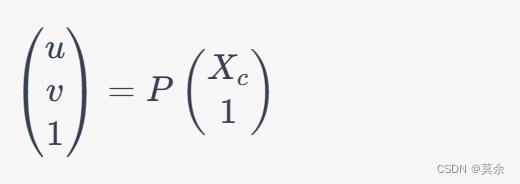RAT-SQL
RAT-SQL(Relation-Aware Transformer-SQL)是微软在2020 ACL发表的论文RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers 提出的模型,这个模型在Spider数据集上的结果为65.6%。RAT-SQL代码的地址为https://github.com/Microsoft/rat-sql,笔者尝试了paddle 版本的RAT-SQL代码https://github.com/PaddlePaddle/Research/tree/master/NLP/Text2SQL-BASELINE
论文的亮点:
(1)以一种的可见的语义parser编码数据库关系
(2)给定一个query或者question模型对应数据库中的列和其相关项
(3)在统一的框架下编码question与数据库schema之间的关系
模型介绍
RAT-SQL模型主要应用在schema encoder 和linking的问题上。首先,要定义text-to-sql的语义部分的问题,可以理解为question,query和 数据库之间的语义schema编码,其次根据这些语义schema编码进行schema linking,text-to-sql生成。
text-to-SQL的问题定义
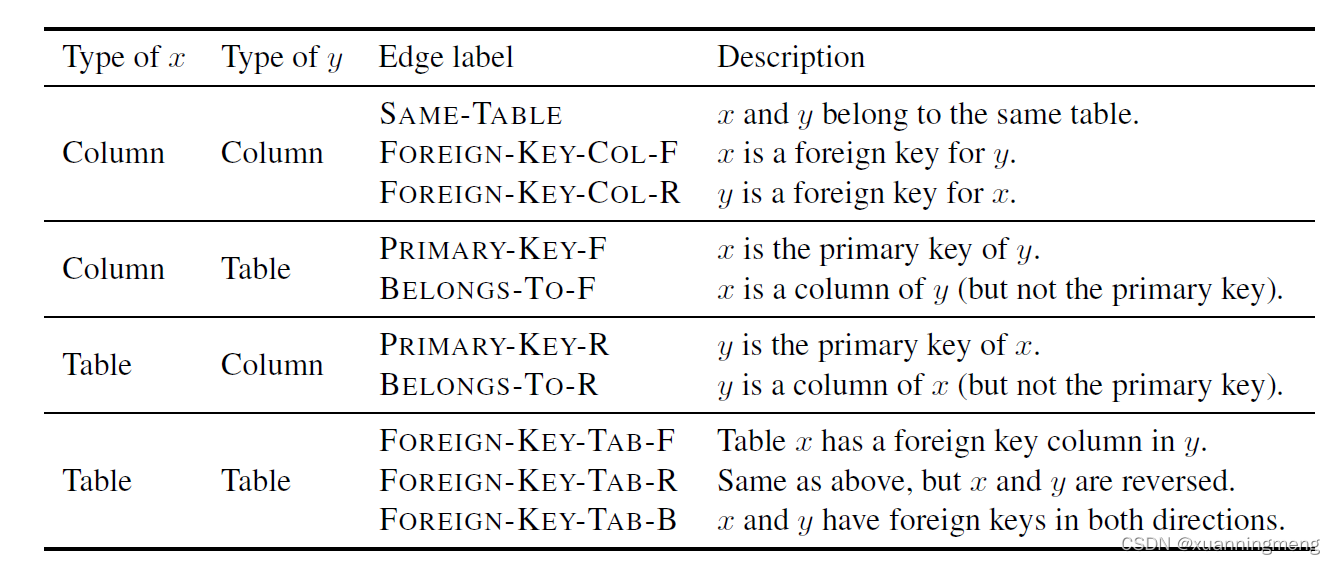
给定一个文本问题question和关系数据库的schema生成一个sql语句 P P P。schema表示为 S = < C , T > S = <C, T> S=<C,T>其中 C C C表示列, T T T表示表。生成的sql语句 P P P 是一颗满足SQL 文本语法的abstract syntax tree。数据库的schema中的部分列 C C C有foreign keys和primary keys,列是有类型的,这里列的类型type τ ∈ { n u m b e r ; t e x t } \tau\in\{number; text\} τ∈{number;text}。这里关系数据库的schema表示为graph G = < V , E > \mathcal{G} = <\mathcal{V}, \mathcal{E}> G=<V,E>,其中 V = C ∪ T \mathcal{V} = C \cup T V=C∪T,边 E \mathcal{E} E的定义如下图:
question 在graph G = < V , E > \mathcal{G} = <\mathcal{V}, \mathcal{E}> G=<V,E>中没有显性昂的表示,所以在模型中的shema S S S中加入question Q Q Q进行联合表征得到questioncontextualized schema graph G Q = < V Q , E Q > = < C ∪ T ∪ Q , E ∪ E Q ↔ S > \mathcal{G_{Q}} = <\mathcal{V_{Q}}, \mathcal{E_{Q}}>=<C\cup T\cup Q, \mathcal{E}\cup\mathcal{E_{Q\leftrightarrow S}}> GQ=<VQ,EQ>=<C∪T∪Q,E∪EQ↔S>,其中 E Q ↔ S \mathcal{E_{Q\leftrightarrow S}} EQ↔S是question和schema 之间的定义的额外关系。
Relation-Aware Input Encoding
RAT-SQL的encoding的输入 X X X包含列 C C C,表 T T T和question Q Q Q,具体表示如下:
X = ( c 1 i n i t , ⋯ , c ∣ C ∣ i n i t , t 1 i n i t , ⋯ , t ∣ T ∣ i n i t , q 1 i n i t , ⋯ , q ∣ Q ∣ i n i t ) X = (c_{1}^{init},\cdots,c_{|C|}^{init},t_{1}^{init},\cdots,t_{|T|}^{init},q_{1}^{init},\cdots,q_{|Q|}^{init} ) X=(c1init,⋯,c∣C∣init,t1init,⋯,t∣T∣init,q1init,⋯,q∣Q∣init)
X X X的初始化可以使用glove,bilstm或者bert的embedding。这里是使用的bert预训练模型得到embedding,encoding过程使用N个Relation-Aware Self-Attention进行文本特征表征, c i , t i , q i \pmb{c}_{i},\pmb{t}_{i},\pmb{q}_{i} ccci,ttti,qqqi由最后一层Nattention的结果作为特征提取结果。下面重点介绍一下Relation-Aware Self-Attention和shema linking。
1.Relation-Aware Self-Attention
Relation-Aware Self-Attention在计算attention中加入了新的偏置项 r i j r_{ij} rij,这个 r i j r_{ij} rij是根据提前定义的边关系得到的。将会在schema linking中重点介绍。
- 常用的attention计算
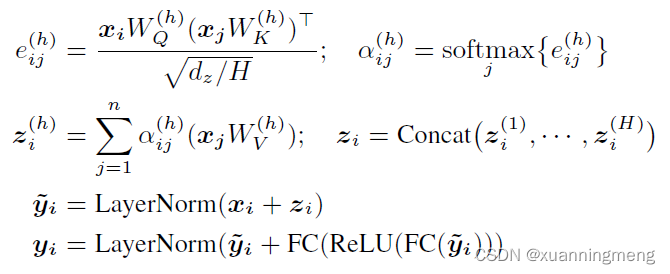
- Relation-Aware Self-Attention
加入了 r i j V \pmb{r_{ij}^{V}} rijVrijVrijV和 r i j K \pmb{r_{ij}^{K}} rijKrijKrijK这两个偏置项,计算公式如下:
e i j ( h ) = x i W Q ( h ) ( x j W K ( h ) + r i j K ) T d z / H z i h = ∑ j = 1 n α i j ( h ) ( x j W V ( h ) + r i j V ) \begin{aligned} e_{ij}^{(h)}&= \frac{x_{i}W_{Q}^{(h)}{(x_{j}W_{K}^{(h)} + \pmb{r_{ij}^{K}})}^T}{\sqrt{d_{z}/H}}\\ & z_{i}^{h} = \sum_{j=1}^{n}\alpha_{ij}^{(h)}(x_{j}W_{V}^{(h)} + \pmb{r_{ij}^{V}}) \end{aligned} eij(h)=dz/HxiWQ(h)(xjWK(h)+rijKrijKrijK)Tzih=j=1∑nαij(h)(xjWV(h)+rijVrijVrijV)
其中 每一对边(i,j) 视为 r i j V = r i j K = c o n c a t ( ρ i j ( 1 ) , ⋯ , ρ i j ( R ) ) \pmb{r_{ij}^{V}}=\pmb{r_{ij}^{K}}=concat(\rho_{ij}^{(1)}, \cdots,\rho_{ij}^{(R)}) rijVrijVrijV=rijKrijKrijK=concat(ρij(1),⋯,ρij(R)),如果 ρ i j ( s ) \rho_{ij}^{(s)} ρij(s)属于提前的定义的的边关系类型中,则 ρ i j ( s ) \rho_{ij}^{(s)} ρij(s)是learned embedding,反之是零向量。
2.Schema Linking
在 E Q ↔ S \mathcal{E_{Q\leftrightarrow S}} EQ↔S中的schema linking 关系目的是使得question和数据库schema中的列、表对齐,包含matching names和match value。
- Name-Based Linking
将question与数据库schema进行exact match和partial match,这里采用1到5的n-gram进行match,将match到结果用relation edge编码,例如ralation edge的定义如下:
| type | type | edge label |
|---|---|---|
| column | column | SAME-TABLE |
| column | column | FOREIGN-KEY-COL-F |
| column | table | PRIMARY-KEY-F |
