目录
一、 数据结构的研究内容
二、基本概念和术语
2.1 - 数据、数据元素、数据项和数据对象
2.2 - 数据结构
2.2.1 - 逻辑结构
2.2.2 - 存储结构
2.3 - 数据类型和抽象数据类型
三、抽象数据类型的表现与实现
四、算法和算法分析
4.1 - 算法的定义及特性
4.2 - 评价算法优劣的基本标准
4.3 - 算法的时间复杂度
4.3.1 - 问题规模和语句频度
4.3.2 - 算法的时间复杂度定义
4.3.3 - 算法的时间复杂度分析举例
4.3.4 - 最好、最坏和平均时间复杂度
4.4 - 算法的空间复杂度
参考资料:数据结构(C 语言版 | 第二版) - 严蔚敏 李冬梅 吴伟民 编著
一、 数据结构的研究内容
早期的计算机主要用于数值计算,现在,计算机主要用于非数值计算,包括处理字符、表格和图像等具有一定结构的数据。这些数据内容存在着某种联系,只有分清楚数据的内在联系、合理地组织数据,才能对它们进行有效地处理,设计出高效的算法。如何合理地组织数据、高效地处理数据,这就是"数据结构"主要研究的问题。
-
计算机主要用于数值计算时,一般要经过如下几个步骤:
-
首先从具体问题抽象出数学模型。
寻求数学模型的实质是分析问题,从中提取操作的对象,并找出这些操作对象之间的关系,然后用数学语言加以描述,即建立相应的数学方操。
-
然后设计一个解此数学模型的算法。
求解这些数学方程的算法是计算数学研究的范畴,如高斯消元法、差分法、有限元法等算法。
-
最后编写程序,进行测试、调试、直到解决问题。
-
-
数据结构主要研究非数值计算问题,非数值计算问题的数学模型不再是数学方程,而是诸如线性表、树和图的数据结构。因此简单来说,数据结构是一门研究非数值计算程序中的操作对象,以及这些对象之间的关系和操作的学科。
下面通过三个实例加以说明:
-
例 1 - 学生学籍管理系统:
表 1.1 学生基本信息表:
学号 姓名 性别 籍贯 专业 060214201 杨阳 男 安徽 计算机科学与技术 060214202 薛林 男 福建 计算机科学与技术 060214215 王诗萌 女 吉林 计算机科学与技术 060214216 冯子晗 女 山东 计算机科学与技术 操作对象:每个学生的基本信息。
操作对象之间的关系:一对一的线性关系。
操作:查找、插入和删除等。
数据结构:线性表。
-
例 2 - 人机对弈问题:
图 1.1 井字棋的对弈树:

操作对象:各种棋盘格局。
操作对象之间的关系:一对多的层次关系。
操作:查找、插入和删除等。
数据结构:树。
-
例 3 - 最短路径问题:
图 1.2 最短路径问题:

操作对象:图中的顶点。
操作对象之间的关系:多对多的网状关系。
操作:查找、插入和删除等。
数据结构:图。
-
二、基本概念和术语
2.1 - 数据、数据元素、数据项和数据对象
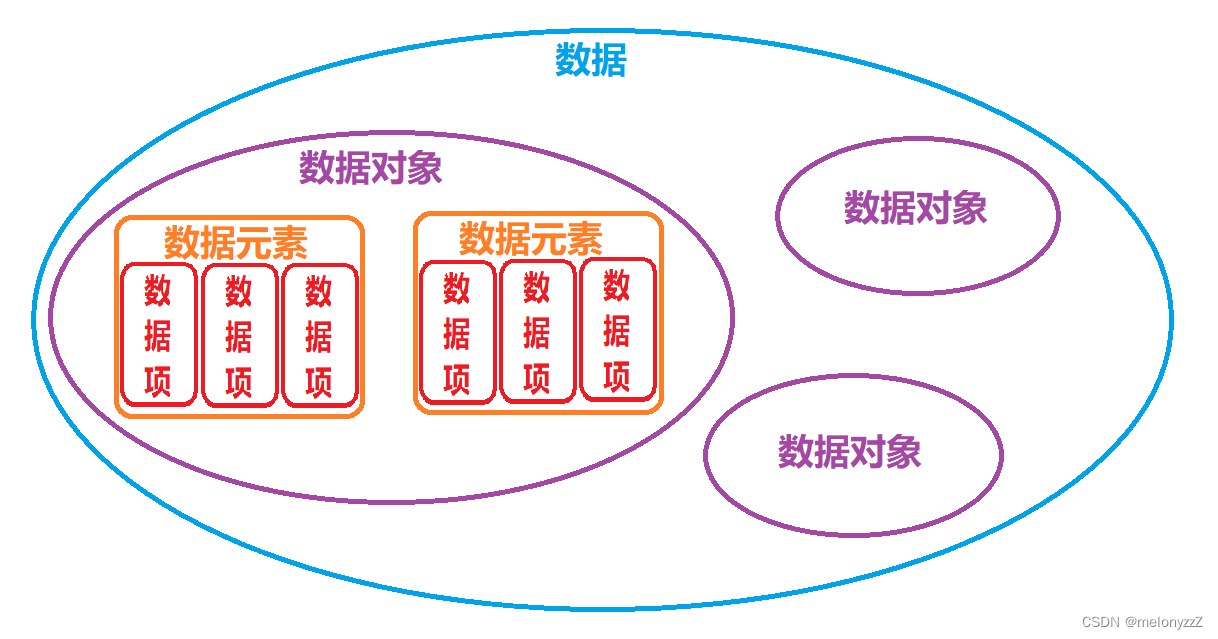
数据(Data)是客观事物的符号表示,是所有能输入到计算机中被计算机程序处理的符号的总称。
数据元素(Data Element)是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。在有些情况下,数据元素也称为元素、记录等。数据元素用于完整地描述一个对象,如示例中的一名学生记录、树中棋盘的一个格局(状态),以及图中的一个顶点等。
数据项(Data Item)是组成数据元素的、有独立含义的、不可分割的最小单位。
数据对象(Data Object)是性质相同的数据元素的集合,是数据的一个子集。
2.2 - 数据结构
