import pandas as pd
import numpy as np
# 使用read_csv()方法进行读取
scenery_file_path = open(r'风景名胜区.csv')
scenery_data = pd.read_csv(scenery_file_path)
scenery_data
| 省份 | 名称 | 总面积(平方公里) | 游客量(万人次) | |
|---|---|---|---|---|
| 0 | 北京 | 十三陵 | 123.0 | 493.9 |
| 1 | 北京 | 八达岭 | 55.0 | 737.5 |
| 2 | 北京 | 石花洞 | 85.0 | 64.4 |
| 3 | 天津 | 盘山 | 106.0 | 228.3 |
| 4 | 河北 | 苍岩山 | 63.0 | 54.0 |
| ... | ... | ... | ... | ... |
| 225 | 新疆 | 库木塔格沙漠 | 1880.0 | 16.5 |
| 226 | 新疆 | 天山天池 | 548.0 | 185.7 |
| 227 | 新疆 | 赛里木湖 | 1301.0 | 55.0 |
| 228 | 新疆 | 罗布人村寨 | 134.0 | 60.1 |
| 229 | 新疆 | 博斯腾湖 | 3550.0 | 82.0 |
230 rows × 4 columns
# 计算‘总面积(平方公里)’的平均数,并保留一位小数
area = float("{:.1f}".format(
scenery_data['总面积(平方公里)'].mean()))
# 计算‘游客量(万人次)’平均数,并保留一位小数
tourist = float("{:.1}".format(
scenery_data['游客量(万人次)'].mean()))
# 将上述计算的平均值,使用fillna()函数,字典映射的形式进行填充
values = {"总面积(平方公里)":area,"游客量(万人次)":tourist}
scenery_data = scenery_data.fillna(value=values)
scenery_data.head
省份 名称 总面积(平方公里) 游客量(万人次)
0 北京 十三陵 123.0 493.9
1 北京 八达岭 55.0 737.5
2 北京 石花洞 85.0 64.4
3 天津 盘山 106.0 228.3
4 河北 苍岩山 63.0 54.0
.. .. ... ... ...
225 新疆 库木塔格沙漠 1880.0 16.5