| column | column | FOREIGN-KEY-COL-R |
| column | table | BELONGS-TO-F |
| table | column | PRIMARY-KEY-R |
| table | column | BELONGS-TO-R |
| table | table | FOREIGN-KEY-TAB-F |
| table | table | FOREIGN-KEY-TAB-R |
| table | table | FOREIGN-KEY-TAB-B |
| question | name | QUESTION-COLUMN-M |
| question | name | COLUMN-QUESTION-M |
| question | name | QUESTION-TABLE-M |
| question | name | TABLE-QUESTION-M |
| table | value | COLUMN-VALUE |
- Value-Based Linking
question 与数据库content进行匹配,获取column以及relation edge,value-based linking可以处理数据库方面的两个挑战,分别是模型不会暴露数据库中未出现的内容以及通过数据库索引文本搜索可以快速进行字搜索 - Memory-Schema Alignment Matrix
通常SQL P中出现的column和table会在question中引用,为了加强这一个特征,这里采用relation-aware attention 作为一个pointer mechanism 使得每一个元素与column,table进行对齐。公式如下
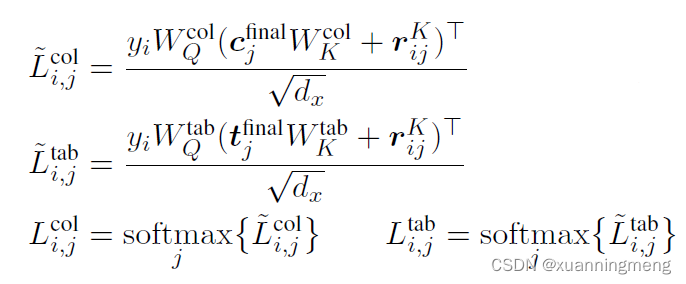
schema linking 得到的矩阵是Relation-Aware Self-Attention中的rij,rij的中的每一个元素对应着relation 边schema的编码,每一条数据有一个rij矩阵,这个矩阵构建了输入X中的question,table和column中的每一个元素i和元素j之间的边的关系,详细说明见后面的代码补充说明。
Decoder
生成的SQL P P P 是一个深度优先的语法树,是通过lstm解码得到的,在生成的最后的节点扩展为APPLYRULE,或者在最后节点从schema选择column和table,这个过程称为SELECTCOLUMN 和SELECTTABLE。解码表达式为
P r ( P ∣ Y ) = ∏ t P r ( a t ∣ a < t , Y ) P_{r}(P|\mathcal{Y}) = \prod_{t} P_{r}(a_{t}| a_{<t}, \mathcal{Y}) Pr(P∣Y)=t∏Pr(at∣a<t,Y)
其中 Y \mathcal{Y} Y是encoding得到的结果。
APPLYRULE的计算过程如下:
P r ( a t = A P P L Y R U L E [ R ] ∣ a < t , y ) = s o f t m a x ( g ( h t ) ) P_{r}(a_{t}=APPLYRULE[R]|a_{<t},y) = softmax(g(h_{t})) Pr(at=APPLYRULE[R]∣a<t,y)=softmax(g(ht))
其中 h t h_{t} ht是lstm的hidden state, g g g是两层激活函数为tanh的mlp。
SELECTCOLUMN 和SELECTTABLE的过程类型:
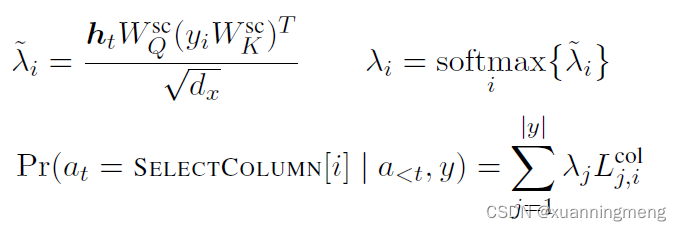
RAT-SQL(Paddle)代码说明
这部分的内容是根据paddlepaddle给出的rat-sql代码进行说明。
模型输入数据
文本表示:question table_type table column_type column match_cell_type match_celll_value predict_value_type predict_value value_type value ,这里的match_celll_value是question中的数字和时间, vlaue 是sql语句中的limit和条件中的值。