数据结构(Data Structure)是相互之间存在一种或多种特定关系的数据元素的集合。
同样的数据元素,可以组成不同的数据结构;不同的数据元素,可以组成相同的数据结构。
数据结构包括逻辑结构和存储结构两个层次。
2.2.1 - 逻辑结构
数据的逻辑结构是从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
根据数据元素之间关系的不同特性,通常有四类基本逻辑结构,如下图所示,它们的复杂程度依次递进。

集合结构:数据元素之间除了"属于同一集合"的关系外,别无其他关系。
其中集合结构、树结构和图结构都属于非线性结构。
2.2.2 - 存储结构
数据对象在计算机中的存储表示称为数据的存储结构,也称为物理结构。把数据对象存储到计算机时,通常要求既要存储各数据元素的数据,又要存储数据元素之间的逻辑关系,数据元素在计算机内用一个结点(node)来表示。
逻辑结构是具体问题抽象出来的数学模型,存储结构是逻辑结构在计算机中的存储表示。
数据元素在计算机中有两种基本的存储结构,分别是顺序存储结构和链式存储结构。
-
顺序存储结构是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系,通常借助程序设计语言中的数组类型来描述。
-
顺序存储结构要求所有的元素依次存放在一片连续的存储空间中,而链式存储结构,无需占用一整块存储空间,但为了表示结点之间的关系,需要给每个结点附加指针字段,用于存放后续元素的存储地址。所以链式存储结构通常借助于程序设计语言的指针类型来描述。
2.3 - 数据类型和抽象数据类型
数据类型(Data Type)是高级程序设计语言中的一个基本概念,前面提到过顺序存储结构可以借助程序设计语言的数组类型描述,链式存储结构可以借助指针类型描述,所以数据类型和数据结构的概念密切相关。
一方面,在程序设计语言中,每一个数据都属于某种数据类型。类型明显或隐含地规定了数据的取值范围、存储方式以及允许进行的运算,数据类型是一个值的集合和定义在这个值集上的一组操作的总称。C 语言除了提供整型、实型、字符型等基本类型数据,还允许用户自定义各种类型数据,例如数组、结构体和指针等。
抽象数据类型(Abstract Data Type,ADT)一般指用户定义的、表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称,具体包括三部分:数据对象、数据对象上关系的集合,以及对数据对象的基本操作的集合。
三、抽象数据类型的表现与实现
抽象数据类型的概念与面向对象方法的思想是一致的。抽象数据类型独立于具体实现,将数据和操作封装在一起,使得用户程序只能通过抽象数据类型定义的某些操作来访问其中的数据,从而实现了信息隐藏。
四、算法和算法分析
程序 = 数据结构 + 算法
4.1 - 算法的定义及特性
算法(Algorithm)是为了解决某类问题而规定的一个有限长的操作序列。
一个算法必须满足以下五个重要特性:
-
有穷性:一个算法必须总是在执行有穷步后结束,且每一步都必须在有穷时间内完成。
-
确定性。
-
可行性。
-
输入:一个算法有零个或多个输入。
-
输出:一个算法有一个或多个输出。
4.2 - 评价算法优劣的基本标准
一个算法的优劣应该从以下几个方面来评价:
-
正确性。
-
可读性。
-
健壮性(鲁棒性,Robustness):当输入的数据非法时,好的算法能适当地做出正确反应或进行相应处理,而不会产生一些莫名其妙的输出结果。
-
