在pytorch 中,
Dataset: 用于数据集的创建;
DataLoader: 用于在训练过程中,传递获取一个batch的数据;
这里先介绍 pytorch 中的 Dataset 这个类,
torch.utils.data. dataset.py 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。
数据集,其实就是一个负责处理索引(index)到样本(sample)映射的一个类(class)。
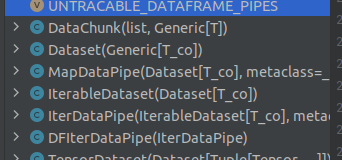
在torch.utils.data. dataset.py 中可知,
pytorch 提供两种数据集:
- Map 式数据集, 上图中
MapDataPipe() - Iterable 式数据集,
IterDataPipe()
1. Map 式数据集
即上图中MapDataPipe(),
1.1 需要重写的方法
一个Map式的数据集必须要重写__getitem__(self, index),
len(self) 两个内建方法,用来表示从索引到样本的映射(Map).
这样一个数据集dataset的作用如下,
- 当使用dataset[idx]命令时,可以在你的硬盘中读取你的数据集中第idx张图片以及其标签(如果有的话);
- len(dataset)则会返回这个数据集的容量。
1.2 使用方法
例子-1: 自己实验中写的一个例子:这里我们的图片文件储存在“./data/faces/”文件夹下,图片的名字并不是从1开始,而是从final_train_tag_dict.txt这个文件保存的字典中读取,label信息也是用这个文件中读取。大家可以照着注释阅读这段代码。
from torch.utils import data
import numpy as np
from PIL import Imageclass face_dataset(data.Dataset):def __init__(self):self.file_path = './data/faces/'f=open("final_train_tag_dict.txt","r")self.label_dict=eval(f.read())f.close()def __getitem__(self,index):label = list(self.label_dict.values())[index-1]img_id = list(self.label_dict.keys())[index-1]img_path = self.file_path+str(img_id)+".jpg"img = np.array(Image.open(img_path))return img,labeldef __len__(self):return len(self.label_dict)2. Iterable 式数据集
一个Iterable(迭代)式数据集是抽象类data.IterableDataset的子类,并且覆写了__iter__方法成为一个迭代器。
这种数据集主要用于数据大小未知,或者以流的形式的输入,本地文件不固定的情况,需要以迭代的方式来获取样本索引。
一个 Iterable 式的数据集必须要重写__iter__,
class IterableDataset(Dataset[T_co]):r"""An iterable Dataset.All datasets that represent an iterable of data samples should subclass it.Such form of datasets is particularly useful when data come from a stream.All subclasses should overwrite :meth:`__iter__`, which would return aniterator of samples in this dataset.When a subclass is used with :class:`~torch.utils.data.DataLoader`, eachitem in the dataset will be yielded from the :class:`~torch.utils.data.DataLoader`iterator. When :attr:`num_workers > 0`, each worker process will have adifferent copy of the dataset object, so it is often desired to configureeach copy independently to avoid having duplicate data returned from theworkers. :func:`~torch.utils.data.get_worker_info`, when called in a workerprocess, returns