如果你正在准备建立支持CUDA的新平台并在上面进行编程,建议你精读CUDA的硬件架构——《CUDA专家手册》Nicholas Wilt 著。
CUDA入门很简单,上手不到三天,我就写些CUDA程序。但是都没有进行效率上的分析,也只是单单的窥视了GPU加速的魅力。要成为一个充分榨取GPU处理能力的并行计算工程师也绝非易事,至此不再单纯编写CUDA程序,重点放在优化上。
阅读《CUDA专家手册》第二章硬件架构后的一个笔记
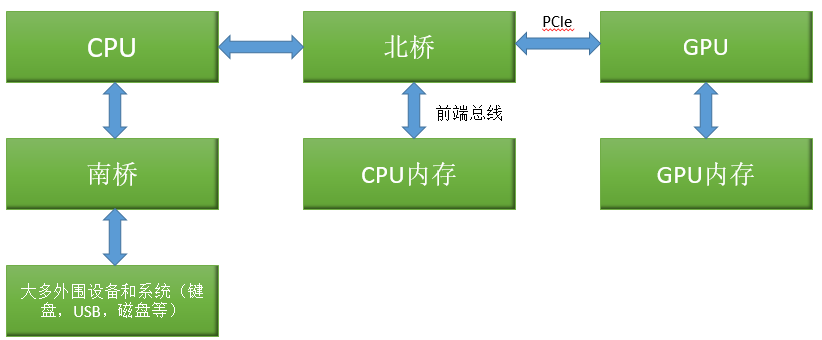
CPU配置
南桥:连接大多外围设备和系统,例如磁盘,鼠标,键盘灯。
北桥:图像总线和内存控制器。
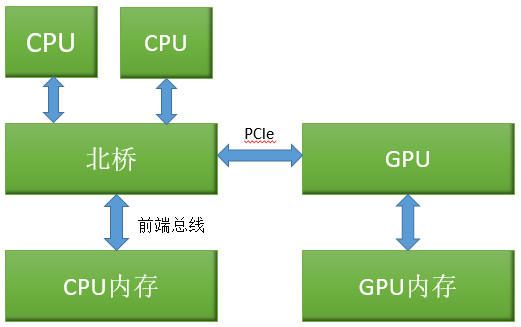
对称处理器蔟
对称处理器蔟系统共享同一个通往CPU内存的路径,不同CPU的内存访问性能相对一致。
非一致内存访问
北桥的内存控制器直接集成到CPU中,这种结构的变化,提高了CPU的内存。
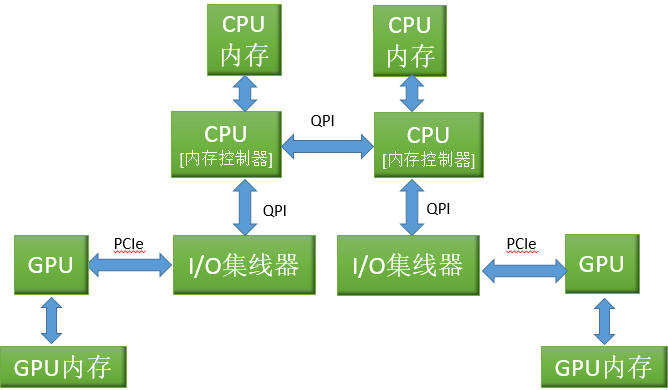
文中提到:由于PCIe宽带往往是整体应用性能的瓶颈,许多系统将使用独立的I/O集线器服务更多的PCIe总线。由于GPU需要巨大的宽带,DMA操作会降低HT/QPI为其主要对象服务的能力。和伪共享相比,对于CUDA应用程序而言,GPU的非本地内存复制操作对性能的影响有可能更为要命。
集成的PCIe
通过将I/O集线器集成到CPU中。集成的PCIe导致的结果是,不同CPU上的GPU之间无法执行点对点操作。而优点是,CPU缓存可以直接参与PCIe总线通信:DMA读请求可以直接读取缓存,并且GPU写入的数据会放入缓存中。
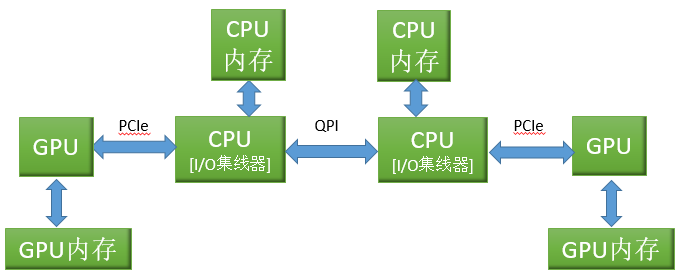
集成GPU
这里的“集成”的意思是“集成到芯片组”,先前只属于CPU的内存池现在可以被集成到芯片组的CPU和GPU所共享。
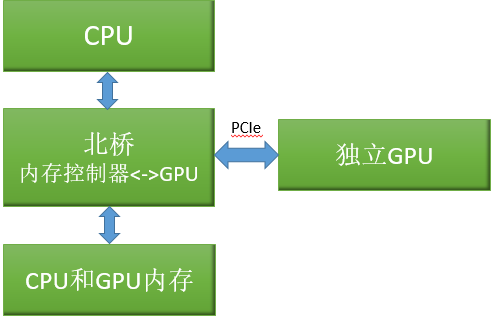
在这样的系统中,CUDA更倾向于在独立的GPU上运行,因为大多数的CUDA应用程序在独立的GPU上部署。
多GPU
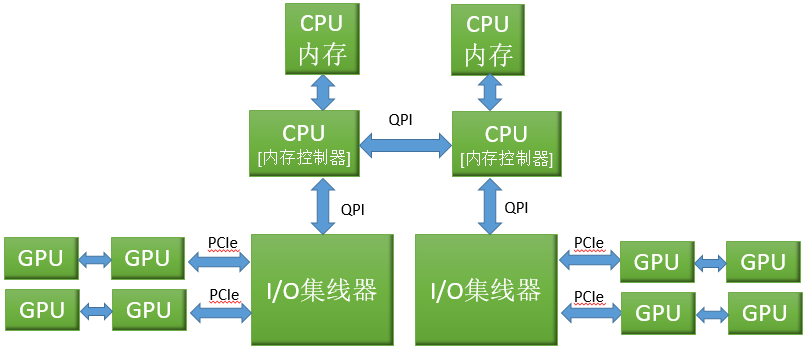
