(九)双重差分模型
一、双重差分模型的介绍
双重差分模型(difference-in-differences)主要被用于社会学中的政策效果评估。使用双重差分方法对各大改革的效果进行评估,从而更好地为政府制定政策提供建议。
双重差分方法的原理是基于一个反事实的框架来评估政策发生和不发生这两种情况下被观测因素 y 的变化。如果一个外生的政策冲击将样本分为两组—受政策干预的 t r e a t treat treat 组和未受政策干预的 [外链图片转存中…(img-StMo9uKG-1640317583301)] 组,且在政策冲击前, [外链图片转存中…(img-GuodsarN-1640317583302)] 组和 [外链图片转存中…(img-VjFfEqRb-1640317583303)] 组的 [外链图片转存中…(img-4OmwyhPy-1640317583303)] 没有显著差异,那么我们就可以将 [外链图片转存中…(img-fTJRZ41u-1640317583304)] 组在政策发生前后 [外链图片转存中…(img-EtaO6Krx-1640317583304)] 的变化看作 [外链图片转存中…(img-D0lwAr7A-1640317583305)] 组未受政策冲击时的状况(反事实的结果)。通过比较 [外链图片转存中…(img-aqX9YKHj-1640317583308)] 组 [外链图片转存中…(img-O4O0VdQs-1640317583309)] 的变化( [外链图片转存中…(img-jeu0uCpk-1640317583309)] )以及 [外链图片转存中…(img-hJ4CzNN9-1640317583310)] 组 [外链图片转存中…(img-sLh0fSxV-1640317583311)] 的变化( Δ Y c \Delta Y_c ΔYc),我们就可以得到政策冲击的实际效果 Δ Δ Y = Δ Y t − Δ Y c \Delta \Delta Y=\Delta Y_{t}-\Delta Y_{c} ΔΔY=ΔYt−ΔYc
具体而言就是,利用政策的准自然实验将研究对象随机的分成处理组和对照组,其中受到政策影响的个体称为处理组,反之是对照组。为了估计政策效应,先比较处理组在政策发生前后的变化,需要注意的是,这种变化的部分可能是时间效应所导致的,即没有政策的发生处理组也会随着时间变动而发生变化。为了剔除这种随着时间变动的影响我们引入了对照组,由于对照组不会受到政策的影响,因而对照组在政策实施前后发生的变化就是由于时间效应带来的变化。我们使用对照组在政策发生前后的结果变量的变化剔除时间效应。
直观上讲,我们只不过是通过对照组构造了一个没有受到政策影响的处理组。
通常情况下,我们可以通过三种方式来理解双重差分方法,即表格法、画图法和回归法。
1、表格法
通过表格法我们可以直观的理解双重差分方法。
首先,我们分别计算处理组和对照组在政策发生前后结果变量的均值;然后,用处理组政策发生后的均值减去政策发生前的均值得到处理组政策前后的变化,将对照组也进行同样的操作,从而得到对照组在政策发生前后的变化(对照组的变化即为由于时间效应的存在对结果变量造成的影响);最后,用处理组的变化减去对照组的变化,剔除掉时间效应,就可以得到政策效应,这两次相减的过程就体现了双重差分的思想。
[外链图片转存中…(img-qxM1H0VC-1640317583311)]
表格中Group 1为处理组, Group 2为对照组。 E ( Y t 1 ) E\left(Y_{t 1}\right) E(Yt1) 表示处理组政策发生前的结果变量均 值; E ( Y t 2 ) E\left(Y_{t 2}\right) E(Yt2) 表示处理组政策发生后的结果变量均值; E ( Y c 1 ) E\left(Y_{c 1}\right) E(Yc1) 表示对照组政策发生前的结果 变量均值; E ( Y c 2 ) E\left(Y_{c 2}\right) E(Yc2) 表示对照组政策发生后的结果变量均值; Δ Y t \Delta Y_{t} ΔYt 表示处理组政策发生前后结 果变量均值的差分; Δ Y c \Delta Y_{c} ΔYc 表示对照组政策发生前后结果变量均值的差分; Δ Δ Y \Delta \Delta Y ΔΔY 是处理组政 策发生前后结果变量均值的差减去对照组政策发生前后结果变量均值的差,即我们所关注的政策效 应。
2、画图法
我们可以将对照组与处理组结果变量的均值随时间的变化绘制成时序图,这样可以直观的理解双重差分方法。
[外链图片转存中…(img-dYRqzHEH-1640317583312)]
在上图中我们可以看到,上面的曲线是对照组结果变量随时间变动的轨迹; 下面的曲线是处理组随 时间变动的曲线。政策发生前为 T = 1 T=1 T=1 ,政策发生后为 T = 2 T=2 T=2 ,我们需要估计的是政策发生前后结果变 量发生了多大的变化。与表格法一样, E ( Y t 1 ) E\left(Y_{t 1}\right) E(Yt1) 表示处理组政策发生前的结果变量均值; E ( Y t 2 ) E\left(Y_{t 2}\right) E(Yt2) 表示处理组政策发生后的结果变量均值; E ( Y c 1 ) E\left(Y_{c 1}\right) E(Yc1) 表示对照组政策发生前的结果变量均 值; E ( Y c 2 ) E\left(Y_{c 2}\right) E(Yc2) 表示对照组政策发生后的结果变量均值; Δ Y t \Delta Y_{t} ΔYt 表示处理组政策发生前后结果变量 均值的差分; Δ Y c \Delta Y_{c} ΔYc 表示对照组政策发生前后结果变量均值的差分; Δ Δ Y \Delta \Delta Y ΔΔY 为剔除了时间效应 之后的政策效应。
通过上图的这一曲线图可以发现,结果变量的数值高低是不重要的,重要的是它的变化方向以及变化的大小。
**###**由画图法可以看到,我们需要特别注意的一点是==共同趋势假定:==政策发生前,对照组与处理组的结果变量呈现出共同的变化趋势。只有满足这一假定,才能使用对照组来模拟处理组在未受到政策冲击时的时间效应。
除了共同趋势检验,在DID方法中还有一个经常被提起的检验,即==安慰剂检验。==
共同趋势检验是安慰剂检验,而反过来则不成立,因为安慰剂检验可以包括除了共同趋势检验以外的检验。
在现有的政策评估的文献中,有很多种进行安慰剂检验的方法。
- 第一种,可以采用政策发生之前的数据,将政策实施前的除第一年之外的所有年份"人为地"设定成为处理组的政策实施年份。然后,根据DID模型逐年回归,当所有回归中的交互项系数都不显著时,说明通过了安慰剂检验,表明之前识别的政策平均效应是可靠的,否则就是不可靠的。如果政策实施前有n年数据,那么就要做n-1次上述回归。
- 第二种,**"人为地"随机选择政策实施对象(处理组),然后使用全样本做DID回归,**如果交互项系数不显著,则判断政策对随机选择的处理组都不存在政策效应,可以进一步证明之前识别的政策平均效应结果是可靠稳健的。
- 第三种,改变被解释变量,通常选择理论上不受政策影响的其他变量,保持真实的对照组和处理组、真实的政策实施时间,重新进行DID回归,理想的结果是,该政策的实施对其他被解释变量都不存在政策效应。
3、回归法
我们考虑两组两期的回归模型,两组指处理组和对照组,两期是指政策发生前和政策发生后。
回归法设定的模型如下:
[外链图片转存中…(img-zk01kxCm-1640317583313)]
