本文目录
阅读本文大约需要10分钟
numactl内存绑定中代码段的问题
代码段为什么没有进入指定的numa节点
内核内存管理一个改进方向建议

numactl内存绑定中代码段的问题
在一个典型的NUMA架构Linux服务器中,我们常常使用类似
numactl -N 1 -m 1 ./a.out
类似的命令来绑定一定进程的memory,比如上面的例子,进程的memory被绑定到NUMA1。
但是这个时候,我们用numastat命令去查看进程a.out的内存分布,很可能会发现它有少部分内存不在NUMA1:
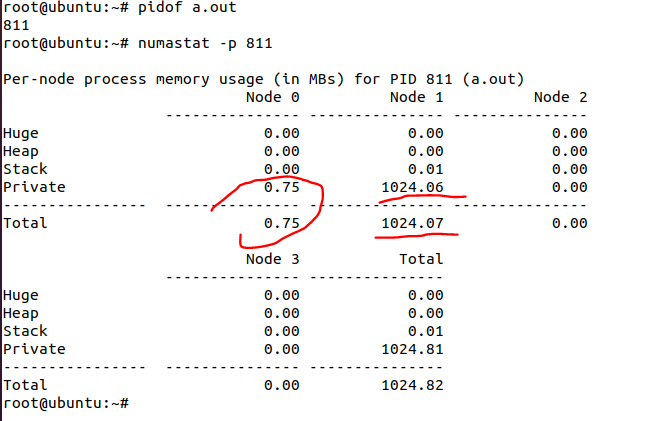
有极少量0.75MB在NUMA0。这是不是说numactl -m 1没有起作用呢?瞎猜没用,眼见为实,我们来调查一下这个在NUMA0的内存属于进程的哪一部分。
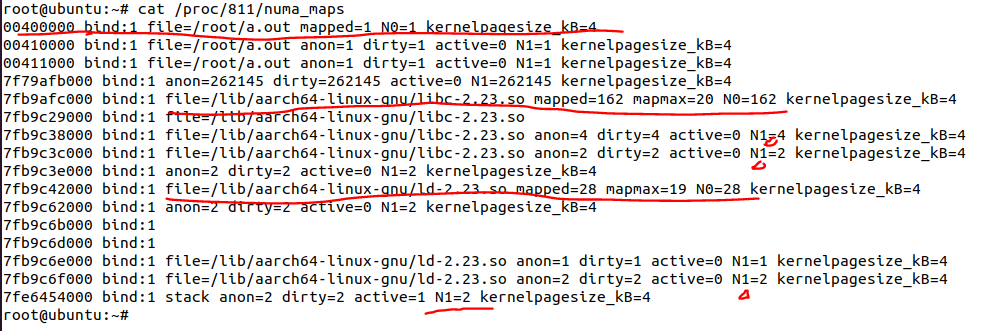
基本上可以看出,有3个地方有位于N0的内存,比如:
开始地址是0x40000的,文件背景为/root/a.out的部分;
开始地址是0x7fb9afc000,文件背景为/lib/aarch64-linux-gnu/libc-2.23.so的部分;
开始地址为0x7fb9c42000,文件背景为/lib/aarch64-linux-gnu/ld-2.23.so的部分。
如果我们进一步探究,会发现上面这三段,都是代码段:

为什么会这样呢?看起来numactl -m <node>对代码段不起作用?