information about the worker. It can be used in either thedataset's :meth:`__iter__` method or the :class:`~torch.utils.data.DataLoader` 's:attr:`worker_init_fn` option to modify each copy's behavior."""def __iter__(self) -> Iterator[T_co]:raise NotImplementedErrordef __add__(self, other: Dataset[T_co]):return ChainDataset([self, other])所有表示数据样本可迭代的数据集都应该对其进行子类化。
这种形式的数据集在数据来自流的时候特别有用。
所有的子类都应该覆盖 :meth:__iter__,它将返回这个数据集中样本的迭代器。
- 当子类与 :class:
~torch.utils.data.DataLoader一起使用时,数据集中的每个项目将从 :class:~torch.utils.data.DataLoader迭代器中产生。 - 当 :attr:
num_workers > 0时,每个工作进程将有一个不同的数据集对象的副本,所以通常需要独立配置每个副本,以避免从工作进程返回重复的数据。 - :func:
~torch.utils.data.get_worker_info,当在工作进程中调用时,返回关于工作者的信息。它可以被用于数据集的 :meth:__iter__方法或 :class:~torch.utils.data.DataLoader的 j- - :attr:
worker_init_fn选项来修改每个副本的行为
2.1 迭代器和生成器之间的关系
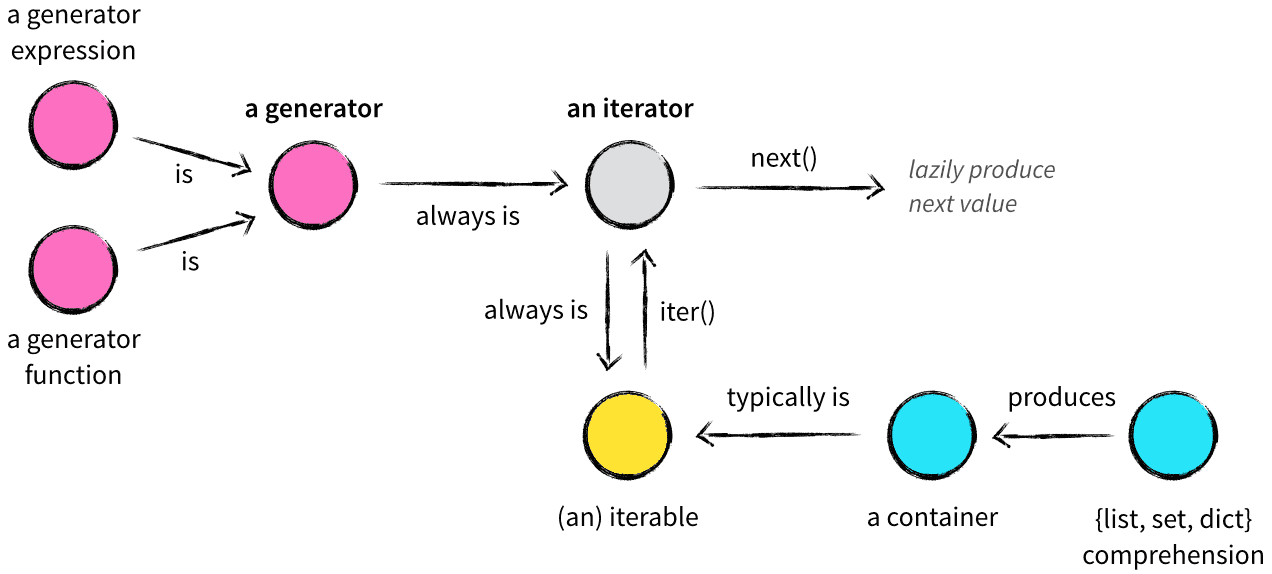
2.2 python 中的迭代器
顾名思义,迭代器就是用于迭代操作(for 循环)的对象,它像列表一样可以迭代获取其中的每一个元素,任何实现了 __next__ 方法 (python2 是 next)的对象都可以称为迭代器。
它与列表的区别在于,构建迭代器的时候,不像列表把所有元素一次性加载到内存,而是以一种延迟计算(lazy evaluation)方式返回元素,这正是它的优点。
比如列表含有中一千万个整数,需要占超过400M的内存,而迭代器只需要几十个字节的空间。
因为它并没有把所有元素装载到内存中,而是等到调用 next 方法时候才返回该元素
(按需调用 call by need 的方式,本质上 for 循环就是不断地调用迭代器的__next__方法)。
以斐波那契数列为例来实现一个迭代器:
class Fib:def __init__(self, n):self.prev = 0self.cur = 1self.n = ndef __iter__(self):return selfdef __next__(self):if self.n > 0:value = self.curself.cur = self.cur + self.prevself.prev = valueself.n -= 1return valueelse:raise StopIteration()# 兼容python2def next(self):return self.__next__()f = Fib(10)
print([i for i in f])
#[1, 1, 2, 3, 5, 8, 13, 21, 34, 52.3 python 中的生成器
知道迭代器之后,就可以正式进入生成器的话题了。
2.3.1 为什么需要生成器
通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中,这种一边循环一边计算的机制,称为生成器:generator
生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。
生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,但是,不同于一般的函数会一次性返回包括了所有数值的数组,生成器一次只能产生一个值,这样消耗的内存数量将大大减小,而且允许调用函数可以很快的处理前几个返回值,因此生成器看起来像是一个函数,但是表现得却像是迭代器
-
生成器函数:也是用def定义的,利用关键字yield一次性返回一个结果,阻塞,重新开始
-
生成器表达式:返回一个对象,这个对象只有在需要的时候才产生结果
普通函数用 return 返回一个值,和 Java 等其他语言是一样的,然而在 Python 中还有一种函数,用关键字 yield 来返回值,这种函数叫生成器函数,函数被调用时会返回一个生成器对象,生成器本质上还是一个迭代器,也是用在迭代操作中,因此它有和迭代器一样的特性,唯一的区别在于实现方式上不一样, 生成器更加简洁。
2.3.2 生成器函数
最简单的生成器函数:
>>> def func(n):
... yield n*2
...
>>> func
<function func at 0x00000000029F6EB8>
>>> g = func(5)
>>> g
<generator object func at 0x0000000002908630>
>>>
func 就是一个生成器函数,调用该函数时返回对象就是生成器 g ,这个生成器对象的行为和迭代器是非常相似的,可以用在 for 循环等场景中。注意 yield 对应的值在函数被调用时不会立刻返回,而是调用next方法时(本质上 for 循环也是调用 next 方法)才返回。
>>> g = func(5)
>>> next(g)
10>>> g = func(5)
>>> for i in g:
... print(i)
...
10
那为什么要用生成器呢?用生成器它没有那么多冗长代码了,而且性能上一样的高效。
不足之处,便是需要多理解一下。
来看看用生成器实现斐波那契数列有多简单。
def fib(n):prev, curr = 0, 1while n > 0:n -= 1yield currprev, curr = curr, curr + prevprint([i for i in fib(10)])
#[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
2.3.2 生成器表达式
- 生成器表达式
器表达式与列表推导式长的非常像,但是它俩返回的对象不一样,前者返回生成器对象,后者返回列表对象。
>>> g = (x*2 for x in range(10))
>>> type(g)
<type 'generator'>
>>> l = [x*2 for x in range(10)]
>>> type(l)
<type 'list'>
生成器的优势,就是迭代海量数据时,生成器会更加内存。
2.3 生成器在 DataLoader中应用
深度学习框架PyTorch中的DataLoader模块的实现就使用了生成器的机制来生成一次训练用的batch。
DataLoader的详解在博主的另一篇文章Pytorch之Dataloader中,这里只讲其中运用到生成器机制的Sampler类模块。
首先,是 RandomSampler, iter(randomSampler) 会返回一个可迭代对象,这个可迭代对象 每次 next 都会输出当前要采样的 index,SequentialSampler也是一样,只不过产生的 index 是顺序的
class RandomSampler(Sampler):def __init__(self, data_source):self.data_source = data_sourcedef __iter__(self):return iter(torch.randperm(len(self.data_source)).long())def __len__(self):return len(self.data_source)
BatchSampler 是一个普通 Sampler 的 wrapper, 普通Sampler 一次仅产生一个 index, 而 BatchSampler 一次产生一个 batch 的 indices。
class BatchSampler(Sampler):"""Wraps another sampler to yield a mini-batch of indices. Args: sampler (Sampler): Base sampler. batch_size (int): Size of mini-batch. drop_last (bool): If ``True``, the sampler will drop the last batch if its size would be less than ``batch_size`` Example: >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)) [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]] >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True)) [[0, 1, 2], [3, 4, 5], [6, 7, 8]] """def __init__(self, sampler, batch_size, drop_last):if not isinstance(sampler, Sampler):raise ValueError("sampler should be an instance of ""torch.utils.data.Sampler, but got sampler={}".format(sampler))if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \batch_size <= 0:raise ValueError("batch_size should be a positive integeral value, ""but got batch_size={}".format(batch_size))if not isinstance(drop_last, bool):raise ValueError("drop_last should be a boolean value, but got ""drop_last={}".format(drop_last))self.sampler = samplerself.batch_size = batch_sizeself.drop_last = drop_lastdef __iter__(self):batch = []for idx in self.sampler:batch.append(idx)if len(batch) == self.batch_size:yield batchbatch = []if len(batch) > 0 and not self.drop_last:yield batchdef __len__(self):if self.drop_last:return len(self.sampler) // self.batch_sizeelse:return (len(self.sampler) + self.batch_size - 1) // self.batch_size
reference:
https://chenllliang.github.io/2020/02/04/dataloader/
https://chenllliang.github.io/2020/02/06/PyIter/
https://www.zhihu.com/question/20829330/answer/213544776
https://www.cnblogs.com/wj-1314/p/8490822.html