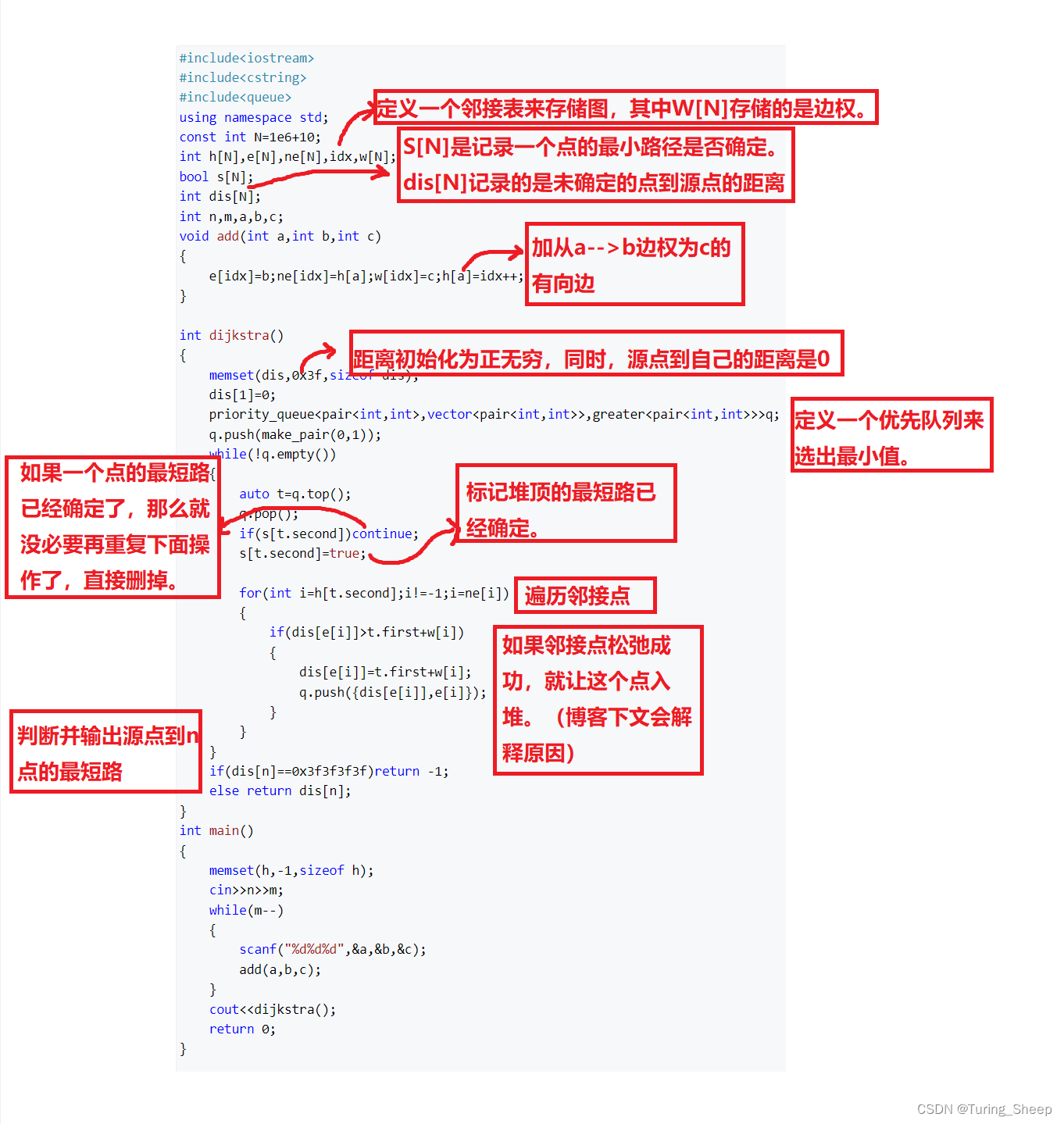
字符串处理【AC自动机】 - 原理 AC自动机详解
AC自动机(Aho-Corasick automaton)在1975年产生于贝尔实验室,是著名的多模匹配算法。
学习AC自动机,要有KMP和Trie(字典树)的基础知识。
KMP是单模匹配算法,即判断模式串T 是否是主串S 的子串。AC自动机是多模匹配算法,例如有多个模式串T 1 , T 2 , T 3 , …, Tk ,求主串S 包含所有模式串的次数。若使用KMP算法,则每个模式串Ti 都要和主串S 进行一次匹配,总时间复杂度为O (n ×k +m ),其中n 为主串S 的长度,m 为模式串T 1 , T 2 , T 3 , …, Tk 的长度和,k 为模式串的个数。而采用AC自动机,时间复杂度只需O (n +m )。
例如给定n个单词,再给出一段包含m 个字符的文章,找出有多少个单词在文章里出现过。
AC自动机实际上是先将KMP算法和Trie树结合,用多个模式串构建一棵字典树,然后在字典树上构建失配指针,失配指针相当于KMP算法中的next函数(匹配失败时的回退位置),最后将主串在Trie树上进行模式匹配。
AC自动机算法分为3步:①构建一棵字典树;②构建AC自动机;③进行模式匹配。
【1】构建字典树
字典树就像我们平时使用的字典一样,把所有单词都编排到一个字典里面,查找单词时,首先看单词的首字母,进入首字母所在的分支,然后看单词的第2个字母,再进入相应的分支,假如该单词在字典树中存在,则只花费单词长度的时间就可以查询到这个单词。
创建字典树指将所有字符串都插入字典树中,字典树可以采用数组或链表存储。插入一个字符串时,需要从前往后遍历整个字符串,在字典树中从根开始判断当前要插入的字符节点是否已经建成,若已建成,则沿该分支遍历下一个字符即可;若没建成,则需要创建一个新节点来表示这个字符,然后往下遍历其他字符,直到整个字符串处理完毕。
假设有单词she、he、his、hers,构建一棵字典树,如下图所示。
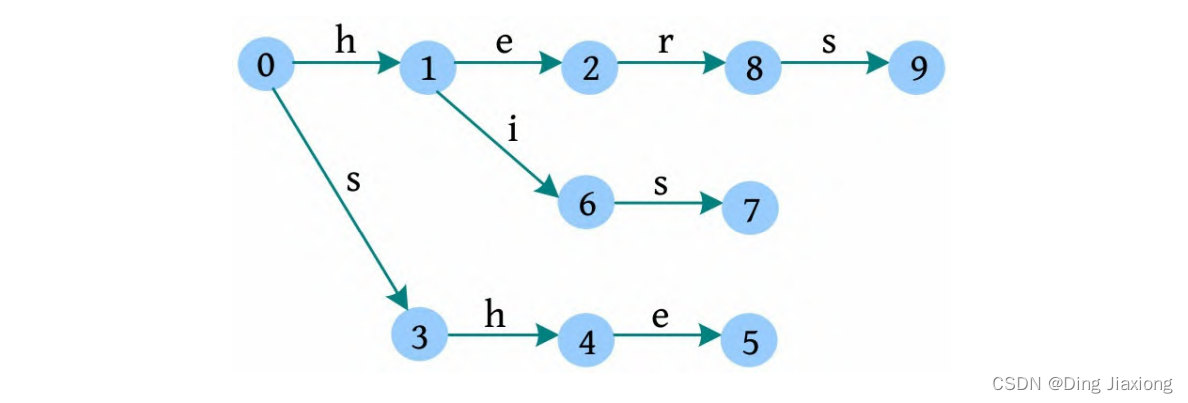
[ 算法代码]
