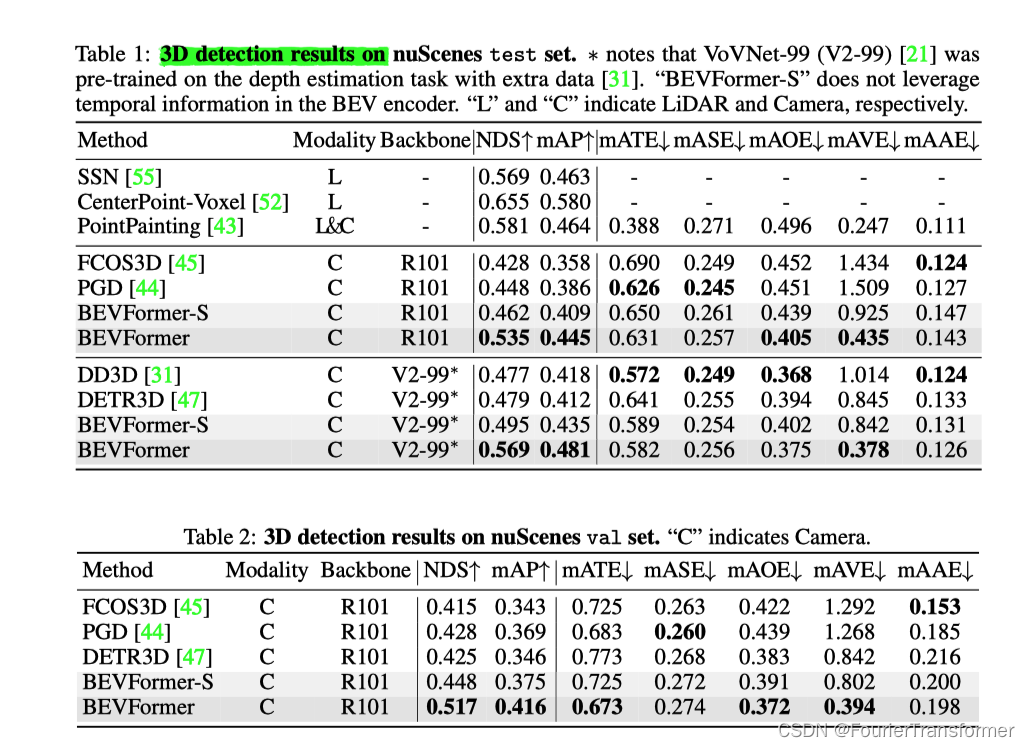
BEVFormerEncoder中的get_reference_points
@staticmethoddef get_reference_points(H, W, Z=8, num_points_in_pillar=4, dim='3d', bs=1, device='cuda', dtype=torch.float):"""Get the reference points used in SCA and TSA.Args:H, W: spatial shape of bev.Z: hight of pillar.D: sample D points uniformly from each pillar.device (obj:`device`): The device wherereference_points should be.Returns:Tensor: reference points used in decoder, has \shape (bs, num_keys, num_levels, 2)."""# reference points in 3D space, used in spatial cross-attention (SCA)if dim == '3d':zs = torch.linspace(0.5, Z - 0.5, num_points_in_pillar, dtype=dtype,device=device).view(-1, 1, 1).expand(num_points_in_pillar, H, W) / Zxs = torch.linspace(0.5, W - 0.5, W, dtype=dtype,device=device).view(1, 1, W).expand(num_points_in_pillar, H, W) / Wys = torch.linspace(0.5, H - 0.5, H, dtype=dtype,device=device).view(1, H, 1).expand(num_points_in_pillar, H, W) / Href_3d = torch.stack((xs, ys, zs), -1)ref_3d = ref_3d.permute(0, 3, 1, 2).flatten(2).permute(0, 2, 1)ref_3d = ref_3d[None].repeat(bs, 1, 1, 1)return ref_3d# reference points on 2D bev plane, used in temporal self-attention (TSA).elif dim == '2d':ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H - 0.5, H, dtype=dtype, device=device),torch.linspace(0.5, W - 0.5, W, dtype=dtype, device=device))ref_y = ref_y.reshape(-1)[None] / Href_x = ref_x.reshape(-1)[None] / Wref_2d = torch.stack((ref_x, ref_y), -1)ref_2d = ref_2d.repeat(bs, 1, 1).unsqueeze(2)return ref_2d
根据上面的代码可以看出来,如果输入的是3d, 则是
按照:
- X方向: 从0.5, 到W-0.5分成W份.
- Y方向: 从0.5, 到H-0.5分成H份.
- Z方向: 从0.5, 到Z-0.5, 分成 num_points_in_pillar份.
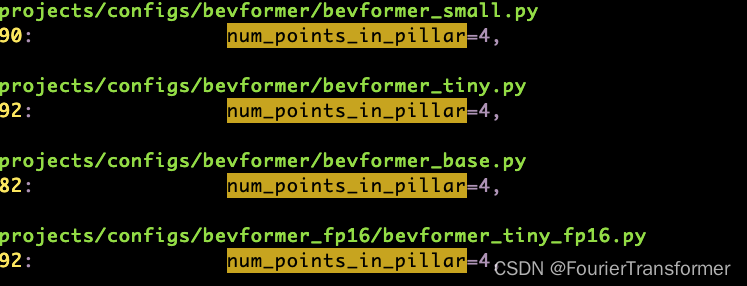
其中num_points_in_pillar 默认给的是4.
配置文件里面给的其实也是4.
BEVFormerEncoder中的point_sampling
# This function must use fp32!!!@force_fp32(apply_to=('reference_points', 'img_metas'))def point_sampling(self, reference_points, pc_range, img_metas):lidar2img = []for img_meta in img_metas:lidar2img.append(img_meta['lidar2img'])lidar2img = np.asarray(lidar2img)lidar2img = reference_points.new_tensor(lidar2img) # (B, N, 4, 4)reference_points = reference_points.clone()# 变换到点云的范围内. 这也是为何get_reference_points中会/H, /W, /Z, 先化到[0, 1]变成ratio.reference_points[..., 0:1] = reference_points[..., 0:1] * \(pc_range[3] - pc_range[0]) + pc_range[0]reference_points[..., 1:2] = reference_points[..., 1:2] * \(pc_range[4] - pc_range[1]) + pc_range[1]reference_points[..., 2:3] = reference_points[..., 2:3] * \(pc_range[5] - pc_range[2]) + pc_range[2]# 由(x, y, z) 变成(x, y, z, 1) 便于与4*4的参数矩阵相乘.reference_points = torch.cat((reference_points, torch.ones_like(reference_points[..., :1])), -1)# 此时reference_points可以当成是点云的点了.reference_points = reference_points.permute(1, 0, 2, 3)# num_query等于H*W*Z. 等于grid_points的数量.D, B, num_query = reference_points.size()[:3]num_cam = lidar2img.size(1)# 要往每个相机上去投影. 因此先申请num_cam份.# reference_points的shape就变成了, (D, b, num_cam, num_query, 4, 1) 便于和4*4的矩阵做matmul.reference_points = reference_points.view(D, B, 1, num_query, 4).repeat(1, 1, num_cam, 1, 1).unsqueeze(-1)# 相机参数由(b,num_cam, 4, 4) 变成(1, b, num_cam, 1, 4, 4) 再变成(D,b,num_cam,num_query,4,4)lidar2img = lidar2img.view(1, B, num_cam, 1, 4, 4).repeat(D, 1, 1, num_query, 1, 1)reference_points_cam = torch.matmul(lidar2img.to(torch.float32),reference_points.to(torch.float32)).squeeze(-1)eps = 1e-5# 把每个相机后面的点mask掉. 因为相机后面的点投过来之后第三位是负的.bev_mask = (reference_points_cam[..., 2:3] > eps)# 再做齐次化. 得到像素坐标.reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3]) * eps)# 由像素坐标转成相对于图像的ratio..# NOTE 这里如果不同相机size不一样的话.要除以对应的相机的sizereference_points_cam[..., 0] /= img_metas[0]['img_shape'][0][1]reference_points_cam[..., 1] /= img_metas[0]['img_shape'][0][0]# 再把超出图像fov范围的点给去掉.bev_mask = (bev_mask & (reference_points_cam[..., 1:2] > 0.0)& (reference_points_cam[..., 1:2] < 1.0)& (reference_points_cam[..., 0:1] < 1.0)& (reference_points_cam[..., 0:1] > 0.0))if digit_version(TORCH_VERSION) >= digit_version('1.8'):bev_mask = torch.nan_to_num(bev_mask)else:bev_mask = bev_mask.new_tensor(np.nan_to_num(bev_mask.cpu().numpy()))# 由(D, b, num_cam, num_query, 2) 变成 (num_cam, b, num_query, D, 2)reference_points_cam = reference_points_cam.permute(2, 1, 3, 0, 4)bev_mask = bev_mask.permute(2, 1, 3, 0, 4).squeeze(-1)# 至此. reference_points_cam代表的就是像素点相对于各个相机的ratio.# bev_mask就代表哪些点是有效的return reference_points_cam, bev_mask
SpatialCrossAttention
个人理解SpatialCrossAttention其实就是正常的Deformable Attention, 只不过原始Deformable Attention中的
refer points是由网络产生的,
而现在的refer points 是由 虚拟的grid points往图像上投影得到的. 在相机参数固定的情况下, 此时的refer points是固定的.
下面是 SpatialCrossAttention这个模块的forward函数的部分代码



问题: 给固定的这些refer points 的收益是多大? 文章好像并没有提. 这一块儿感觉不充分.
另外, 显然这样虚拟的grid points 是不合理的, 因为有些地方可能就没有点, 但是还是能够投影到图像上的. 这里用真值的点应该会更好,
比如用lidar的points. 但是BEVFormer paper里面没有对比加入lidar后的效果.