本文是秦春林《全局光照技术》的一些阅读笔记,所有图片都是书里的,我啥版权都没。。
一、CPU
1、冯诺依曼架构
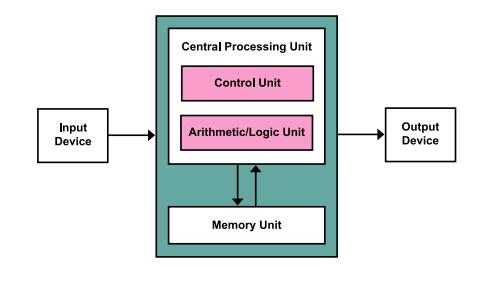
冯诺依曼架构中,数据总是存储在内存中,数据从内存传递到处理器的总时间可描述为一个固定和一个依赖数据大小的可变开销,其中固定开销被称为延迟,实际上指通信上发送一条空消息所需时间。因此不管处理器速度多快,计算机都内存传输速度这个,通常使用 缓存、预取、多线程 等方法克服该瓶颈。
1.1 缓存:
当处理器需要数据时,先向一级缓存中查询,若数据不在一级缓存,则一次查询二级三级缓存,L1、L2、L3速度依次变慢,空间依次变大
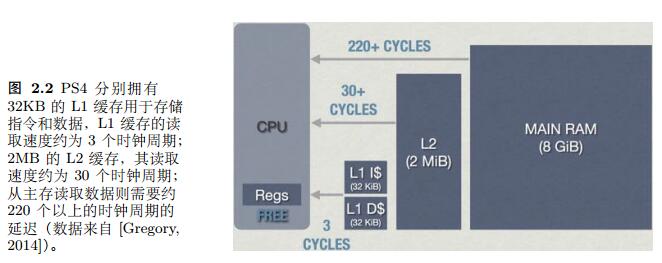
当处理器在缓存中而主存中读取到了需要指令或数据时,则称为缓存命中 cache hit,反之则称为 cache miss
1.2 预取:
预取技术是目的是为了提高缓存命中,集成在处理器内部,通常包括根据之前的数据访问模式,预先载入前数据临近对应范围内的数据,但预测不了跳跃的随机数据(如指针跳跃,因为只有处理到该指令的时候才知道其指令是追踪一指针),还有就是分支预测,通过过去的数据来预测后续的分支走向,因此对于条件分支语句,在编写时可能考虑指令的连续性,能使分支预测更加有效的工作
1.3 多线程:
1.3.1 指令级并行:
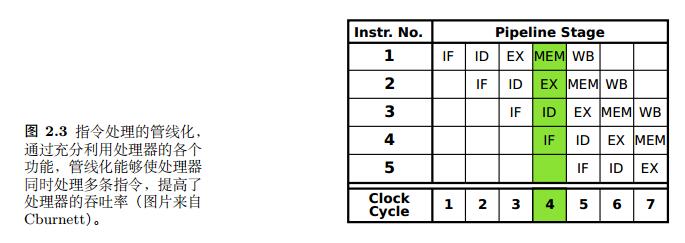
类似工厂流水线,但当指令出现依赖时,则会发生并行障碍,通常有 管线气泡、操作数前移、乱序执行 等方式来处理
1.3.2 线程级并行
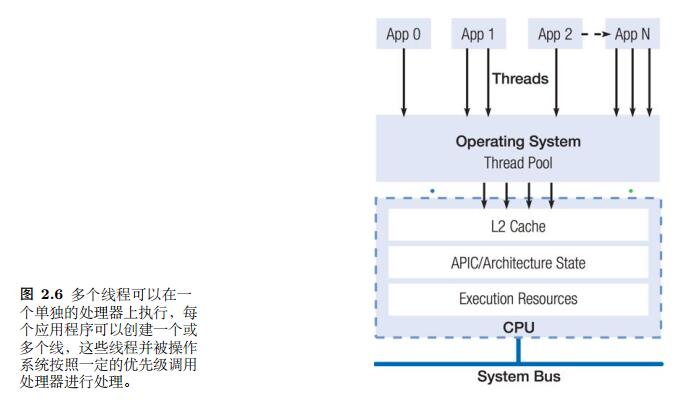
从早期的时分多线程技术(Temporal Multithreading, TMT)到现在的 同时多线程技术(Simultaneous Multithreading, SMT)