由于SLI导致多GPU表现为单个GPU,并且CUDA应用程序不能像图形应用程序那样透明地得到加速,所以CUDA开发人员一般不适用SLI。
CUDA中的地址空间
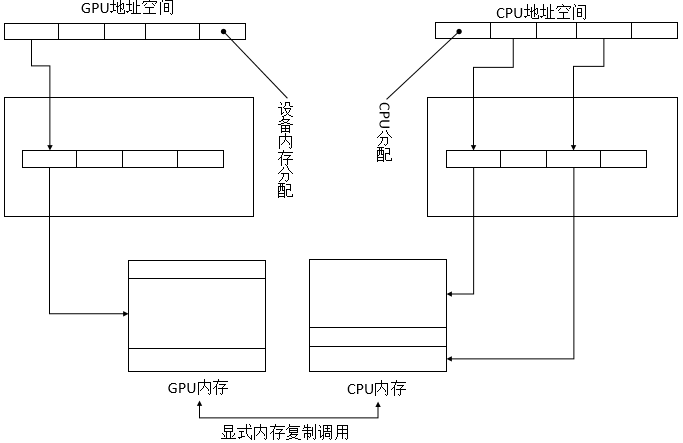
CPU和GPU的地址空间是分开的。CPU不能读取或写入GPU的设备内存,反过来,GPU也无法读取或写入CPU的内存。
虚拟寻址简史
指定内存位置的16位值称为地址,地址的计算和相应内存位置上的操作过程则统称为寻址。16位地址空间简图如下:
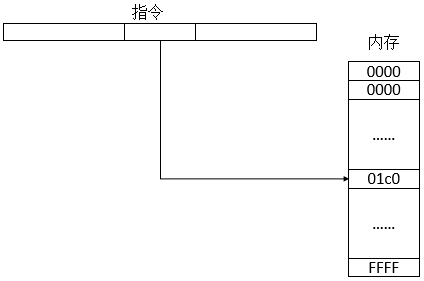
虚拟寻址能使一个连续的虚拟地址空间映射到物理内存并不连续的一些页。虚拟地址空间:
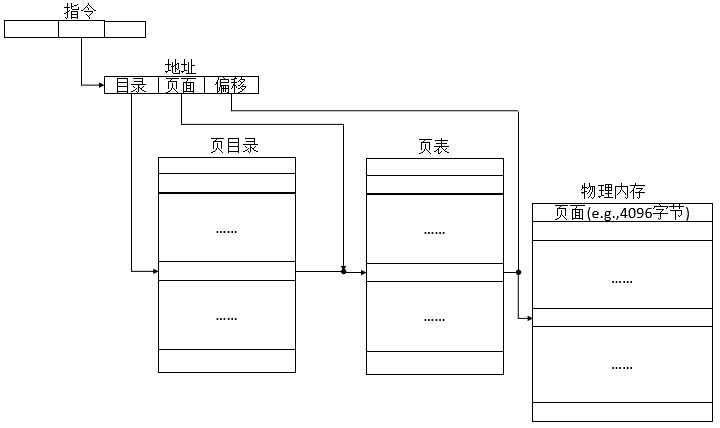
第一个索引指向页表的“页目录”,第二索引代表第一个索引约束下选择的页表。这种分层设计减少了页表所需的内存量,把不活跃的页表标记为非常驻状态并交换到磁盘上。
页表:操作系统为每个进程维护一个页表描述进程中页与帧的对应,逻辑地址分为了页号和偏移量两部分。一般情况下页表的大小位页的大小,页表中每条记录称为页表实体(PTE,page table entry)。页表可以是多级页表,受制于页大小的限制页表的大小不能大于一页(也不可能把巨大的页表存放在主存中),因此页表做多级处理,根页表始终在主存中,当次级页表不在主存中时从辅存加载对应的页表进主存。
操作系统使用虚拟地址硬件实现的功能:
- 缓式分配(lazy allocation):通过设置PTE运行分配无物理内存支持的页,从而可以分配大容量的内存。如果请求内存的应用程序碰巧访问这些页面,操作系统会立刻找到一个有物理内存的页面并解决这个故障。
- 请求式调页(demand paging):内存可以被复制到磁盘中并且页面被标记为“非常驻”。如果这样的内存再次被引用,硬件会产生“页面故障”信号,而且操作系统会将数据复制到一个物理页中并修正PTE指向该页,然后继续执行。如此,故障得以解决。
- 写时复制(copy-on-write):通过创建第二组映射到相同的物理页面的PTE,并将两组PTE标记为只读,虚拟内存得以“复制”。如果硬件捕获到一个试图写入这些页面的操作,操作系统将会复制该组页面到另一组物理页面,并再次标志这两组PTE为可写,然后恢复执行。如果应用程序只写入一个很小比例的“复制页面”,写时复制也就在性能上具有明显优势。