226 新疆 天山天池 548.0 185.7
227 新疆 赛里木湖 1301.0 55.0
228 新疆 罗布人村寨 134.0 60.1
229 新疆 博斯腾湖 3550.0 82.0[230 rows x 4 columns]>
# 通过groupby()函数按“省份”一列拆分scenery_data
data = scenery_data.groupby("省份")
# 显示“河北”分组的数据
hebei_scenery = dict([x for x in data])['河北']
hebei_scenery
| 省份 | 名称 | 总面积(平方公里) | 游客量(万人次) | |
|---|---|---|---|---|
| 4 | 河北 | 苍岩山 | 63.0 | 54.0 |
| 5 | 河北 | 嶂石岩 | 120.0 | 7.8 |
| 6 | 河北 | 西柏坡-天桂山 | 256.0 | 780.0 |
| 7 | 河北 | 秦皇岛北戴河 | 366.0 | 823.0 |
| 8 | 河北 | 响堂山 | 41.0 | 10.0 |
| 9 | 河北 | 娲皇宫 | 132.0 | 365.1 |
| 10 | 河北 | 太行大峡谷 | 20.0 | 9.8 |
| 11 | 河北 | 崆山白云洞 | 161.0 | 86.0 |
| 12 | 河北 | 野三坡 | 499.0 | 275.0 |
| 13 | 河北 | 承德避暑山庄外八庙 | 564.0 | 135.0 |
from pyecharts import options as opts
from pyecharts.charts import Bar
# 内置主题类型可查看 pyecharts.globals.ThemeType
from pyecharts.globals import ThemeType
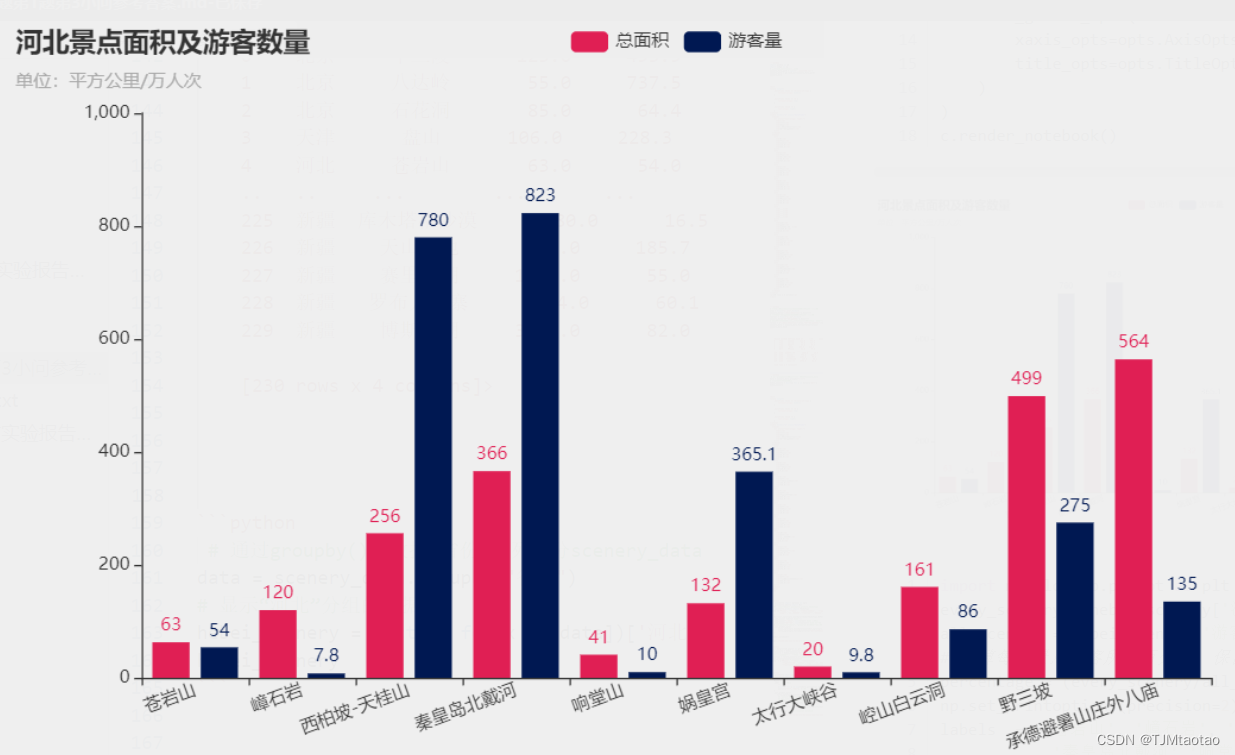
labels =['苍岩山', '嶂石岩', '西柏坡-天桂山', '秦皇岛北戴河','响堂山','娲皇宫','太行大峡谷','崆山白云洞','野三坡','承德避暑山庄外八庙']
c = (Bar(init_opts=opts.InitOpts(theme=ThemeType.ROMA)) #设置主题颜色.add_xaxis( labels) #x轴标签.add_yaxis("总面积", list(hebei_scenery['总面积(平方公里)'])) #y轴 总面积.add_yaxis("游客量", list(hebei_scenery['游客量(万人次)'])) #y轴 游客量#.set_colors(["white", "green"]) #设置条形的颜色.