DACS
- 介绍
- 方法
- Naive Mixing
- DACS
- ClassMix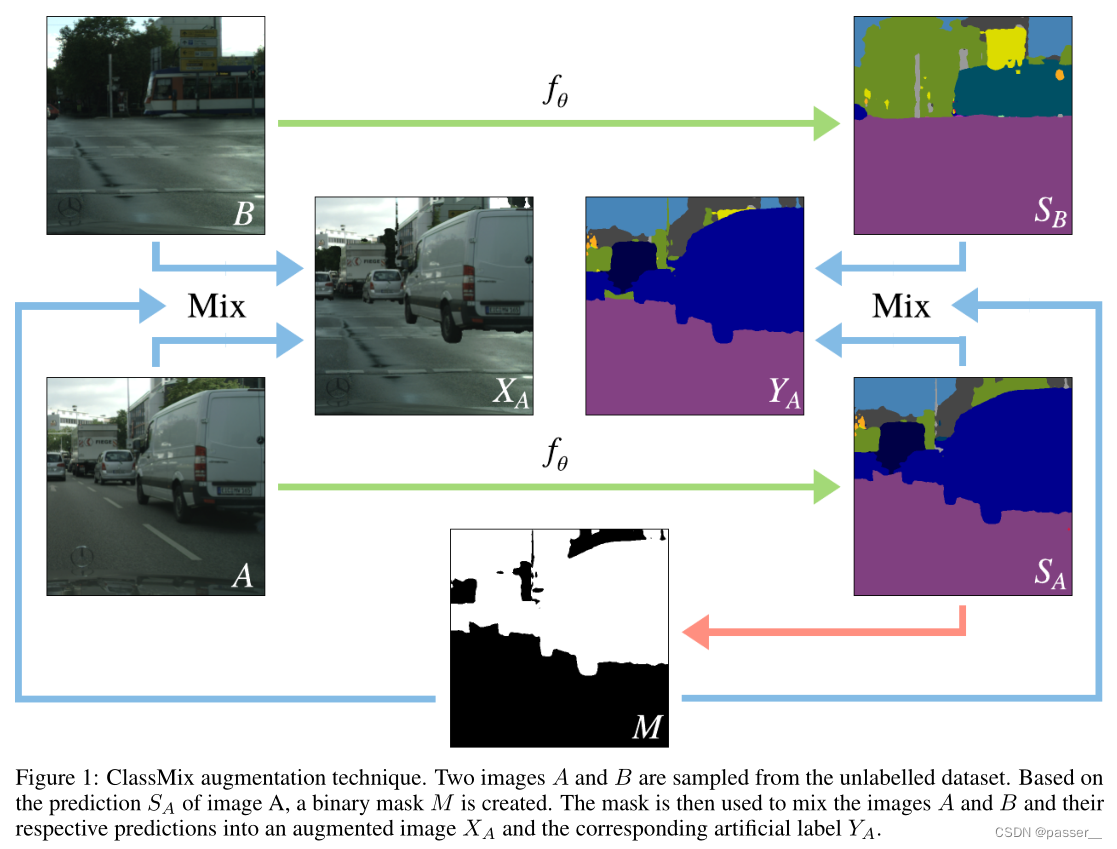
- 算法流程
- 实验结果
- 反思
介绍
近年来,基于卷积神经网络的语义分割模型在众多应用中表现出了显著的性能。然而当应用于新的领域时,这些模型通常不能很好地泛化,特别是从合成数据到真实数据时。本文讨论了无监督域适应(UDA)的问题,即对来自一个源域的标记数据进行训练,同时从目标域的无标记数据进行学习。现有的方法通过对这些无标签图像进行伪标签训练取得了成功。人们提出了多种技术来降低由域转移引起的低质量伪标签的情况,并取得了不同程度的成功。我们提出了DACS:通过跨域混合采样的域适应,它将来自两个域的图像与相应的标签和伪标签混合在一起。除了标签数据本身外,这些混合样本还会被训练。
我们注意到,在现有的纠正错误伪标签的方法中,目标域中的某些图像会过度采样,图像中的低置信度像素会被过滤掉。许多低置信度像素与语义边界上的预测对齐,从而导致那里的训练信号减弱。传统的直接使用混合的方法会导致一些类进行合并。
总结来说:DACS提出了三个创新点。
①引入了一种新的算法,将目标域的图片和源域中的图片进行混合,创造出来一个新的、高扰动的样本
②通过实验证明跨域的图像混合可以很大程度上解决类合并的问题