struct node{node *fail;node *ch[K]; // K 为分支数int count;node(){fail = NULL;memset(ch , NULL , sizeof(ch));count = 0;}
};node *superRoot, *root; //超根, 树根, 为方便处理, 添加超根, 树根为 其儿子void insert(char* str){ // Trie 的插入node *t = root;int len = strlen(str);for(int i = 0 ; i < len ; i ++){int x = str[i] - 'a'; //字符转数字if(t -> ch[x] == NULL){t -> ch[x] = new node;}t = t -> ch[x];}t-> count ++;
}
【2】构建AC 自动机
若了解KMP算法,那么肯定了解KMP算法中的next函数(回退函数或者fail函数)。next函数指S [i ]与T [j ]不等时j 应该回退的位置。如下图所示,

当S [i ]与T [j ]不等时,j 应该回退到3的位置,继续比较。
AC自动机的失配指针有同样的功能,模式串在字典树上匹配失败时,会跳转到当前节点失配指针所指向的节点,再次进行匹配操作。AC自动机之所以可以实现多模式匹配,要归功于失配指针(fail指针)。
AC自动机是由字典树及失配指针(匹配失败时转向哪里)组成的。在字典树创建完成后再给每个节点添加失配指针,AC自动机就构造完成了。上面的字典树在添加失配指针后如下图所示。
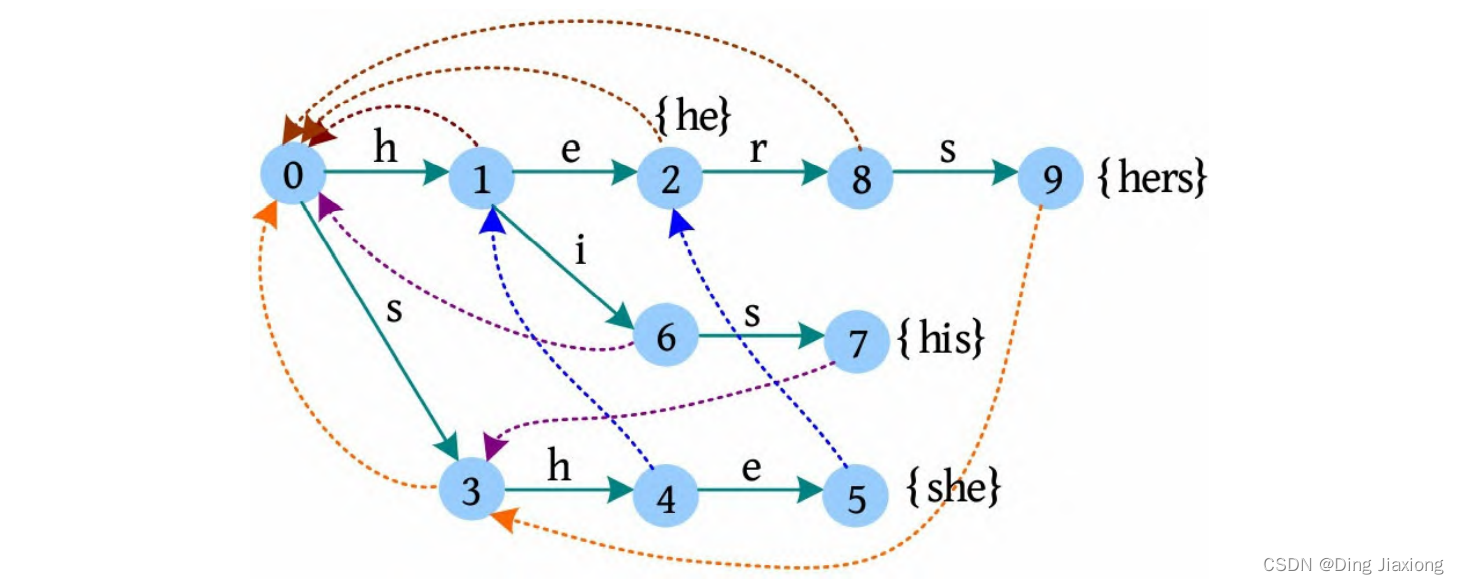
AC自动机的失配指针指向的节点代表的字符串是当前节点代表的字符串的后缀,且在字典树中没有更长的当前节点的后缀。上图中,5号节点的失配指针指向2号节点(字符串{he}),它是5号节点(字符串{she})的后缀,且在字典树中没有更长的5号节点的后缀。
实际上,4号节点的e子节点不为空,4号节点的e子节点的失配指针指向其失配指针的e子节点(2号节点)。5号节点的r子节点为空,5号节点的r子节点指向其失配指针的r子节点(8号节点)。
构建AC自动机实际上就是添加失配指针的过程。由于失配指针都是向上走的,所以从根节点开始进行广度优先搜索就可以得到。
构建AC自动机的过程如下。
① 树根入队。