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=20)), #x轴的标签向x轴偏了20度title_opts=opts.TitleOpts(title="河北景点面积及游客数量", subtitle="单位:平方公里/万人次"),)
)
c.render_notebook()
import matplotlib.pyplot as plt
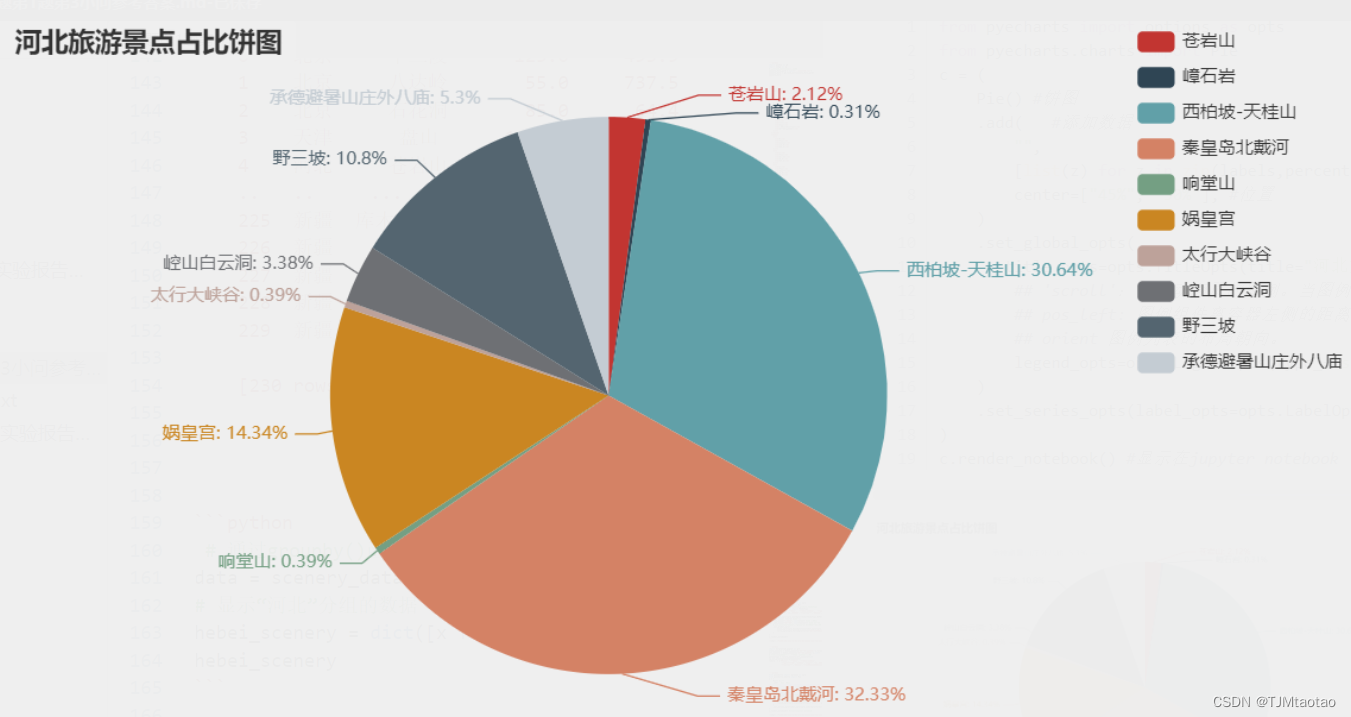
every_scenery = hebei_scenery['游客量(万人次)'].values
all_scenery = hebei_scenery['游客量(万人次)'].sum()
# 计算每个景点游客所占百分比 保留两位小数
percentage = (every_scenery/all_scenery)*100
np.set_printoptions(precision=2)
labels = ['苍岩山', '嶂石岩', '西柏坡-天桂山', '秦皇岛北戴河','响堂山','娲皇宫','太行大峡谷','崆山白云洞','野三坡','承德避暑山庄外八庙']
from pyecharts import options as opts
from pyecharts.charts import Pie
c = (Pie() #饼图.add( #添加数据"",[list(z) for z in zip(labels,percentage )],center=["45%", "50%"], #位置).set_global_opts(title_opts=opts.TitleOpts(title="河北旅游景点占比饼图"), #主标题## 'scroll':可滚动翻页的图例。当图例数量较多时可以使用。## pos_left: 图例组件离容器左侧的距离。## orient 图例列表的布局朝向。legend_opts=opts.LegendOpts(type_="scroll", pos_left="84%", orient="vertical"), #图例配置项,).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) #数字项名称和百分比
)
c.render_notebook() #显示在jupyter notebook
数据集链接