③在GTA5—>City 取得了sota 的水准
方法
Naive Mixing

对于朴素的混合方法就是拿目标域的两张图进行混合,然后生成Xm,然后获得其对应的伪标签Ym,然后将源域中的Xs,Ys,和在目标域混合生成的图片再放到一块训练。
DACS
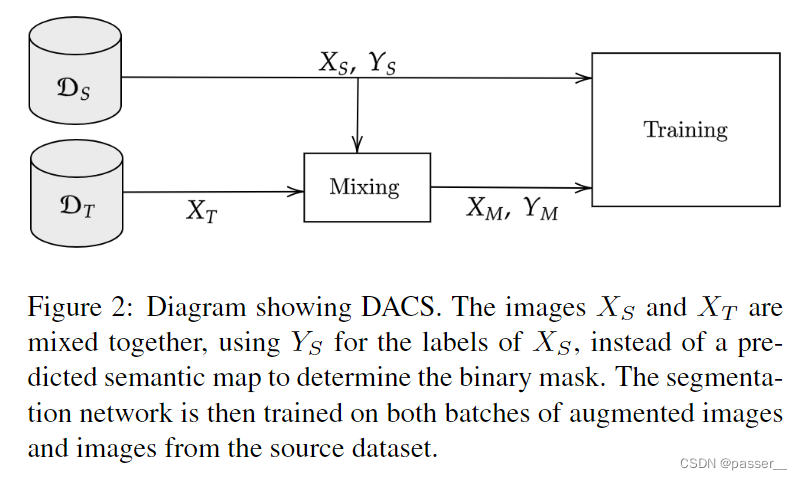
DACS也是基于上述的混合的思想,不过使用的混合图片一张来自源域一张来自目标域。首先使用网络对目标域的数据生成伪标签,对于混合的方式采用的方式ClassMix,将源域Xs中的图像随机一半类抠出来粘贴到目标域的图片上,然后生成对应的伪标签,此时已知源域图片Xs和对应的标签Ys和混合图片Xm及其对应的标签Ym。
ClassMix
如图所示:获取的B,Sb,A,Sa,通过Sa获得动态的二进制掩码M,随机将A中的一半类粘贴到B得到一个新的混合图Xa,然后将Sa,SB和M获得对应的特征图Ya。
算法流程

和方法里面的DACS讲解的差不多,先获取源域中的图标和对应的标签,然后获取目标域的图片,通过训练的网络获取对应的伪标签,然后将Xs和Xt通过ClassMix的方式混合,同时将标签也进行混合。然后将生成Xm和源域中的Xs利用网络生成对应的标签,然后去计算对应的交叉熵损失函数,执行反向传播和梯度下降。对于其他的参数在论文中都已经详细给了就不多介绍了。
