NoSQL介绍:


NOSQL解决cpu和内存压力的:

NoSQL解决io压力:

NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
NoSQL最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
NoSQL有如下优点:易扩展,NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间也在架构的层面上带来了可扩展的能力。大数据量,高性能,NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。

NoSQL的分类:
- 键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果数据库管理员(DBA)只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB。 - 列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak. - 文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值,在处理网页等复杂数据时,文档型数据库比传统键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。 - 图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。如:Neo4J, InfoGrid, Infinite Graph。
注意:行数据库就是我们传统的mysql,Orical等。

NoSQL数据库在以下的这几种情况下比较适用:
1、数据模型比较简单;
2、需要灵活性更强的IT系统;
3、对数据库性能要求较高;
4、不需要高度的数据一致性;
5、对于给定key,比较容易映射复杂值的环境。
NoSQL的优点/缺点:
优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活性,半结构化数据
- 没有复杂的关系
缺点:
- 没有标准化
- 有限的查询功能(到目前为止)
- 最终一致是不直观的程序


常见的NoSQL:


行式数据库:
行式数据库(Row-Based)数据按行存储,常见的行式数据库有Mysql,DB2,Oracle,Sql-server等;列数据库(Column-Based)数据存储方式按列存储,常见的列数据库有Hbase,Hive,Clickhouse,Sybase 等。
行存储是将整行放入连续的物理位置,就像传统的记录存储或文件存储方式,列存储是按列将连续的某几列数据放入连续的物理存储单元中,行存储方法如下图所示。

行存储的特点:
数据是按行存储的
没有索引的查询会消耗大量的IO资源
建立索引和视图需要耗费大量的时间和系统资源
面对高并发的查询,数据库必须被大量膨胀才能满足性能需求
实操中我们会发现
行式数据库在读取数据的时候
会存在一个固有的“缺陷”
比如,所选择查询的目标即使只涉及少数几项属性
但由于这些目标数据埋藏在各行数据单元中
而行单元往往又特别大
应用程序必须读取每一条完整的行记录
从而使得读取效率大大降低
对此,行式数据库给出的优化方案是加“索引”
在OLTP类型的应用中
通过索引机制或给表分区等手段
可以简化查询操作步骤,并提升查询效率
行式存储的适用场景包括:
1、适合随机的增删改查操作;
2、需要在行中选取所有属性的查询操作;
3、需要频繁插入或更新的操作,其操作与索引和行的大小更为相关。
列式数据库:
列存储特点:
数据按列存储—每一列单独存放
数据即是索引,无须另建索引
只访问查询所涉及到的列(与行数据库不同)–节省IO开支
可以高效压缩
查询的并发处理性能高

1.针对海量数据背景的OLAP应用
(例如分布式数据库、数据仓库等等)
行式存储的数据库就有些“力不从心”了
行式数据库建立索引和物化视图
需要花费大量时间和资源
因此还是得不偿失
无法从根本上解决查询性能和维护成本等问题
也不适用于数据仓库等应用场景
所以后来出现了基于列式存储的数据库,2.对于数据仓库和分布式数据库来说
大部分情况下它会从各个数据源汇总数据
然后进行分析和反馈
其操作大多是围绕同一列属性的数据进行的
而当查询某属性的数据记录时
列式数据库只需返回与列属性相关的值
在大数据量查询场景中
列式数据库可在内存中高效组装各列的值
最终形成关系记录集
因此可以显著减少IO消耗
并降低查询响应时间
非常适合数据仓库和分布式的应用
列式存储引擎的适用场景包括:
1、查询过程中,可针对各列的运算并发执行(SMP),在内存中聚合完整记录集,可能降低查询响应时间;
2、可在数据列中高效查找数据,无需维护索引(任何列都能作为索引),查询过程中能够尽量减少无关IO,避免全表扫描;
3、因为各列独立存储,且数据类型已知,可以针对该列的数据类型、数据量大小等因素动态选择压缩算法,以提高物理存储利用率;如果某一行的某一列没有数据,那在列存储时,就可以不存储该列的值,这将比行式存储更节省空间。
当然,跟行数据库一样,列式存储也有不太适用的场景,主要包括:
1.数据需要频繁更新的交易场景
2.表中列属性较少的小量数据库场景
3.不适合做含有删除和更新的实时操作
各自应用场景:
行存储数据库适用在OLTP(on-line transaction processing)场景即联机事务处理,而列数据库适合适用在大数据分析OLAP(on-line Analytical processing)联机分析处理,当然不管是列数据库还是行数据库起功能或能力都不是万能的,只是给DBA多提供了一个可选方案,具体项目执行需要架构师根据项目实际情况选择最合适的方案。
常见列式数据库:


图数据库:
图数据库: 基于图论实现的一种新型noSql数据库,其数据库存储结构和数据的查询方式都是以图论为基础的,图论中图的基本元素为节点和边,在图数据库中对应的就是节点和关系。
随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,传统数据库很难处理关系运算。大数据行业需要处理的数据之间的关系随数据量呈几何级数增长,亟需一种支持海量复杂数据关系运算的数据库,图数据库应运而生。
世界上很多著名的公司都在使用图数据库。比如:
社交领域:Facebook, Twitter,Linkedin用它来管理社交关系,实现好友推荐
零售领域:eBay,沃尔玛使用它实现商品实时推荐,给买家更好的购物体验
金融领域:摩根大通,花旗和瑞银等银行在用图数据库做风控处理
汽车制造领域:沃尔沃,戴姆勒和丰田等顶级汽车制造商依靠图数据库推动创新制造解决方案
电信领域:Verizon, Orange和AT&T 等电信公司依靠图数据库来管理网络,控制访问并支持客户360
酒店领域:万豪和雅高酒店等顶级酒店公司依使用图数据库来管理复杂且快速变化的库存
既然图数据库应用这么广泛,越来越多的企业和开发者开始使用它,那它究竟什么过人之处呢,下面我们来揭开它的神秘面纱。
1.1 什么是图?
图由两个元素组成:节点和关系。
每个节点代表一个实体(人,地,事物,类别或其他数据),每个关系代表两个节点的关联方式。这种通用结构可以对各种场景进行建模 - 从道路系统到设备网络,到人口的病史或由关系定义的任何其他事物。
1.2 什么是图数据库?
图数据库(Graph database)并非指存储图片的数据库,而是以图这种数据结构存储和查询数据。
图形数据库是一种在线数据库管理系统,具有处理图形数据模型的创建,读取,更新和删除(CRUD)操作。
与其他数据库不同,关系在图数据库中占首要地位。这意味着应用程序不必使用外键或带外处理(如MapReduce)来推断数据连接。
与关系数据库或其他NoSQL数据库相比,图数据库的数据模型也更加简单,更具表现力。
图形数据库是为与事务(OLTP)系统一起使用而构建的,并且在设计时考虑了事务完整性和操作可用性。
应用场景
图数据库适用场景:
辅助搜索:如社交网络,类似facebook兴趣图谱可以辅助推荐一些兴趣相似或者有联系的用户
辅助问答:如知识问答,通过将知识建设成图的形式,可以把问题回答的更准确和可靠
辅助决策:通过结合图相关的算法,如PageRank、mcl、betweenness等可以通过图数据库的优势挖掘或者推理出一些信息,辅助业务决策
图数据库不适用场景:
统计、报表分析
不适合写多读少的场景。在写入或者删除时候,需要维护关系的链接指针。因此大量而频繁的写操作,在性能上是一个考验。

首先,先简要介绍一下Neo4j。Neo4j是由Java和Scala写成的一个NoSql数据库,专门用于网络图的存储。更详细的内容可见官网。作为一个图形数据库,Neo4j有以下优点:
更快的数据库操作。当然,有一个前提条件,那就是数据量较大,在MySql中存储的话需要许多表,并且表之间联系较多(即有不少的操作需要join表)。
数据更直观,相应的SQL语句也更好写(Neo4j使用Cypher语言,与传统SQL有很大不同)。
更灵活。不管有什么新的数据需要存储,都是一律的节点和边,只需要考虑节点属性和边属性。而MySql中即意味着新的表,还要考虑和其他表的关系。
数据库操作的速度并不会随着数据库的增大有明显的降低。这得益于Neo4j特殊的数据存储结构和专门优化的图算法。

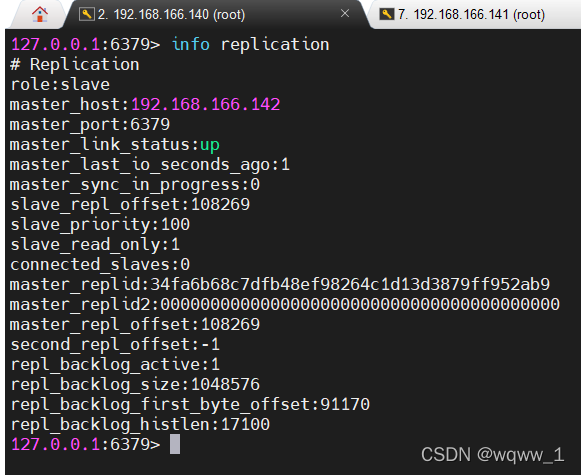
1.Redis简介:
- Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key - value 数据库.
Redis 与 其他 key - value 缓存产品有以下三个特点:
- Redis 支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis 不仅仅支持简单的 key - value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储.
- Redis 支持数据的备份,即 master - slave 模式的数据备份.
- Redis 优势
-
性能极高:Redis 读的速度是 110000 次 /s, 写的速度是 81000 次 /s 。
-
丰富的数据类型:Redis 支持二进制案例的 String, List, Hashe, Set 及 sorted set 数据类型操作。
-
原子性:Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
-
其他特性:Redis 还支持 publish/subscribe 通知,key 过期等特性。
- Redis 数据类型
Redis 支持 5 中数据类型:string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)

