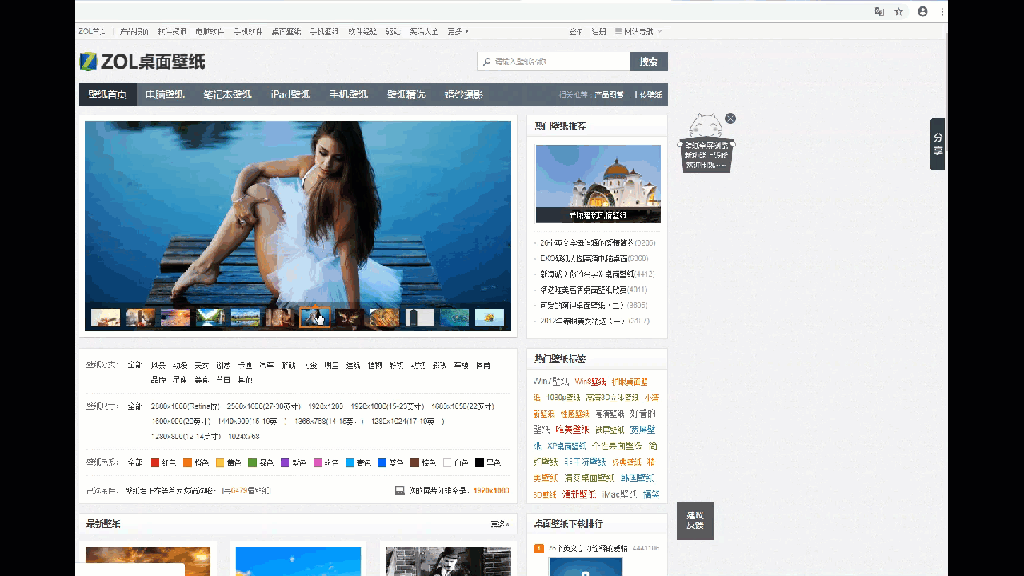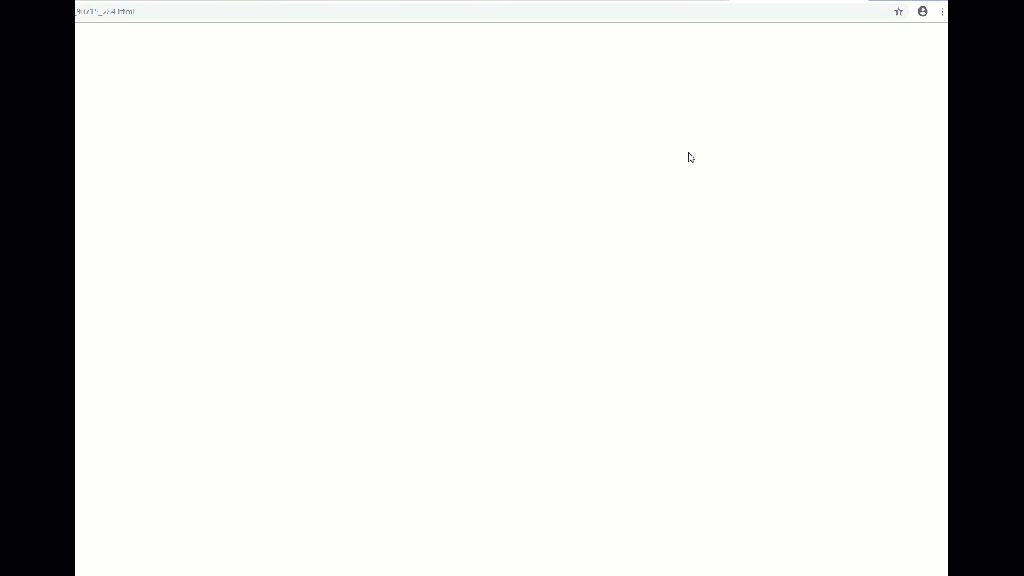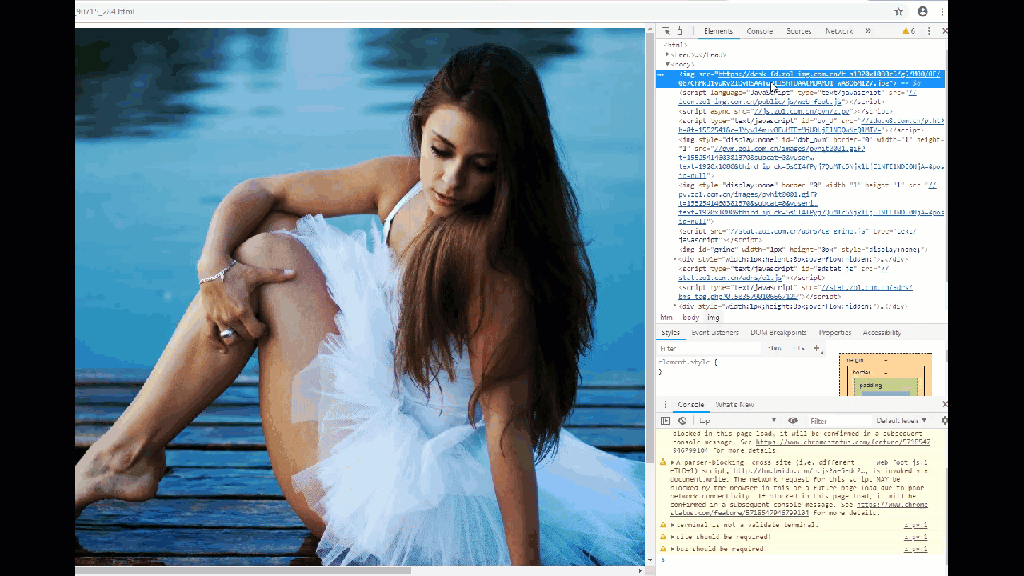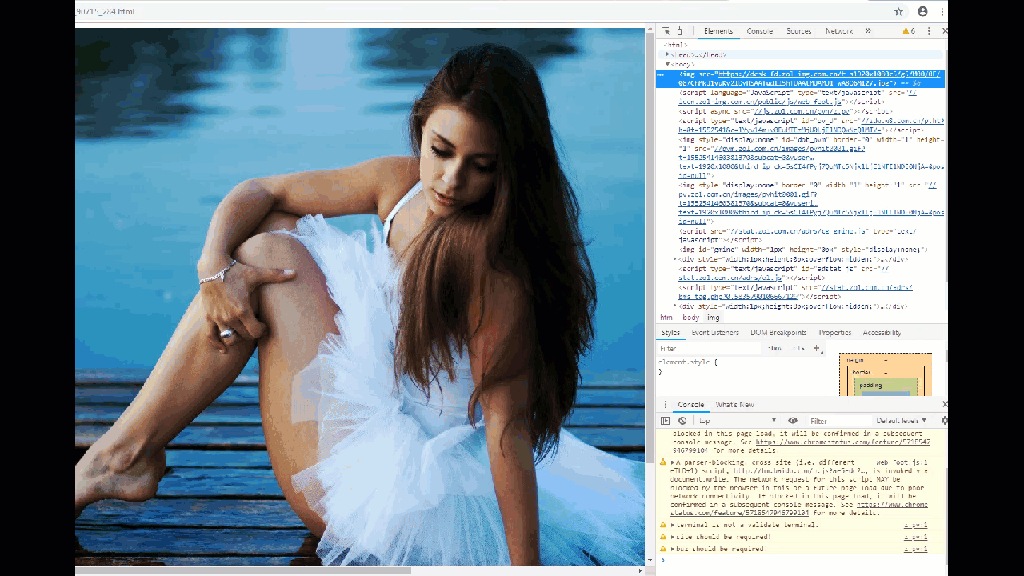
最近学习了一下python爬虫写了个小demo,根据python网络爬虫(一) 爬取网站图片_sunrise的博客-CSDN博客_python网络爬虫爬取图片这篇文章修改了一下,这个爬取的只是分页的缩略图,这对于lsp这怎么行,那必须要高清图片不是
上完整代码:
import requests
import time
from lxml import etree# 请求的路径
url = 'http://desk.zol.com.cn/dongman/1920x1080/'
# 这里是你要保存的路径位置 前面的r 表示这段不转义
path = r"F:\图片"
# 请求头
headers = {"Referer": "Referer: http://desk.zol.com.cn/dongman/1920x1080/","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36", }headers2 = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0", }# TODO 获取到Html页面进行解析