格式如下:q1,q2,…,qn, [SEP],table_type, t11, t12, …, column_type_1,c11,c22,…,c1m,…,column_type_k,ck1,ck2,…,ckm,[SEP],…, 用sep间隔
schema linking补充说明
这里是争对Name-Based Linking和Value-Based Linking进行补充说明。relation edge定义的类型包含default,sc linking(Name-Based Linking)和cv linking(Value-Based Linking)类型。三种类型分别如下:
default类型有qc_default,qt_default,cq_default,ct_default,cc_default等,
sc_linking的类型有qcCEM,qcCPM,qtTEM,qtTPM,cqCEM等,cv_linking的类型有qcNUMBER,cqNUMBER,qcTIME,cqTIME,qcCELLMATCH,cqCELLMATCH等,
-
Name-Based Linking
(1) 先进行question与数据库schema进行匹配,即question与数据库中的table,column按照分词 n-gram的方式进行exact matching和partial matching,得到 question token index, table_index, linking type 或者question token index, column_index, linking type
(2) 根据question 分词的token mapping得到question 字符级的match 结果,这个结果可以理解为一个三元组(question char index, table_index, linking type) 或者 (question char index, column_index, linking type) ,实际上代码是保存为一个字典形式,key值为question char index, table_index 或者question char index, column_index -
Value-Based Linking
(1) question 与数据库中的content进行matching,question 分词是否在数据库 content cell的值中, 如果在cell的值中,得到match结果 question token index,column index,linking type,
(2) 如果question分词是数值,判断column 是否为数值型,real型和日期型中的一种,则得到 question token index,column index,linking type,
(3) 根据 question 分词的token mapping得到quesiton字符级的match 结果,question index,column index,linking type -
R R R矩阵构建说明
(1) 初始化关系矩阵是全为0的n x n方阵, n的值为 question 长度 + table 数量 + column数量
(2) question table column的类型字典, key的值为0到n-1,每一个key的value是question,table,column之一
(3) 对初始化矩阵进行遍历,结合question table column的类型字典,sc linking,cv linking 以及linking type字典进行编码得到关系矩阵
实验结果
在百度text-to-sql数据集训练集的大小为22521,验证集的大小为2482,测试集的大小为3759,数据库的大小为208,预训练模型是ernie tiny,paddle版rat-sql训练30epoch的结果为:
with value: {‘count’: 2482, ‘exact’: 1331, ‘acc’: 0.5362610797743755}
without_value {‘count’: 2482, ‘exact’: 1687, ‘acc’: 0.6796937953263498}
以上是rat-sql的介绍,如果表述错误,请指出。