代码段为啥没进入指定numa?
原因其实是比较清晰的。上述代码段对应的内存,在Linux内核中,都属于有文件背景的页面,受page cache机制管理。
想象一个场景,如果a.out曾经运行过一次(其实我开机后已经在没有用numactl绑定内存的情况下,运行过一次a.out,上面的数据是第二次运行a.out的时候采集的),然后系统也加载了一些动态库,那么a.out本身的代码段,库的代码段可能进入到了numa节点m,从而在内存命中。接下来,如果我们用numactl -m <n> ./a.out去运行a.out并绑定numa节点n,势必要再次需要a.out的代码段以及a.out依赖的动态库的代码段。但是前一次,这些代码段都进入了page cache(位于NUMA node m),所以第2次在numa node n运行的时候,其实是命中了numa node m里面的内存。
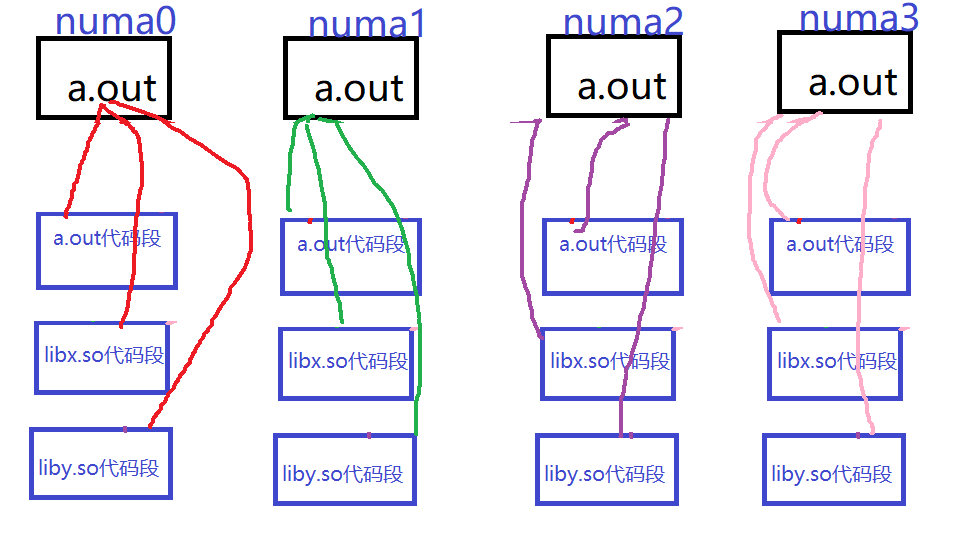
假设我们运行4个a.out,这4个a.out分别运行于4个不同的numa,然后a.out依赖a.out的代码段、libx.so代码段,liby.so代码段。那么,完全有可能出现下图的情况,a.out的代码段位于numa0,libcx.so代码段位于numa1,liby.so的代码段位于numa2,这样4份运行中的a.out,都各自有跨NUMA的代码段内存访问,这样在icache替换的时候,都需要跨NUMA访问内存。