作用:


2.Redis安装:
下载:进入redis官网:https://redis.io/
下载稳定版本(即带有stable字样的是稳定版本)


安装:
安装前环境准备:
第一步:安装redis需要在有c语言的编译环境下,执行命令安装c语言环境::
①基本环境gcc,安装命令:yum install gcc-c++
等待其安装完成,输入gcc -v查看当前gcc的版本:
我们安装的Redis版本是6.2.6.对gcc环境的版本有一定的要求,所以我们要升级gcc的版本, 输入以下命令:
②升级gcc的版本: 输入以下命令:
#第一步
sudo yum install centos-release-scl
#第二步
sudo yum install devtoolset-8-gcc*
#第三步
scl enable devtoolset-8 bash一直y就好。
然后查看gcc --veriosn版本
③上传到linux:将从官网下载下载下来的压缩包用工具上传到linux主机的任意目录,
我这里上传到了/usr/src下
④解压redis-6.2.6.tar.gz:
进入到压缩包所在的目录下,使用tar -zxvf redis-6.2.6.tar.gz 进行解压
⑤编译:解压完成后,进入解压后的目录,cd redis-6.2.6 ,然后执行 编译命令 make即可。
⑥安装:make完了之后再执行安装命令(同样在redis-6.2.6目录下):make install,安装文件!
到此安装完毕!!!
大家应该会发现我们并没有指定安装的路径,但是Redis有一个默认的路径,得记住:/usr/local/bin

前台启动:

后台启动:
复制一份配置文件:cp redis.conf redis_copy.conf
然后编辑: vim redis.conf
①先在网络部分注释掉单机连接那一行,即注释掉bind 127.0.0.1 :
输入/要搜索的关键字 +回车 ,然后可以使用n翻页,进行查找

②同样我们要将后台运行打开:daemonize no,设置为yes。

将后台运行改成yes:

③将 protected-mode yes 改为:protected-mode no (原因:把yes改成no,允许外网访问),protected-mode是redis本身的一个安全层,这个安全层的作用:就是只有【本机】可以访问redis,其他任何都不可以访问redis.
3.Redis启动:
进入到redis默认的安装路径:
cd /usr/local/bin 查看启动命名:ll
我们将配置文件拷贝过来到bin下,以后就用这个配置文件来启动Redis服务:
命令: cp /usr/src/redis-6.2.6/redis.conf redis.conf
下来就是.启动和连接Redis服务!
#启动redis服务,在/usr/local/bin下执行命令:
redis-server redis.conf
#连接redis服务
redis-cli -p 6379
测试redis服务:
先测试set和get基本操作:

在以后的springboot/spring项目中需要额外的一些设置:
二、查看虚拟机防火墙是否关闭,需要关闭防火墙
1:查看防火状态
systemctl status firewalld
service iptables status
2:暂时关闭防火墙
systemctl stop firewalld
service iptables stop
3:永久关闭防火墙
systemctl disable firewalld
chkconfig iptables off
关闭后再查看防火墙状态
三:开放指定端口6379:
开放指定端口的方式一:
在linux中执行: /sbin/iptables -I INPUT -p tcp --dport 6379 -j ACCEPT
redis默认端口号6379是不允许进行远程连接的,所以在防火墙中设置6379开启远程服务;
开放指定端口的方式二:
先开启防火墙才能开放指定端口的:systemctl start firewalld
firewall-cmd --zone=public --add-port=6379/tcp --permanent
4.Redis关闭:
关闭的方式一:控制台关闭:shutdown
关闭的方式二:指定端口关闭:redis-cli -p 6379 shutdown



Redis配置连接密码:
当我们需要远程连接的时候,尽量设置密码(不设置密码也可以远程连接的),保证安全性:
requirepass 密码

使用密码连接:
一次性直接连接:

或者后续输入密码进行连接: