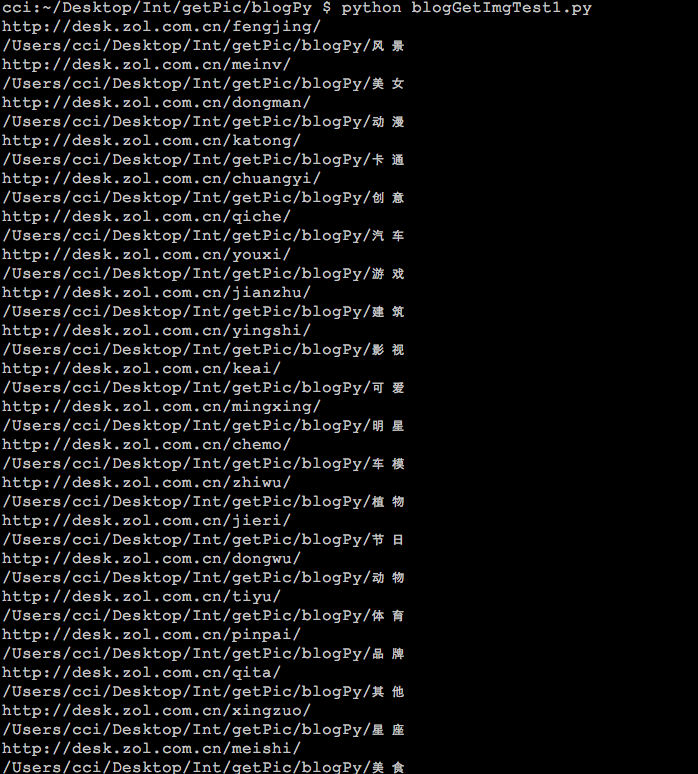
声明:仅供参考、学习。
爬取地址:http://desk.zol.com.cn/dongwu/1920x1080/
爬取页码:1-2页
存储位置:D盘根目录
运行条件:电脑安装python 3.0+
代码:
from urllib import request,error
import re
url = "http://desk.zol.com.cn/dongwu/1920x1200/"
urls = []urls.append(url)
for i in range(2,2):urls.append(url + "%r.html" % i)
###########################获取每张壁纸的页面########################
for url in urls:try:response = request.urlopen(url) #打开页面byte_html = response.read() #此时的html是'byte'类型html =str(byte_html) #转换成字符串pattern = re.compile(r'<a.*? href="(.*?)".*?>.*?</a>')imglist = re.findall(pattern,html) #匹配<a>标签中的href地址truelist= []for item in imglist:if re.match(r'^\/bizhi\/',item):truelist.append(item)except error.HTTPError as e:print(e.reason)except error.URLError as e:print(e.reason)except:pass
#########################对每张壁纸, 获取其地址并下载到本地################################
x = 0
for wall_pager_page in truelist :print('-' * 40)print(wall_pager_page)url1 = "http://desk.zol.com.cn" + wall_pager_pageresponse1 = request.urlopen(url1)byte_html1 = response1.read()html1 = str(byte_html1)pattern1 = re.compile(r'<a.*?id="1920x1080" href="(.*?)".*?>.*?</a>')urllist = re.findall(pattern1,html1)print('url1:'+urllist[0])html2 = str(request.urlopen("http://desk.zol.com.cn"+urllist[0]).read())pattern2 = re.compile(r'<img.*? src="(.*?)"')wallpageurl = re.findall(pattern2,html2)print(wallpageurl[0])request.urlretrieve(wallpageurl[0],"D:/%r.jpg" % x)x += 1执行结果:

保存的图片: