文章目录
- 前言
- 一、明确一个大方针
- 二、分析网页
- 1.查看页面结构
- 三、开始动手吧
- 1.获取网页信息
- 2.获取图片地址
- 3.全部代码
- 总结
前言
本案例仅用于技术学习
每天与电脑为伴,天天看着默认的桌面屏幕,作为喜新厌旧的我怎么能忍?搜索桌面壁纸,随意的挑选了一个网址,开始爬取图片之旅。
一、明确一个大方针
中心主旨还是获取网页信息—提取图片信息—保存图片
使用到的库有requests,获取网页信息,BeautifulSoup库提取网页信息,re匹配图片个数字段,os保存文件
二、分析网页
http://desk.zol.com.cn/ 目标网页
1.查看页面结构

网站将图片按照分类分别存放,设置了小专题,每个专题内有不同个数的图片。选择风景分类,查看每个专题排列规则。


观察发现每个专题对应每个<li class=“photo-list-padding”>标签,图片的个数在span标签下。点开li标签,可以看到a标签中有属性href,点击链接,进入专题,说明这个链接是专题的链接。

在专题内查看图片,通过查看上下张图片,同一个专题内的图片是按照顺序命名的,这样我们就知道了如何找到专题内图片的网址。
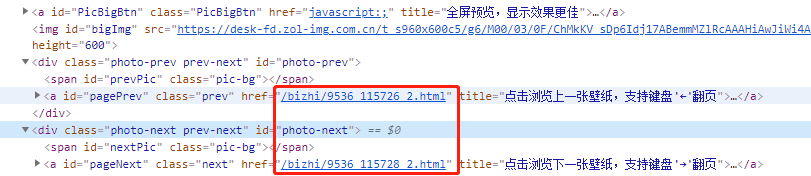
接下来需要找到当前图片的地址,查看a标签的id命名,找到当前图片,发现有img标签,点击网址,确实是我们要找的图片。
三、开始动手吧
1.获取网页信息
这里直接从风景开始,如果需要其他分类可以修改网址或循环获取。
url="http://desk.zol.com.cn/fengjing"
html = getHtml(url) #获取网页信息
getPicUrl(html,5) #获取图片并保存,传入要抓取的图片数量
2.获取图片地址
图片在专题中保存着,所以需要先获取专题url,向专题url发送请求,获取专题的网址信息,在信息中找到图片地址。这里获取了图片张数,使用专题内第一张图片的数字递增寻找下一张,但是实际网站图片不是按照递增保存的,会导致部分图片找不到。

3.全部代码
import os
import requests
import re
from bs4 import BeautifulSoupdef getHtml(url):try:r=requests.get(url,timeout=30)r.raise_for_status()r.encoding=r.apparent_encodingreturn r.textexcept Exception as e:print("网址不正确")print(e)def getPicUrl(html,picn):try:soup=BeautifulSoup(html,'html.parser')lis=soup.find_all('li',"photo-list-padding")#遍历标题for li in lis:if (picn != 0) & (len(lis) != 0):des=li.a.span.textprint(des)'''正则表达式获取描述中的图片张数'''pattern = re.compile(r".*?(\d+).*")res = re.findall(pattern, des)n=int(str(res[0]))'获取专题网址链接'href = li.a.attrs['href']href1 = href.split('_')[0]href2 = href.split('_')[1]'''跟据获取的图片数量拼接网址''''''按照递增顺序获取图片,获取的第一张图片id不是最小的'''for i in range(n):h = int(href2)+iurl = "http://desk.zol.com.cn"+href1+'_'+str(h)+'_2.html'print(url)pichtml = getHtml(url)'''网址存在的情况下保存图片'''if pichtml is not None:soup2 = BeautifulSoup(pichtml, 'html.parser')imgurl = soup2.find(id='bigImg').attrs['src']print(imgurl)savePic(imgurl)picn=picn-1if picn == 0:breakelse:print("收集完成")breakexcept Exception as e:print(e)def savePic(url):'''保存到文件中'''root = "D:/Program/picture/"path = root + url.split('/')[-1]try:if not os.path.exists(path):r = requests.get(url)with open(path, 'wb') as f:f.write(r.content)f.close()print('保存成功')else:print('已存在')except Exception as e:print('保存失败,失败原因为:')print(e)def main():url="http://desk.zol.com.cn/fengjing"html = getHtml(url)getPicUrl(html,5)main()
总结
运行代码后会自动抓取指定数量的图片,抓取完成后会自动停止。目前的不足之处有:1.专题内部分图片抓取不到 2.抓取不能接着上一次停下的位置继续 3.循环抓取不同分类
不过目前来看,下载的图片已经够过完2020了(狗头),将文件夹设置成桌面,每天自动换一张。虽然没多少时间能看着桌面壁纸。