- 映射文件I/O(mapped file I/O):文件可以被映射到地址空间,并且通过访问文件可以解决页面故障。对进行随机访问相关文件的应用程序,通过委托操作系统中高度优化的VNM代码进行内存管理是非常有用的,特别是因为它是紧密耦合的大容量存储驱动程序。
不相交的地址空间
GPU并不支持请求式调页,所以被CUDA分配的每一个字节虚拟内存都必须对应一个字节的物理内存。
由于每个GPU有它自己的内存和地址转换硬件,GPU的地址空间和CUDA应用程序中的CPU地址空间是相互分开的。CPU和GPU都有自己的地址空间,用来映射各自设备自身的页表,两者的设备都要通过显式的内存复制命令来交换数据。
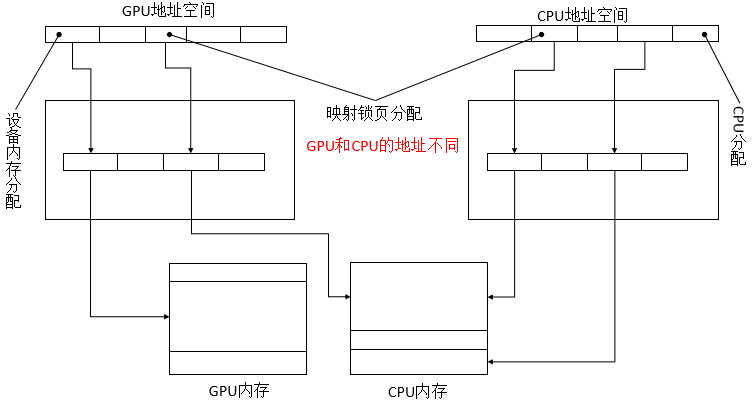
映射锁页内存
映射锁页内存是被映射到CUDA地址空间的锁页主存,在CUDA内核程序里可以直接对其读取或写入。CPU和GPU的页表更新了,以便CPU和GPU中拥有指向相同主机内存缓冲区的地址区间。由于地址空间不同,GPU指向该缓冲区的指针必须使用cuMemHostGetDevicePointre()或cudaHostGetDevicePointer()函数来查询。
可分享锁页内存
设置锁页内存“可分享”,会导致CUDA驱动把该内存映射给系统中的所有CPU,而不仅仅是当前上下文的GPU。
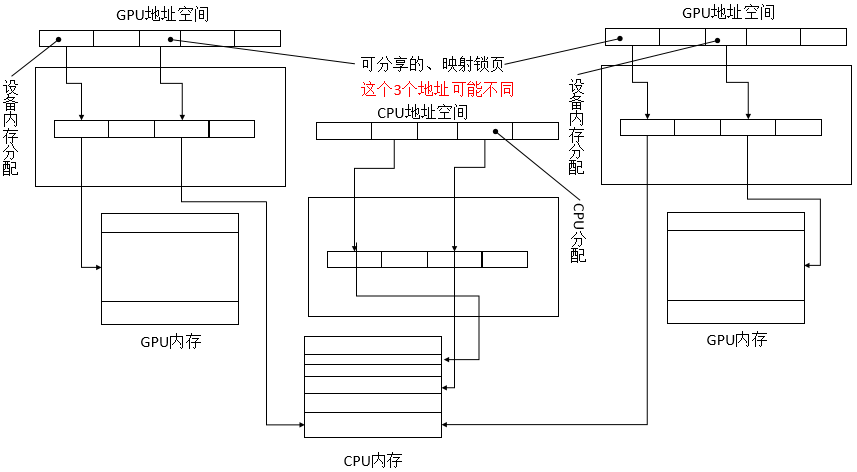
统一寻址
统一虚拟寻址(unified virtual addressing,UVA)。当UVA生效时,CUDA会从相同的虚拟地址空间CPU和GPU分配内存。CUDA驱动程序通过以下两步来完成上述任务:第一,初始化程序执行基于CPU地址空间的大型虚拟分配,该分配过程中可能会碰到无物理内存支持的情况;第二,将GPU分配的内存映射到上述地址空间。由于64位CPU支持48位虚拟地址空间,而CUDA GPU只支持40位,应用程序使用UVA时应确保CUDA被提前初始化,以保证CUDA所需的虚拟地址先于CPU代码的分配请求而被满足。
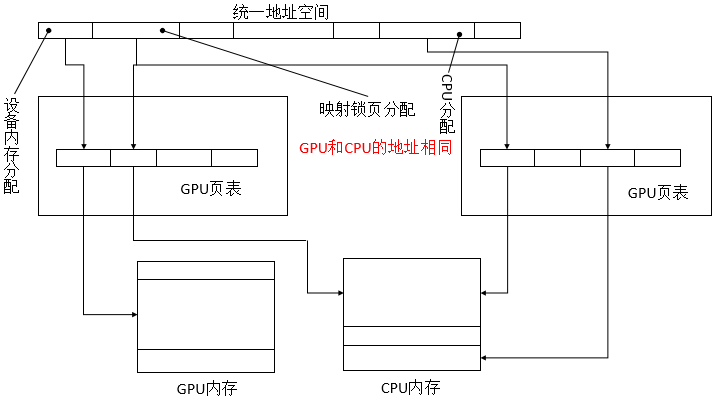
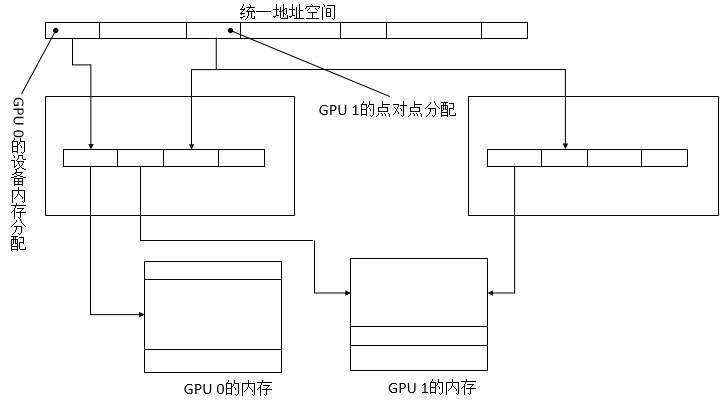
点对点映射
点对点可以是费米架构GPU读写另一个费米架构GPU的内存。点对点映射仅支持启用UVA的平台,并且只对连接到相同I/O集线器上的GPU有效。由于使用点对点映射时UVA始终是有效的,不同设备的地址空间范围不重叠,并且驱动程序(和运行时)可以从指针推断出所驻留的设备。
点对点内存寻址是非对称的。上图所示,对于1号GPU的内存分配,0号GPU是可见的,反之则不行。为了让GPU之间能够看到对方的内存,每个GPU必须显式地映射其它GPU的内存。
CPU/GPU交互
- 锁页主机内存:GPU可以直接访问的CPU内存。
- 命令缓冲区:由CUDA驱动程序写入命令,GPU从此缓冲区读取命令并控制其执行。
- CPU/GPU同步:指的是CPU如何跟踪GPU的进度。
锁页主机内存和命令缓冲区
GPU可以通过直接内存访问(direct memory access, DMA)方式来访问CPU中的锁页内存。锁页是操作系统常用的操作,可以使硬件外设直接访问CPU内存,从而避免过多的复制操作。“被锁定”的页面已被操作系统标记为不可操作系统换出的,所以设备驱动程序给这些外设编程时,可以使用页面的物理地址直接访问内存。而CPU仍然可以访问上述锁页内存,但是此内存是不能移动或换页到磁盘上的。
CPU/GPU并发
- 阿姆达尔法则
加速比=1(rs+rp/N)
其中, rs+rp=1 且 rs 代表的是串行部分比率。因为对研究CPU/GPU并发等小规模的性能场合时,这一公式形式似乎不太方便。所以,将其变形成如下公式:
加速比=N(N(1−rp)+rp) 错误处理
开发人员可以手动执行CPU/GPU同步作为辅助,具体通过调用cudaThreadSynchronize(), cuCtxSynchronize()等函数来完成。cudaFree()或cuMemFree()的函数调用也会导致CPU/GPU的同步。对于调试代码,如果难以通过同步操作来隔离故障,开发人员可以设置CUDA_LAUNCH_BLOCKING的环境变量,以迫使所有启动的内核同步。CPU/GPU同步
上下文范围的同步通过简单调用cudaThreadSynchronize(), cuCtxSynchronize()等函数来检查GPU的请求的最近同步值,并且一直等待,直到同步位置获得该值。