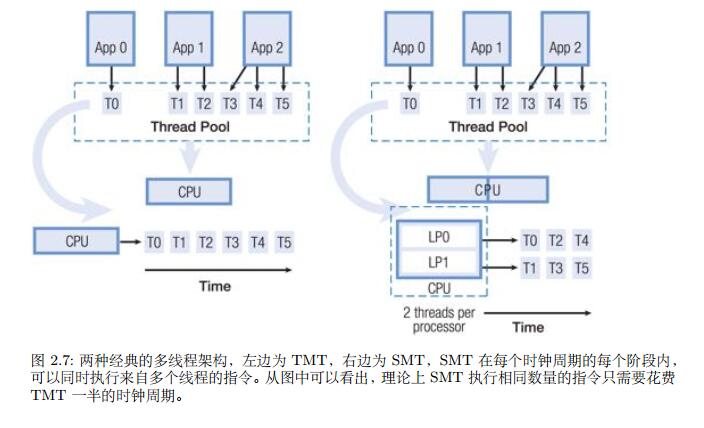
1.3.3 处理器级并行
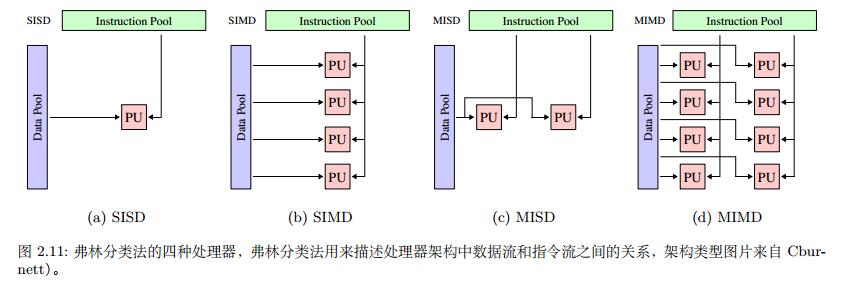
弗林分类法根据指令流和数据流将计算机分为四类
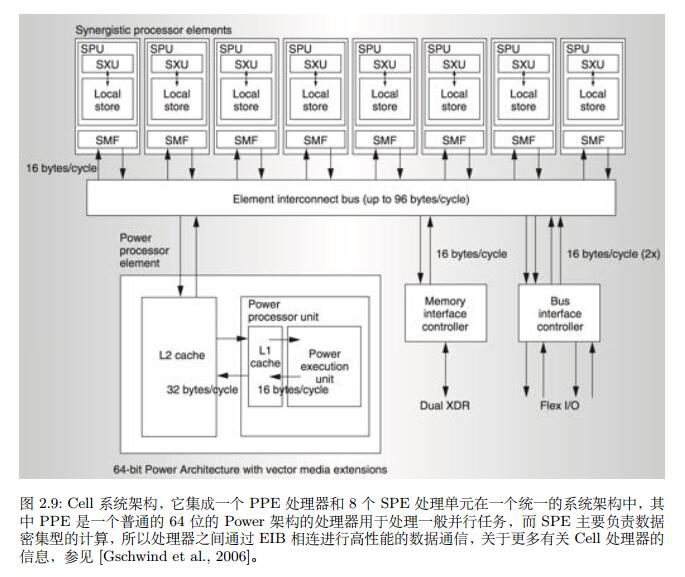
如图所示,其中PPE = Power Processor Element, SPE = Synergistic Processing Element, Cell处理器类似于现代GPU架构,每个SPE是完全 SIMD 的数据结构,只有一个128位的 SIMD 寄存器,用来存储各种数据类型,并且Cell处理器摒弃了多级缓存系统,而是通过 DMA 直接从主存中读取数据,因此,为了更高效的工作,需要将大量数据提前搬到SPE,并一次性做尽可能多的计算
而其他的CPU架构因为处理器间通信的需要,需要保持缓存一致性,并不适用于大规模并行计算。
二、GPU
2.1 内存结构
GPU架构与CPU最大的不同在内存系统上,GPU使用了一种称为硬件托管的内存模型,缓存自动根据局部性特征获取当前正在执行的指令附近的指令以及当前整在处理的数据附近的数据,并在指令将计算结果写入寄存器后自动将其写入到缓存系统中,并更新其他处理器的缓存,同时,GPU使用程序托管内存模型,即数据存放地点由程序员决定
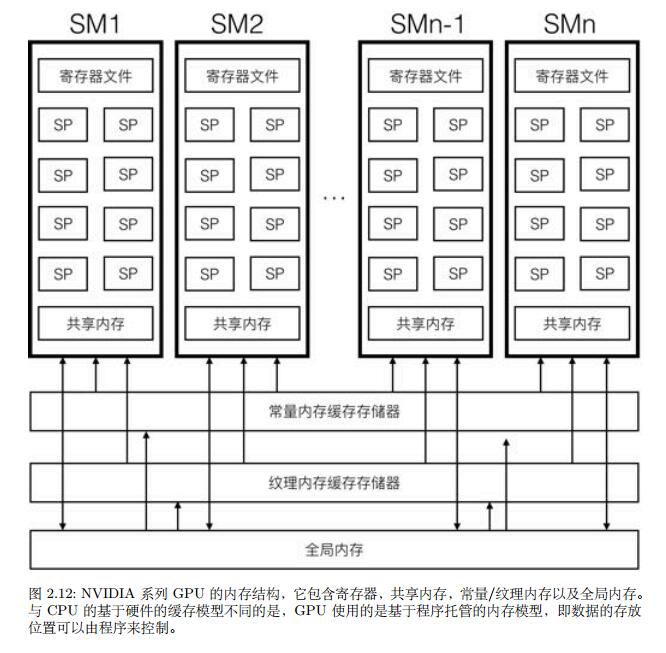
2.1.1 全局内存
GPU和CPU均可对全局内存进行操作,也是GPU处理器访问速度最慢的内存
2.1.2 常量/纹理内存