实验结果
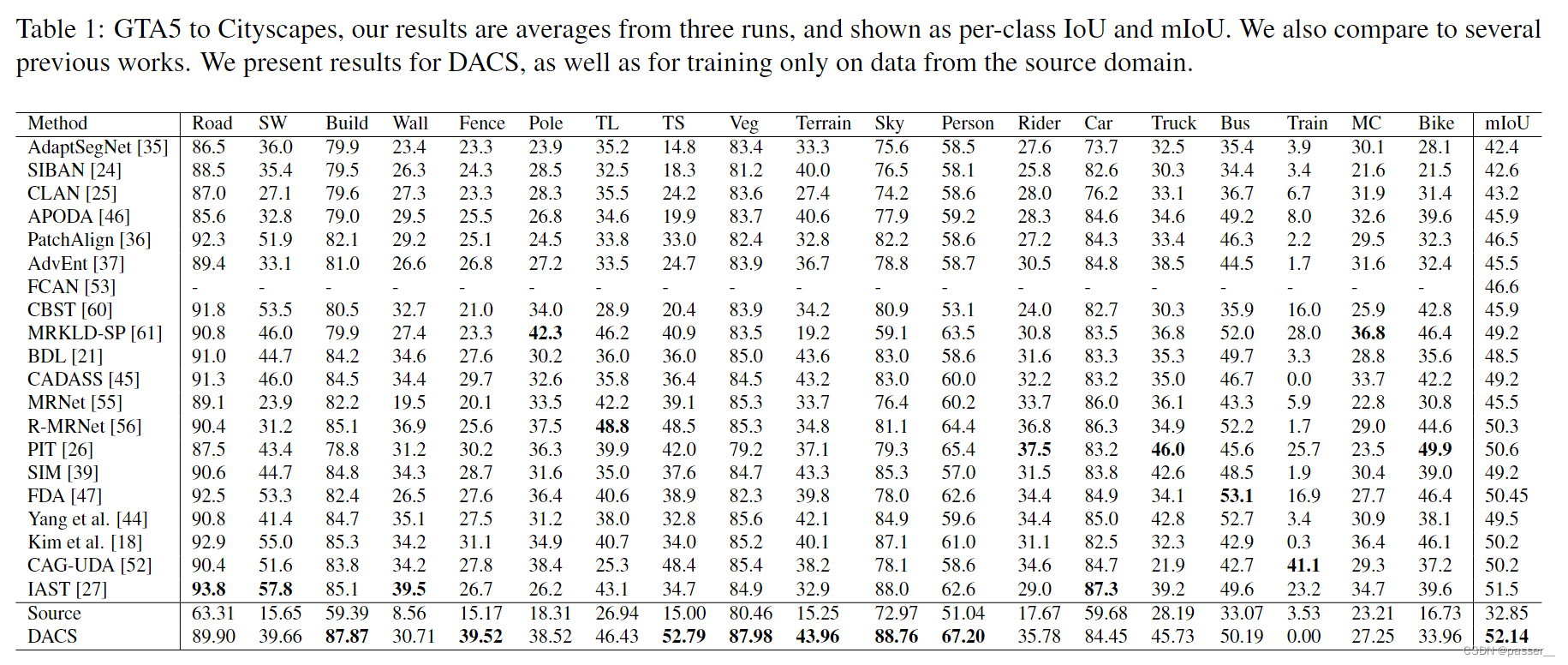
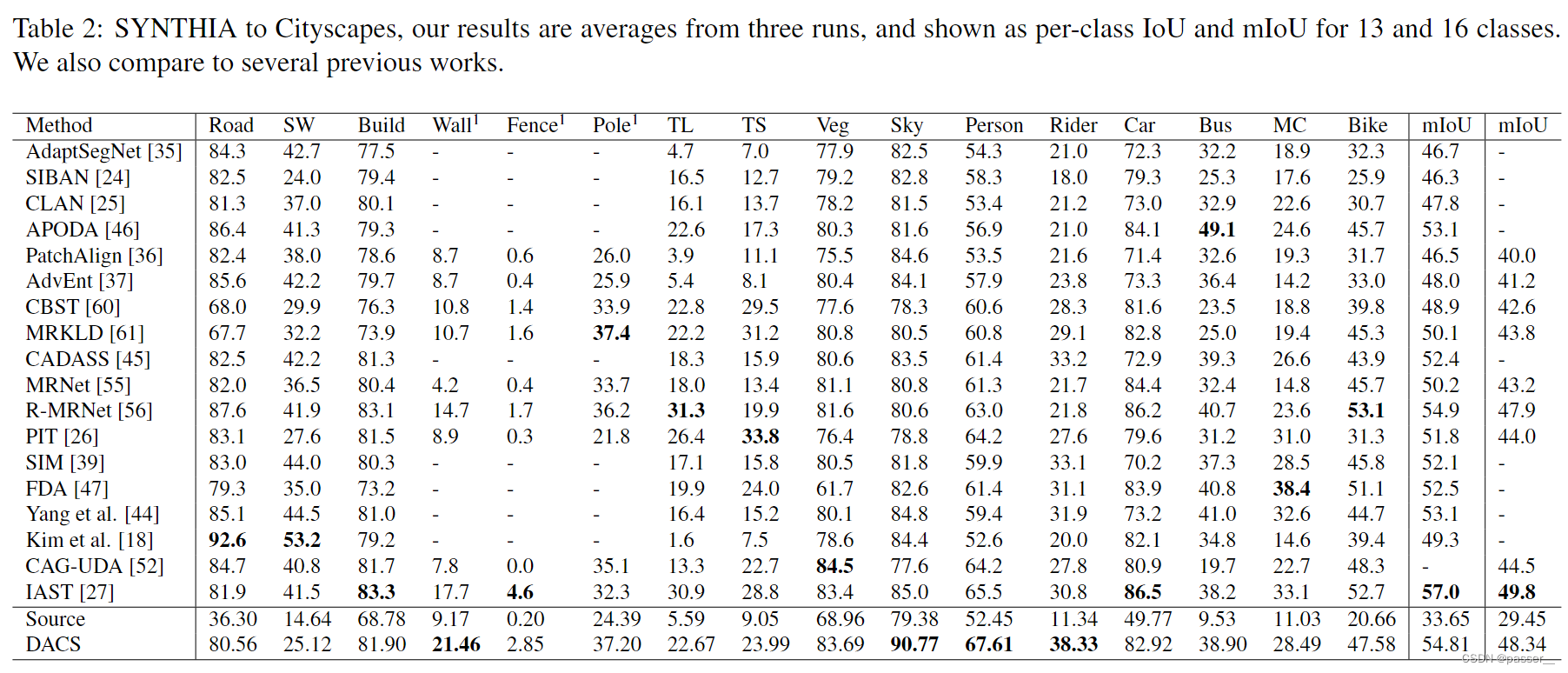
上两张图分别是在GTA5和SYNTHIA下的Iou和MIou。可以看出来虽然不是每一项都是sota,但是很多项都是top1。

为了进一步评估DACS,并更好地理解类合并问题的根源,进行了额外的实验,并在上图中展示。结果显示了论文3.1节中解释的朴素混合,以及仅使用伪标签而不使用任何混合和使用不同的混合策略。从上图可以看出,DACS的性能明显强于朴素混合。如论文3.1节所述,最重要的原因是朴素混合合并了几个类,这极大地影响了整体性能。从表中每个班级的借据可以清楚地看出,其中七个班级的朴素混合分数低于1%。
反思
老文章,但是没搜到别人写的学习笔记,就单纯按照自己所理解和代码中的写了,有不对的地方望指正。论文中提到了ClassMix,但是没有提到那个二进制掩码的地方,我去翻了翻代码发现确实是有相关的步骤,而且最后实验就跟最后论文说的一样用了2个源域的和2个目标域的图进行跑的。(等考完试看完代码再补充更新)
代码链接:https://github.com/vikolss/DACS/blob/master/trainUDA.py