高效性:高效性包括时间和空间两个方面。时间高效是指算法设计合理,执行效率高,可以用时间复杂度来度量;空间高效是指算法占用存储容量合理,可以用空间复杂度来度量。时间复杂度和空间复杂度是衡量算法的两个主要指标。
4.3 - 算法的时间复杂度
如何评估算法时间开销?
-
让算法先运行,事后统计运算时间。
不过这种方法的缺陷很显然:
-
统计结果和机器性能有关。
-
统计结果和编程语言有关,越高级的语言执行效率越低。
-
统计结果和编译程序产生的机器指令质量有关。
-
有些算法是不能事后再统计的,比如导弹控制算法。
-
-
因此我们通常采用事前分析估算法,通过计算算法的渐进时间复杂度来衡量算法的效率。
4.3.1 - 问题规模和语句频度
不考虑计算机的软硬件等环境因素,影响算法时间代价的最主要因素是问题规模。问题规模是算法求解问题输入量的多少,是问题大小的本质表示,一般用整数 n 表示。问题规模 n 对不同的问题含义不同。显然 n 越大算法的执行时间越长。
一个算法的执行时间大致等于所有语句执行时间的总和,而语句的执行时间则为该条语句的重复执行次数和执行一次所需时间的乘积。
一个语句的重复执行次数称作语句频度(Frequency Count)。
由于语句的执行要由源程序经编译程序翻译成目标代码,目标代码经配装再执行,因此语句执行一次实际所需的具体时间是与机器的软、硬件环境(如机器速度、编译程序质量等)密切相关的。所以,所谓的算法分析并非精确统计算法实际执行所需时间,而是针对算法中语句的执行次数做出估计,从中得到算法执行时间的信息。
设每条语句执行一次所需的时间均是单位时间,则一个算法的执行时间可用该算法中所有语句频度之和来度量。
例 - 求 1 + 2 + ... + n:
sum = 0; // 语句频度为 1
for (int i = 1; i <= n; ++i) // 语句频度为 n + 1,当 i == n + 1 时,还要判断一次
{sum += i; // 语句频度为 n
}该算法中所有语句频度之和是一个关于 n 的函数,用 f(n) 表示之。换句话说,上例算法的执行时间与 f(n) 成正比。
f(n) = 2n + 2。
4.3.2 - 算法的时间复杂度定义
对于简单的算法,可用直接计算出算法中所有语句的频度,但是对于稍微复杂一些的算法,则通常是比较困难的,即便能够给出,也可能是一个非常复杂的函数。因此,为了客观地反映一个算法的执行时间,可以只用算法中的"基本语句"的执行次数来度量算法的工作量。
所谓"基本语句"指的是算法中重复执行次数和算法的执行时间成正比的语句,它对算法运行时间的贡献最大。
通常,算法的执行时间是随问题规模增长而增长的,因此对算法的评价通常只需考虑其随问题规模增长的趋势。这种情况下,我们只需要考虑当问题规模充分大时,算法中基本语句的执行次数在渐进意义下的阶。如上面例题中求 1 + 2 + ... + n 的算法,当 n 趋向无穷大时,显然有:,即当 n 充分大时,f(n) 和 n 之比是一个不等于零的常数。即 f(n) 和 n 是同阶的,或者说 f(n) 和 n 的数量级(Order of Magnitude)相同。在这里,我们用 "O" 来表示数量级,记作 T(n) = O(f(n)) = O(n)。
由此我们可以给出下述算法时间复杂度的定义:
一般情况下,算法中基本语句重复执行的次数是问题规模 n 的某个函数 f(n),算法的时间度量记作 T(n) = O(f(n)),它表示随问题规模 n 的增大,算法执行时间的增长率和 f(n) 的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度(Time Complexity)。
4.3.3 - 算法的时间复杂度分析举例
分析算法时间复杂度的基本方法为:找出所有语句中语句频度最大的那条语句作为基本语句,计算基本语句的频度得到问题规模的某个函数 f(n),取其数量级用符号 "O" 表示即可。具体计算数量级时,可以遵循以下定理:
上述定理说明,在计算算法时间复杂度时,可以忽略所有低次幂项和最高次幂的系数,这样可以简化算法分析,也体现出了增长率的含义。
下面举例说明如何求非递归算法的时间复杂度。
-
例 1:
void func1(int n) {int cnt = 0;for (int i = 0; i < 100; ++i){++cnt;}printf("%d\n", cnt); }如果算法的执行时间不随问题规模 n 的增加而增长,算法中语句频度就是某个常数,即便这个常数再大,算法的时间复杂度都是 O(1)。
-
例 2:
void func2(int n) {int cnt = 0;for (int i = 0; i < 2 * n; ++i){++cnt;}int m = 10;while (m--){++cnt;}printf("%d\n", cnt); }时间复杂度为 O(n)。
-
例 3:
void func3(int n, int m) {int cnt = 0;for (int i = 0; i < n; ++i){++cnt;}for (int i = 0; i < m; ++i){++cnt;}printf("%d\n", cnt); }时间复杂度为 O(n + m)。
若提示 n 远大于 m,或者 m 远大于 n,时间复杂度则为 O(n) 或 O(m)。
-
例 4:
void func4(int n) {int cnt = 0;for (int i = 0; i < n; ++i){for (int j = 0; j < n; ++j){++cnt;}}for (int i = 0; i < 2 * n; ++i){++cnt;}int m = 10;while (m--){++cnt;}printf("%d\n", cnt); }时间复杂度为 O(n^2)。
若算法可用递归方法描述,则算法的时间复杂度通常可使用递归方程表示,此时将涉及递归方程求解问题。
-
例 1 - 计算阶乘递归算法的时间复杂度:
long long factorial(size_t n) {if (n == 0 || n == 1)return 1;return n * factorial(n - 1); }因为 n 的阶乘仅比 n - 1 的阶乘多一次乘法运算,即 factorial = n * factorial(n - 1),那么有:f(n) = 1 + f(n - 1) = 2 + f(n - 2) = ... ... = n - 1 + f(1) = n,所以阶乘递归算法的时间复杂度为 O(n)。
-
例 2 - 计算斐波那契递归算法的时间复杂度:
long long fibonacci(size_t n) {if (n == 0)return 0;else if (n == 1 || n == 2)return 1;elsereturn fibonacci(n - 1) + fibonacci(n - 2); }分析(以 fib(6) 为例):
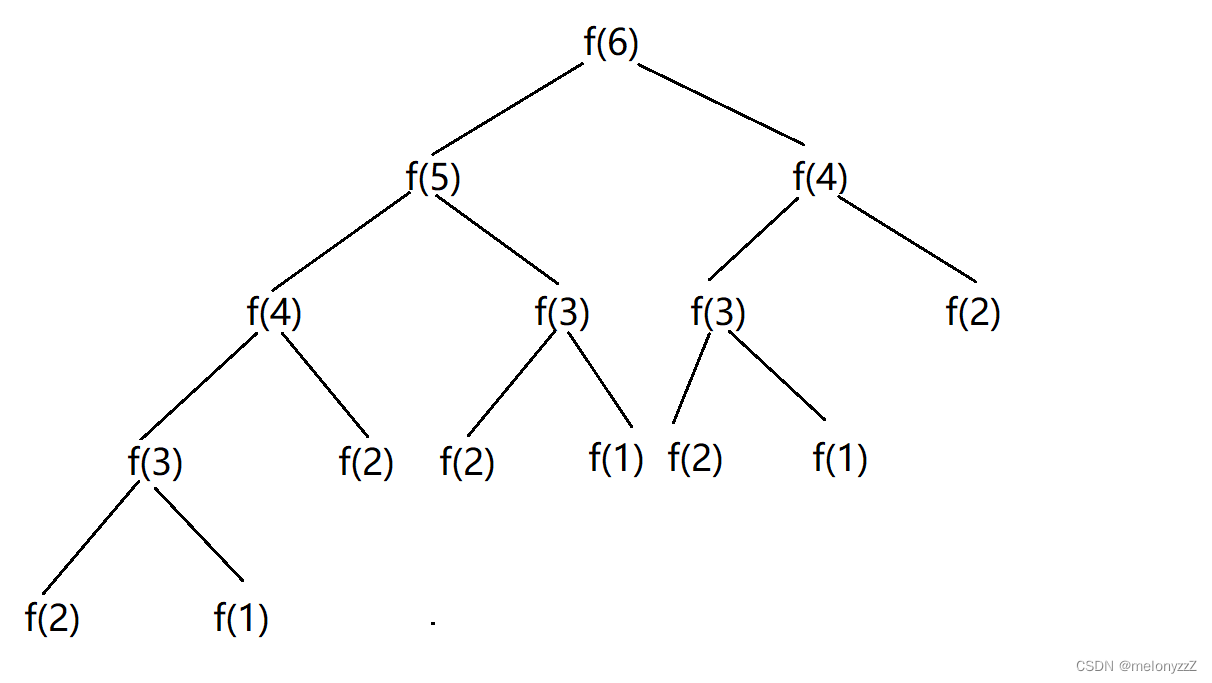
因此斐波那契递归算法的时间复杂度为 O(2^n)。
4.3.4 - 最好、最坏和平均时间复杂度
对于某些问题的算法,其基本语句的频度不仅仅与问题的规模相关,还依赖于其他因素。