常量/纹理内存是全局内存中的一块虚拟地址,但其能提供高速缓存(如上图所示,通常是L1缓存)并且是只读内存,然而因为缓存系统都是利用的数据局部性原理,对于数据不集中、利用率不高或者随机访问的数据,则会经常出现 cache miss,尽量不要使用常量内存。对于纹理内存,GPU还提供了基于硬件的线性插值功能
2.1.3 共享内存
共享内存实际上是SM附近的L1高速缓存,为了提供更高的带宽,共享内存通常被分割为多个相同大小的储存体,这些储存提的内存可被同时使用,任何对共享内存的读写可被分配到 n 个储存体上同时进行,如 NVIDIA 的费米架构上有32个储存体,无论有多少线程发起操作,每个储存体每个周期只执行一次操作,并且储存提是各自独立的,因此无需顺序访问,但多个线程访问同一个储存体则会引起冲突,阻塞其他访问该储存体的线程

2.1.4 延迟隐藏
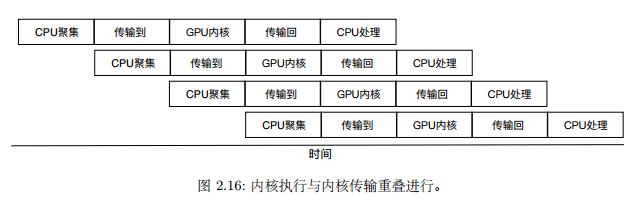
处理器读取全局内存时间高达400-600个时钟周期,因此在CPU中,通常通过缓存、多线程等的方式来隐藏延迟,而GPU则是将多线程发挥到极致,在GK210/110 架构中,虽然每个 SM 只有192个 SP,但可分配的线程多达2048个,即每个时钟周期有192个线程就进行计算的时候,剩下近2000个线程正在从内存中获取数据,相比于CPU,GPU拥有数量众多的寄存器,其致力于为每一个线程分配一个真实的寄存器,因此数据无需在切换线程的时候在寄存器和缓存中换进换出,一次上下文调换只需要重新执行另一组寄存器的数据,此外,利用该技术,还可以实现类似于指令集并行的从CPU到GPU内存传输的重叠:
2.1.5 全局内存的合并
当连续的线程向全局内存发起数据请求,且请求的地址连续,则请求会被合并成一次请求,但其请求的基础数据内存必须是对齐的
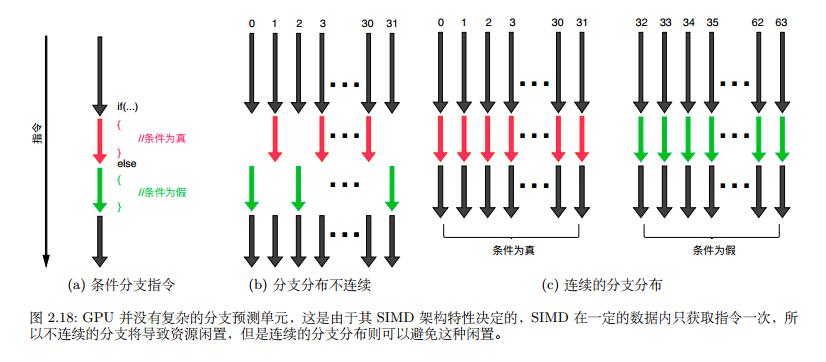
2.1.6 分支
GPU没有分支预测,因此会执行每一个分支并最终激活其中一个