② 若队列不为空,则取队头元素t 并出队,访问该元素的每一个子节点t ->ch[i ]:
- 若t ->ch[i ]不为空,则t ->ch[i ]的失配指针指向t ->fail->ch[i ],t ->ch[i ]入队;
- 若t ->ch[i ]为空,则t ->ch[i ]指向t ->fail->ch[i ]。
③ 队空时,算法结束。
void build_ac(){ //构建AC 自动机queue<node *> q; // 队列, 广度优先搜索使用q.push(root);while(!q.empty()){node *t;t = q.front();q.pop();for(int i = 0 ; i < K ; i ++){if(t->ch[i]){t->ch[i]->fail = t->fail->ch[i];q.push(t->ch[i]);}else{t->ch[i] = t->fail->ch[i];}}}
}
【3】模式匹配
模式匹配指从树根开始处理模式串的每个字符,沿着当前字符的fail指针,一直遍历到u ->count=-1为止,在遍历过程中累加这些节点的u ->count,累加后将节点标记为u ->count=-1,避免重复统计。u ->count大于或等于1的节点都是可以匹配的节点。
int query(char *str){ //统计在str 中包含多少个单词int ans = 0;node *t = root;int len = strlen(str);for(int i = 0 ; i < len; i++){int x = str[i] - 'a';t = t->ch[x];for(node *u = t ; u -> count != -1 ; u = u->fail){ans += u->count;u->count = -1;}}return ans;
}
例如,在字符串{shers}中包含了几个单词?首先从字典树的根开始,匹配第1个字符s,然后匹配第2个字符h,接着匹配第3个字符e,匹配成功{she},5号节点的失配指针指向2号节点,又匹配成功{he};继续匹配第4个字符r,5号节点的r子节点指向其失败指针的r子节点,因此访问8号节点,继续匹配第5个字符s,匹配成功{hers};字符串匹配完毕,包含3个单词。