下面通过一个示例说明:
const char* my_strchr(const char* str, int character)
{while (*str != '\0'){if (*str == character){return str;}str++;}return NULL;
}容易看出,此算法中 if 语句的频度不仅与问题规模 n 有关,还与
str和character有关。假设
str指向的字符串中必定存在字符character,则查找必定成功,且 if 语句的频度将由字符第一次出现在字符串中的位置决定。此例说明,算法的时间复杂度不仅与问题的规模有关,还与问题的其他因素有关。再如某些排序的算法,其执行时间与待排序记录的初始状态有关。因此,有时会对算法有最好、最坏以及平均时间复杂度的评价。
称算法在最好情况下的时间复杂度为最好时间复杂度,指的是算法计算量可能达到最小值;称算法在最坏情况下的时间复杂度为最坏时间复杂度,指的是算法计算量可能达到的最大值;算法的平均时间复杂度是指算法在所有可能情况下,按照输入实例以等概率出现时,算法计算量的加权平均值。
对算法时间复杂度的度量,人们更关心的是最坏情况下和平均情况下的时间复杂度。然而在很多情况下,算法的平均时间复杂度难于确定,因此,通常只讨论算法在最坏情况下的时间复杂度,即分析最坏情况下,算法执行时间的上界。
-
例 1 - 计算冒泡排序算法的时间复杂度:
写法一:
void bubble_sort(int arr[], int sz) {for (int i = 0; i < sz - 1; ++i) // 进行 sz - 1 趟冒泡排序{int exchange = 0; // 假设待排序数组已经有序for (int j = 0; j < sz - 1 - i; ++j) // 每趟冒泡排序比较 sz - 1 - i 对{if (arr[j] > arr[j + 1]) // 升序{int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;exchange = 1;}}if (exchange == 0){break;}} }写法二:
void bubble_sort(int arr[], int sz) {for (int end = sz - 1; end > 0; --end) {int exchange = 0;for (int i = 0; i < end; ++i) // 确定第 end 位{if (arr[i] > arr[i + 1]){int tmp = arr[i];arr[i] = arr[i + 1];arr[i + 1] = tmp;exchange = 1;}}if (exchange == 0){break;}} }最好时间复杂度为 O(n),最坏时间复杂度为 O(n^2)。
-
例 2 - 计算二分查找算法的时间复杂度:
int binary_search(int arr[], int sz, int target) {int left = 0;int right = sz - 1;while (left <= right){int mid = left + ((right - left) >> 1); if (arr[mid] < target){left = mid + 1;}else if (arr[mid] > target){right = mid - 1;}else{return mid;}}return -1; }最好时间复杂度为 O(1)。
假设总共有 n 个元素,每次查找的区间大小就是 n,n/2,n/4,...,n/2^k,其中 k 表示循环的次数,在最坏情况下有 n/2^k = 1,即 k = log2(n),它是以 2 为底 n 的对数,所以最坏时间复杂度为 O(log2(n)),简写为 O(logn)。
注意:以其他数为底数的对数不能简写。
4.4 - 算法的空间复杂度
关于算法的存储空间需求,类似于算法的时间复杂度,我们采用渐近空间复杂度作为算法所需存储空间的度量,简称空间复杂度(Space Complexity),它也是问题规模 n 的函数,记作:S(n) = O(f(n))。
一般情况下,一个程序在机器上执行时,除了需要寄存本身所用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的辅助存储空间。其中,对于输入数据所占的具体存储量取决于问题本身,与算法无关,这样只需分析该算法在实现时所需要的辅助空间就可以了。
若算法执行时所需要的辅助空间相对于输入数据量而言是个常数,则称这个算法为原地工作,辅助空间为 O(1)。
-
例 1 - 数组逆序,将一维数组
nums中的numsSize个数逆序存放到原数组中:算法一:
void reverse1(int* nums, int numsSize) {for (int i = 0; i < numsSize / 2; ++i){int tmp = nums[i];nums[i] = nums[numsSize - 1 - i];nums[numsSize - 1 - i] = tmp;} }算法一仅需要另外借助两个变量
i和tmp,与问题规模 n 大小无关,所以其空间复杂度为 O(1)。算法二:
void reverse2(int* nums, int numsSize) {int* tmp = (int*)malloc(sizeof(int) * numsSize);if (NULL == tmp){perror("malloc failed!");return;}for (int i = 0; i < numsSize; ++i){tmp[i] = nums[numsSize - 1 - i];}for (int i = 0; i < numsSize; ++i){nums[i] = tmp[i];}free(tmp);tmp = NULL; }算法二需要另外借助一个大小为
numsSize的辅助数组 b,所以其空间复杂度为 O(n)。 -
例 2 - 计算斐波那契递归算法的空间复杂度(重要):
long long fibonacci(size_t n) {if (n == 0)return 0;else if (n == 1 || n == 2)return 1;elsereturn fibonacci(n - 1) + fibonacci(n - 2); }递归算法的空间复杂度 = 每次递归的空间复杂度 * 递归深度。
因此斐波那契递归算法的空间复杂度为 O(n)。
对于一个算法,其时间复杂度和空间复杂度往往是相互影响的,当追求一个较好的时间复杂度时,可能会导致占用较多的存储空间,即可能会使空间复杂度的性能变差,反之亦然。不过经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度,所以,人们都以算法的时间复杂度作为算法优劣的衡量指标。


![[qiankun]实战问题汇总](https://img-blog.csdnimg.cn/290e7d4aa9354eb88bff7a32e1327ac7.png)