def getHtml():# 发送请求resq = requests.get(url, headers=headers)# 显示请求是否成功print(resq)# 解析请求后获得的页面html = etree.HTML(resq.text)# 获取a标签下进入高清图页面的urlhrefs = html.xpath('.//a[@class="pic"]/@href')# TODO 进入更深一层获取图片 高清图片for i in range(1, len(hrefs)):# 请求resqt = requests.get("https://desk.zol.com.cn" + hrefs[i], headers=headers)# 解析htmlt = etree.HTML(resqt.text)srct = htmlt.xpath('.//img[@id="bigImg"]/@src')# 截图片名称imgname = srct[0].split('/')[-1]# 根据url获取图片img = requests.get(srct[0], headers=headers2)# 执行写入图片到文件with open(path + "\\" + imgname, "ab") as file:file.write(img.content)# 打印爬取的图片print(img, imgname)if __name__ == "__main__":getHtml()
稍微解压一下,其实就是分为两层,第一层解析首页页面的分页当中的超链接,获取到进入高清图页面的url ,在进入循环,去解析它获取到高清图的下载地址,最后下载保存下来即可,大家有兴趣可以结合我的文章和上面的文章去完成分页的高清图爬取,相信对你的python技术会有很大的帮助,最后学学技术就行,切勿恶意爬取页面!切勿恶意爬取页面!切勿恶意爬取页面!