最近感觉桌面壁纸用太久了,有点视觉疲劳,所以在ZOL上新找了一张,这里,我就使用最简单的爬虫来把它抓到我的壁纸目录里吧。
首先在浏览器中审查喜欢的图片,来确定他的链接。
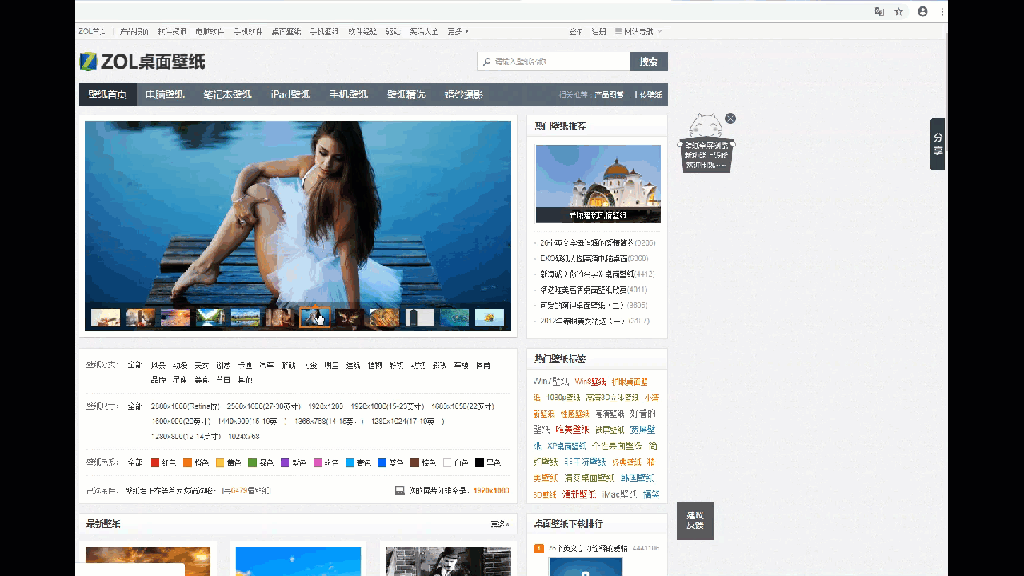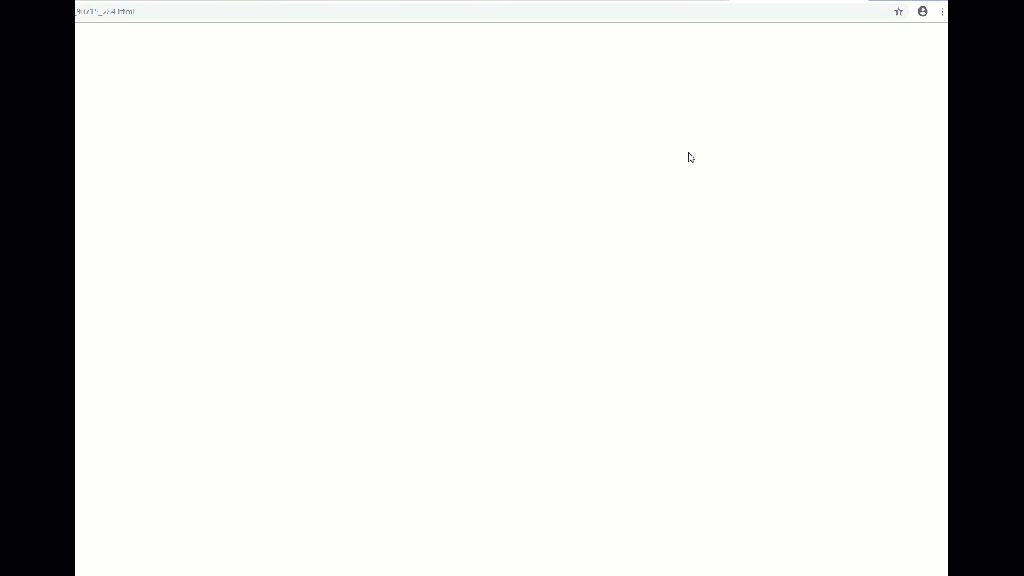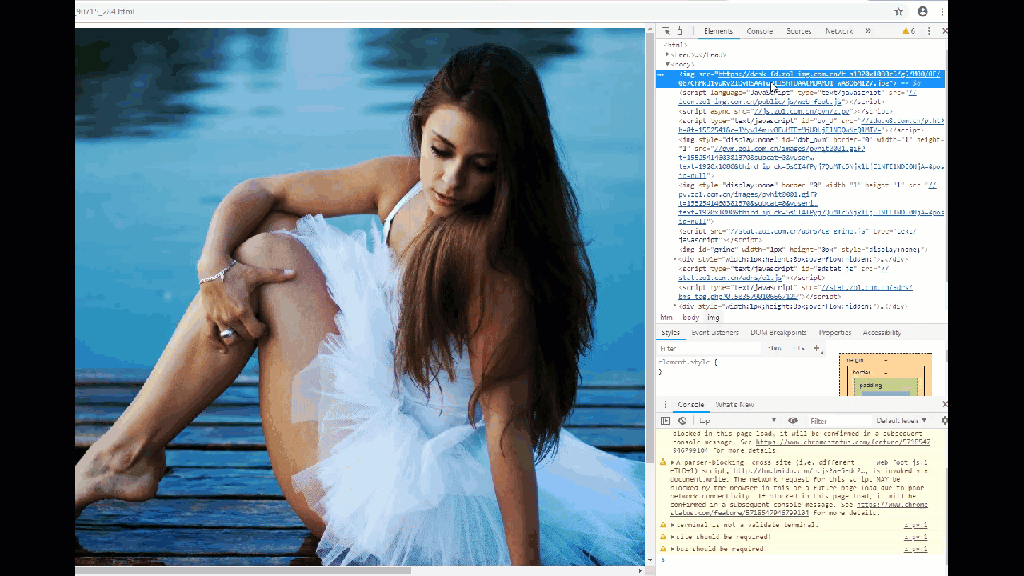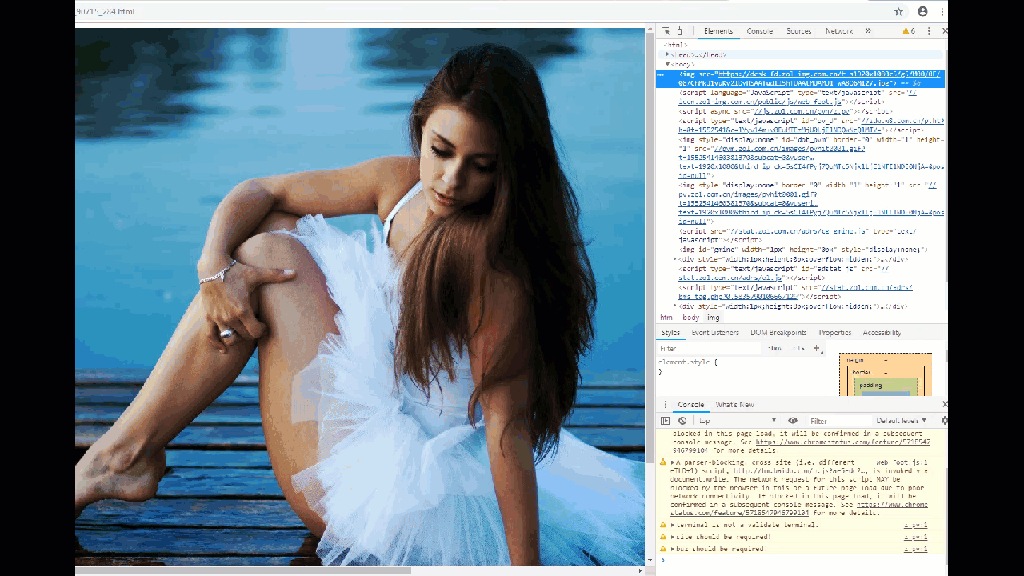
接下来我们使用python来将它下载下来,这里我使用urllib这个包。
一、urllib的简单使用
python3中的urllib的使用方法与python2中的urllib或者urllib2有些区别,首先是导入方式
1 from urllib import request
我们先用它访问一下百度首页吧
1 from urllib import request 2 3 response = request.urlopen("http://www.baidu.com") 4 5 #读取页面内容 6 7 page_body = response.read() 8 9 print(page_body)
运行之后应该可以看到打印出了百度首页的页面源码, 特别需要注意的是, response.read()返回的是二进制数据, 这一点对于这节的目的来说,很方便。
二、使用urllib下载壁纸
我们只需要将上面的小例子中的链接替换为我们图片的url即可将之下载下来,随后仅仅需要写到磁盘即可。
1 from urllib import request 2 3 if __name__ == '__main__': 4 img_link = 'https://desk-fd.zol-img.com.cn/t_s1920x1080c5/g5/M00/0F/08/ChMkJ1vuKy2IDyRSAATudIl5hTUAAtMUAMU1-wABO6M127.jpg' 5 response = request.urlopen(img_link) 6 img_data = response.read() 7 save_to = './test.jpg' 8 with open(save_to, 'wb') as fp: 9 fp.write(img_data) 10
运行以上程序, 可以看到图片被保存在了同级目录中, 至此,我们实现了一个可以抓取单一图片的小爬虫, 功能虽然简单, 但任何功能强大的爬虫都是从它开始的, 在之后的章节,我们将在他的基础上来实现一个功能更加完备的图片爬虫。
下一节:
二、文本提取——正则表达式