cuEventRecord()函数的作用是将一个命令加入队列使得一个新的同步值写入共享同步位置中,cuEventQuery()和cuEventSynchronize()则分别用于检查和等待这个事件的同步值。
通过指定CU_CTX_BLOCKING_SYNC到cuCtxCreate()或指定cudaDeviceBlockingSync到cudaSetDeviceFlags(),应用程序可以强制使用上下文范围的同步进入阻塞状态。然而,使用阻塞的CUDA事件(指定CU_EVENT_BLOCKING_SYNC到cuEventCreate()或指定cudaEventBlockingSync到cudaEventCreate())更可取,因为它们粒度更细且可以与任何类型的CUDA上下文进行无缝互操作。- 事件和时间戳
主机接口有一个机载高分辨计时器,它可以在写入一个32位的同步值时同时写一个时间戳。CUDA使用这个硬件实施实现CUDA事件的异步计时功能。
主机接口和内部GPU同步
foreach streamMemcpy device<-hostLaunch kernelMemcpy host<-deviceGPU间同步
在CUDA 4.0中,Nvidia能够在cudaStreamWaitEvent()和cuStreamWaitEvent()函数的形式中添加GPU之间的同步。这些API调用导致驱动程序为主机接口将等待命令插入当前GPU的命令缓冲区中,使得GPU一直等待,直到事件的给定同步值被写入为止。从CUDA 4.0开始,事件不一定会被等待中的同一个GPU用信号唤醒。流原先只能在单个GPU的硬件单元之间同步执行,现在已经提升到可以在GPU之间同步执行了。
GPU架构
- 特斯拉架构(Tesla)
- 费米架构(Fermi)
- 开普勒架构(Kepler)
从深度学习选择什么样的gpu来谈谈gpu的硬件架构
尾巴
似乎跟以前看《操作系统》一样苦难,抽象难记。说不定三天后,我就忘的一干二净。看的时候也是非常枯燥泛味,看第一遍的时候草草就得翻过去了。所以在第二遍,边写边看似乎是一个好的选择,虽然时间拉的长,但至少是看完了。
参考:
《GPGPU编程技术——从GLSL、CUDA到OpenCL》♥♥♥♥♥
《数字图像处理高级应用——基于MATLAB与CUDA的实现》♥♥♥
《基于CUDA的并行程序设计》♥♥♥
《CUDA专家手册》♥♥♥♥♥
《高性能CUDA应用设计与开发》♥♥♥♥