其中, Y i t Y_{i t} Yit 是被解释变量; treat i _{i} i 是组别虚拟变量: 如果个体属于处理组,则 treat i = 1 _{i}=1 i=1 ,如果属于对照组,则 treat i = 0 ; P t _{i}=0 ; \quad P_{t} i=0;Pt 是时间虚拟变量: 政策实施之后 P t = 1 P_{t}=1 Pt=1 ,否则 P t = 0 ; β 3 P_{t}=0 ; \beta_{3} Pt=0;β3 的大小和方向反映了双重差分政策效应。
因为回归法具备很多其他方法不具备的优点,所以我们通常采用回归法估计政策效应。
回归法的优点:
- 能够计算政策效应的标准误和显著性;
- 回归过程中可以控制其他影响被解释变量的变量;
- 回归法允许包含多期的数据使结果更加准确;
- 在评估政策时还可以将政策强度考虑在内(比如:研究关税政策变动的影响)。
在现实中,很多政策的实施都是渐进式的,通常会有试点区然后再逐步推广至其他地区,针对这种现实情况,我们就需要构造==两组多期的DID模型和多组多期的DID模型==。
(1)两组多期DID模型的设定
Y i t = β 0 + β 1 treat i + β 3 treat i ∗ P t + λ t + ε i t Y_{i t}=\beta_{0}+\beta_{1} \text { treat }_{i}+\beta_{3} \text { treat }_{i} * P_{t}+\lambda_{t}+\varepsilon_{i t} Yit=β0+β1 treat i+β3 treat i∗Pt+λt+εit
其中, λ t \lambda_{t} λt 为时间效应,其他变量与上面两组两期的模型的变量解释相同。
(2)多组多期DID模型的设定
Y i s t = β 1 D s t + β 2 X i s t + u s + λ t + ε i t Y_{i s t}=\beta_{1} D_{s t}+\beta_{2} X_{i s t}+u_{s}+\lambda_{t}+\varepsilon_{i t} Yist=β1Dst+β2Xist+us+λt+εit
其中的下标 i i i 表示个体, t t t 表示时间, s s s 表示组别; u s u_{s} us 为多组的估计效应, λ t \lambda_{t} λt 为多重的时 间效应; D s t D_{s t} Dst 为虚拟变量,表示组别在 t t t 时是否受到了政策的影响,如果受到政策的影响则为 1 ,否则为 0 。
此外,在现有的政策性评估的文章中,除了以上的DID模型外,还有控制个体效应的DID模型。模型设定如下所示:
Y i t = β 1 treat i ∗ P t + + u i + λ t + ε i t Y_{i t}=\beta_{1} \text { treat }_{i} * P_{t}++u_{i}+\lambda_{t}+\varepsilon_{i t} Yit=β1 treat i∗Pt++ui+λt+εit
其中, u i u_{i} ui 是个体效应,其他变量解释与上述相同。
如果政策发生前后,处理组和对照组中的个体个数没有发生变化,那么在方程中加入个体效应,可以估计出处理组和对照组中的所有的个体效应。在两次相减的过程中,个体效应就会抵消, [外链图片转存中…(img-5t74xvMb-1640317583313)] 仍然能够反映政策效应。此时,这种控制个体效应的DID模型就是可行的,否则,就不能真正的识别政策效应。
二、做DID需要注意的若干问题
在构建双重差分模型时,我们需要注意一些问题。
第一,DID方法不仅仅能够估计出政策效应,还能识别出组别固定效应和时间效应。
第二,双重差分模型反映的是政策冲击的"即时效应",也就是政策发生时所能带来的平均效应是多少,但是有时候政策冲击具有滞后效应,今年实施的政策可能明年或者更之后的年份才能展现出效果。
对于滞后效应的衡量:
通常情况下可以用 [外链图片转存中…(img-GXiLc3nK-1640317583314)] 的滞后一期来估计政策冲击的平均效应。在科研实践中,如果某一个政策不存在即时效应一定要尝试考察是否存在滞后效应。
第三,使用DID方法必须保证处理组和对照组在政策实施前的时间趋势是一致的,这个假设只能通过足够长的时间序列数据才能检验,必须要保证==对照组和处理组在政策发生之前至少有两期的数据。==如果不满足共同趋势的假定,那么估计得到的交互项的系数就可能存在偏误。
如果对照组和处理组确实不满足共同趋势的假定,我们可以通过如下三种思路进行解决:
第一个,是寻找更好的对照组(这里我们需要用到==合成控制法==),把多个对照组加权构成一个虚拟的对照组,使得虽然每个对照组都与处理组的时间趋势不一样,但加权后的虚拟对照组的时间趋势与处理组的一样。这样虚拟对照组与处理组就满足了共同趋势的假定。这种方法常用于案例分析中。
第二个,是估算出因时间趋势不同而带来的偏差,然后从双重差分结果中减去这个偏差,这种方法也被称作三重差分方法(Difference-in-differences-in-differences,DDD)。
三重差分法的思路是,既然两个地区的时间趋势不一样,那么可以分别在两个地区寻找一个没有受到干预影响的人群或行业,通过对这两组的双重差分估算出时间趋势的差异,然后再从原来实验组和对照组的双重差分估算值中减去这个时间趋势差异。
对于三重差分模型的设定,可以参考陈强教授的《高级计量经济学及stata应用》第343页的例子:
假设美国B州针对65岁及以上老年人(用E表示)引入了一项新的医疗保健政策,而该政策不适用于65岁以下的人群(用N表示),欲考察此政策对于健康状况 [外链图片转存中…(img-PB3yxVlX-1640317583315)] 的影响。
如果运用双重差分模型,我们有两种方法可以参考:
- 以B州65及以上人群作为实验组,65岁以下人群作为对照组。这种方法的缺陷是,年轻人和老年人的健康状况随着时间可能发生不同的变化;
- 以相邻A州65岁及以上的老年人作为对照组,这种方法虽然避免了上述方法中的问题,但是不能保证正常实施之前,两个州的老年人健康状况有着同样的时间趋势。
所以,最好的办法是将上述两种方法综合起来。
首先,基于第一种方法,将B州65岁及以上人群作为实验组,65岁以下人群作为对照组;
然后,使用A州的数据衡量年轻人和老年人的健康状况随时间变化的不同;
最后,再从双重差分的结果中把这一不同减去,就能够估计出政策效应。这就是三重差分法。
我们引入三重差分模型:
y = β 0 + β 1 B + β 2 E + β 3 B × E + γ 0 D + γ 1 D × B + γ 2 D × E + δ D × B × E + ε i t \begin{gathered} y=\beta_{0}+\beta_{1} B+\beta_{2} E+\beta_{3} B \times E+\gamma_{0} D \\ +\gamma_{1} D \times B+\gamma_{2} D \times \mathrm{E}+\delta D \times B \times \mathrm{E}+\varepsilon_{i t} \end{gathered} y=β0+β1B+β2E+β3B×E+γ0D+γ1D×B+γ2D×E+δD×B×E+εit
其中, B B B 表示是否为 B B B 州 ( B (B (B 州为 1 , A 1 , A 1,A 州为 0 ) , E ) , E ),E 表示是否为老年人 (是为 1 ,否为 0 ) , D ) , D ),D 为时间虚拟变量 (政策实施后为 1 ,实施前为 0 )。交互项 D × B × E D \times B \times E D×B×E 前面的系数 δ \delta δ 就是政策 效果。
第三个,是增加不同组别不同的时间趋势,即控制同一年份不同组别不同的时间趋势。需要注意 的是,如果在基准回归中加入了这一趋势变量,那么在安慰剂检验时也需要加入,二者必须保持一 致,通过这种控制,之前提到的三种安慰剂检验方法,跑出来的交互项系数可能就不显著,从而可 能通过安慰剂检验。