内核为什么这样做呢?原因在于,page cache的管理机制是以inode为单位的,每个page inode唯一!一个inode(比如a.out对应的inode)的page cache在内存命中的情况下,内核会直接用这部分page cache。这个page cache,不会为每个NUMA单独复制一份。从page cache的管理角度来讲,这没有问题。
我们把前面的a.out kill掉,然后drop一次cache,再看a.out的内存分布,发现在node0的部分减少了(0.75->0.63)
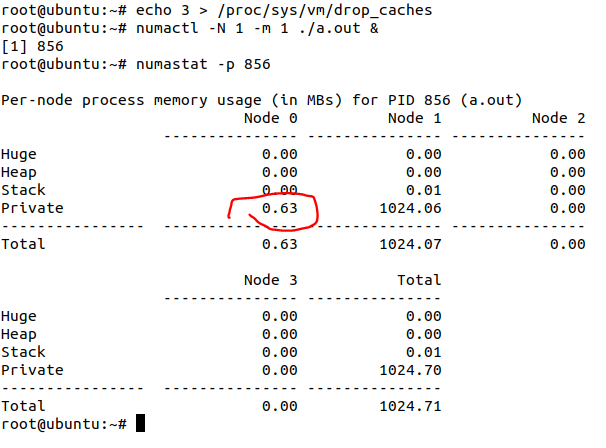
为什么呢?因为我drop掉部分page cache后(echo 3也不可能drop掉全部的所有的代码段,毕竟这里面很多代码是“活跃”代码),我们再运行a.out并绑定numa1的时候,这次这些没有命中的代码段page cache,会进入到numa1。
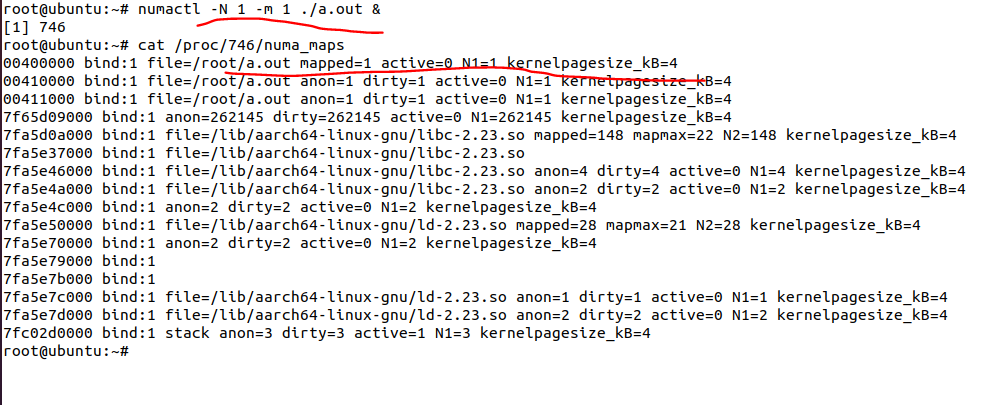
如果我们重启系统,开机第一次运行a.out就绑定numa1呢?这个时候,我们会看到a.out的代码段在numa1:
然后我们把a.out kill掉,第二次绑定numa node0运行a.out,会发现这次的a.out的代码段还是在numa node1而不是node0:
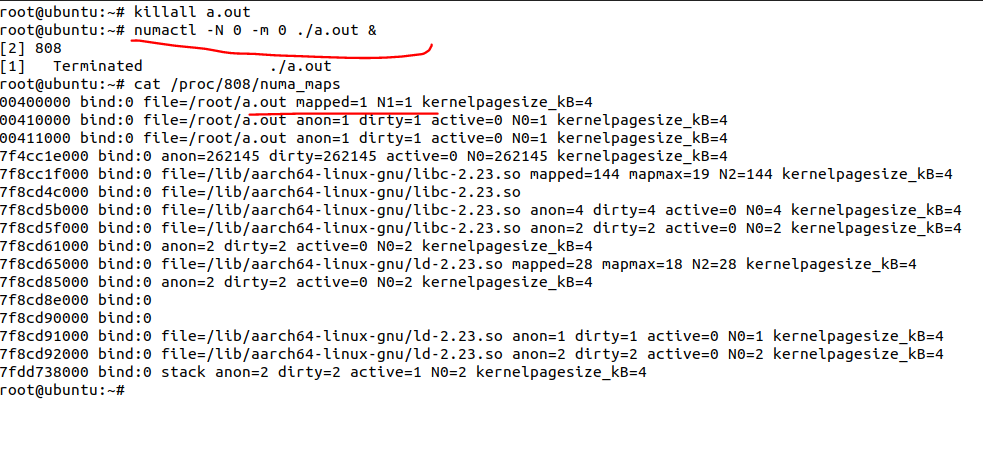
原因是它命中了第一次运行a.out已经进入node1的代码段page cache。
初恋为什么如此刻骨铭心,你终究还是错过了那个人,而多少年以后,常常回想起来,你依然泪流满面?因为,它命中了你的page cache。但是终究,一个人,一生可能不会只运行一次a.out。我们终究也要学会放手,把全部的爱,献给你身边与你相濡以沫的那个人。

内存管理的改进方向
2020年8月,我在Linux内核里面提交和合入了per-numa CMA的支持:
dma-contiguous: provide the ability to reserve per-numa CMA
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=b7176c261cdbc
这样让每个NUMA里面的外设申请连续内存的时候,可以申请到本NUMA的近地址内存,而不用跑到远端去,从而提高I/O的性能:

考虑到代码段以及其他page cache的跨NUMA特点,这里我想提一个可能性,就是per-numa Page cache。内核可以支持让关键的代码段,文件背景页面,在每个NUMA单独获得一份page cache:
它的缺点是显而易见的,page cache可能会用多份内存。它的优点也是显而易见的,就是代码段不用跨NUMA了。这属于典型的以空间换时间!
这个事情行不行得通呢?技术上是行得通的,实践上,我是不敢做的,因为需要大量的benchmark,加上patch至少得发20,30个版本,前后一两年至少的。别的不说,宋牧春童鞋的省vmemmap内存的patch已经发到了22版:
[PATCH v22 0/9] Free some vmemmap pages of HugeTLB pagehttps://lore.kernel.org/lkml/20210430031352.45379-1-songmuchun@bytedance.com/
要是干这个page cache的优化,不得至少发个30版?通常这种有利于全世界,而不利于自己的KPI的事情,是没有多少工程师愿意投入的 :-) 细思恐极,这需要极大的耐心、投入和奉献精神。
那么,前期是不是可以从一个小点开始优化呢?我觉得是可能的。
比如a.out本身在numa0运行,kill后再在numa1运行,这个时候,内核感知到a.out独一份,没有share的情况,是不是直接在内核态把page cache直接migrate到numa1呢?我这里还是打个嘴炮就好,把想象空间留给读者。
扫描/识别二维码关注"Linux阅码场"

如果您觉得不错,请转发转发转发!
或者随手点个“在看”吧~