Y i s t = β 0 + β 1 D s t + β 2 X i s t + u s + λ s t + ε i t Y_{i s t}=\beta_{0}+\beta_{1} \mathrm{D}_{s t}+\beta_{2} X_{i s t}+u_{s}+\lambda_{s t}+\varepsilon_{i t} Yist=β0+β1Dst+β2Xist+us+λst+εit
三、双重差分模型的Stata操作
我们通过Card和Krueger发表在1994年AER上的一篇文章关于最低工资调整的案例来理解双重差分模型的stata基本步骤和程序。
他们研究了最低工资调整对就业的影响,文章以快餐业为考察对象,处理组和对照组分别为新泽西州和宾夕法尼亚州。选择快餐业的原因是因为快餐业属于低技能行业,此类行业的从业人员对于最低工资的反映最为强烈。
文章选择的政策事件背景是,从1992年4月1日起,新泽西州最低工资由每小时4.25美元上升到每小时5.05美元,而宾夕法尼亚州最低工资保持不变。新泽西州的快餐业为处理组,宾夕法尼亚州的快餐业为对照组。
[外链图片转存中…(img-igjRKTaF-1640317583315)]
根据上述数据集,我们设定双重差分模型。
[外链图片转存中…(img-aObu7VM2-1640317583316)]
设定分组虚拟变量和时间虚拟变量:如果是新泽西州则设定 [外链图片转存中…(img-ZwLJsQEC-1640317583317)] ,否则 [外链图片转存中…(img-2YqbbK6H-1640317583318)] ;对于时间虚拟变量,如果是1992年4月1日之后,则 [外链图片转存中…(img-sMNT1Ij2-1640317583319)] ,否则 [外链图片转存中…(img-2UGStGDy-1640317583320)] 。
Stata中可以通过【diff】命令对双重差分模型进行估计。需要注意的是:diff命令只能用于两组两期的方法。
#首次使用diff命令,需要通过命令【ssc install diff】进行安装。
diff命令的基本格式是:
【diff outcome_var [if] [in] [weight] ,[ options]】
其中,outcome_var是被解释变量;必选项treat(varname)用来指定处理变量;必选项period(varname)用来指定时间虚拟变量;选项cov(varlist)用来指定其他的控制变量;选项cluster(varname)和robust用来设定标准差,cluster是聚类标准误,robust是稳健标准误;选项test是进行平衡性检验,比较处理组和对照组在政策发生之前在控制变量方面是否存在显著性的差异,一般来说,如果没有显著性的差异,就说明处理组和对照组是高度相似的,是符合使用DID方法的。
在Stata中调用数据集
use http://fmwww.bc.edu/repec/bocode/c/CardKrueger1994.dta
使用des命令查看数据集,结果如下:
[外链图片转存中…(img-2hibCYGx-1640317583322)]
通过sum命令查看各变量的描述统计的情况。
[外链图片转存中…(img-mDKO500e-1640317583323)]
使用命令【diff fte,t(treated) p(t)】进行双重差分模型估计(命令中没有加入控制变量)。
diff fte,t(treated) p(t)
[外链图片转存中…(img-ioIXrzJP-1640317583324)]
从上表中的估计结果可以看到,政策实施前处理组和对照组的差值Diff(T-C)是-2.884,政策实施后的差值是0.030,二者的差值也就是双重差分的系数为2.914,其对应的p值为0.071,表示在10%的显著性水平下通过了检验。
#需要注意的是在政策实施前,处理组是326家企业,政策实施后是320家企业,这是一个非平衡面板数据。
此外,我们也可以构建treated*t的交互项进行OLS回归,两者的结果是一致的。
在上述模型的基础上,我们加入控制变量对双重差分模型进行估计(report为报告控制变量的系数结果)。
diff fte,t(treated) p(t) cov(bk kfc roys) report
[外链图片转存中…(img-euBYYGme-1640317583325)]
最后,我们进行平衡性检验来查看各变量在处理组和控制组之间是否存在差异。
diff fte,t(treated) p(t) cov(bk kfc roys wendys) test
[外链图片转存中…(img-4ey3A6O9-1640317583326)]
从结果中可以看到,被解释变量在处理组和对照组之间存在显著性的差异,而其余的控制变量的平均效应不存在显著性的差异,这就说明对照组和控制组选择是恰当的。
开始基准回归,然后稳健型检验,平行趋势检验,安慰剂检验,其他稳健型检验
(十)合成控制法
一、合成控制法的基本思想
合成控制法是上一篇笔记中双重差分方法的衍生。双重差分方法考察的是政策的平均效应和异质性效应。如果我们要考察某一政策冲击对某一个体的单独影响,双重差分方法是无法达到这一效果的,此时,合成控制法才是最合适的方法。
经济学研究中经常要评估某一项政策或事件的效应,使政策可能实施于某个国家和地区、省、州或城市。最简单的方法是考察政策实施前后的时间序列,看我们所关心的结果如何变化,不过,这一结果还可能受其原有变化趋势的影响或其他同时发生的混淆性事件的作用。
为此,常常使用“鲁宾的反事实框架”,即假设该地区如果没有受到政策干预将会怎么样,并与事实上受到政策干预的实际数据进行对比,二者之差即为处理效应。这种方法的困难之处在于,我们无法观测到“该地区如果没有受到政策干预将会是怎么样的”(反事实)。
鉴于反事实无法观测,通常的解决办法是寻找适当的控制组,即在各方面都与受干预地区相似却未受干预的其他地区,以作为处理组的反事实替身。但通常我们是不易找到最理想的控制地区,使其能够在在各方面都接近于处理地区。比如,我们要考察仅在北京实施的某项政策的效果,自然会想到以上海作为控制地区,但上海毕竟与北京不完全相同,或可用其他一线城市(上海、广州、深圳)构成北京的控制组,比较上海、广州、深圳与北京在政策实施前后的差别,这一方法也称为比较案例研究。
但是,如何选择控制组通常存在主观随意性,且上海、广州、深圳与北京的相似度也不尽相同。为了解决控制组选择的难题,Abadie和Gardeazabal(2003)提出“合成控制法”(Synthetic Control Method)。
Abadie Alberto and Javier Gardeazabal,“The Economic Costs of Conflict:A Case Study of the Basque Country”, American Economic Review,2003,93(1),113-132.
"合成控制法"的基本思想是:假设我们要考察仅在北京实施的某项政策效果,虽然我们无法找到北京的最佳控制地区,但通常可对中国的若干大城市进行适当的线性组合,以构造一个更为优秀的“合成控制地区”(synthetic control region),并将“真实北京”与“合成北京”进行对比,所以这一方法称为“合成控制法”。
合成控制法的一大优势是,可以根据数据来选择线性组合的最有权重,避免研究中主观选择控制组的随意性。
总结以上,合成控制法的基本思想是以真实地区为基础,在相似地区中以一定的线性组合构造出合成地区进行组合。
合成控制法的优点
- 作为一种非参数的方法,是对传统的双重差分法DID的拓展
- 通过数据驱动确定权重,减少了主观选择的误差,避免了政策内生性问题
- 通过对多个控制对象加权来模拟目标对象政策实施前的情况,不仅可以清晰地反映每个控制对象对“反事实”事件的贡献,同时也避免了过分外推
- 可以对每一个研究个体提供与之对应的合成控制对象,避免平均化的评价,不至于因各国政策实施时间不同而影响政策评估结果,避免了主观选择造成的偏差
- 研究者们可在不知道实施效果的情况下设计实验
合成控制法的具体方法
以Abadie和Gardeazabal两位作者在2003年发表的西班牙巴斯克地区(Basque country)恐怖活动的经济成本的研究文章为例。
文章中,被解释变量为人均GDP,记为 ;影响 的解释变量或预测变量(predictors)包括投资率、人口密度、产业结构、人力资本等。
巴斯克地区拥有独特的语言和文化,在历史上多次成功的避开强敌入侵。在20世纪70年代初,巴斯克地区的人均GDP在西班牙17个地区中排名第三。之后,由于民族独立的诉求未获满足,从1975年开始巴斯克地区陷入有组织的恐怖活动之中,恐怖活动重创巴斯克地区,自20世纪90年代末,巴斯克地区的人均GDP在西班牙排名降为第六。然而,70年代末至80年代初西班牙整体经济也在下行,因此不易区分恐怖活动的单独效应,而且巴斯克地区在恐怖活动之前的经济增长潜力显然与西班牙其他地区也不尽相同。
为此,Abadie和Gardeazabal(2003)使用西班牙其他地区的线性组合来构造合成的控制地区,并使得合成控制地区的经济特征与60年代末恐怖活动爆发前的巴斯克地区尽可能相似,然后把此后“合成巴斯克地区”(synthetic Basque country)的人均GDP演化与“真实巴斯克地区”(actual Basque country)进行对比。
假设共有(1+J)个地区,其中第1个地区为受到恐怖活动冲击的巴斯克地区,而其余J个西班牙地区则是未受到冲击的地区(在文章中J=16)。没有受到影响的这些地区构成了潜在的控制组,称为"donor pool"(愿意为“器官捐献库”,借用医学术语)。
合成控制法的一个潜在假定是,恐怖活动仅影响巴斯克地区,而未波及西班牙的其他地区(事实上恐怖活动也主要集中于巴斯克地区)。
将合成地区的权重记为以下J维列向量:
W ≡ ( w 2 ⋯ w J + 1 ) ′ \mathbf{W} \equiv\left(\begin{array}{lll} w_{2} & \cdots & w_{J+1} \end{array}\right)^{\prime} W≡(w2⋯wJ+1)′
其中, W 2 \mathrm{W}_{2} W2 表示第2个地区在合成巴斯克地区所占的权重, 以此类推;所有权重皆非负,且权重之和为 1 。 w w w 的不同取值即构成不同的合成控制 地区, 简称 “合成控制” ( synthetic control)。
在巴斯克地区爆发恐怖活动之前,记其各预测变量的平均值为向量 x 1 x_{1} x1 ( K × 1 (K \times 1 (K×1 维列向量, 下标1表示“treated region” ), 即表中第(1)列的数值(除了人均GDP)。
将西班牙其他地区相应预测变量 的平均值记头矩阵 X 0 ( K × J X_{0}\left(K \times J_{\text {}}\right. X0(K×J 维矩阵,下标 0 表示 “control region” ), 其 中第 j \mathrm{j} j 列为第 j \mathrm{j} j 个地区的相应取值。
合成控制法的关键是
需选择权重 w \mathrm{w} w, 使得 X 0 w \mathrm{X}_{0} \mathrm{w} X0w 尽可能地接近于 X 1 \mathrm{X}_{1} X1, 即经过加权之后, 合成 控制地区的经济特征应尽量接近处理地区。为度量此距离, 可使用二次型 ( 类似于欧几里得空间中两点之间的距离) 。由于 x 1 x_{1} x1 中的每个预测变量对 于 y y y 的预测能力有大小之别, 应在距离函数中享有不同的权重, 故考虑以下 有约束最小化问题
min w ( x 1 − X 0 w ) ′ V ( x 1 − X 0 w ) s.t. w j ≥ 0 , j = 2 , ⋯ , J + 1 ; ∑ j = 2 J + 1 w j = 1 \begin{gathered} \min _{\mathbf{w}}\left(\mathbf{x}_{1}-\mathbf{X}_{0} \mathbf{w}\right)^{\prime} \mathbf{V}\left(\mathbf{x}_{1}-\mathbf{X}_{0} \mathbf{w}\right) \\ \text { s.t. } w_{j} \geq 0, j=2, \cdots, J+1 ; \sum_{j=2}^{J+1} w_{j}=1 \end{gathered} wmin(x1−X0w)′V(x1−X0w) s.t. wj≥0,j=2,⋯,J+1;j=2∑J+1wj=1
图 其中, V V V 为 ( K × K ) (K \times K) (K×K) 维对角矩阵, 其对角线元素均为非负权重, 反映 相应的预测变量对于人均GDP的相对重要性 , 此最小化问题的目标函数 是二次函数, 为 “二次规划” ( quadratic programming ) 问题, 一般 进行数值求解。记此约束最小化问题的最优解为 w ∗ ( V ) w^{*}(V) w∗(V); 显然, 它依赖于 对角矩阵 V V V 。
这样,因为 是关于 的函数,所以我们进一步需要选择最优的 使得在恐怖活动全面爆发之前合成巴斯克地区的人均GDP与真实巴斯克地区尽量接近。
记Z 为 ( 10 × 1 ) (10 \times 1) (10×1) 维列向量, 包含巴斯克地区在 1960 − 1969 1960-1969 1960−1969 年间的人均 GDP; 记Z为 ( 10 × J ) (10 \times \mathrm{J}) (10×J) 维矩阵, 其中每列为相应控制地区在 1960-1969年 间的人均GDP。
用Z W ∗ ( V ) \mathrm{W}^{*}(\mathrm{~V}) W∗( V) 来预测 Z 1 \mathrm{Z}_{1} Z1, 然后选择 V \mathrm{V} V, 以最小化 “均方预测误差”( Mean Squared Prediction Error, 简记MSPE ), 即将每期的预测误 差平方后再求各期的平均:
min v 1 10 ( z 1 − Z 0 w ∗ ( V ) ) ′ ( z 1 − Z 0 w ∗ ( V ) ) \min _{\mathbf{v}} \frac{1}{10}\left(\mathbf{z}_{1}-\mathbf{Z}_{0} \mathbf{w}^{*}(\mathbf{V})\right)^{\prime}\left(\mathbf{z}_{1}-\mathbf{Z}_{0} \mathbf{w}^{*}(\mathbf{V})\right) vmin101(z1−Z0w∗(V))′(z1−Z0w∗(V))
确定了 V之后,我们便可以确定向量 W。
经过计算,Abadie和Gardeazabal(2003)发现,只有两个地区的权重为正,即加泰罗尼亚(Catalonia,权重0.8508)与马德里(Madrid,权重0.1492),而其他地区的权重均为0。直观上来看,Catalonia与Madrid的经济特征也与巴斯克地区最为相似。
在得到合成巴斯克地区的权重之后,我们就可以计算合成地区的人均GDP在样本期间的演化过程。
记巴斯克地区在样本期间 (假设为T期)的人均GDP为向量 y 1 ( T × 1 \mathrm{y}_{1}(\mathrm{~T} \times 1 y1( T×1 维列向量 ) ) ) 。
记其他地区在样本期间的人均GDP为矩阵 Y 0 Y_{0} Y0 ( T × J (T \times J (T×J 维矩阵 ), 其中每列为相应地区的人均GDP。
由此可得合成巴斯克地区的人均GDP序列 y 1 ∗ = Y O ∗ y_{1}{ }^{*}=Y \mathrm{O}^{*} y1∗=YO∗ 。最直观的方法是将 y 1 \mathrm{y}_{1} y1 与合成控制的 y 1 ∗ \mathrm{y}_{1}{ }^{*} y1∗ 画时间趋势图, 参见右图。

合成控制法的synth命令
Abadie等人在2010年发表的一篇与合成控制法相关的文章中提供了合成控制法的Stata程序"synth"。
Abadie Alberto,Alexis Diamond,and Jens Hainmueller, “Syntheic Control Methods for Comparative Case Studies:Estimating the Effect of California’s Tobacco Control Program,” Journal of the American Statistical Association,2010,105(490), 493-505
在Stata中安装"synth"程序。
ssc install synth
通过"help"查看"synth"命令的帮助。
help synth
"synth"命令的基本格式如下:
synth depvar predictorvars , trunit(#) trperiod(#) [ counit(numlist) xperiod(numlist) mspeperiod() figure resultsperiod() nested allopt keep(file) ]
其中,"depvar"为结果变量;"predictorvars"是预测变量,即控制变量。
必选项: "trunit(#)"用于指定处理地区(trunit表示treated unit);
"trperiod(#) "用于指定政策干预开始的时期。
选择项: "counit(numlist)"用于指定潜在的控制地区(即donor pool),默认为数据集中除处理地区以外的所有地区;
"xperiod(numlist)"用于指定将预测变量(predictors)进行平均的时期区间,默认为政策干预开始之前的所有时期(the entire pre-intervention period);
"mspeperiod()"用于指定最小化均方预测误差(MSPE)的时期,默认为政策干预之前的所有时期;"figure"表示将处理地区与合成控制的结果变量绘制时间趋势图;
"resultsperiod() "用于指定时间趋势图的时间范围(默认为整个样本期间);
“nested"表示使用嵌套的数值方法寻找最优的合成控制(推荐使用此项),这比默认方法更费时间,但可能更精确,在使用"nested"时,如果再加上选择项"allopt”(即"nested allopt"),则比单独使用"nested"还费时间,但精度可能更高;
"keep(file)"将估计结果(比如,合成控制的权重、结果变量)存为另一Stata数据集(filename.dta),以便进行后续计算。
合成控制法Stata操作
以Abadie等人(2010)《加州控烟政策有效性评估研究》为例。
Abadie等人(2010)将合成控制法应用于研究美国加州1988年第99号控烟法的效果。1988年11月美国加州通过了当代美国最大规模的控烟法,并于1989年1月开始生效。该法将加州的香烟消费税提高了每包25美分,将所得收入专项用于控烟的教育与媒体宣传,并引发了一系列关于室内清洁空气的地方立法,比如在餐馆、封闭工作场所等禁烟。
Abadie等人使用的数据为美国1970-2000年38个州际面板数据。由于马萨诸塞、亚利桑那、俄勒冈和弗罗里达四个州在1989至2000年期间也引入了正式的控烟立法无法作为控制地区,因此,将这四个州从潜在控制区donor pool中去掉。另外,还去掉了阿拉斯加、夏威夷、马里兰、华盛顿等州,这些州在1989至2000年期间将香烟消费税提高了每包50美分及以上,最后剩下38个州作为潜在的控制地区。
研究的结果变量为cigsale(人均香烟消费量,包/年);预测变量包括retprice(平均香烟零售价格)、lnincome(人均收入对数)、age15to24(15-24岁人口所占比重)、beer(人均啤酒消费量),这些预测变量均为1980-1988年的州平均值,另外,还使用1975、1980与1988年的人均香烟消费量作为三个额外的预测变量。
面板变量为state(州),时间变量为year(年)。
在Stata中打开数据集"smoking.dta",并将数据集设定为面板数据。
use "D:\smoking.dta"
xtset state year
[外链图片转存中…(img-m7acUZcV-1640317583327)][外链图片转存中…(img-pNsvnPwP-1640317583328)]
由设定结果可知,数据集为平衡面板数据集。
使用"synth"命令生成合成加州。
synth cigsale retprice lnincome age15to24 beer cigsale(1975) cigsale(1980) cigsale(1988),trunit(3) trperiod(1989) xperiod(1980(1)1988) figure nested keep(smoking_synth)
其中,"cigsale(1975) cigsale(1980) cigsale(1988)"分别表示人均香烟消费在1975、1980与1988年的取值;"trunit(3)"表示第3个州(即加州)为处理地区;"trperiod(1989)"表示控烟法在1989年开始实施;"xperiod(1980(1)1988)“表示将预测变量在1980-1988年期间进行平均,其中"1980(1)1988"表示时间始于1980年,以1年为间隔,而止于1988年,等价于"1980 1981 1982 1983 1984 1985 1986 1987 1988”;"keep(smoking_synth)"将估计结果存为Stata数据集smoking_synth.dta(存放路径为Stata当前的工作路径)。
| [外链图片转存中…(img-9g8ehLyQ-1640317583329)] | [外链图片转存中…(img-Ik1agZpG-1640317583330)] |
|---|---|
各个州所占的权重
由上图Stata输出的各个州的权重结果可以知道,大多数州的权重为0,而只有以下五个州的权重为正,即Colorado(0.161)、Connecticut(0.068)、Montana(0,201)与Utah(0.335)。
[外链图片转存中…(img-7OL6hYXp-1640317583331)]
真实加州与合成加州在各项指标上的比较
观察上图中的真实加州与合成加州各项指标的结果,我们可以看到,真实加州与合成加州的预测变量、控制变量均十分的接近,所以合成加州可以很好地复制加州的经济特征。

真实加州与合成加州的结果变量(人均香烟消费量)的时间趋势图
由上图的趋势图可知,在1989年控烟法之前,合成加州的人均香烟消费与真实加州几乎如影相随,表明合成加州可以很好地作为加州如未控烟的反事实替身。在控烟法实施之后,加州与合成加州的人均香烟消费量即开始分岔,而且此效应越来越大。
更直观的,我们可以再打开一个Stata程序,然后调用我们先前保存的数据集"smoking_synth。dta",计算真实加州与合成加州人均香烟消费之差(即处理效应),然后绘制差值的图像。
use "C:\data\smoking_synth.dta"
紧接着,我们在Stata中定义处理效应,具体操作如下:
gen effect = _Y_treated - _Y_synthetic
其中,处理效应为"effect","_Y_treated"与"_Y_synthetic"分别表示处理地区与合成控制的结果变量。
生成处理效应的变量之后,我们绘制其图像。
label variable _time "year"
label variable effect "gap in per-capita cigarette sales(in packs)"
line effect _time,xline(1989,lp(dash)) yline(0,lp(dash))
其中,xline(1989,lp(dash))与yline(0,lp(dash))表示在横轴1989年初和纵轴0处绘制虚线。
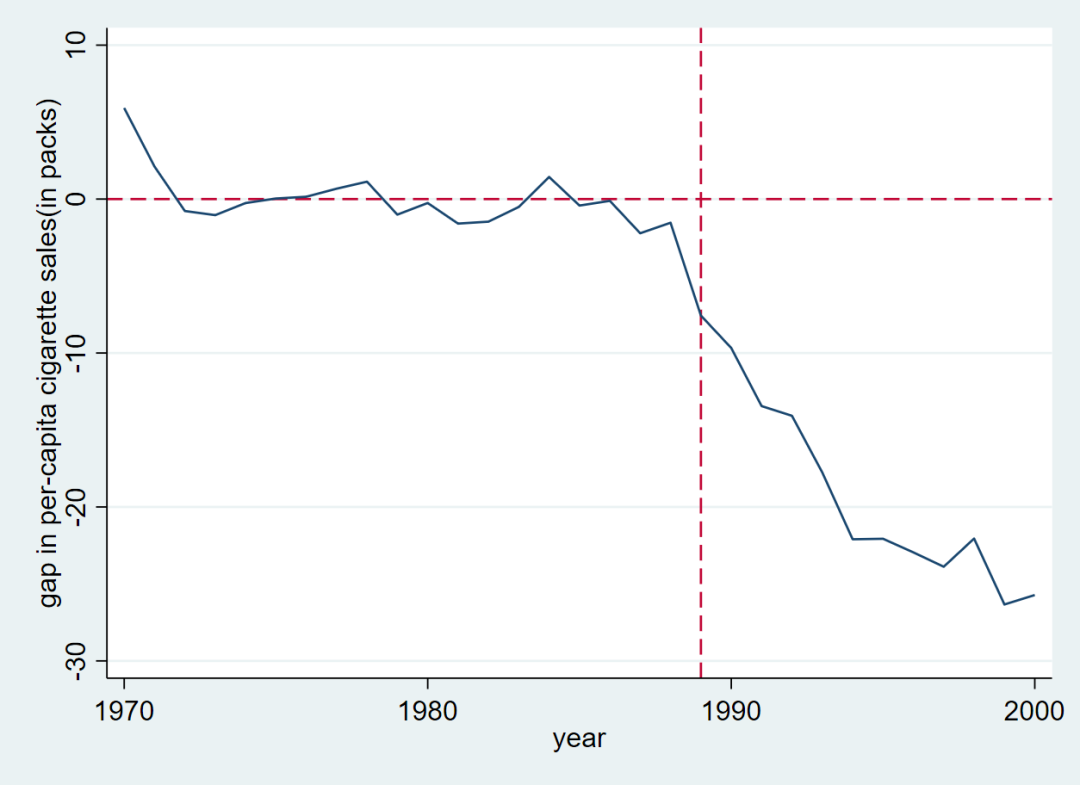
处理效应的时间趋势图
通过上图的处理效应的时间趋势图,我们可以看到,加州控烟法对于人均香烟消费量有很大的负效应,而且此负效应随着时间的推移而变大。具体来说,在1989-2000年期间,加州的人均年香烟消费减少了20多包,大约下降了25%之多,故其经济效应十分显著。
最后,对上述处理效应结果的稳健性进行检验。为了检验上述合成控制估计结果的稳健性,Abadie等人在他们的文章中加入了更多的预测变量,比如失业率、收入不平等、贫困率、福利转移、犯罪率、毒品相关的逮捕率香烟税、人口密度等等,发现结果依然稳健。另外一个担心是,地区之间无相互影响的假定可能不满足,比如加州的反烟运动可能波及到其他州,烟草行业或将其他州的香烟广告预算投入到加州,甚至从其他州走私便宜香烟到加州,Abadie等人根据史实对此进行了探讨,认为这些效应均不大,至少不可能导致上述图中如此大的处理效应。
合成控制法的稳健性检验
安慰剂检验
在上面对加州控烟法有效性的评估是对控烟法处理效应的点估计,我们需要对这个点估计在统计上的显著性进行判断。
Abadie等人认为,在比较案例研究中,由于潜在的控制地区数目通常并不多,所以不适合使用大样本理论进行统计推断。为此,Abadie等人提出使用“安慰剂检验”来进行统计检验,这种方法类似于统计学中的“排列检验”,适用于任何样本容量。
“安慰剂”(placebo)一词来自医学上的随机试验。比如,要检验某种新药的疗效,此时可将参加实验的人群随机分为两组,其中一组为实验组,服用真药;而另一组为控制组,服用安慰剂(比如,无用的糖丸),并且不让参与者知道自己服用的究竟是真药还是安慰剂,以避免由于主观心理作用而影响实验效果,称为“安慰剂效应”(placebo effect)。
“安慰剂检验”借用了“安慰剂”的思想,通常有三种方法进行“安慰剂检验”。
结合加州控烟法的案例。
第一种方法,为了检验案例中合成控制法所估计的控烟效应是否完全由偶然因素所驱动。我们可以从donor pool中随机抽取一个州(并不是加州)进行合成控制估计,观察是否会得到和加州类似的效应,这就相当于重新对其他38个州重复38遍合成,以观察是否存在类似的效应。
第二种方法,直接将每个州“干预后的MSPE”与“干预前的MSPE”相比,即计算二者的比值。
第二种方法的基本逻辑是:对于处理地区(加州)而言,如果控烟法有效果,那么合成控制将无法很好地预测真实加州干预后的结果变量,导致较大的干预后的MSPE。然而,如果在干预之前,合成加州就无法很好地预测真实加州的结果变量(产生较大的干预前的MSPE),这也会导致干预后的MSPE增大,所以选取二者的比值以控制前者的影响。如果加州控烟法确实有较大的处理效应,而其他州的安慰剂效应都很小,则应该观测到加州的“干预后的MSPE”与“干预前的MSPE”的比值明显高于其他各州。
第三种方法,基于时间的安慰剂检验,这种方法要求政策发生前要有很长的时期,对数据有着一定的限制,我们需要通过论证政策在实施点之前的年份中影响是不显著的,从而证明政策实施之后存在着明显的处理效应。
Abadie等人进行了一系列的安慰剂检验,依次将donor pool中的每个州作为假想的处理地区(即假设也在1988年通过控烟法),然后使用合成控制法估计其“控烟效应”。
在对某个州进行安慰剂检验时,如果在“干预之前”其合成控制的拟合效果很差(即均方预测误差MSPE很大),那么有可能出现在“干预之后”的“效应”波动也很大,从而导致结果不可信。
干预之前的MSPE可写为 (以加州为例):
MSPE p r e ≡ 1 T 0 ∑ t = 1 T 0 ( y 1 t − ∑ j = 2 J + 1 w j ∗ y j t ) 2 \operatorname{MSPE}_{p r e} \equiv \frac{1}{T_{0}} \sum_{t=1}^{T_{0}}\left(y_{1 t}-\sum_{j=2}^{J+1} w_{j}^{*} y_{j t}\right)^{2} MSPEpre≡T01t=1∑T0(y1t−j=2∑J+1wj∗yjt)2
为此,Abadie等人仅保留了干预前MSPE不超过加州干预前MSPE两倍的19个州。

上图为19个州的安慰剂检验结果,其中,黑线表示加州的处理效应,即加州与合成加州的人均香烟消费之差;灰线表示其他19个控制州的安慰剂效应。显然,与其他州的安慰剂效应相比,加州的(负)处理效应显得特别大。假如加州的控烟法并无任何效应,则在这20个州中碰巧看到加州的处理效应最大的概率仅为1/20。
上图将39个州干预后与干预前MSPE的比值以直方图的形式呈现出来,可以看到:加州的干预后的MSPE是干预前的MSPE的大约130倍,高于所有其他38个州。如果加州控烟法完全无效,而由于偶然因素使得此比值在所有39个州中最大的概率仅为1/39。
使用合成控制法的注意事项
Abadie等人在2015年的文章中进一步探讨了使用合成控制法的前提与局限性。
Abadie Alberto, Alexis Diamond, and Jens Hainmueller, "Comparative Politics and the Synthetic
Control Method", American Journal of Political Science, 2015, 59(2), 495-510.
- 第一,同样受到此政策影响的地区应从donor pool中去掉。
- 第二,在样本期间受到很大特殊冲击的地区应排除在donor pool之外。
- 第三,为了避免“内插偏差”(interpolation biaas),应将donor pool限定为与处理地区具有相似特征的控制地区。
- 第四,在应用合成控制法时,要求干预前期数达到一定规模。这是因为,合成控制法的可信度取决于合成控制能在干预前的相当一段时期内很好地追踪处理地区的经济特征与结果变量。如果干预前的拟合不好,或干预前期数太短,则不建议使用合成控制法。
- 第五,如果政策冲击的效应需要一段时间才会显现(滞后效应),则要求干预后的期数足够大,此时才能够对该政策的效应进行评估。
(十一)断点回归
断点回归设计理论
断点回归设计(Regression Discontinuity Design)由Thistlewaite and Campbell(1960)首次使用,但直到1990年代末才引起经济学家的重视。Hahn et al(2001)提供了断点回归的计量经济学理论基础。目前,断点回归在教育经济学、劳动经济学、健康经济学、政治经济学以及区域经济学等领域的应用仍然方兴未艾。
我们以一个上大学的教育回报的案例来理解断点回归设计。
我们需要研究的是:上大学与不上大学对工资薪酬有没有影响?有多大的影响?
假设有一名叫Mike的同学:
- Mike不上大学的工资是 Y i 0 Y_{i0} Yi0;
- Mike上大学后能赚到的工资是 Y i 1 Y_{i1} Yi1 。
那么 就是读大学给Mike带来的薪酬改变 Y i 1 − Y i 0 Y_{i1}-Y_{i0} Yi1−Yi0。但是,对于研究人员来说,我们不能既让Mike上大学,又不让Mike上大学,即我们只能获得 Y i 0 Y_{i0} Yi0与 Y i 1 Y_{i1} Yi1其中的一个数据,这样我们就无法得知读大学对薪酬所带来的影响。此时,我们就需要引入断点回归设计。
我们假设: 上大学与否( D i D_i Di )完全取决于高考成绩 是否超过500分:
D i = { 1 若 x i ≥ c 0 若 x i < c D_{i}= \begin{cases}1 & \text { 若 } x_{i} \geq c \\ 0 & \text { 若 } x_{i}<c\end{cases} Di={10 若 xi≥c 若 xi<c
记不上大学与上大学的两种潜在结果分别为 ( y 0 i , y 1 i ) (\mathrm{y}_{0i} , \mathrm{y}_{1i}) (y0i,y1i) 。
处理变量Di为 x i x_{i} xi 的函数, 记为 D ( x i ) D\left(x_{i}\right) D(xi) 。在给定 x i x_{i} xi 的情况下, 可将Di视为常数。即 不可能与任何变量有关系。
对于高考成绩为498、499、500或501的考生(500分附近的考生),可以认为他们在各方面(包括可观测变量与不可观测变量)都没有系统差异,他们高考成绩的细微差异只是由于“上帝之手”随机抽样的结果,从而导致成绩为500或501的考生上大学(进入处理组),而成绩为498或499的考生落榜(进入控制组)。因此,由于制度原因,仿佛对高考成绩在小邻域 之间的考生进行了随机分组,所以可以视为准实验(quasi experiment)。
断点回归设计中处理组和对照组都不是随机的,但是存在一个分组规则,决定哪些个体属于处理组,哪些个体属于对照组。
考试成绩本身包含随机因素,如果考生能够事先知道分组规则,并通过自身的努力完全控制分组变量 的取值,从而可以自行选择进入处理组或对照组,那么断点回归将会失效。但在一般情况下考生无法精确地控制成绩,因此,在断点附近的考生,成绩大于或小于断点的概率大约都是二分之一,形成局部的随机分组。
由于存在随机分组,所以我们可以一致地估计在 附近的局部平均处理效应(Local Average Treatment Effect,简记LATE),即
眹 由于存在随机分组, 故可一致地估计在 x = 500 x=500 x=500 附近的局部平均处理 效应(LATE):
LATE ≡ E ( y 1 i − y 0 i ∣ x = 500 ) = E ( y 1 i ∣ x = 500 ) − E ( y 0 i ∣ x = 500 ) = lim x ≤ 500 E ( y 1 i ∣ x ) − lim x ↑ 500 E ( y 0 i ∣ x ) \begin{aligned} \text { LATE } & \equiv \mathrm{E}\left(y_{1 i}-y_{0 i} \mid x=500\right) \\ &=\mathrm{E}\left(y_{1 i} \mid x=500\right)-\mathrm{E}\left(y_{0 i} \mid x=500\right) \\ &=\lim _{x \leq 500} \mathrm{E}\left(y_{1 i} \mid x\right)-\lim _{x \uparrow 500} \mathrm{E}\left(y_{0 i} \mid x\right) \end{aligned} LATE ≡E(y1i−y0i∣x=500)=E(y1i∣x=500)−E(y0i∣x=500)=x≤500limE(y1i∣x)−x↑500limE(y0i∣x)
其中, lim x → 500 ; lim x > 500 \lim _{x \rightarrow 500} ; \lim _{x>500} limx→500;limx>500 分别表示从 500 的右侧与左侧取极限, 左右侧极限值的 差异体现的就是政策效应。
断点回归可以分为两种类型,一种是"精确断点回归",另一种是"模糊断点回归。"精确断点回归"的特征是:在断点 处,个体得到处理的概率从0跳跃为1;“模糊断点回归”的特征是:在断点 处,个体得到处理的概率从a跳跃为b,其中0<a<b<1。笔记只整理了"精确断点回归"的内容,"模糊断点回归"的详细内容可以查看陈强教授的《高级计量经济学及Stata应用(第二版)》中的内容。
假设实验前, y i y_{i} yi 与 x i x_{i} xi 存在线性关系:
y i = α + β x i + ε i y_{i}=\alpha+\beta x_{i}+\varepsilon_{i} yi=α+βxi+εi
且不失一般的, 处理效应为正, 即在断点处存在一个向上的跳跃。
由于在断点附近,个体在各方面均无系统差别,所以造成条件期望函数在此跳跃的唯一原因只可能是 D i D_i Di 的处理效应。
为了估计这一影响,我们构造断点回归设计RDD回归方程:
y i = α + β ( x i − c ) + τ D i + γ ( x i − c ) D i + ε i ( i = 1 , 2 … n ) y_{i}=\alpha+\beta\left(x_{i}-c\right)+\tau D_{i}+\gamma\left(x_{i}-c\right) D_{i}+\varepsilon_{i} \quad(i=1,2 \ldots n) yi=α+β(xi−c)+τDi+γ(xi−c)Di+εi(i=1,2…n)
其中, ( x − c ) (x-c) (x−c) 是为了将断点变为 0 , 引入虚拟变量 D D D 是为了产生不同的截距项, 引入交互项则允许断点两侧的回归斜率不同。
当 D = 0 D=0 D=0 时, 得到左边那段线, 当 D = 1 D=1 D=1 时, 得到的是右边那段线。对上式进行OLS回归, 所得虚拟变量 D D D 的系数就是 x = c x=c x=c 处的局部平均处理效应的估计量, 也即政策效应。由于此回归存在一个断点,所以称为"断点回归"或"断点回归设计"。
在有交互项的情况下,如果在上述方程中使用 而不是标准化变量 ,则 虽然度量断点两侧回归线的截距之差,但并不等于这两条回归线在 处的跳跃距离。这是因为,存在交互项意味着断点两侧的回归线斜率不同,并非平行线,所以在断点处的跳跃距离并不等二者的截距项之差。
上述方程等价于使用断点两侧的数据分别进行回归,然后计算两侧截距项之差。如果断点两侧的回归线斜率不同,但未包括交互项,即相当于强迫两侧的斜率相同。这会导致断点右(左)侧的观测值影响对左(右)侧截距项的估计(我们不希望有此影响),从而引起偏差。
对上述方程(5)进行断点回归的估计可能会出现两个问题。首先,如果回归函数包含高次项(比如二次项 )则会导致遗漏变量偏差;其次,既然断点回归是局部的随机试验,那么原则上只应该使用断点附近的观测值,但方程(5)的估计是使用的整个样本。
为了解决以上两个问题,我们在方程(5)的基础上引入高次项(比如二次项)
其中, 为对LATE的估计量,并可以使用稳健标准误来控制可能存在的异方差。
由于在断点附近仿佛存在随机分组,所以一般认为断点回归是内部有效性比较强的一种准实验。在某种意义上,断点回归可以视为"局部随机实验";而且,可以通过考察协变量在断点两侧的分布是否具有显著差异来检验此随机性。另一方面,断点回归仅推断在断点处的因果关系,并不一定能推广到其他样本值,所以外部有效性受局限。
因为最优带宽 通常是难以确定的,而且在设定函数的情况下还与函数的具体形式有关,所以,研究者们开始转向非参数回归,不再依赖于具体的函数形式,这种非参数回归的方法还可以通过最小化均方误差(MSE)来选择最优带宽 ,通常情况下使用的方法都是局部线性回归的方法,具体的模型设定是:
min { α , β , δ , γ } ∑ i = 1 n K [ ( x i − c ) / h ] [ y i − α − β ( x i − c ) − δ D i − γ ( x i − c ) D i ] 2 \min _{\{\alpha, \beta, \delta, \gamma\}} \sum_{i=1}^{n} K\left[\left(x_{i}-c\right) / h\right]\left[y_{i}-\alpha-\beta\left(x_{i}-c\right)-\delta D_{i}-\gamma\left(x_{i}-c\right) D_{i}\right]^{2} {α,β,δ,γ}mini=1∑nK[(xi−c)/h][yi−α−β(xi−c)−δDi−γ(xi−c)Di]2
上式中, 为局部回归的残差平方和; 为加权核函数,越接近断点,权重越大,一般默认为三角核函数,也可以使用矩形核(权重相等,相当于普通OLS回归),简而言之,三角核函数属于加权的OLS。
局部线性回归的实质是,在一个小邻域 内进行加权最小二乘估计,此权重由核函数来计算,离 越近的点权重越大。
最优带宽 的确定通常有三种方法:
- Cross Validation(Ludwig & Miller,2007),简记为CV;
- Imbensand Kalyanaraman(2012),简记为IK;
- Calonico,Cattaneo,Titiunik(2012,2017),简记为CCT。
Stata的命令rd,默认使用IK法确定最优带宽;命令rdrobust提供CCT最新多种不同的最优带宽计算方法选项(mserd、cerrd,默认为mserd)。
断点回归设计也需要进行稳健性检验,由于断点回归在操作上存在不同选择,实践中一般建议同时汇报以下四种情形,以保证稳健性。
- 分别汇报三角核与矩形核的局部线性回归结果(后者等价于线性参数回归);
- 分别汇报使用不同带宽的结果(比如,最优带宽及其二分之一或两倍带宽),即不同计算方式,需要自己计算出然后加入到回归命令中;
- 分别汇报包含协变量与不包含协变量的情形;
- 进行模型设定检验,包括检验分组变量(如高考分数)与协变量的条件密度是否在断点处连续,防止存在人为操作。
对于协变量的条件密度是否连续除了画图外还可以使用"跑回归"的方式,也即将协变量逐个作为被解释变量进行回归,看是否存在显著的政策效应,如果存在则表明协变量不连续。
断点回归设计的Stata命令
断点回归设计在Stata中的命令主要有:
- rdrobust:断点回归设计的命令
- rdbwselect:选择最优带宽的命令
- rdbinselect:处理箱体的命令
- rdplot:画图的命令,用来检验是否存在跳跃点
- McCrary Test:检验分组变量与协变量的条件密度是否在断点处连续
rdrobust命令的基本格式如下:
rdrobust depvar runvar [if] [in] [ , c(cutoff) p(pvar) q(qvar) kernel(kernelfn) h(hvar) b(bvar) rho(rhovar) covs(covars) bwselect(bwmethod) delta(deltavar) vce(vcemethod) matches(nummatches) level(level) all ]
"depvar"是被解释变量;"runvar"是分组变量;
"c(cuoff)"中填写分组变量的断点;
"p(pvar)"是局部多项式点估计,默认为局部线性;
"q(qvar)"指定多项式的阶数,默认为2阶;
"kernel(kernelfn)"用来指定核函数,默认为三角核函数(另外两个选项分别为均匀核函数(uniform)和伊番捏切科夫核函数(epanechnikov),三种核函数的主要区别是误差项平方和前权重的大小是不同的);
"h(hvar)"为带宽选择,默认使用最优带宽(我们也可以手动计算带宽的0.5、1.5、2倍等值带入括号中,在稳健性检验时常常使用这种方法);
"b(bvar)"对箱体进行设定,比如括号中如果填写100,就是将箱体个数放大100倍;
"covs(covars)"中放入协变量;
"bwselect(bwmethod)"是估计带宽的方法,默认为CCT方法;
“all”表示均使用默认值。
命令rdbwselect、rdbinselect与rdplot的语法格式与rdrobust相似。
McCrary Test命令的基本格式为:
DCdensity assign_var, breakpoint(#) generate(Xj Yj r0 fhat se_fhat) graphname (filename)
其中,"assign_var"为分组变量;
必选项"breakpoint(#)"用来指定断点位置;
必选项"generate(Xj Yj r0 fhat se_fhat)"用来指定输出变量名;
选择项"graphname (filename)"用来指定密度函数图的文件名。
断点回归设计的案例操作
研究美国民主党候选人在本届的当选情况对自己在本辖区内下一届竞选得票率的影响,即考察当期在位者的优势。根据美国竞选法,当一个辖区内民主党得票率超过50%,即可获胜当选成为在位者。
显然,分组变量就是本届得票率,断点为0.5。如果将民主党与共和党的当期得票率作差,此时断点就变成0。
案例中具体包括如下变量:
- vote:民主党候选人在下次参议院选举中的得票比例。
- margin:民主党候选人在上次参议院选举中的得票比例减去共和党候选人在上次参议院选举中的得票比例(判断下次选举时是否连任,断点为0)。
- class:美国参议院有100个席位,分为三个组,每组有33-34人,每隔两年轮换一次,class指在哪一个组任职。
- termshouse:某议员在众议院任职任期数。
- termssenate:某议员在参议院任职任期数。
- population:某个州的人口总数。
在Stata中调用"rdrobust_senate.dta"数据集,并查看数据集信息。
use "D:\rdrobust_senate.dta"
des
sum vote margin class termshouse termssenate population,sep(2)
通过des命令,我们可以看到,这个数据集中有1390个观测值,8个变量。此外,我们也可以看到各变量的标签。
通过sum命令我们可以查看各变量的描述性统计情况,命令中"sep(2)"是指每两个变量隔一条线。
接下来,我们在Stata中实现断点回归设计。
rdbinselect vote margin, scale(100)
使用rdbinselect命令进行估计(也可以使用新命令rdplot进行这一估计)。其中,"vote"是被解释变量,"margin"是分组变量,"scale(100)"是将箱体个数扩大100倍。

从输出结果我们可以看到,在断点左侧有595个观测值,在断点右侧有702个观测值;“Poly.order”显示使用了四阶多项式进行拟合;断点左侧的箱体数目为3个,右侧为6个;断点左侧箱体的宽度为33.307,右侧箱体宽度为16.661。表格的下半部分是将箱体个数扩大了100倍后的结果,箱体个数扩大为原来的100倍,箱体宽度缩小为原来的100倍。
与此同时,通过rdbinselect命令我们还得到了回归函数的拟合图,如下图所示。
[外链图片转存中…(img-YCRw5pxb-1640317583332)]
上图中的每个点对应着每个直方图的均值,300个箱体即为300个点,每个点就是箱体包含数据的均值。断点左侧表示在位者不是民主党人时,民主党下次当选的得票率;右侧表示在位者是民主党人时,民主党下一次还当选的得票率。观察上图,可以很明显的看到:在断点处有一个跳跃,这个跳跃一定程度上反映了在位者的优势。
接下来,我们对这一结果进行估计。
rdrobust vote margin,all
[外链图片转存中…(img-xfUA8WV4-1640317583333)]
由结果可知,计算最优带宽的方法"BW type"是“mserd”,加权核函数"Kernel"为三角核函数"Triangular"。左侧的观测值是595个,右侧的观测值是702个,§=1说明是一次函数形式,最优带宽(h)为17.754,修正之后的最优带宽(最优带宽可能是有偏移的)为28.028。
我们可以看到显著的政策效应为7.4141,最优带宽修正之后的结果为7.5065,其所对应的p值均为0.000,小于0.01,说明在位者优势能够给下一期带来更多的选票。表格中最后一行的"Robust"是针对偏移修正的情况,提供了一个稳健标准误的结果。
最后,我们对上述的估计结果进行稳健性检验
依照第一部分的内容,有四种方法进行稳健性检验,我们应当同时汇报四种方法的结果。
第一种方法: 使用另外一种计算最优带宽的方法检验。
rdrobust vote margin,all bwselect(cerrd) c(0) p(1) kernel(triangular)rdrobust vote margin,all bwselect(cerrd) c(0) p(1) kernel(triangular)
[外链图片转存中…(img-hFyj551W-1640317583334)]
可以看到,使用"cerrd"计算最优带宽得到的结果为7.6316与"mserd"得到的结果7.4141相差不大,且二者在1%的显著性水平下均显著。
第二种方法: 先选定一种计算最优带宽的方法,然后查看最优带宽的二分之一或者两倍的结果。
指定固定带宽估计的命令
rdrobust vote margin, all h( ) b( ) //估计时要在()中填入具体数字
命令rdbwselect可以提供所有计算最优带宽的方法和结果
rdbwselect vote margin,all
[外链图片转存中…(img-nLl96Eqx-1640317583335)]
上表呈现了10种计算最优带宽的方法和结果。
我们以上表中第一个结果为例,h=17.754,b=28.028。查看二分之一最优带宽和两倍最优带宽的结果。
rdrobust vote margin, all h(8.877) b(14.014)
rdrobust vote margin, all h(35.508) b(56.056)
| [外链图片转存中…(img-T6Yq1EMf-1640317583336)] | [外链图片转存中…(img-AjcRYyBN-1640317583336)] |
|---|---|
上述结果显示,在1%的显著性水平下结果均是显著的。
第三种方法: 加入协变量查看结果是否稳健。
rdrobust vote margin, all covs(class termshouse termssenate)
[外链图片转存中…(img-kbAjfenS-1640317583337)]
由得到的结果可知,政策效应为6.85,修正后的结果为6.99,两个结果在1%的显著性水平下均是显著的。
第四中方法: 设定检验,检验协变量和分组变量的条件密度在断点处是否连续。
命令hist margin可以绘制频数直方图;命令kdensity margin可以绘制密度直方图。
hist margin
kdensity margin
绘制条件密度函数图
DCdensity margin, breakpoint(0) generate(Xj Yj r0 fhat se_fhat) graphname(rd.eps)
上图中,黑色的线即为条件密度,黑线旁边的两条线表示一个置信区间。可以看到在断点处两个区间是有交集的,所以可以判断分组变量在断点处是连续的。
另外一种协变量条件密度检验的方法为"跑回归",即分别将协变量作为被解释变量进行断点回归,预期的结果应当是不显著的。
rdrobust class margin,all
rdrobust termshouse margin,all
rdrobust termssenate margin,all
观察上述三个命令的拟合结果可知,与预期相符所有协变量断点回归的结果均不显著。